 网硕互联帮助中心
网硕互联帮助中心DataAgent 核心架构分析
请关注公众号【碳硅化合物AI】
概要总结
本文档旨在深入剖析 DataAgent 项目的核心架构设计。作为一款基于 Spring AI Alibaba Graph 构建的企业级智能数据分析 Agent,DataAgent 的架构围绕四大核心模型展开:智能体(Agent)、数据源(DataSource)、语义模型(Semantic Model)以及业务知识(Business Knowledge)。
文档首先从系统入口切入,解析了 DataAgentApplication 启动类与核心配置类 DataAgentConfiguration 的职责,阐述了 Spring Boot 上下文加载与工作流引擎的初始化机制。随后,文档详细拆解了模型层的各个组件:作为执行核心的“智能体”及其配置体系、支持多库连接的“数据源”模块、用于语义检索的“语义模型”,以及提供领域上下文的“业务知识”与“智能体知识”库。
通过 PlantUML 类图,文档直观呈现了入口层、控制层、服务层与工作流层之间的依赖链路,以及核心模型间的实体关系。同时,借助时序图还原了智能体创建配置及业务知识向量化的完整作业流程。最后,文档总结了系统的技术实现亮点,涵盖 Spring Boot 自动配置、StateGraph 工作流编排、向量存储集成、多数据源隔离及知识库管理机制。
整体架构遵循高内聚、低耦合的设计原则,既保证了当前系统的稳定性,也为未来的功能扩展与性能调优奠定了坚实基础。
目录
- 1. 入口类以及说明
- 1.1 主入口类
- 1.2 核心配置类
- 1.3 关键类关系图
- 2.模型架构分析
- 2.1 智能体 (Agent)
- 2.2 数据源 (DataSource)
- 2.3 语义模型 (Semantic Model)
- 2.4 业务知识 (Business Knowledge)
- 2.5 智能体知识 (Agent Knowledge)
- 2.6模型类关系图
- 3. 关键业务时序图
- 3.1 智能体创建和配置时序图
- 3.2 业务知识向量化时序图
- 4. 实现关键点说明
- 4.1 Spring Boot 自动配置机制
- 4.2 StateGraph 工作流构建
- 4.3 向量存储集成
- 4.4 多数据源支持
- 4.5 知识管理机制
- 5. 总结说明
1. 入口类以及说明
1.1 主入口类
DataAgentApplication 是 DataAgent 项目的标准 Spring Boot 启动入口。
@EnableScheduling
@SpringBootApplication
public class DataAgentApplication {
public static void main(String[] args) {
SpringApplication.run(DataAgentApplication.class, args);
}
}
该类通过 @SpringBootApplication 注解引导 Spring Boot 的自动配置机制,并利用 @EnableScheduling 激活后台定时任务调度能力。应用启动时,容器将自动扫描并加载工作流定义、数据源适配器及模型服务等核心 Bean,完成系统初始化。
1.2 核心配置类
DataAgentConfiguration 承担着系统核心架构的装配职责。该类主要负责构建 StateGraph 工作流引擎,并实例化各类服务组件。通过在此处定义工作流的节点(Node)流转逻辑与边(Edge)连接关系,确立了整个智能分析系统的运行骨架。
