 网硕互联帮助中心
网硕互联帮助中心26年1月来自MIT、多伦多大学、Sony和Deepmind的论文“VirtualEnv: A Platform for Embodied AI Research”。
随着大语言模型(LLM)在推理和决策方面的不断进步,人们越来越需要真实且交互式的环境来严格评估它们的能力。VirtualEnv,是一个基于UE 5 构建的新一代仿真平台,它能够在具身化和交互式场景中对 LLM 进行细粒度的基准测试。VirtualEnv 支持丰富的智体-环境交互,包括物体操作、导航和自适应多智体协作,以及受游戏启发的机制,例如密室逃脱和程序生成的环境。其提供一个基于UE构建的用户友好型 API,允许研究人员使用自然语言指令部署和控制由 LLM 驱动的智体。其集成大规模 LLM 和视觉-语言模型(VLM),例如基于 GPT 的模型,以从多模态输入生成的环境和结构化任务。实验对几种常用的LLM在复杂度递增的任务中的性能进行基准测试,分析它们在适应性、规划能力和多智体协调方面的差异。本文还描述用于程序化任务生成、任务验证和实时环境控制的方法。VirtualEnv 是一个开源平台,目标是推进人工智能和游戏交叉领域的研究,实现具身人工智能环境下低复杂度智体的标准化评估,并为沉浸式模拟和交互式娱乐的未来发展铺平道路。
VirtualEnv的多智体规划和执行的系统概览如图所示: 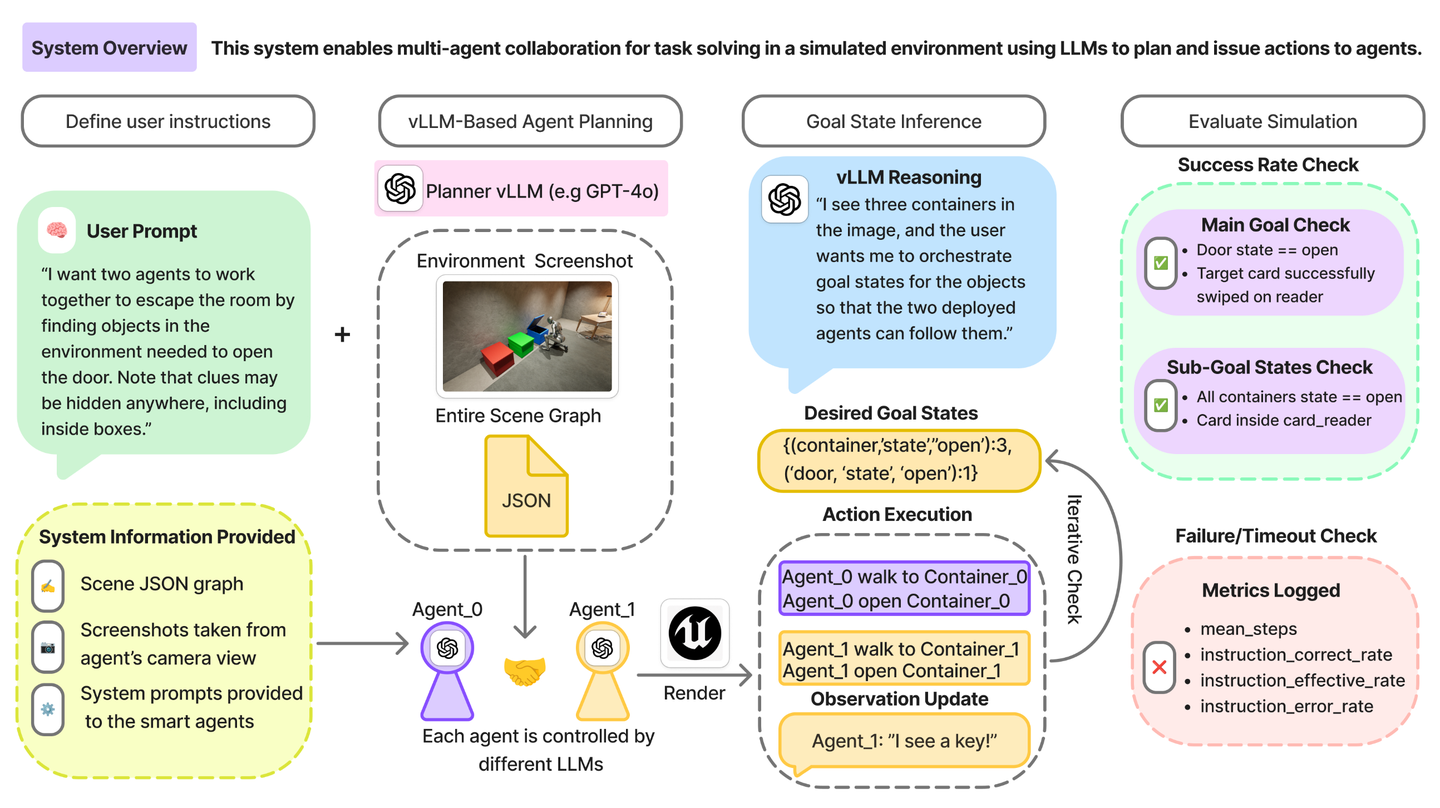
VirtualEnv模拟器的主要特性
如图展示VirtualEnv的三大核心功能:逼真的室内外环境、包含超过20,000个交互式资源的庞大资源库,以及对人形机器人智体的精准控制。这些特性构成全面的具身人工智能研究平台的基础。 
如表所示,VirtualEnv独特地结合多智体支持和语言交互功能,同时在现有平台中提供最全面的环境类型(3D-MIO)和最大的任务库(140,000个任务)。这种组合能够实现跨越室内外环境的复杂场景,支持比单房间(AI2Thor)或仅限多房间(Habitat 3.0、VirtualHome)的替代方案更广泛的具身人工智能研究。 
