 网硕互联帮助中心
网硕互联帮助中心使用 Merge 节点可以在所有数据流的数据都可用时,合并来自多个流的数据。
0.194.0 版本重大变更
n8n 团队在 0.194.0 版本中全面改进了此节点。本文档反映的是该节点的最新版本。如果您使用的是旧版 n8n,可以查看此文档的历史版本。
1.49.0 版本次要变更
n8n 1.49.0 版本新增了支持两个以上输入的功能。旧版本仅支持最多两个输入。如果您运行的是旧版本并希望在这些版本中合并多个输入,请使用代码节点。
模式 > SQL 查询功能也是在 n8n 1.49.0 版本中添加的,旧版本不可用。
节点参数#
您可以通过选择模式来指定 Merge 节点应如何合并来自不同数据流的数据:
追加(Append)#
保留所有输入的数据。选择输入数量来依次输出每个输入的项目。节点会等待所有连接的输入执行完毕。
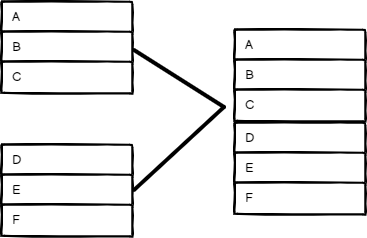
追加模式的输入和输出
组合(Combine)#
合并两个输入的数据。在组合方式中选择一个选项来决定如何合并输入数据。
字段匹配#
通过字段值比较项目。在待匹配字段中输入您想要比较的字段。
n8n 的默认行为是保留匹配项。您可以通过输出类型设置来改变这一行为:
- 保留匹配项:合并匹配的项目。类似于内连接(inner join)。
- 保留非匹配项:合并不匹配的项目。
- 保留所有项:合并匹配的项目并包含不匹配的项目。类似于全外连接(outer join)。
- 增强输入1:保留输入1的所有数据,并添加输入2的匹配数据。类似于左连接(left join)。
- 增强输入2:保留输入2的所有数据,并添加输入1的匹配数据。类似于右连接(right join)。
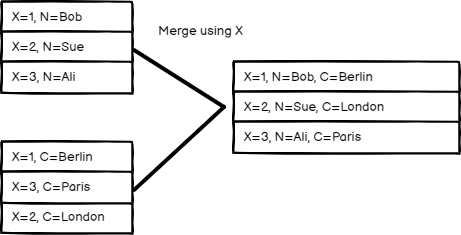
字段匹配模式的输入输出
位置匹配#
根据项目顺序进行合并。输入1中索引0的项目将与输入2中索引0的项目合并,依此类推。
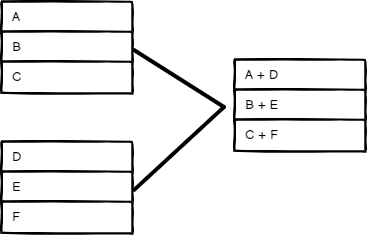
位置匹配模式的输入输出
全组合模式#
输出所有可能的项目组合,同时合并同名字段。
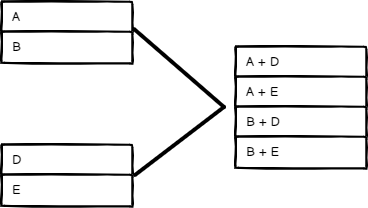
全组合模式的输入输出
合并模式选项#
当通过 模式 > 合并 方式合并数据时,您可以设置以下 选项:
- 冲突处理:选择当数据流冲突或存在子字段时的合并方式。详情请参阅冲突处理。
- 模糊比较:是否在比较字段时容忍类型差异(启用)或严格比较(禁用,默认)。例如启用时,n8n 会将 "3" 和 3 视为相同值。
- 禁用点表示法:阻止在字段名中使用 parent.child 形式访问子字段。
- 多重匹配:选择 n8n 在比较数据流时如何处理多个匹配项。
- 包含所有匹配项:如果存在多个匹配项,则输出多个条目,每个匹配项对应一个条目。
- 仅包含首个匹配项:保留每个匹配项的第一个条目,丢弃其余多个匹配项。
- 包含未配对项:选择在按位置合并时是否保留未配对项。默认行为是排除没有匹配项的条目。
冲突处理#
如果在同一索引位置的多项数据中存在同名字段,就会发生字段冲突。例如,如果输入1和输入2中的所有项目都有一个名为 language 的字段,这些字段就会发生冲突。默认情况下,n8n 会优先处理输入2,这意味着如果 language 在输入2中有值,n8n 在合并项目时会使用该值。
