 网硕互联帮助中心
网硕互联帮助中心摘要:本文深入剖析垂直领域SFT训练中的三大顽疾:模型复读、灾难性遗忘和过拟合。通过Y-Trainer框架及其核心NLIRG算法,构建一套可复现、可对照的训练流程。文末提供完整代码示例、效果验证方法及实用技巧,助你提升垂直领域模型训练效果。
一、痛点直击:垂直SFT训练中的"不可能三角"
在垂直领域大模型微调过程中,我们常常面临一个尴尬的"不可能三角":
-
专业性:需要模型深度掌握垂直领域知识
-
通用性:希望保留基础对话和常识能力
-
稳定性:要求输出格式规范、表达多样
当我们在一个角上发力,另外两个角往往会崩溃。你是否也经历过这些令人崩溃的场景?
-
专业精准,基础崩溃:模型能准确回答"劳动合同解除条件",却无法正常回应"你好",甚至将天气查询回答成法律条文
-
训练时完美,上线后复读:训练loss一路下降,上线后却反复使用相同句式,生成内容缺乏多样性,像一台复读机
-
数据质量敏感:一条错误标注或格式混乱的数据,可能导致整个模型能力崩塌
最令人沮丧的是:这些问题往往同时出现,且常规解决方案效果有限:
-
降低学习率?→ 专业能力提升受限
-
增加通用语料?→ 训练时间翻倍,专业性稀释
-
调整训练轮次?→ 今天好明天坏,效果不稳定
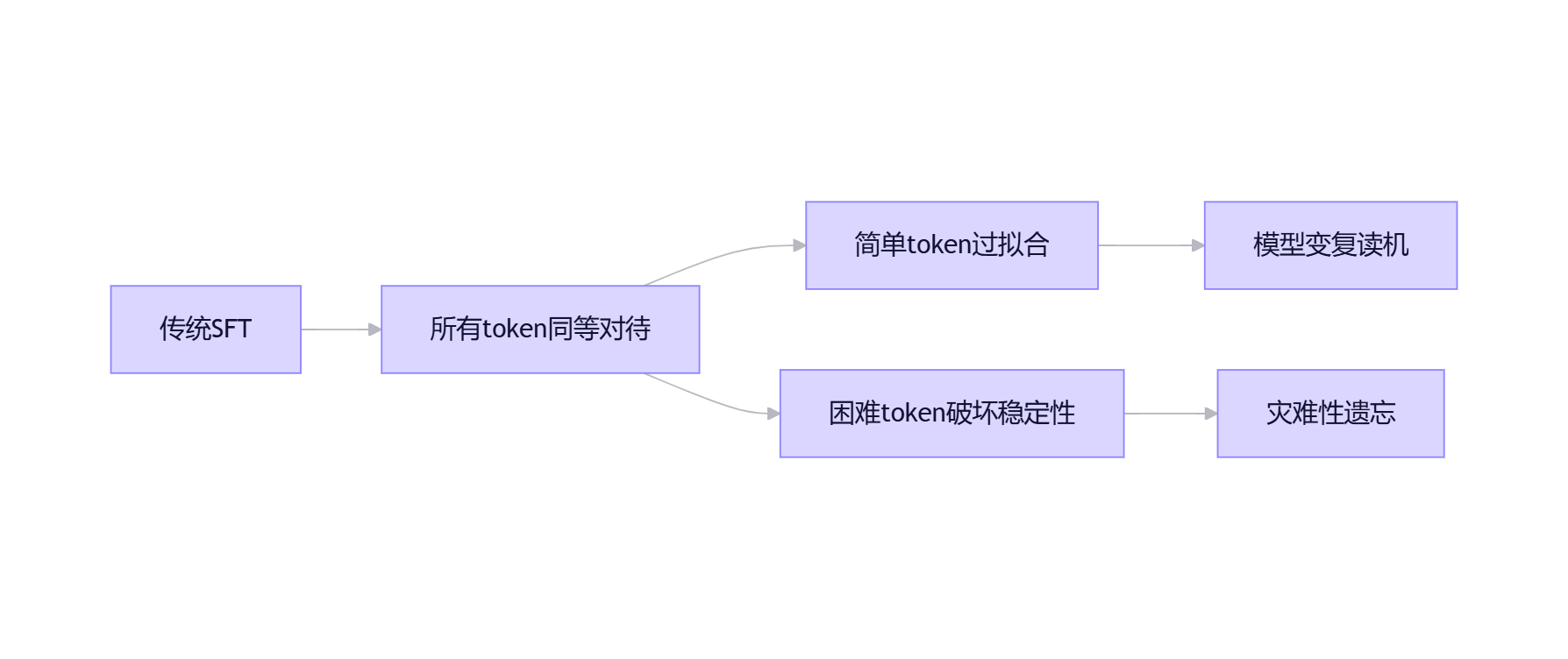
今天,我想和大家探讨一个可能被忽视的方向:训练信号的精细分配。不是所有token都值得同等对待,而Y-Trainer的NLIRG算法正是解决这一问题的利器。
二、问题根源:梯度分配不合理是元凶
2.1 被忽视的核心事实:SFT的梯度来源是token,不是样本
在指令微调中,真正驱动模型学习的是每个token产生的梯度,而非整个样本。一个样本中哪些token贡献大、哪些梯度更激进,直接决定了"模型在这一轮训练中到底学了什么"。
2.2 两大极端现象如何联手毁掉你的模型
现象1:大量低loss token反复出现
垂直数据往往存在强模板:法律文书的"根据《XX法》第X条"、医疗报告的"患者主诉…"、客服话术的"很抱歉给您带来不便"等。这些token在训练早期就进入低loss区间。如果继续以相同强度训练它们,模型会在"表面模式"上过拟合,导致:
-
生成内容模板化、缺乏多样性
-
同义改写、字段顺序变化等小改动导致输出漂移
-
信息密度下降,回答变长但内容空洞
现象2:少量高loss token触发过强更新
垂直数据中不可避免存在困难样本:专业术语拼写错误、长尾表达、噪声标注等。它们对应高loss token,产生更大梯度,迫使模型用大代价拟合少量异常信号,导致:
-
原有通用能力被挤压
-
训练过程不稳定,loss曲线波动剧烈
-
模型变得"偏科",失去基础对话能力
Y-Trainer官方文档一针见血地指出:
"灾难性遗忘通常是由过难语料导致,通过识别这些token,进行动态调整,可有效避免。过拟合是由相似语料或者模型已经掌握的知识导致,通过识别这些token,进行动态调整,可有效避免。"
三、传统解法的局限性:在"数据侧"修修补补
面对上述问题,业界常用解决方案及其局限性:
|
解决方案 |
优点 |
缺点 |
实际应用痛点 |
|
混合通用语料 |
保留基础能力 |
需要合规获取/清洗/维护通用数据;比例需反复调整 |
数据合规限制下无法使用外部通用语料 |
|
降低学习强度 |
缓解过拟合 |
专项能力提升受限;"既不够专业,也不够稳定" |
专业问题准确率显著下降 |
|
数据清洗规范 |
提高数据质量 |
无法解决"同一数据中哪些token应该学得更重" |