高保真引擎:VirtualEnv提供一个高度动态和交互式的人工智能研究环境。 VirtualEnv 基于UE 5(Games 2024)构建,拥有丰富的场景,包括办公室、零售场所和城市街景。VirtualEnv 的核心在于强调真实感和复杂的智体与环境交互,它利用先进的渲染管线和程序生成技术,实现物理布局、物体摆放和光照条件的无限变化。
丰富的物体和动作库:VirtualEnv 拥有超过 20,000 个不同的物体,支持各种现实世界场景,例如家居布置、家务活动、城市导航和多步骤决策。每个物体都嵌入了各种交互功能——例如可打开的门、可移动的家具、可抓取的物体和交互式设备——使智体能够执行精细的交互。许多物体采用摄影测量扫描进行高分辨率建模,确保了逼真的物理效果和视觉精度。虚幻引擎的物理引擎能够实现物体对运动、形变和状态转换等交互的真实响应。此外,结构化元数据使AI智体能够推断物体属性,从而增强其学习真实世界物理交互的能力。
多模态感知与观测:VirtualEnv提供丰富的多模态感知功能,支持在动态环境中进行感知和决策。智体可以访问RGB和深度传感器,获取逼真的输入和空间理解,并进行语义分割以实现像素级物体识别。全景俯视图进一步辅助空间推理和大规模导航。这些模态的结合使智体能够以更高的精度和适应性在复杂场景中进行解释和行动。
用户友好的API和语言驱动的AI智体:VirtualEnv原生支持大语言模型(LLM)和视觉-语言模型(VLM)的集成,使AI智体能够通过自然语言与世界进行交互。这使得基于高级指令的灵活任务执行、动态决策和交互式环境控制成为可能。研究人员可以探索人工智能模型如何实时解释、响应和执行语言指令,从而推动基于LLM的机器人技术和具身语言理解的发展。
