 网硕互联帮助中心
网硕互联帮助中心0. 前言
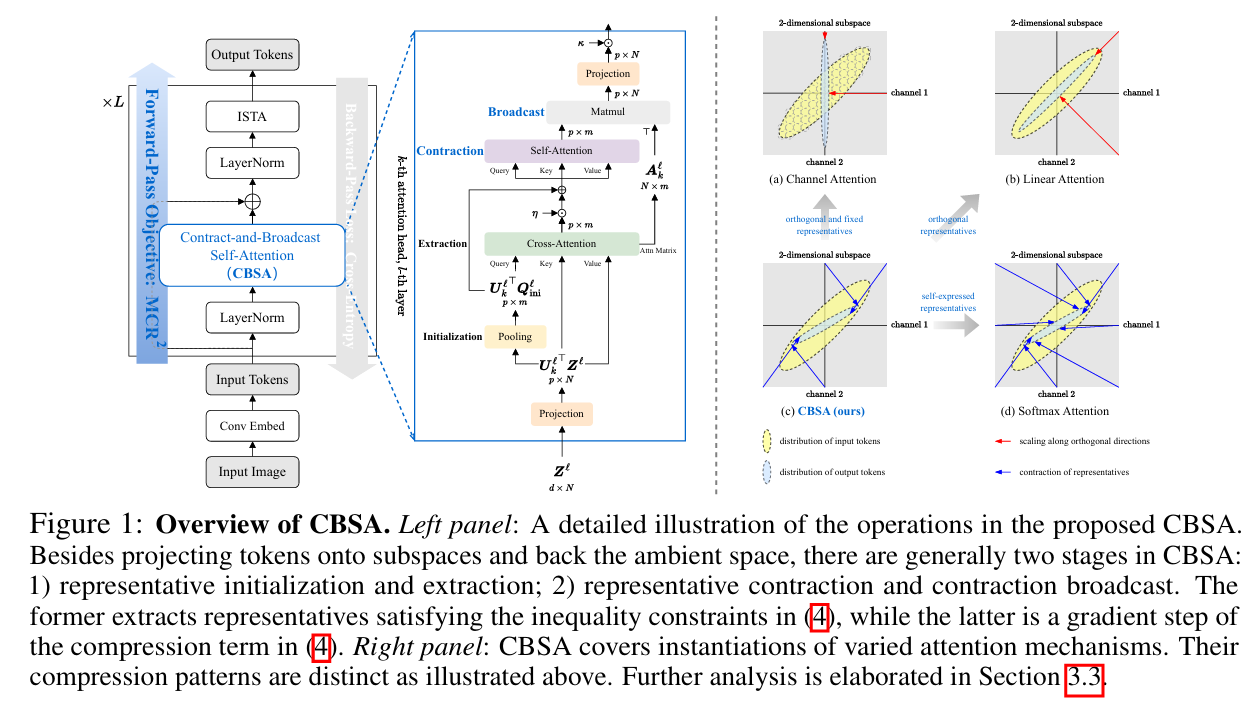
本文介绍CBSA收缩 – 广播自注意力机制(Contract-and-Broadcast Self-Attention),并将其集成到ultralytics最新发布的YOLO26目标检测算法中,构建C3k2-LWGA创新模块。传统注意力机制存在黑盒难理解、计算复杂度高的问题,CBSA通过算法展开推导出本质上可解释且高效的注意力机制。它先从输入数据中选出少量代表性tokens,接着对代表进行收缩计算,再将结果广播给所有原始数据。该机制计算量线性增长,具有明确数学解释,还能统一多种注意力机制。
1. CBSA自注意力机制简介
注意力机制在多个领域取得了显著的实证成功,但它们的基础优化目标仍不明确。此外,自注意力的二次复杂度变得越来越难以承受。虽然可解释性和效率是两个相互促进的追求,但先前的工作通常分开研究它们。在本文中,我们提出了一个统一的优化目标,通过算法展开推导出本质上可解释且高效的注意力机制。具体而言,我们构建了所提出目标的一个梯度步骤,其中包含我们的收缩-广播自注意力(CBSA)的一系列前向传递操作,该机制通过收缩输入标记的少量代表来将输入标记压缩到低维结构。这种新颖的机制不仅可以通过固定代表数量来实现线性扩展,还可以在使用不同代表集时涵盖各种注意力机制的实例化。我们进行了广泛的实验,证明了与黑盒注意力机制相比,在视觉任务上具有可比的性能和优越的优势。我们的工作阐明了可解释性和效率的整合,以及注意力机制的统一公式。

原始论文:https://arxiv.org/pdf/2509.16875
原始代码:https://github.com/QishuaiWen/CBSA
2. 基本原理与创新点
一、核心定位:给注意力机制“拆黑盒、提速度、做统一”
传统注意力机制(比如Transformer里的softmax注意力)有两个大问题:
之前的研究要么只解决“理解”,要么只解决“速度”,CBSA则想一次性搞定——既让注意力机制的工作过程“说得通”,又让它“跑得飞快”,甚至还能把不同类型的注意力(比如softmax注意力、线性注意力)统一成一个框架。
二、设计逻辑:“抓少数代表,搞定所有数据”
CBSA的核心思路特别像“老师批改作业”:不用逐题看每个学生的作业,先挑几个有代表性的同学(比如中等水平、能反映全班共性问题的),只批改这几个“代表”的作业,再把批改思路告诉全班,大家各自修正。具体分两步:
三、关键优势:又快、又懂、还“万能”
万能:能统一所有经典注意力。最厉害的是,CBSA能“变”成其他注意力机制——只要换不同的“代表”选择方式:选“所有数据当代表”,CBSA就等同于传统的softmax注意力;选“正交的代表”(比如数据的主方向),CBSA就变成线性注意力;选“固定方向的代表”,CBSA就变成通道注意力(比如SE、CBAM里的通道优化)。相当于给不同的注意力机制找了个“统一公式”,能清晰看到它们的本质区别(只是“代表”的选择方式不同)。
3. 具体改进步骤
🍀🍀步骤1:创建C3k2_CBSA.py文件
在ultralytics\\nn\\modules\\目录下,新建一个C3k2_CBSA.py文件
然后,把以下C3k2_CBSA模块核心代码拷入进去:
# https://github.com/QishuaiWen/CBSA
import torch
from torch import nn
from einops import rearrange, repeat
class TSSA(nn.Module):
# https://github.com/RobinWu218/ToST/blob/main/tost_vision/tost.py
def __init__(self, dim, heads, dim_head):
super().__init__()