清洗多轮后仍需加入通用语料 |
这些方法本质上都是在"数据侧"补洞,而非在"信号侧"优化。就像给发烧病人盖被子,而非治疗病因。
Y-Trainer的定位提供新思路:
"无需依赖通用语料,即可卓越地保留模型的泛化能力,守住核心能力的同时实现专项提升!无需语料平衡,即使在语料分布很不均匀的情况下,依然能够稳定训练。"
四、NLIRG算法详解:为每个token精准分配"学习能量"
4.1 核心思想:用loss衡量难度,动态调整梯度
NLIRG(Nonlinear Learning Intensity Regulation,基于梯度的非线性学习强度调节)的核心思想非常直观:根据每个token的loss值,动态计算其梯度权重,实现"智能因材施教"。
def dynamic_sigmoid_batch(losses, max_lr=1.0, x0=1.2, min_lr=5e-8,
k=1.7, loss_threshold=3.0, loss_deadline=15.0):
"""
NLIRG核心算法:基于损失值的动态权重计算
参数说明:
– losses: 损失值张量 (shape: [batch_size, seq_len])
– max_lr: 最大学习率权重 (默认: 1.0),控制梯度增强上限
– x0: 第一个sigmoid函数的中心点 (默认: 1.2),决定低loss区间的分界
– min_lr: 最小学习率权重 (默认: 5e-8),防止完全阻断梯度
– k: sigmoid函数的斜率 (默认: 1.7),控制曲线陡峭程度
– loss_threshold: 损失阈值 (默认: 3.0),区分中等和困难区域
– loss_deadline: 损失上限 (默认: 15.0),超过此值梯度归零
返回:权重张量,用于调整反向传播的梯度
"""
关键点在于:这不是新的损失函数,而是对原有梯度进行的智能加权,实现训练哲学的转变——从"平均用力"到"精准投放"。
4.2 四段式梯度分配策略:科学应对不同难度token
Y-Trainer将loss分为四个区间,实施不同策略:
|
损失区间 |
梯度策略 |
训练目的 |
实际效果 |
|
loss ≤ 1.45 |
削减梯度 |
避免过拟合 |
防止模型过度记忆简单样本,减少复读现象 |
|
1.45 < loss < 6.6 |
增强梯度 |
高效学习 |
重点攻克有价值样本,提升学习效率 |
|
6.6 < loss < 15 |
削减梯度 |
稳定训练 |
防止困难样本带偏模型,保护已有能力 |
|
loss ≥ 15.0 |
梯度归零 |
隔离噪声 |
忽略明显错误样本,避免训练崩坏 |
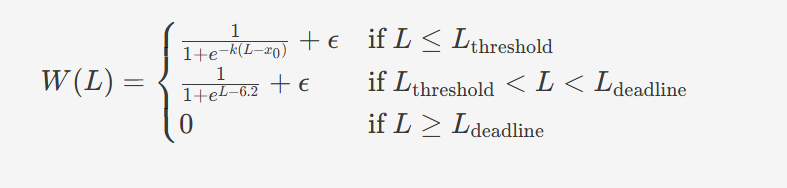
NLIRG权重计算公式,L为损失值,W(L)为对应权重
关键洞察:中等难度token(1.45 < loss < 6.6)才是真正的"价值洼地",值得分配更多"学习能量"。这与人类学习规律一致:太简单的内容无需反复练习,太难的内容暂时放弃,中等难度的内容最能促进能力提升。
五、实战指南:三步搭建可对照的训练流程
5.1 环境准备(5分钟快速上手)
# 克隆代码
git clone https://github.com/yafo-ai/y-trainer.git
cd y-trainer
# 安装依赖(单卡环境可不装deepspeed)
# 注意:官方文档中peft包名有断行,实际应为peft>=0.10.0
pip install torch peft>=0.10.0 tensorboard matplotlib
