 网硕互联帮助中心
网硕互联帮助中心
导语:
在数据爆炸与通用人工智能(AGI)交织的今天,我们正站在从“数字化”向“语义化、智能化”转型的十字路口。
Palantir凭什么成为数据整合的王者,支撑起全球最复杂的数据治理体系?数字孪生如何摆脱“只有皮囊、没有灵魂”的建模瓶颈,真正具备“思考”能力?未来的网络安全与通信,又将如何被大模型(LLM)重塑,实现效率的指数级飞跃?
我们整理了这套包含14篇顶级学术与技术白皮书的资源包,并为每一篇准备了中文深度总结 PPT。这不仅仅是一堆 PDF,这是一套完整的、关于未来数字化基础设施的知识图谱。它锁定了当前技术领域最核心的四个关键词:Palantir架构(数据治理)、数字孪生(物理世界重构)、语义感知(通信进化)、大模型增强(LLM赋能)。
如果你是 AI 创业者、技术架构师,或者是关注数字化转型的决策者,这份包里隐藏着未来五年的技术风向标。
https://t.zsxq.com/bHLaD获取资源整合包
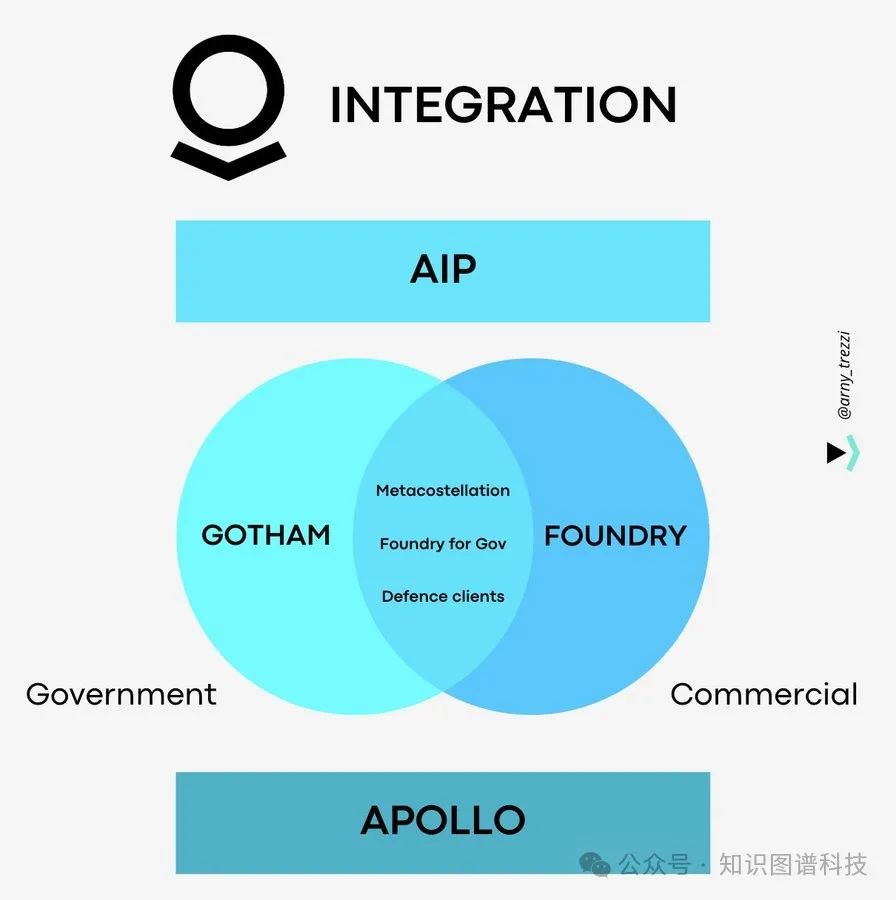
一、架构之王:Palantir的工程哲学与数据治理之道
Palantir 不仅是一家商业公司,更代表了一套极致的数据处理方法论。它解决的不是“如何存储数据”的问题,而是“如何让数据在最复杂的场景下,以最快的速度支撑决策”的问题。
1.1 Palantir:从工具到“数字平台”的理论升维
在《Data integration and analysis platforms as digital platforms》一文中,Palantir 被提升到了“数字平台”的理论高度 [1]。它超越了传统的数据仓库或 BI 工具,成为数字社会的基础设施。
【金句卡片:Palantir的本质】Palantir的核心价值在于其Foundry平台,它将数据、模型和业务逻辑无缝集成,形成一个可操作的“数字操作系统”。它不是一个简单的工具,而是一个定义未来数据治理规范的平台。
