 网硕互联帮助中心
网硕互联帮助中心一、线性回归:预测连续值的"入门神器"
1. 核心原理:用线性关系拟合真实数据
线性回归的本质的是寻找变量之间的线性映射关系,从而预测一个连续的输出值。
数学公式:![]()
-
y:待预测的连续值
-
X1,X2,…Xn:输入特征
-
θ0:截距项
-
θ1,θ2,…,θn:特征系数
算法的目标,就是通过数据训练出最优的 θ 值,让预测值和真实值的误差最小。
2. 实战案例:用体重和年龄预测收缩压
(1)代码实现
import pandas as pd
from sklearn.linear_model import LinearRegression
# 1. 数据读取
data = pd.read_csv('多元线性回归.csv', encoding='gbk')
# 2. 定义特征(X)和标签(y)
X = data[['体重', '年龄']] # 两个输入特征
y = data['血压收缩'] # 连续输出标签
# 3. 模型训练
model = LinearRegression().fit(X, y)
# 4. 提取模型参数
weight_coef = model.coef_[0] # 体重的系数
age_coef = model.coef_[1] # 年龄的系数
intercept = model.intercept_ # 截距项
# 5. 输出结果
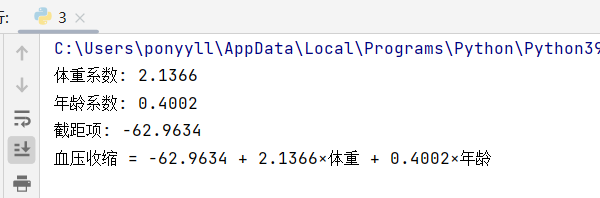
print(f"体重系数: {weight_coef:.4f}")
print(f"年龄系数: {age_coef:.4f}")
print(f"截距项: {intercept:.4f}")
print(f"血压收缩 = {intercept:.4f} + {weight_coef:.4f}×体重 + {age_coef:.4f}×年龄")
(2)运行结果
3. 适用场景
线性回归适合连续值预测,比如:
-
预测房价、股票价格;
-
预测学生成绩、产品销量;
-
预测生理指标(如血压、血糖)。
二、逻辑回归:从线性到分类的"进阶魔法"
逻辑回归名字里带"回归",但实际是二分类算法——它基于线性回归的结果,通过一个「sigmoid函数」将输出映射到0~1之间,从而表示"属于某一类的概率"。
1. 核心原理:sigmoid函数的分类
先做线性回归:计算 ![]() ;
;
再通过sigmoid函数映射:![]()
当 P≥0.5 时,预测为类别1;
当 P<0.5 时,预测为类别0。
sigmoid函数的作用是"压缩":无论z是多大的正数或负数,输出都稳定在0~1之间,完美契合"概率"的定义。
2. 实战案例:信用卡欺诈检测
(1)数据预处理:解决"数据不一致"问题
import pandas as pd
from sklearn.preprocessing import StandardScaler
# 1. 数据读取(处理编码问题)
data = pd.read_csv("./creditcard.csv", encoding='utf8', engine='python')
# 2. 数据脱敏:已提前处理,保护用户隐私
# 3. 特征标准化:Amount(交易金额)和其他特征量级差异大,需归一化
scaler = StandardScaler()
data['Amount'] = scaler.fit_transform(data[['Amount']]) # Z标准化:(x-均值)/标准差
# 4. 删除无关特征:Time(交易时间)对分类无意义
data = data.drop(['Time'], axis=1)
# 查看数据前5行
print(data.head())
为什么要标准化?