num_heads = heads
self.heads = num_heads
self.attend = nn.Softmax(dim=1)
self.qkv = nn.Linear(dim, dim, bias=False)
self.temp = nn.Parameter(torch.ones(num_heads, 1))
self.to_out = nn.Linear(dim, dim)
self.scale = dim_head ** -0.5
def forward(self, x, return_attn=False):
w = rearrange(self.qkv(x), 'b n (h d) -> b h n d', h=self.heads)
b, h, N, d = w.shape
if return_attn:
dots = w @ w.transpose(-1, -2)
return self.attend(dots)
w_normed = torch.nn.functional.normalize(w, dim=-2)
w_sq = w_normed ** 2
# Pi from Eq. 10 in the paper
Pi = self.attend(torch.sum(w_sq, dim=-1) * self.temp) # b * h * n
dots = torch.matmul((Pi / (Pi.sum(dim=-1, keepdim=True) + 1e-8)).unsqueeze(-2), w ** 2)
attn = 1. / (1 + dots)
out = -torch.mul(w.mul(Pi.unsqueeze(-1)), attn)
out = rearrange(out, 'b h n d -> b n (h d)')
return self.to_out(out)
@torch.jit.ignore
def no_weight_decay(self):
return {'temp'}
class MSSA(nn.Module):
# https://github.com/Ma-Lab-Berkeley/CRATE/blob/main/model/crate.py
def __init__(self, dim, heads=8, dim_head=64):
super().__init__()
inner_dim = dim_head * heads
project_out = not (heads == 1 and dim_head == dim)
self.heads = heads
self.scale = dim_head ** -0.5
self.attend = nn.Softmax(dim=-1)
self.qkv = nn.Linear(dim, inner_dim, bias=False)
self.to_out = nn.Linear(inner_dim, dim)
def forward(self, x, return_attn=False):
w = rearrange(self.qkv(x), 'b n (h d) -> b h n d', h=self.heads)
dots = torch.matmul(w, w.transpose(-1, -2)) * self.scale
attn = self.attend(dots)
if return_attn:
return attn
out = torch.matmul(attn, w)
out = rearrange(out, 'b h n d -> b n (h d)')
return self.to_out(out)
class CBSA(nn.Module):
"""
Cross-Block Self-Attention module.