pip install -r requirements.txt
# 建议Python 3.8+环境
python –version
环境配置技巧:
-
单卡训练:无需安装deepspeed,节省配置时间
-
显存<24GB:务必开启LoRA,否则可能OOM
-
梯度检查点:显存紧张时添加–enable_gradit_checkpoing 'true'参数
5.2 垂直SFT训练(单卡LoRA方案)
python -m training_code.start_training \\
–model_path_to_load Qwen/Qwen3-1.5B \\ # 基础模型路径,可替换为本地路径
–training_type 'sft' \\ # 训练类型:sft(指令微调)/cpt(继续预训练)
–use_NLIRG 'true' \\ # 核心算法开关,true为开启
–use_lora 'true' \\ # LoRA开关,显存不足必开
–lora_target_modules "q_proj,k_proj,v_proj,o_proj,gate_proj,up_proj,down_proj" \\
–batch_size 1 \\ # 单卡通常设为1
–token_batch 10 \\ # SFT关键参数!控制每次反向传播的token数
–epoch 3 \\ # 训练轮次,建议3-5轮
–data_path your_vertical_data.json \\ # 你的垂直数据路径
–output_dir results_sft \\ # 输出目录
–checkpoint_epoch '0,1' # 保存检查点的轮次,如'0,1,2'
参数详解(针对SFT场景):
-
–token_batch:SFT训练的核心参数,控制每次反向传播的token数量。值越小,token loss计算越精确,NLIRG效果越好,但训练速度越慢。官方推荐默认值10
-
–use_NLIRG:默认为true,做对照实验时务必显式设置为false
-
–lora_target_modules:LoRA适配的模块,对Qwen系列模型使用上述配置
5.3 大型CPT训练(多卡全量方案)
deepspeed –master_port 29501 –include localhost:0,1,2,3 \\
–module training_code.start_training \\
–model_path_to_load Qwen/Qwen3-8B \\
–training_type 'cpt' \\
–use_NLIRG 'true' \\
–use_deepspeed 'true' \\ # 启用DeepSpeed
–pack_length 2048 \\ # 文本打包长度,短文本训练必设
–batch_size 2 \\
–epoch 3 \\
–data_path domain_corpus.json \\
–output_dir results_cpt
多卡训练注意事项:
-
DeepSpeed配置:官方支持Stage3,节省显存
-
文本打包:通过–pack_length将短文本合并,提高训练效率
-
主节点端口:–master_port需确保未被占用
六、效果验证:不要只看loss,建立科学评估体系
6.1 对照实验设计
# Baseline(关闭NLIRG)
python -m training_code.start_training \\
–use_NLIRG 'false' \\ # 显式关闭NLIRG