场景图表示:VirtualEnv 使用场景图组织其环境,该场景图以层级结构编码对象、智体和空间关系。这种表示方法能够高效地查询环境状态,使智体能够根据周围环境做出明智的决策。它还支持语义推理,使智体能够理解对象的作用和空间约束,从而提高其与环境进行有效交互的能力。此外,场景图支持部分观测,使得在信息有限的情况下研究智体的行为成为可能,这对于不确定性下的规划研究至关重要。 VirtualEnv 通过提供可编程场景图 API,简化了创建和修改场景及任务的过程,使研究人员在设计交互式和自适应仿真环境时拥有更大的灵活性。
环境构建和资源选择:VirtualEnv 中的所有环境均采用混合方法构建,该方法结合手动场景创作和虚幻引擎(UE) 5 中的程序化生成。从UE商城精心挑选高分辨率 3D 资源,并选择那些具有丰富功能(例如,可打开、可抓取、可移动)和清晰语义类别的资源。这些资源的选择基于它们与具身人工智能任务(例如,室内导航、物体操作和目标导向行为)的相关性,并被组织成主题一致的场景(例如,办公室、厨房、零售商店和城市户外环境)。
语言驱动的任务和场景生成:VirtualEnv 支持通过基于语言的界面动态生成场景。用户提供自然语言提示,描述所需的任务设置,例如密室逃脱挑战或协作解决问题的场景。LLM会解读提示并将其分解为一系列子目标或谜题(例如,“找到钥匙”、“解开谜题”、“打开盒子”)。基于这些子目标,系统会识别所需的环境组件,包括物体、线索和空间布局,并自动更新场景图以实例化它们。然后,通过 VirtualEnv API 渲染环境,生成完整的交互式场景,并在其中评估智体完成语言定义任务的能力。该流程基于多模态推理和任务感知场景构建,实现了可扩展且多样化的环境生成。(参见下图) 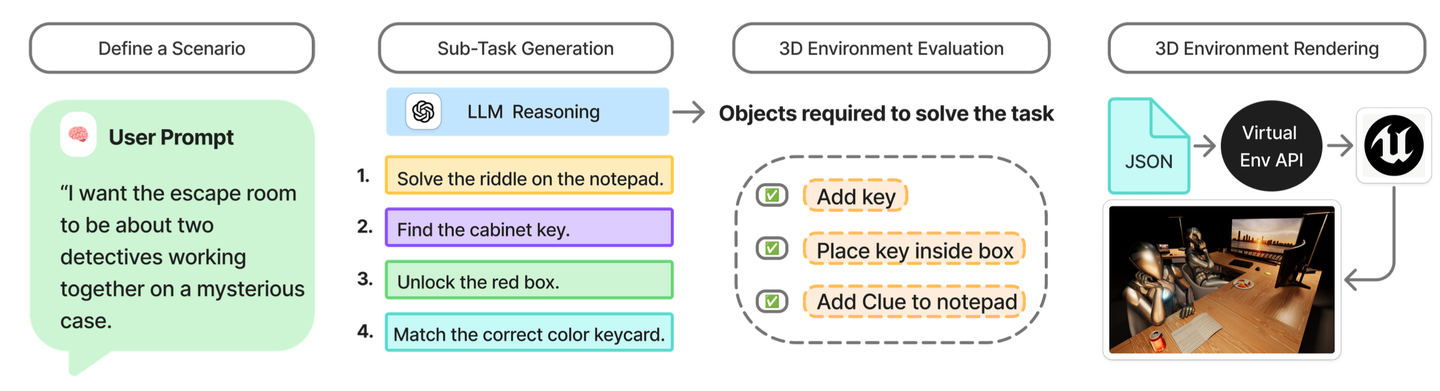
密室逃脱挑战框架
为了评估 VirtualEnv 中的高阶推理能力,引入密室逃脱挑战框架。与简单的导航或检索任务不同,密室逃脱融合了解谜、物体互动、叙事线索以及偶尔的多智体协作。智体必须在环境中发现线索,将场景中的信息联系起来,并解决一个贯穿始终的谜题,从而鼓励更灵活、更审慎的行为。