Adapted to work with 2D feature maps (B, C, H, W) instead of sequences.
"""
def __init__(self, dim, heads=8, dim_head=64):
super().__init__()
inner_dim = heads * dim_head
self.heads = heads
self.dim_head = dim_head
self.scale = dim_head ** -0.5
self.attend = nn.Softmax(dim=-1)
self.proj = nn.Linear(dim, inner_dim, bias=False)
self.step_x = nn.Parameter(torch.randn(heads, 1, 1))
self.step_rep = nn.Parameter(torch.randn(heads, 1, 1))
self.to_out = nn.Linear(inner_dim, dim)
self.pool = nn.AdaptiveAvgPool2d(output_size=(8, 8))
self.qkv = nn.Identity()
def attention(self, query, key, value):
dots = (query @ key.transpose(-1, -2)) * self.scale
attn = self.attend(dots)
out = attn @ value
return out, attn
def forward(self, x, return_attn=False):
"""
Forward pass for CBSA.
Args:
x: Input tensor of shape (B, C, H, W) – 2D feature map
return_attn: Whether to return attention weights
Returns:
Output tensor of shape (B, C, H, W) – 2D feature map
"""
b, c, h, w = x.shape
width = w # avoid name collision with projected tensor
n = h * w
inner_dim = self.heads * self.dim_head
# Convert 2D feature map to sequence format: (B, C, H, W) -> (B, H*W, C)
x_seq = rearrange(x, 'b c h w -> b (h w) c')
# Project to inner dimension
proj = self.proj(x_seq) # (B, n, inner_dim)
self.qkv(proj)
# Create representation tokens using pooling
# Use full feature map to avoid shape mismatch; pool to fixed 8×8 tokens
if n > 1:
proj_2d = proj.reshape(b, h, width, inner_dim).permute(0, 3, 1, 2) # (B, inner_dim, h, w)
rep = self.pool(proj_2d) # (B, inner_dim, 8, 8)
rep = rep.reshape(b, inner_dim, -1).permute(0, 2, 1) # (B, 64, inner_dim)
else:
# Handle edge case when H*W = 1
rep = proj.reshape(b, 1, inner_dim).repeat(1, 64, 1) # (B, 64, inner_dim) – repeat single token
# Reshape for attention
proj = proj.reshape(b, n, self.heads, self.dim_head).permute(0, 2, 1, 3) # (B, heads, n, dim_head)
rep = rep.reshape(b, 64, self.heads, self.dim_head).permute(0, 2, 1, 3) # (B, heads, 64, dim_head)
# Cross attention: rep attends to w
rep_delta, attn = self.attention(rep, proj, proj)
if return_attn:
return attn.transpose(-1, -2) @ attn
# Update representation
rep = rep + self.step_rep * rep_delta
# Self attention on representation
x_delta, _ = self.attention(rep, rep, rep)
x_delta = attn.transpose(-1, -2) @ x_delta
x_delta = self.step_x * x_delta
# Reshape back to sequence: (B, heads, n, dim_head) -> (B, n, heads*dim_head)
x_delta = rearrange(x_delta, 'b h n k -> b n (h k)')
x_out = self.to_out(x_delta)
# Convert back to 2D feature map: (B, H*W, C) -> (B, C, H, W)
x_out = rearrange(x_out, 'b (h w) c -> b c h w', h=h, w=w)
return x_out
def autopad(k, p=None, d=1): # kernel, padding, dilation
"""Pad to 'same' shape outputs."""
if d > 1:
k = d * (k – 1) + 1 if isinstance(k, int) else [d * (x – 1) + 1 for x in k] # actual kernel-size
if p is None:
p = k // 2 if isinstance(k, int) else [x // 2 for x in k] # auto-pad
return p
class Conv(nn.Module):
default_act = nn.SiLU() # default activation
def __init__(self, c1, c2, k=1, s=1, p=None, g=1, d=1, act=True):
super().__init__()
self.conv = nn.Conv2d(c1, c2, k, s, autopad(k, p, d), groups=g, dilation=d, bias=False)
self.bn = nn.BatchNorm2d(c2)
self.act = self.default_act if act is True else act if isinstance(act, nn.Module) else nn.Identity()
def forward(self, x):
return self.act(self.bn(self.conv(x)))
def forward_fuse(self, x):
return self.act(self.conv(x))
class Bottleneck(nn.Module):
"""Standard bottleneck."""