您可以通过选择 选项 > 冲突处理 来更改此行为:
- 当字段值冲突时:选择要优先处理的输入源,或选择 始终在字段名后添加输入编号 来保留所有字段和值,同时在字段名后附加输入编号以显示其来源。
- 嵌套字段合并
- 深度合并:合并项目所有层级的属性,包括嵌套对象。当处理复杂的嵌套数据结构时,这能确保合并所有层级的嵌套属性。
- 浅层合并:仅合并项目顶层的属性,不合并嵌套对象。适用于扁平数据结构或只需合并顶层属性而无需考虑嵌套属性的情况。
SQL 查询#
编写自定义 SQL 查询来合并数据。
示例:
| SELECT * FROM input1 LEFT JOIN input2 ON input1.name = input2.id |
来自先前节点的数据可作为表使用,您可以在 SQL 查询中按顺序将它们引用为 input1、input2、input3 等。完整支持的 SQL 语句列表请参考 AlaSQL GitHub 页面。
选择分支#
选择要保留的输入。此选项始终会等待两个输入的数据都可用。您可以选择 输出:
- 输入1数据
- 输入2数据
- 单个空条目
该节点会输出所选输入的数据,不做任何修改。
模板与示例#
Browse 合并节点 integration templates, or search all templates
合并数量不等的数据流#
传入 Merge 节点 Input 1 的数据项将优先处理。例如,如果 Merge 节点在 Input 1 收到 5 项数据,在 Input 2 收到 10 项数据,则只会处理 5 项数据。Input 2 中剩余的 5 项数据将不会被处理。
使用 If 和 Merge 节点的分支执行#
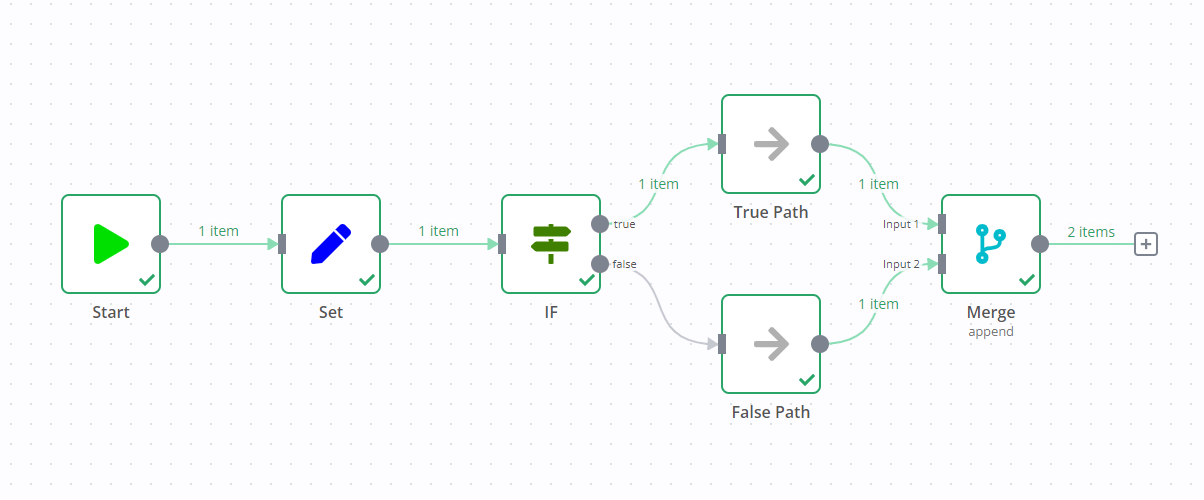
/// 信息 | 0.236.0 及以下版本 n8n 在 1.0 版本中移除了此执行行为。本节适用于使用 v0 (旧版) 工作流执行顺序的工作流。默认情况下,这包括所有在 1.0 版本之前构建的工作流。您可以在工作流设置中更改执行顺序。 /// 如果在包含 If 节点的工作流中添加 Merge 节点,可能会导致 If 节点的两个输出数据流都被执行。
一个数据流会触发 Merge 节点,然后 Merge 节点会去执行另一个数据流。
例如,在下方的截图中有一个包含 Edit Fields 节点、If 节点和 Merge 节点的工作流。If 节点的标准行为是只执行一个数据流(在截图中是 true 输出)。但由于 Merge 节点的存在,即使 If 节点没有向 false 数据流发送任何数据,两个数据流都会被执行。
动手实践:分步示例#
创建一个包含示例输入数据的工作流来体验 Merge 节点的功能。
使用 Code 节点设置示例数据#
| return [ { json: { name: 'Stefan', language: 'de', } }, { json: { name: 'Jim', language: 'en', } }, { json: { name: 'Hans', language: 'de', } } ]; |