1.3 关键类关系图
下图展示了从应用启动到控制器、服务层及底层工作流引擎的类依赖关系。

2. 模型架构分析
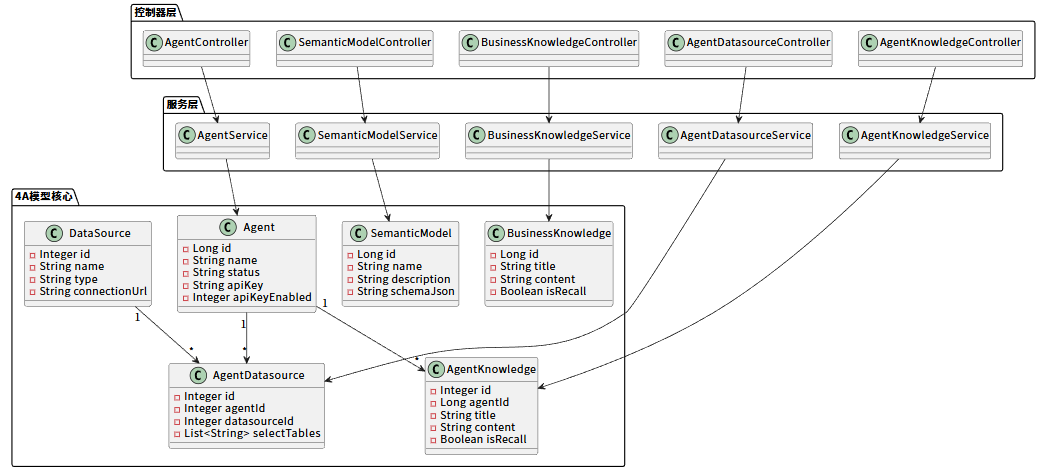
DataAgent 的基础设施围绕四个核心维度构建:Agent(智能体)、DataSource(数据源)、Semantic Model(语义模型)以及 Business Knowledge(业务知识)。这四者共同支撑起智能数据分析的能力。
2.1 智能体 (Agent)
智能体是系统的核心执行单元,聚合了数据源配置、知识库关联及提示词策略。每个智能体实例即代表一个独立的数据分析机器人。
关键类:
- AgentController:负责智能体生命周期管理(CRUD)及 API Key 鉴权。
- AgentService:封装智能体管理的具体业务逻辑。
关键代码片段:
@PostMapping
public ResponseEntity<Agent> create(@RequestBody Agent agent) {
if (agent.getStatus() == null || agent.getStatus().trim().isEmpty()) {
agent.setStatus("draft");
}
Agent saved = agentService.save(agent);
return ResponseEntity.ok(saved);
}
2.2 数据源 (DataSource)
数据源模块定义了业务数据库的连接规范,支持 MySQL、PostgreSQL、H2、达梦等多种主流数据库。配置内容涵盖连接凭证及目标数据表的筛选策略。
关键类:
- AgentDatasourceController:处理智能体与特定数据源的绑定关系。
- AgentDatasourceService:执行数据源初始化及 Schema 元数据的提取与导入。
关键代码片段:
@PostMapping("/init")
public ResponseEntity<ApiResponse> initSchema(@PathVariable(value = "agentId") Long agentId) {
AgentDatasource agentDatasource = agentDatasourceService.getCurrentAgentDatasource(agentId.intValue());
Integer datasourceId = agentDatasource.getDatasourceId();
List<String> tables = Optional.ofNullable(agentDatasource.getSelectTables()).orElse(List.of());
Boolean result = agentDatasourceService.initializeSchemaForAgentWithDatasource(agentId, datasourceId, tables);
return ResponseEntity.ok(ApiResponse.success("Schema初始化成功"));
}
2.3 语义模型 (Semantic Model)