–model_path_to_load Qwen/Qwen3-1.5B \\
–training_type 'sft' \\
–use_lora 'true' \\
–batch_size 1 \\
–token_batch 10 \\
–data_path your_data.json \\
–output_dir baseline_results
# 实验组(开启NLIRG)
python -m training_code.start_training \\
–use_NLIRG 'true' \\ # 显式开启NLIRG
–model_path_to_load Qwen/Qwen3-1.5B \\
–training_type 'sft' \\
–use_lora 'true' \\
–batch_size 1 \\
–token_batch 10 \\
–data_path your_data.json \\
–output_dir nlirg_results
关键提示:Y-Trainer默认开启NLIRG,做对照实验时务必显式设置–use_NLIRG 'false',避免误判。所有其他参数必须保持一致,确保实验公平性。
6.2 评估指标体系(三维度验证)
不要只看训练loss!建立三维度评估体系:
|
评估维度 |
具体指标 |
评估方法 |
重要性 |
|
领域能力 |
任务准确率、业务规则遵循度 |
垂直任务测试集(200+样本) |
★★★ |
|
通用能力 |
指令遵循率、基础对话质量、常识问答正确率 |
通用回归测试集(100+样本) |
★★☆ |
|
输出质量 |
重复率(3-gram)、信息密度、格式稳定性 |
自动化脚本+人工抽样(50+样本) |
★★☆ |
评估工具推荐:
-
重复率计算:nltk.translate.bleu_score或自定义n-gram重复率
-
格式验证:编写正则表达式验证输出格式
-
人工评估:使用标注平台,让3位标注员对输出质量打分(1-5分)
6.3 训练过程可视化(TensorBoard监控)
# 训练时启用TensorBoard
python -m training_code.start_training \\
–use_tensorboard 'true' \\
–tensorboard_path ./logs \\
…其他参数…
# 启动可视化(新终端)
tensorboard –logdir=./logs –port=6006
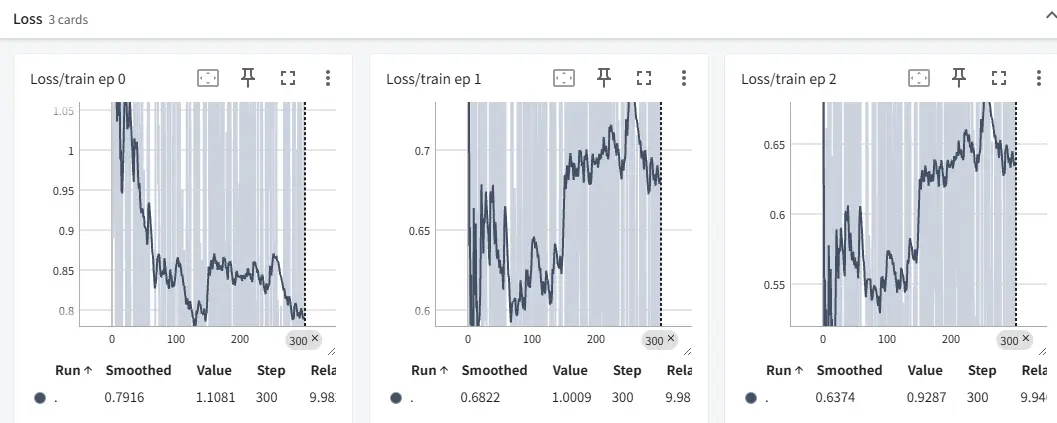
关键监控指标:
-
loss曲线:观察NLIRG是否使训练更稳定
-
梯度分布:验证不同loss区间token的梯度变化
-
验证集指标:及时发现过拟合迹象
七、高级技巧:提升训练效果的实用策略
7.1 语料质量预筛(训练前排雷)
在训练前,使用Y-Trainer的语料排序工具评估数据质量:
python -m training_code.utils.schedule.sort \\
–data_path raw_data.json \\
–output_path sorted_data.json \\
–model_path Qwen/Qwen3-8B \\
–mode "similarity_rank" # 基于曲线相似度的排序策略
算法原理:通过分析模型对每条语料的响应(损失值和熵的变化),计算语料难度评分
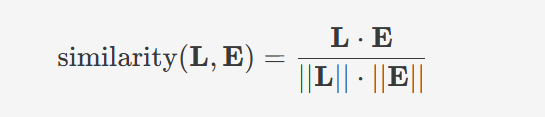
实用价值:
提前发现脏数据:低分语料往往是格式错误或内容错误,可优先修复