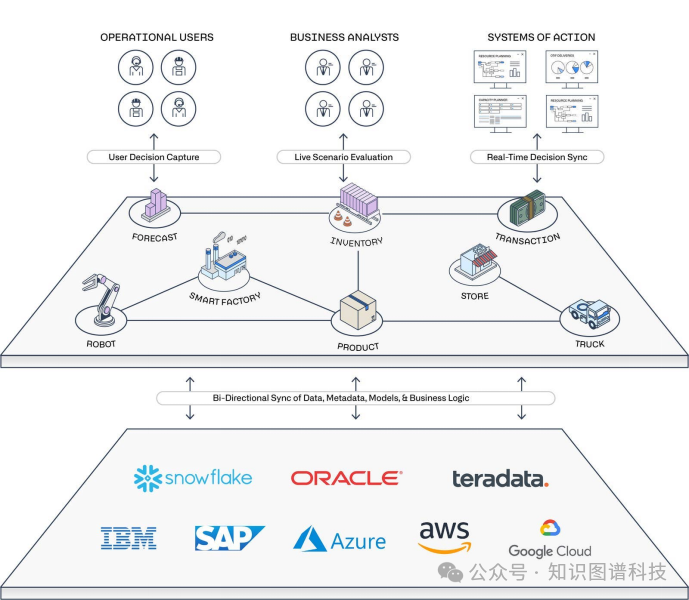
Palantir 的工程哲学在于其对异构数据的极致处理能力。在工业、国防、金融等领域,数据往往分散在数百个不同的系统、数据库和格式中。Foundry 平台通过其独特的本体论(Ontology)层,将这些物理世界中的实体(如“设备”、“订单”、“人员”)抽象化,并在数字世界中建立统一的语义模型。这使得分析师无需关心底层数据源的复杂性,直接在统一的业务概念上进行操作和决策。
1.2工程硬核:极致压缩与毫秒级响应的秘密
Palantir 如何在处理海量异构数据时,依然保持毫秒级的响应速度?这背后是顶级的工程学支撑。
《Palantir: Hierarchical Similarity Detection for Post-Deduplication Delta Compression》这篇论文揭示了其核心技术之一:分层相似性检测(Hierarchical Similarity Detection)[2]。
在处理大规模数据集时,数据去重(Deduplication)是提高效率的关键。传统的去重方法成本高昂,尤其是在需要实时更新的场景。Palantir 的方法巧妙地利用了数据的层级结构和相似性,实现了:
|
技术特点 |
描述 |
核心价值 |
|
分层检测 |
在不同粒度(如文件、块、字节)上进行相似性匹配。 |
提高去重效率,减少计算资源消耗。 |
|
增量压缩 |
仅存储数据块之间的差异(Delta),而非完整副本。 |
极致压缩存储空间,尤其适用于时间序列数据和版本控制。 |
|
后去重 |
在数据摄入后进行去重,不影响实时写入性能。 |
确保数据流的低延迟,同时保持数据的高效存储。 |
简单来说,这项技术解释了 Palantir 如何在保持数据完整性的同时,把存储成本压到极致,并确保数据查询的效率。这是其能够处理 TB 级甚至 PB 级数据的工程基石。
1.3安全基石:NFV驱动的自动化威胁缓解