原理与设计。游戏中的谜题设计为规划和解决问题提供一个有用的框架,因为每个谜题都是全新的,无法通过记忆来解决。许多谜题还涉及抽象或虚构的物体,这要求智体适应陌生的环境。将这些理念融入 VirtualEnv 可以鼓励探索、策略优化以及对环境反馈的响应。该框架整合认知谜题、交互机制和叙事提示,遵循 Heikkinen & Shumeyko (2016) 的经验金字塔模型。随着谜题的展开,玩家需要导航、操作物体并做出决策。
难度等级:根据谜题长度和线索间的依赖关系,将密室逃脱挑战分为四个难度等级,逐步增加认知要求:
对人工智能研究的启示:通过将密室逃脱谜题嵌入 VirtualEnv 逼真、动态的环境中,连接具身人工智能和下一代游戏应用。成功完成这些任务标志着人工智能在推理、情境理解和自适应问题解决能力方面的进步。此外,灵活的谜题设计提供一个框架,用于探索 LLM 微调、具身人工智能集成以及对新任务的泛化。随着人工智能的不断发展,这些基准测试将有助于评估人工智能智体在实时交互式环境中适应陌生、多步骤挑战的能力。
使用 vLLM 进行环境修改
如图所示,VirtualEnv 使用vLLM来响应自然语言命令修改现有的 3D 场景。该模型将提示(例如,“将钥匙放入盒子中”)转换为 JSON 编码的编辑语句,这些语句指定目标对象、空间关系和放置规则。这些编辑语句被合并到当前的观察图中,并在UE 5 中渲染。然后,解释检查会将符号图与渲染视图进行比较,并标记预期状态和可视化状态之间的任何不匹配之处。这种语言引导的编辑流程无需人工干预即可快速、精确地调整复杂的环境。 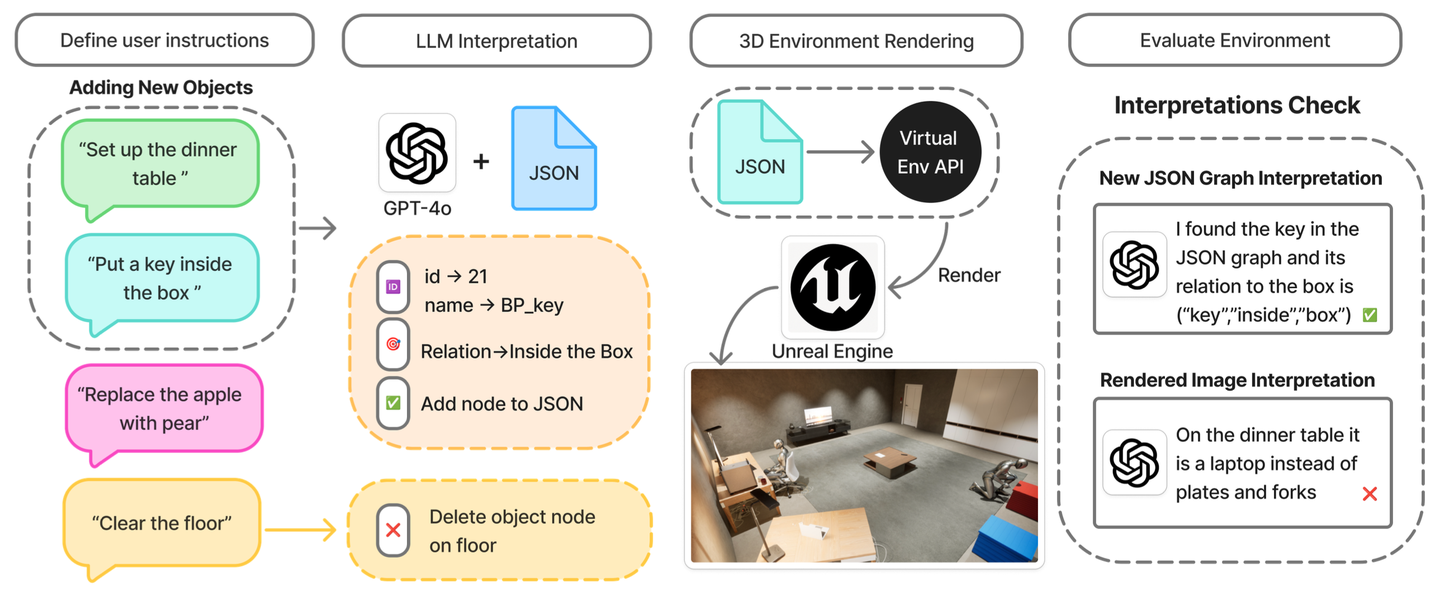
如图所示:各平台视觉真实度排名对比。采用问卷调查的方式进行一项定性基准研究,共有 31 位受访者参与。参与者在盲测中根据视觉真实度对每个平台进行排名,评分范围从 5 分(最真实)到 1 分(最不真实)。与其他所有环境相比,该平台的视觉真实度最高。 



评论前必须登录!
注册