def __init__(
self, c1: int, c2: int, shortcut: bool = True, g: int = 1, k: tuple[int, int] = (3, 3), e: float = 0.5
):
super().__init__()
c_ = int(c2 * e) # hidden channels
self.cv1 = Conv(c1, c_, k[0], 1)
self.cv2 = Conv(c_, c2, k[1], 1, g=g)
self.add = shortcut and c1 == c2
def forward(self, x: torch.Tensor) -> torch.Tensor:
"""Apply bottleneck with optional shortcut connection."""
return x + self.cv2(self.cv1(x)) if self.add else self.cv2(self.cv1(x))
class Attention(nn.Module):
def __init__(self, dim: int, num_heads: int = 8, attn_ratio: float = 0.5):
super().__init__()
self.num_heads = num_heads
self.head_dim = dim // num_heads
self.key_dim = int(self.head_dim * attn_ratio)
self.scale = self.key_dim**-0.5
nh_kd = self.key_dim * num_heads
h = dim + nh_kd * 2
self.qkv = Conv(dim, h, 1, act=False)
self.proj = Conv(dim, dim, 1, act=False)
self.pe = Conv(dim, dim, 3, 1, g=dim, act=False)
def forward(self, x: torch.Tensor) -> torch.Tensor:
B, C, H, W = x.shape
N = H * W
qkv = self.qkv(x)
q, k, v = qkv.view(B, self.num_heads, self.key_dim * 2 + self.head_dim, N).split(
[self.key_dim, self.key_dim, self.head_dim], dim=2
)
attn = (q.transpose(-2, -1) @ k) * self.scale
attn = attn.softmax(dim=-1)
x = (v @ attn.transpose(-2, -1)).view(B, C, H, W) + self.pe(v.reshape(B, C, H, W))
x = self.proj(x)
return x
class C2f(nn.Module):
def __init__(self, c1: int, c2: int, n: int = 1, shortcut: bool = False, g: int = 1, e: float = 0.5):
super().__init__()
self.c = int(c2 * e) # hidden channels
self.cv1 = Conv(c1, 2 * self.c, 1, 1)
self.cv2 = Conv((2 + n) * self.c, c2, 1) # optional act=FReLU(c2)
self.m = nn.ModuleList(Bottleneck(self.c, self.c, shortcut, g, k=((3, 3), (3, 3)), e=1.0) for _ in range(n))
def forward(self, x: torch.Tensor) -> torch.Tensor:
"""Forward pass through C2f layer."""
y = list(self.cv1(x).chunk(2, 1))
y.extend(m(y[-1]) for m in self.m)
return self.cv2(torch.cat(y, 1))
def forward_split(self, x: torch.Tensor) -> torch.Tensor:
"""Forward pass using split() instead of chunk()."""
y = self.cv1(x).split((self.c, self.c), 1)
y = [y[0], y[1]]
y.extend(m(y[-1]) for m in self.m)
return self.cv2(torch.cat(y, 1))
class C3(nn.Module):
"""CSP Bottleneck with 3 convolutions."""
def __init__(self, c1: int, c2: int, n: int = 1, shortcut: bool = True, g: int = 1, e: float = 0.5):
super().__init__()
c_ = int(c2 * e) # hidden channels
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c1, c_, 1, 1)
self.cv3 = Conv(2 * c_, c2, 1) # optional act=FReLU(c2)
self.m = nn.Sequential(*(Bottleneck(c_, c_, shortcut, g, k=((1, 1), (3, 3)), e=1.0) for _ in range(n)))
def forward(self, x: torch.Tensor) -> torch.Tensor:
"""Forward pass through the CSP bottleneck with 3 convolutions."""