在安全领域,《PALANTIR: An NFV-Based Security-as-a-Service Approach for Automating Threat Mitigation》则展示了 Palantir 如何利用网络功能虚拟化(NFV)打造一套自动化的“安全大脑” [3]。
NFV 允许安全功能(如防火墙、入侵检测)以软件形式部署和管理。Palantir 将其与自身的决策平台结合,实现了:
1威胁感知:实时监控数据流,通过本体论识别异常行为。
2自动化响应:一旦发现威胁,系统自动生成决策,通过 NFV 动态部署或调整安全策略,实现威胁的即时缓解。
这种“数据-决策-行动”的闭环,是 Palantir 在数据治理和安全领域的核心竞争力。
二、灵魂重构:语义数字孪生与知识图谱的融合
传统的数字孪生(DT)常常被诟病为“只有皮囊,没有灵魂”。它们是物理世界的 3D 模型加上实时数据流,但缺乏对业务逻辑、因果关系和领域知识的理解。
本资源包的第二部分,正是关于如何通过语义化,赋予数字孪生“思考能力”。
2.1从3D模型到“认知型”数字孪生
《Ontologies in digital twins: A systematic literature review》这篇 2024 年的最新综述是理解该领域的必读文献 [4]。它系统性地复盘了本体论(Ontology)在数字孪生中的所有关键进展。
本体论,可以理解为机器世界的“百科全书”或“词典”。它定义了领域内所有实体(如“泵”、“阀门”、“故障”)及其相互关系。当本体论与数字孪生结合时,DT 就从一个数据容器升级为认知型数字孪生(Cognitive Digital Twin)。
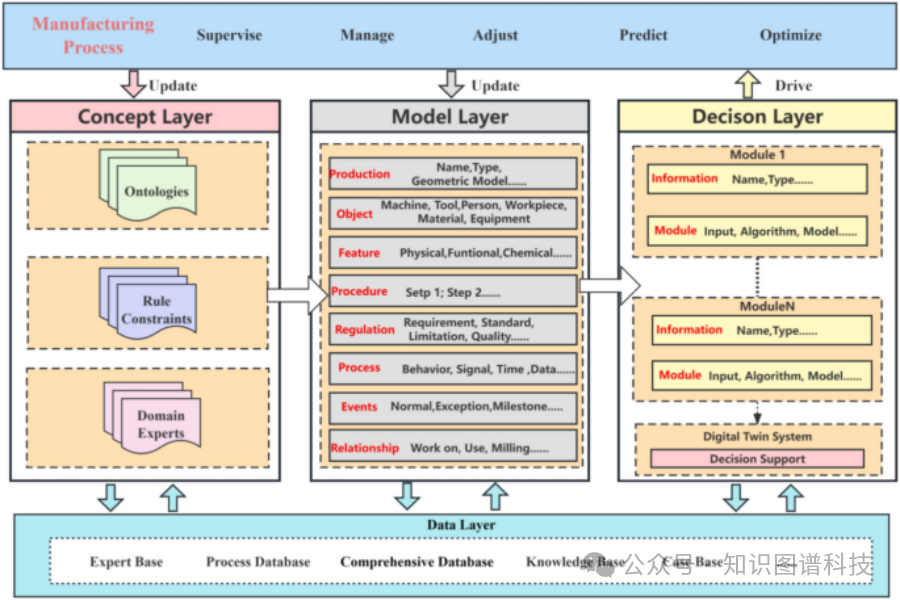
如图所示,本体论位于架构的概念层(Concept Layer),为上层的模型和决策提供了统一的语义基础。
2.2知识图谱:构建语义数字孪生的通用手册
如何将抽象的本体论落地为可操作的数字孪生模型?