如果Amount是"万元级",而其他特征是"0~1级",模型会过度重视Amount的影响。标准化后所有特征权重一致,模型更公平。
(2)可视化:查看正负样本分布
import matplotlib.pyplot as plt
from pylab import mpl
# 解决中文显示问题
mpl.rcParams['font.sans-serif'] = ['Microsoft YaHei']
mpl.rcParams['axes.unicode_minus'] = False
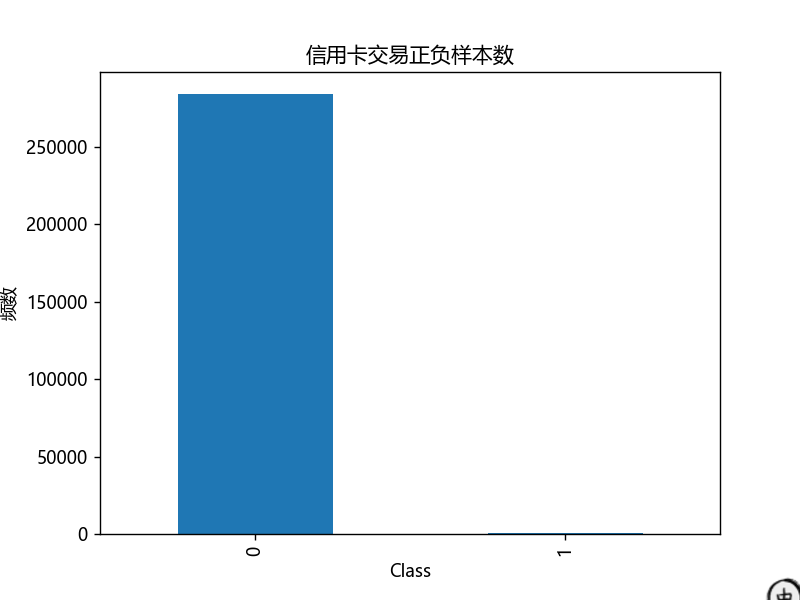
# 统计正负样本个数
labels_count = pd.value_counts(data['Class'])
print(labels_count) # 输出:0 284315,1 492
# 绘制柱状图
plt.title("信用卡交易正负样本数")
plt.xlabel("类别(0=正常,1=欺诈)")
plt.ylabel("频数")
labels_count.plot(kind='bar')
plt.show()
这里能发现「样本不均衡」(正常交易远多于欺诈),这也是分类任务中常见的问题——后续评价不能只看准确率,还要看精确率、召回率。
(3)模型训练:正则化防止过拟合
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
# 划分训练集和测试集
X = data.drop(['Class'], axis=1)
y = data['Class']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=1000) #随机选取,生成随机种子,保证结果不变
# 初始化逻辑回归模型:C是正则化参数(C越小,正则化越强,防止过拟合)
lr = LogisticRegression(C=0.01)
# 训练模型
lr.fit(X_train, y_train)
# 测试集预测
test_predicted = lr.predict(X_test)
运行结果:
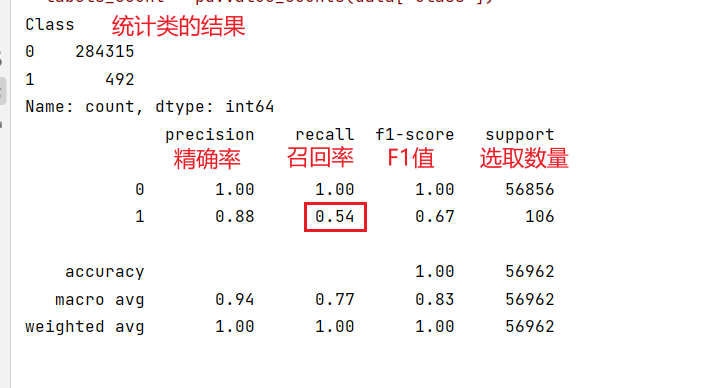
(4)模型评价:不止看准确率
分类任务中,「准确率」往往不够用(比如样本不均衡时,模型全预测为0也能有99%准确率),「混淆矩阵」和四大核心指标:
① 混淆矩阵
|
预测值=1 |
预测值=0 |
|
|
真实值=1 |
TP(真阳性) |
FN(假阴性) |
|
真实值=0 |
FP(假阳性) |
TN(真阴性) |
-
TP:真实是1,预测也是1;
-
FN:真实是1,预测是0 ;
-
FP:真实是0,预测是1 ;
-
TN:真实是0,预测是0 。
② 四大评价指标
准确率(Accuracy):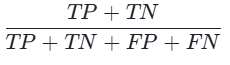 (整体预测正确的比例);
(整体预测正确的比例);
精确率(Precision):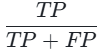 (预测为1的样本中,真实是1的比例);
(预测为1的样本中,真实是1的比例);
召回率(Recall):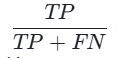 (真实是1的样本中,被预测为1的比例);
(真实是1的样本中,被预测为1的比例);
F1-score: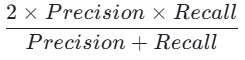 (精确率和召回率的调和平均,综合评价)。
(精确率和召回率的调和平均,综合评价)。
样本不均衡时,召回率和F1-score更重要。
3. 适用场景
逻辑回归适合二分类任务,比如:
-
欺诈检测(信用卡、交易);
-
疾病诊断(患病/健康);
-
客户流失预测(流失/留存);
-
垃圾邮件识别(垃圾/正常)。
三、线性回归vs逻辑回归:核心区别一目了然
|
对比维度 |
线性回归 |
逻辑回归 |
|
核心任务 |
连续值预测 |
二分类(概率预测) |
|
输出范围 |
(-∞, +∞)连续值 |
[0,1]概率值 |
|
核心函数 |
线性映射 |
线性映射+Sigmoid函数 |
|
损失函数 |
均方误差(MSE) |
交叉熵损失(Cross-Entropy) |
|
适用场景 |
房价、成绩、生理指标预测 |
欺诈、患病、垃圾邮件分类 |
|
模型本质 |
回归模型 |
分类模型 |



评论前必须登录!
注册