return self.cv3(torch.cat((self.m(self.cv1(x)), self.cv2(x)), 1))
class PSABlock(nn.Module):
def __init__(self, c: int, attn_ratio: float = 0.5, num_heads: int = 4, shortcut: bool = True) -> None:
super().__init__()
self.attn = Attention(c, attn_ratio=attn_ratio, num_heads=num_heads)
self.ffn = nn.Sequential(Conv(c, c * 2, 1), Conv(c * 2, c, 1, act=False))
self.add = shortcut
def forward(self, x: torch.Tensor) -> torch.Tensor:
x = x + self.attn(x) if self.add else self.attn(x)
x = x + self.ffn(x) if self.add else self.ffn(x)
return x
class C3k2(C2f):
def __init__(
self,
c1: int,
c2: int,
n: int = 1,
c3k: bool = False,
e: float = 0.5,
attn: bool = False,
g: int = 1,
shortcut: bool = True,
):
super().__init__(c1, c2, n, shortcut, g, e)
self.m = nn.ModuleList(
nn.Sequential(
Bottleneck(self.c, self.c, shortcut, g),
PSABlock(self.c, attn_ratio=0.5, num_heads=max(self.c // 64, 1)),
)
if attn
else C3k(self.c, self.c, 2, shortcut, g)
if c3k
else Bottleneck(self.c, self.c, shortcut, g)
for _ in range(n)
)
class C3k(C3):
def __init__(self, c1: int, c2: int, n: int = 1, shortcut: bool = True, g: int = 1, e: float = 0.5, k: int = 3):
super().__init__(c1, c2, n, shortcut, g, e)
c_ = int(c2 * e) # hidden channels
# self.m = nn.Sequential(*(RepBottleneck(c_, c_, shortcut, g, k=(k, k), e=1.0) for _ in range(n)))
self.m = nn.Sequential(*(Bottleneck(c_, c_, shortcut, g, k=(k, k), e=1.0) for _ in range(n)))
class C3k_CBSA(C3k):
def __init__(self, c1, c2, n=1, shortcut=False, g=1, e=0.5, k=3, heads=8, dim_head=64):
super().__init__(c1, c2, n, shortcut, g, e, k)
c_ = int(c2 * e) # hidden channels
self.m = nn.Sequential(*(CBSA(c_, heads=heads, dim_head=dim_head) for _ in range(n)))
class C3k2_CBSA(C3k2):
def __init__(
self,
c1: int,
c2: int,
n: int = 1,
c3k: bool = False,
e: float = 0.5,
attn: bool = False,
g: int = 1,
shortcut: bool = True,
heads=8,
dim_head=64
):
super().__init__(c1, c2, n, shortcut, g, e)
if attn:
print(attn , 'attn=True 注意力模式 – 使用CBSA + Bottleneck')