《A methodology for creating semantic digital twin models supported by knowledge graphs》提供了一份标准化的通用手册[5]。它定义了利用知识图谱(KG)构建语义数字孪生的通用流程:
1本体建模:定义核心实体、属性和关系。
2数据映射:将来自传感器、ERP、MES 等系统的异构数据映射到本体结构中。
3图谱构建:生成知识图谱,将孤立的数据点连接成一个巨大的语义网络。
4语义推理:利用图谱进行逻辑推理,实现故障诊断、预测性维护等高级功能。
2.3制造业的顽疾与三层知识图谱架构
在复杂的制造业场景中,数据源的复杂性是最大的顽疾。
《Digital twin system for manufacturing processes based on a multi-layer knowledge graph model》这篇研究提出了一个惊艳的“三层知识图谱架构”[6],专门解决制造业中多源数据整合的挑战:
|
知识图谱层级 |
核心内容 |
解决的问题 |
|
设备层 KG |
传感器数据、设备参数、实时状态。 |
实时数据采集与设备状态监控。 |
|
工艺层 KG |
生产流程、工序、工艺参数、质量标准。 |
业务逻辑与物理过程的关联。 |
|
领域层 KG |
行业标准、安全规范、专家经验。 |
跨系统、跨工厂的知识复用与共享。 |
通过这种分层架构,数字孪生能够清晰地理解“哪个设备(设备层)在哪个工序(工艺层)上违反了哪个行业标准(领域层)”,从而实现精准的故障定位和决策支持。
2.4互操作性:打破数据孤岛的元数据架构
数据孤岛是数字化转型的最大障碍。不同系统、不同厂商的数据格式和定义各不相同。
《Semantic digital twin for interoperability and Comprehensive Management of Data Assets》针对这一问题,提出了一种面向设计者的元数据架构[7]。通过统一的语义元数据层,它让不同系统的数据资产能够真正实现互操作。这对于构建跨部门、跨企业的工业互联网平台至关重要。
三、未来进化:当大模型(LLM)遇上数字孪生与通信
本资源包中最具前瞻性的部分,探讨了LLM如何作为“超级大脑”,赋能数字孪生和下一代通信网络。
3.1 LSDTs:LLM驱动的“自主决策”数字孪生
传统的数字孪生需要人工输入大量的规则和约束,例如环境法规、技术指南等非结构化文档。这是一个巨大的体力活,且更新滞后。
《LSDTs: LLM-Augmented Semantic Digital Twins for Adaptive Knowledge-Intensive Infrastructure Planning》这篇文章是核心中的核心 [8]。它提出了LSDTs(LLM-Augmented Semantic Digital Twins)框架,利用大语言模型(LLM)的强大理解能力,实现了数字孪生的“自主学习”:
1知识提取:LLM 自动阅读海量的非结构化文档(如最新的环保法、建筑规范、安全手册)。
2语义注入:LLM 将提取出的知识转化为结构化的语义约束和规则,并注入到数字孪生的本体论层。
3自适应规划:当用户提出规划需求时,LSDT 不仅基于物理模型进行仿真,还会基于 LLM 注入的规则进行合规性检查和自适应调整。
这意味着,未来的数字孪生不再需要人工苦力去录入规则,LLM 会自动阅读文档并告诉系统:“根据最新的环保法,这里的布线需要预留 500 米缓冲区。”数字孪生真正获得了“自主决策”的能力。
3.2语义感知通信:从传输“比特”到传输“意义”
通信网络的未来,不再是追求更高的带宽,而是追求更高的效率和语义理解。
《Generative AI-Driven Semantic Communication Networks》与《From Semantic Communication to Semantic-aware Networking》这两篇文章共同构筑了未来通信的愿景 [9] [10]。
【核心转变】传统通信:传输比特(Bits),目标是接收端精确还原发送端的每一个0和1。语义通信:传输意义(Meaning),目标是接收端准确理解发送端的意图。
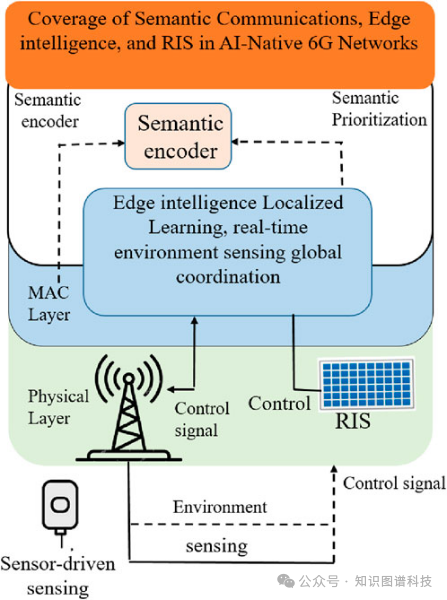