语义模型旨在构建数据结构的语义化映射。它将物理数据库的表结构、字段定义转化为向量化表示,从而支持基于自然语言的语义检索,弥合人机交互与底层数据间的鸿沟。
关键类:
- SemanticModelController:对外提供语义模型的管理接口。
- SemanticModelService:实现语义模型构建与维护的核心逻辑。
2.4 业务知识 (Business Knowledge)
业务知识库存储了领域内的专业术语、计算规则及元数据。通过向量化技术,这些非结构化知识可被系统检索并用于增强 SQL 生成(RAG),显著提升分析结果的业务准确性。
关键类:
- BusinessKnowledgeController:负责业务知识的录入、更新及向量索引触发。
- BusinessKnowledgeService:封装知识向量化处理与检索匹配逻辑。
关键代码片段:
@PostMapping("/refresh-vector-store")
public ApiResponse<Boolean> refreshAllKnowledgeToVectorStore(@RequestParam(value = "agentId") String agentId) {
businessKnowledgeService.refreshAllKnowledgeToVectorStore(agentId);
return ApiResponse.success("success refresh vector store");
}
2.5 智能体知识 (Agent Knowledge)
与全局业务知识不同,智能体知识(Agent Knowledge)是特定智能体实例独有的私有知识配置,用于满足个性化或隔离性的分析需求。
关键类:
- AgentKnowledgeController:管理智能体私有知识库。
- AgentKnowledgeService:处理私有知识的生命周期与向量化。
2.6 模型类关系图
3. 关键业务时序图
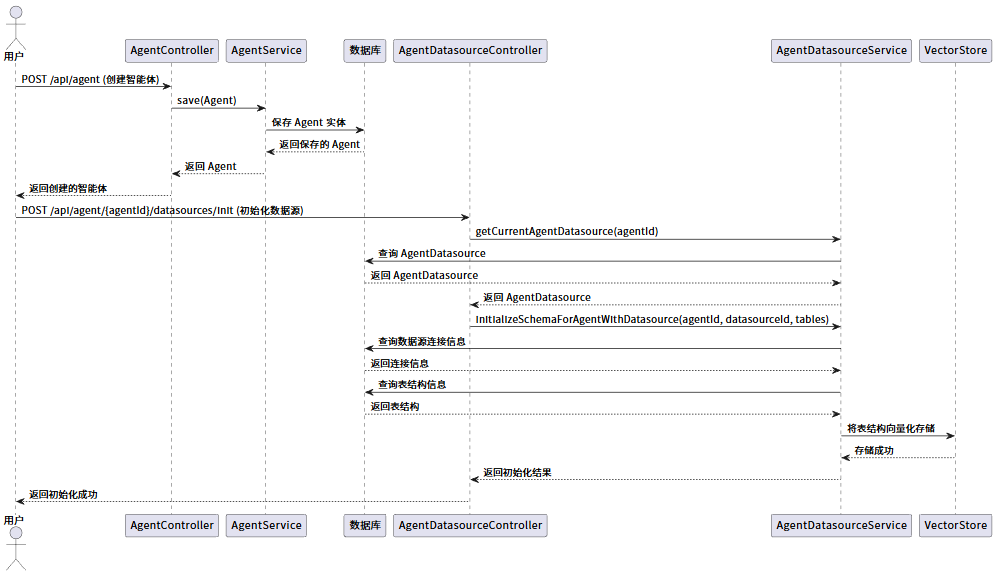
3.1 智能体创建和配置时序图
该时序图描述了用户创建一个新智能体,并为其初始化数据源、将数据库 Schema 同步至向量存储的全过程。
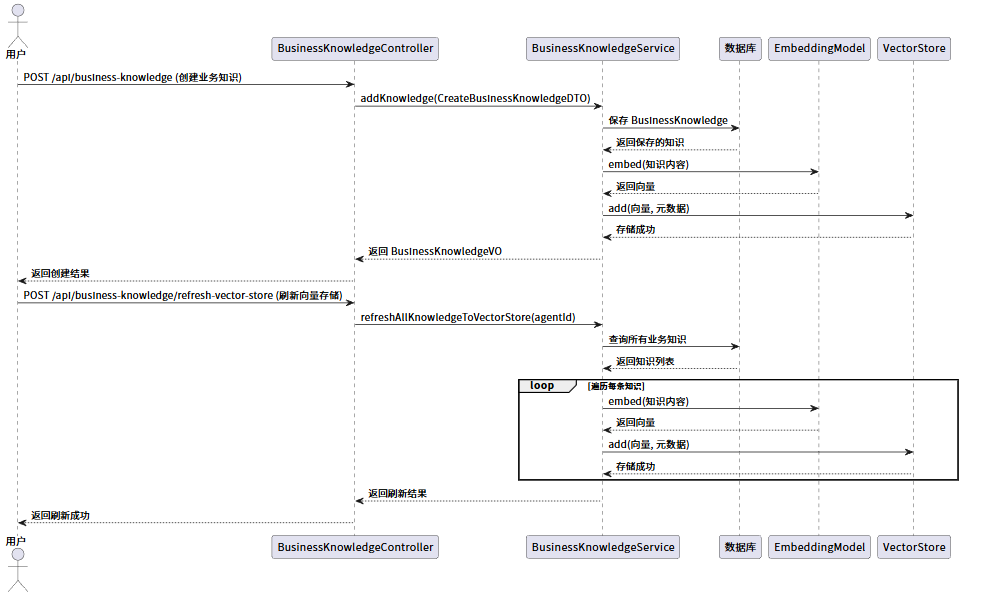
3.2 业务知识向量化时序图
本图展示了业务知识从录入到 Embedding 向量化,并最终持久化到向量数据库的流程,以及批量刷新向量库的操作逻辑。
4. 实现关键点说明
4.1 Spring Boot 自动配置机制
DataAgent 深度集成了 Spring Boot 的自动配置特性。DataAgentConfiguration 通过 @Configuration 和 @Bean 定义核心组件,利用 Spring 容器管理 Bean 的全生命周期。 技术要点包括:
- 使用 @ConditionalOnMissingBean 保证默认 Bean 的可覆盖性。
- 通过 @Primary 明确多实现下的注入优先级。
- 利用 @ConditionalOnProperty 实现基于配置文件的功能开关。
4.2 StateGraph 工作流构建
工作流引擎基于 StateGraph 进行声明式构建,通过链式调用编排复杂的业务逻辑:
StateGraph stateGraph = new StateGraph(NL2SQL_GRAPH_NAME, keyStrategyFactory)