# 优先级1:attn=True 注意力模式 – 使用使用CBSA + Bottleneck,这里可以自行组合试试看
self.m = nn.ModuleList(
nn.Sequential(
Bottleneck(self.c, self.c, shortcut, g),
CBSA(self.c, heads=heads, dim_head=dim_head),
# C3k_CBSA(self.c, self.c, shortcut, g, e=1.0),
# PSABlock(self.c, attn_ratio=0.5, num_heads=max(self.c // 64, 1)),
)
for _ in range(n)
)
elif c3k:
print(c3k,'c3k=True C3k模式 – 使用C3k_CBSA代替C3k')
# 优先级2:c3k=True C3k模式 – 使用C3k_CBSA代替C3k
self.m = nn.ModuleList(
C3k_CBSA(self.c, self.c, 2, shortcut, g)
for _ in range(n)
)
else:
print(c3k,'c3k=False 基础模式 – 使用C3k_CBSA代替Bottleneck')
# 优先级3:c3k=False 基础模式 – 使用C3k_CBSA代替Bottleneck
self.m = nn.ModuleList(
C3k_CBSA(self.c, self.c, shortcut, g, e=1.0)
for _ in range(n)
)
🍀🍀步骤2:tasks.py文件修改
首先,在ultralytics/nn/tasks.py代码最前端导入C3k2_CBSA模块,代码如下:
from ultralytics.nn.modules.C3k2_CBSA import C3k2_CBSA
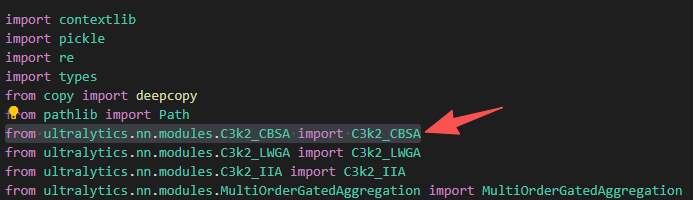
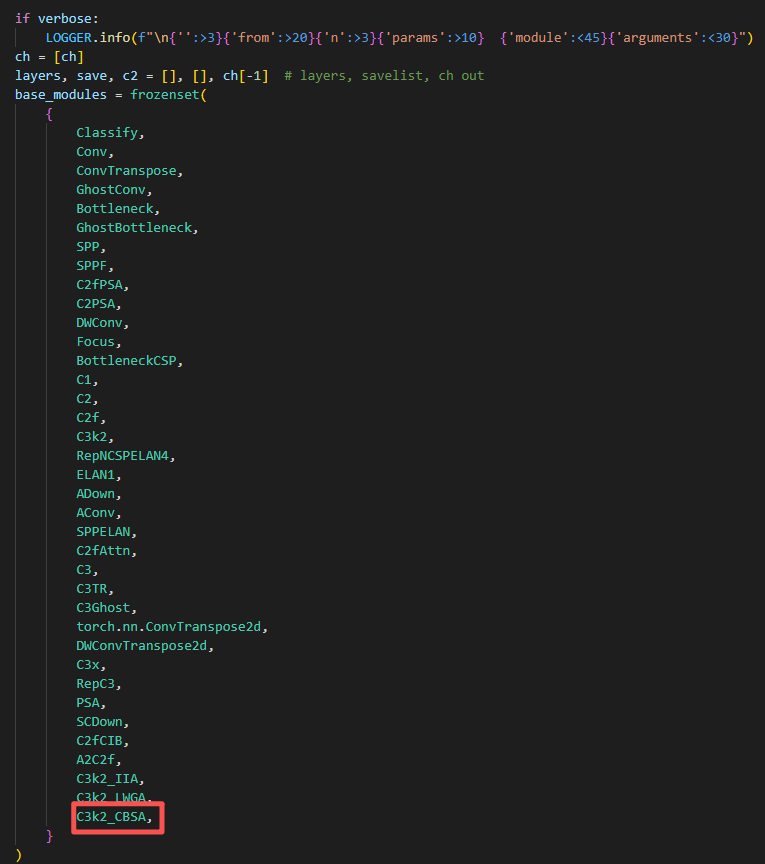
然后,tasks.py文件中找到parse_model函数(ctrl+f 可以直接搜索parse_model位置)导入C3k2_CBSA模块:1)base_modules部分;2)repeat_modules部分。
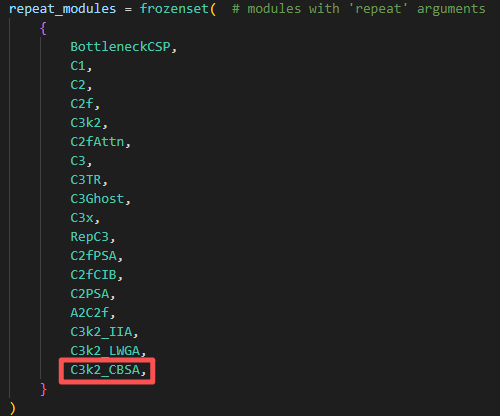
🍀🍀步骤3:创建YAML配置文件
以Ultralytics 公司于 2025 年 9 月发布的最新一代目标检测模型YOLO26为例(代码官方可下载,不然会报错),创建yolo26-C3k2_CBSA.yaml配置文件,代码如下:
# Ultralytics 🚀 AGPL-3.0 License – https://ultralytics.com/license
# Ultralytics YOLO26 object detection model with P3/8 – P5/32 outputs
# Model docs: https://docs.ultralytics.com/models/yolo26
# Task docs: https://docs.ultralytics.com/tasks/detect
# Parameters
nc: 80 # number of classes
end2end: True # whether to use end-to-end mode
reg_max: 1 # DFL bins
scales: # model compound scaling constants, i.e. 'model=yolo26n.yaml' will call yolo26.yaml with scale 'n'
# [depth, width, max_channels]
n: [0.50, 0.25, 1024] # summary: 260 layers, 2,572,280 parameters, 2,572,280 gradients, 6.1 GFLOPs
s: [0.50, 0.50, 1024] # summary: 260 layers, 10,009,784 parameters, 10,009,784 gradients, 22.8 GFLOPs
m: [0.50, 1.00, 512] # summary: 280 layers, 21,896,248 parameters, 21,896,248 gradients, 75.4 GFLOPs
