 网硕互联帮助中心
网硕互联帮助中心
📖标题:Rethinking Video Generation Model for the Embodied World
🌐来源:arXiv, 2601.15282v1
🌟摘要
视频生成模型显著推进了具身智能,开启了生成各种机器人数据的新可能性,这些数据可以捕捉物理世界中的感知、推理和行动。然而,合成准确反映现实世界机器人交互的高质量视频仍然具有挑战性,而缺乏标准化基准限制了公平比较和进步。为了弥补这一差距,我们引入了一个全面的机器人基准RBench,旨在评估五个任务领域和四个不同实施例的面向机器人的视频生成。它通过可重复的子指标评估任务级正确性和视觉保真度,包括结构一致性、物理合理性和动作完整性。对25个代表性模型的评估凸显了在生成物理逼真的机器人行为方面的重大缺陷。此外,该基准与人类评估实现了0.96的Spearman相关系数,验证了其有效性。虽然RBench提供了识别这些缺陷的必要镜头,但实现物理现实主义需要超越评估以解决高质量训练数据的严重短缺。在这些见解的推动下,我们引入了一个精致的四阶段数据管道,从而产生了RoVid-X,这是用于视频生成的最大开源机器人数据集,具有400万注释的视频拆条,涵盖数千个任务,并丰富了全面的物理属性注释。总的来说,这种评估和数据的协同生态系统为视频模型的严格评估和可扩展训练奠定了坚实的基础,加速了体现AI向通用智能的演进。
🛎️文章简介
🔸研究问题:如何有效评估和提升面向具身机器人的视频生成模型的物理真实性和任务完成能力?
🔸主要贡献:提出首个面向机器人视频生成的综合基准RBench与大规模高质量数据集RoVid-X,推动具身AI发展。
📝重点思路
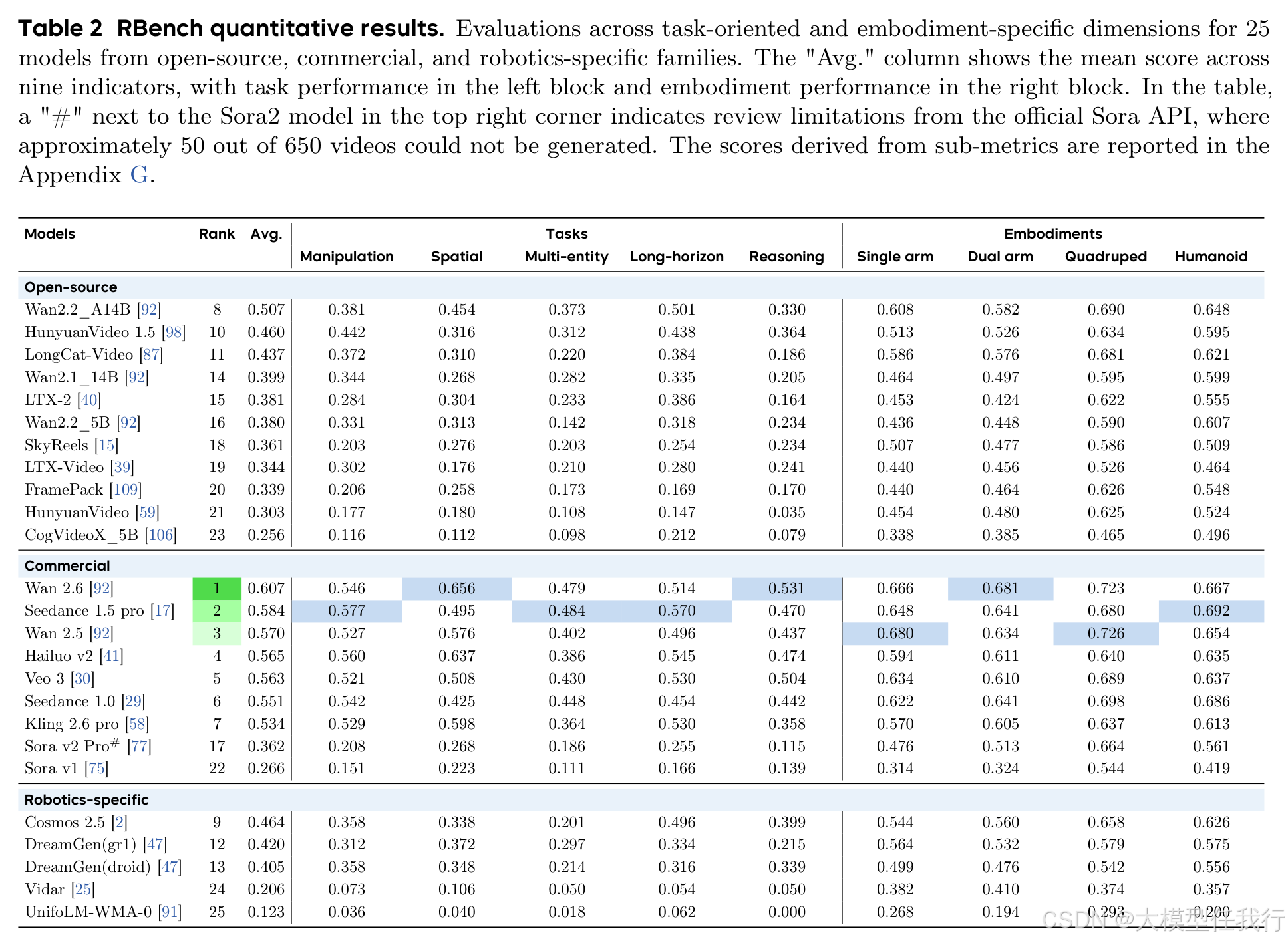
🔸设计RBench基准,涵盖5类任务(操作、长程规划、多实体协作、空间关系、视觉推理)和4种机器人形态,共650个图像-文本对。
🔸构建细粒度自动化评估指标,包括任务完成度(物理语义合理性、任务一致性)和视觉质量(运动幅度、平滑性、主体稳定性)。
🔸通过多模态大模型(MLLM)实现零样本视频评估,结合低层运动统计增强判别力。
🔸建立四阶段数据管道:机器人视频收集、质量过滤、任务分割与描述、物理属性标注,构建RoVid-X数据集。
🔸发布含400万标注视频片段的RoVid-X,覆盖千级任务类型,并提供光学流、深度图等物理注释。
🔎分析总结
🔸25个主流视频模型在RBench上表现普遍不佳,尤其在物理合理性和动作完整性方面存在显著缺陷。
🔸商业闭源模型整体优于开源模型,但Sora系列在物理真实性任务中表现欠佳,揭示媒体生成与具身模拟的差距。
🔸RBench评分与人类偏好高度相关(Spearman ρ=0.96),验证其有效性与可靠性。
🔸使用RoVid-X微调模型后,在各类任务和形态上均取得稳定性能提升,证明数据集的有效性。
🔸当前模型在认知推理与精细操控任务上瓶颈明显,而粗粒度运动(如四足行走)相对更易生成。
💡个人观点
论文将视频生成从“视觉保真”推向“物理智能”,提出兼具任务逻辑与物理规律的评估体系。
🧩附录





评论前必须登录!
注册