.addNode(INTENT_RECOGNITION_NODE, nodeBeanUtil.getNodeBeanAsync(IntentRecognitionNode.class))
.addNode(EVIDENCE_RECALL_NODE, nodeBeanUtil.getNodeBeanAsync(EvidenceRecallNode.class))
.addEdge(START, INTENT_RECOGNITION_NODE)
.addConditionalEdges(INTENT_RECOGNITION_NODE, edge_async(new IntentRecognitionDispatcher()), ...)
核心机制:
- 异步节点加载:通过 NodeBeanUtil 实现节点的异步获取与依赖注入。
- 动态路由:支持普通边与条件边(Conditional Edge),利用 Dispatcher 根据运行时上下文决定流转路径。
- 流式执行:编译生成的 CompiledGraph 支持响应式流(Flux),适配实时交互场景。
4.3 向量存储集成
系统基于 Spring AI 的 VectorStore 接口实现了存储层的抽象,解耦了具体实现。默认提供内存态的 SimpleVectorStore,同时支持通过配置无缝切换至 Elasticsearch、PGVector 等生产级向量数据库。 技术细节:
- 向量化处理采用异步机制,避免阻塞主业务线程。
- 灵活的配置策略允许根据环境差异(开发/生产)动态选择存储介质。
4.4 多数据源支持
通过集成 Druid 连接池,系统实现了对多源异构数据库(MySQL, PostgreSQL, H2, 达梦等)的统一管理。 设计亮点:
- 动态配置:数据源配置持久化存储,支持运行时动态增删。
- 隔离性:每个 Agent 可绑定独立的数据源,实现租户级的数据隔离。
- 语义增强:Schema 初始化阶段自动提取表结构并向量化,为 NL2SQL 提供精准的上下文支持。
4.5 知识管理机制
业务知识与智能体知识均纳入向量化管理体系。系统利用 EmbeddingModel 将文本转化为向量存入 VectorStore,在查询时通过相似度匹配召回相关上下文。 优化策略:
- 异步写入:知识创建与向量生成解耦,提升前端响应速度。
- 批量同步:提供全量刷新接口,确保向量索引与数据库内容的一致性。
- RAG 增强:检索结果直接作用于 Prompt 构建,大幅提高 SQL 生成的准确率。
5. 总结说明
DataAgent 展现了清晰的分层架构设计,从入口引导、配置装配、服务实现到底层模型,职责边界明确。基于 模型(Agent, DataSource, Semantic Model, Business Knowledge)的核心实体设计,配合统一的 RESTful API,构建了稳健的后端基础。
系统采用 Spring AI Alibaba 的 StateGraph 作为工作流引擎,通过声明式编程实现了复杂分析流程的灵活编排。向量存储的深度集成赋予了系统语义理解能力,显著优化了 NL2SQL 的转化效果。同时,灵活的多数据源架构确保了系统能够适应多样化的企业级数据环境。
整体而言,DataAgent 的架构设计贯彻了高内聚、低耦合的工程原则,模块化程度高,易于维护与二次开发。结合 Spring Boot 强大的生态能力,系统不仅具备快速交付的能力,也为后续的智能化演进预留了广阔空间。



评论前必须登录!
注册