l: [1.00, 1.00, 512] # summary: 392 layers, 26,299,704 parameters, 26,299,704 gradients, 93.8 GFLOPs
x: [1.00, 1.50, 512] # summary: 392 layers, 58,993,368 parameters, 58,993,368 gradients, 209.5 GFLOPs
# YOLO26n backbone
backbone:
# [from, repeats, module, args]
– [-1, 1, Conv, [64, 3, 2]] # 0-P1/2
– [-1, 1, Conv, [128, 3, 2]] # 1-P2/4
– [-1, 2, C3k2_CBSA, [256, False, 0.25]]
– [-1, 1, Conv, [256, 3, 2]] # 3-P3/8
– [-1, 2, C3k2_CBSA, [512, False, 0.25]]
– [-1, 1, Conv, [512, 3, 2]] # 5-P4/16
– [-1, 2, C3k2_CBSA, [512, True]]
– [-1, 1, Conv, [1024, 3, 2]] # 7-P5/32
– [-1, 2, C3k2_CBSA, [1024, True]]
– [-1, 1, SPPF, [1024, 5, 3, True]] # 9
– [-1, 2, C2PSA, [1024]] # 10
# YOLO26n head
head:
– [-1, 1, nn.Upsample, [None, 2, "nearest"]]
– [[-1, 6], 1, Concat, [1]] # cat backbone P4
– [-1, 2, C3k2_CBSA, [512, True]] # 13
– [-1, 1, nn.Upsample, [None, 2, "nearest"]]
– [[-1, 4], 1, Concat, [1]] # cat backbone P3
– [-1, 2, C3k2_CBSA, [256, True]] # 16 (P3/8-small)
– [-1, 1, Conv, [256, 3, 2]]
– [[-1, 13], 1, Concat, [1]] # cat head P4
– [-1, 2, C3k2_CBSA, [512, True]] # 19 (P4/16-medium)
– [-1, 1, Conv, [512, 3, 2]]
– [[-1, 10], 1, Concat, [1]] # cat head P5
– [-1, 1, C3k2_CBSA, [1024, True, 0.5, True]] # 22 (P5/32-large)
– [[16, 19, 22], 1, Detect, [nc]] # Detect(P3, P4, P5)
🍀🍀步骤4:新建train.py文件训练模型
import warnings
warnings.filterwarnings('ignore')
from ultralytics import YOLO
if __name__ == '__main__':
model = YOLO('ultralytics/cfg/models/26/yolo26-C3k2_CBSA.yaml') # 导入yaml配置文件
# model.load('yolo11n.pt') # loading pretrain weights
model.train(data='dataset/data.yaml',
cache=False,
imgsz=640,
epochs=300,
batch=32,
close_mosaic=0,
workers=4, # Windows下出现莫名其妙卡主的情况可以尝试把workers设置为0
# device='0',
optimizer='SGD', # using SGD
# patience=0, # set 0 to close earlystop.
# resume=True, # 断点续训,YOLO初始化时选择last.pt
# amp=False, # close amp
# fraction=0.2,
project='runs/train',
name='yolo26-C3k2_CBSA',
)
🍀🍀步骤5:模型结构打印结果
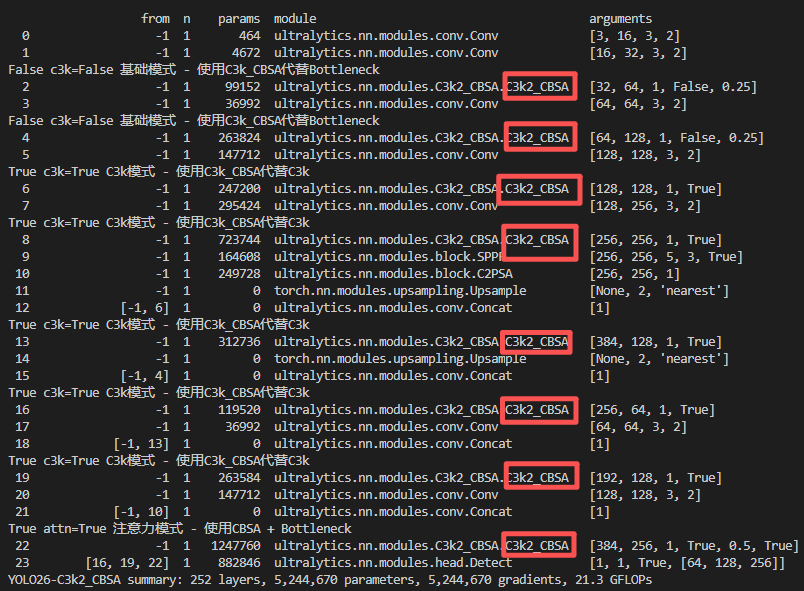




评论前必须登录!
注册