优化训练顺序:非简单"由易到难",而是智能混合,训练更稳定
节省训练资源:过滤掉明显错误的样本,减少无效训练
正如官方文档指出:
"再训练之前排查语料问题,检查得分较低的语料是否编写错误。平衡语料难易顺序,逐步训练。注意:简单的将语料从易到难进行训练,实际测试效果并不如混合进行。"
7.2 资源优化策略(面向不同硬件环境)
单卡<24GB显存配置:
–use_lora 'true' \\
–enable_gradit_checkpoing 'true' \\
–batch_size 1 \\
–token_batch 5 \\
–model_path_to_load Qwen/Qwen3-1.5B
单卡24GB+显存配置:
–use_lora 'true' \\
–batch_size 1 \\
–token_batch 10 \\
–model_path_to_load Qwen/Qwen3-7B
多卡训练(4xA100)配置:
–use_deepspeed 'true' \\
–batch_size 2 \\
–pack_length 2048 \\
–model_path_to_load Qwen/Qwen3-8B
关键原则:
-
token_batch值越小,NLIRG效果越好,但速度越慢
-
显存不足时,优先保证token_batch不低于5,再考虑降低batch_size
-
LoRA秩(rank)设置:垂直领域建议8-16,通用领域建议4-8
八、适用场景分析:什么情况下应该选择Y-Trainer?
8.1 适合场景(效果显著)
✅ 强垂直领域模型:法律、医疗、金融等需要专业性,同时保留基础能力的场景
✅ 数据质量参差不齐:NLIRG的高loss归零机制能有效隔离噪声样本
✅ 资源有限环境:单卡/小集群训练,需要LoRA和显存优化支持
✅ 快速迭代需求:无需反复调整数据比例,节省调参时间
8.2 不适合场景(效果有限)
❌ 通用聊天机器人训练:本身就是混合语料,NLIRG优势不明显
❌ 极大规模集群训练(>64卡):可能需要定制分布式策略
❌ 数据已高度优化:如果数据已经经过严格清洗和平衡,收益可能有限
结语
垂直SFT训练的困境,本质是梯度分配的粗放管理。Y-Trainer通过NLIRG算法,将训练强度控制从"样本级"推进到"token级",就像从"大水漫灌"到"精准滴灌"的农业变革。
我的建议行动路径:
先验证再投入:用你的垂直数据跑一次最简对照实验(开启/关闭NLIRG)
建立评估体系:创建通用能力回归测试集,监控模型整体健康度
逐步应用高级功能:从基础NLIRG到语料排序,再到资源优化
记录迭代过程:保存每次实验的配置和结果,形成团队知识库
正如Y-Trainer官方文档所强调:
"Y-Trainer算法通过模型内部信号,可以对语料进行质量评分,提早排查错误。传统的SFT通常需要混合一定比例通用语料,防止模型能力退化,Y-Trainer算法可在只使用垂直领域语料的情况下训练,并取得更好的效果。"
告别数据平衡的噩梦,重获训练掌控权。在这个大模型应用爆发的时代,掌握高效的训练方法比盲目堆砌算力更重要。你准备好告别"复读机"模型了吗?
资源推荐
-
官方文档:最权威的使用指南
-
核心算法详解:NLIRG数学原理
-
快速开始示例:5分钟上手
-
GitHub仓库:源代码与issue讨论
互动讨论
你在垂直SFT训练中遇到过哪些问题?NLIRG算法对你有哪些启发?欢迎在评论区分享你的经验和疑问,一起探讨大模型训练的最佳实践!
#LLM #模型训练 #SFT #AI工程化 #YTrainer




评论前必须登录!
注册