通过生成式AI驱动,网络能够理解你发送内容的语义,只传输与“意义”相关的最小信息量。这带来了两个革命性的优势:
1极致压缩:在工业物联网、自动驾驶等场景,数据压缩率可达99%以上,极大地节省了带宽。
2低延迟:传输的数据量大幅减少,使得网络延迟降至最低,实现近乎实时的交互。
未来的网络将是一个“语义感知网络”,它不仅能传输数据,还能理解数据,并根据业务需求动态调整传输策略。
四、为什么这份资源值得你收藏?(行动指南)
这套资源包不仅仅是 14 篇 PDF 的集合,它代表了当前技术前沿的“理论-工程-未来”闭环。
4.1从理论到工程的闭环:解决“知行不一”
许多技术人员困于理论与实践的脱节。这份资源包提供了完美的闭环:
|
维度 |
资源示例 |
价值体现 |
|
理论综述 |
《Ontologies in digital twins: A systematic literature review》 |
帮助你系统性地建立知识体系,避免盲人摸象。 |
|
工程实践 |
《Palantir: Hierarchical Similarity Detection…》 |
揭示顶级公司的工程实现细节,指导你的架构设计。 |
|
未来前瞻 |
《LSDTs: LLM-Augmented Semantic Digital Twins…》 |
锁定未来 2-3 年的技术热点,提前布局。 |
4.2前瞻性的“AI+”融合:锁定下一个风口
这份资源包率先引入了 LLM(大模型)与 KG(知识图谱)结合的落地案例(LSDTs),这是目前技术圈最卷、也是最有机会实现突破的方向。它为你提供了:
•LLM赋能数据治理:如何让大模型从非结构化数据中提取结构化知识。
•KG赋能数字孪生:如何用知识图谱为数字孪生提供逻辑和推理能力。
•AI赋能通信:如何利用生成式 AI 实现通信效率的革命性提升。
4.3配套中文PPT总结:高效学习的加速器
我们深知,14 篇英文文献看完至少需要一周时间。
因此,我们针对每一篇文献都准备了中文深度总结PPT,让你在5分钟内掌握一篇文章的精髓。这些 PPT 结构清晰、语言通俗,非常适合你在公司内部做技术分享、周报参考,或作为快速学习新领域的加速器。
【行动呼吁】
未来已来,但它并非均匀分布。这份资源包,就是你站在技术浪潮之巅的入场券。
立即获取这套包含14篇顶级白皮书和配套中文PPT,锁定你的未来五年技术优势。
参考文献
[1] Data integration and analysis platforms as digital platforms
[2] Palantir: Hierarchical Similarity Detection for Post-Deduplication Delta Compression
[3] PALANTIR: An NFV-Based Security-as-a-Service Approach for Automating Threat Mitigation
[4] Ontologies in digital twins: A systematic literature review
[5] A methodology for creating semantic digital twin models supported by knowledge graphs
[6] Digital twin system for manufacturing processes based on a multi-layer knowledge graph model
[7] Semantic digital twin for interoperability and Comprehensive Management of Data Assets
[8] LSDTs: LLM-Augmented Semantic Digital Twins for Adaptive Knowledge-Intensive Infrastructure Planning
[9] Generative AI-Driven Semantic Communication Networks
[10] From Semantic Communication to Semantic-aware Networking





评论前必须登录!
注册