| return [ { json: { greeting: 'Hello', language: 'en', } }, { json: { greeting: 'Hallo', language: 'de', } } ]; |
尝试不同的合并模式#
添加 Merge 节点。将第一个 Code 节点连接到 Input 1,第二个 Code 节点连接到 Input 2。运行工作流将数据加载到 Merge 节点中。
最终的工作流应如下所示:
Click to explore
View template details
现在尝试 Mode 中的不同选项,观察它们如何影响输出数据。
追加模式#
选择 Mode(模式) > Append(追加),然后选择 Execute step(执行步骤)。
表格视图中的输出结果应如下所示:
| Stefan | de | |
| Jim | en | |
| Hans | de | |
| en | Hello | |
| de | Hallo |
通过匹配字段合并#
您可以合并这两个数据输入,使每个人都能获得对应语言的正确问候语。
表格视图中的输出结果应如下所示:
| Stefan | de | Hallo |
| Jim | en | Hello |
| Hans | de | Hallo |
通过位置合并#
选择 Mode(模式) > Combine(合并),Combine by(合并方式) > Position(位置),然后选择 Execute step(执行步骤)。
表格视图中的输出结果应如下所示:
| Stefan | en | Hello |
| Jim | de | Hallo |
保留未匹配项#
如果您想保留所有项目,请选择 Add Option(添加选项) > Include Any Unpaired Items(包含未匹配项),然后开启 Include Any Unpaired Items(包含未匹配项)。
表格视图中的输出结果应如下所示:
| Stefan | en | Hello |
| Jim | de | Hallo |
| Hans | de |
按所有可能组合合并#
选择 模式 > 合并,合并方式 > 所有可能组合,然后选择 执行步骤。
表格视图中的输出应如下所示:
| Stefan | en | Hello |
| Stefan | de | Hallo |
| Jim | en | Hello |
| Jim | de | Hallo |
| Hans | en | Hello |
| Hans | de | Hallo |
大数据时代,掌握必要的数据分析能力,将大大提升你的工作效率和自身竞争力。PowerBI是一种常用的数据分析工具,本书将详细讲解利用PowerBI进行数据分析及可视化的相关知识。书中主要内容包括:PowerBI入门、数据集成、数据处理、基础操作、基础视觉对象、自定义视觉对象、数据分析表达式、创建数据报表、视觉对象开发、开发基于R的视觉对象等。本书内容丰富,采用双色印刷,配套视频讲解,结合随书附赠的素材边看边学边练,能够大大提高学习效率,迅速掌握PowerBI数据分析技能,并用于实践。本书适合数据分析初学者、初级数据分析师、数据库技术人员、市场营销人员、产品经理等自学使用。





评论前必须登录!
注册