 网硕互联帮助中心
网硕互联帮助中心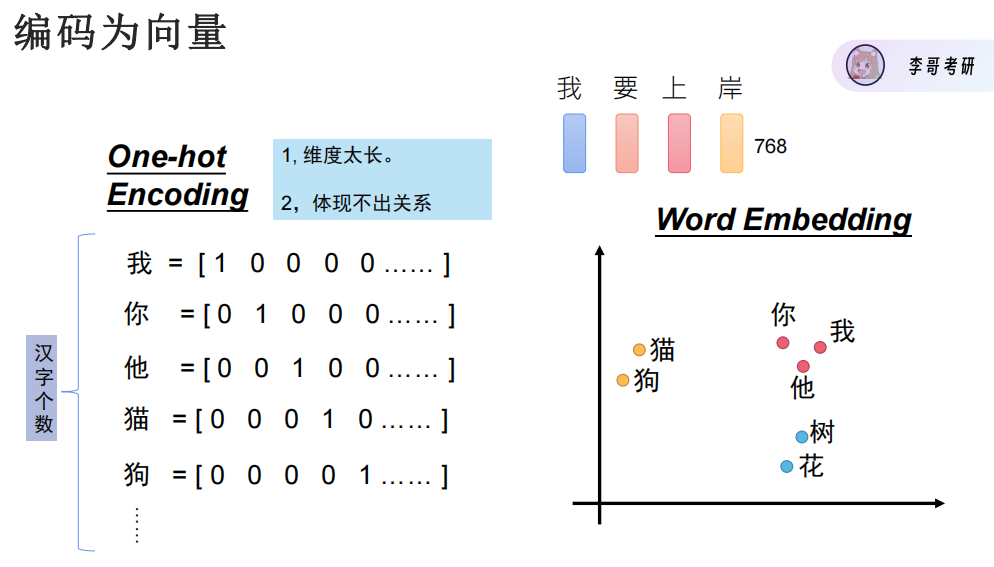
One-hot编码
Word-Embedding词嵌入
文字编码为向量可以用数据表示文字,但是无法表示文字之间的关系,比如你我他应该关系近,无法用数据表示。
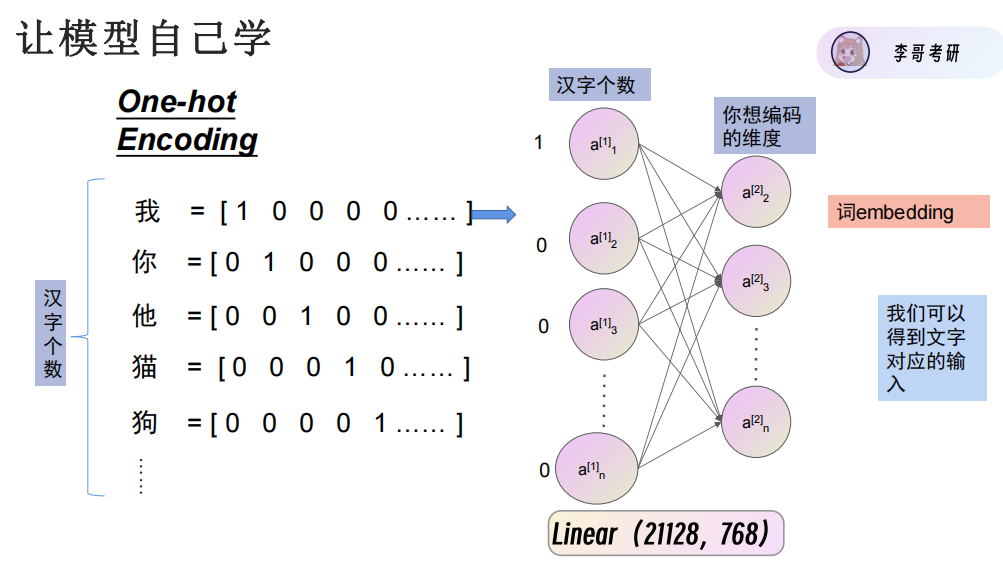
让模型自己学会,再变为768维的向量。
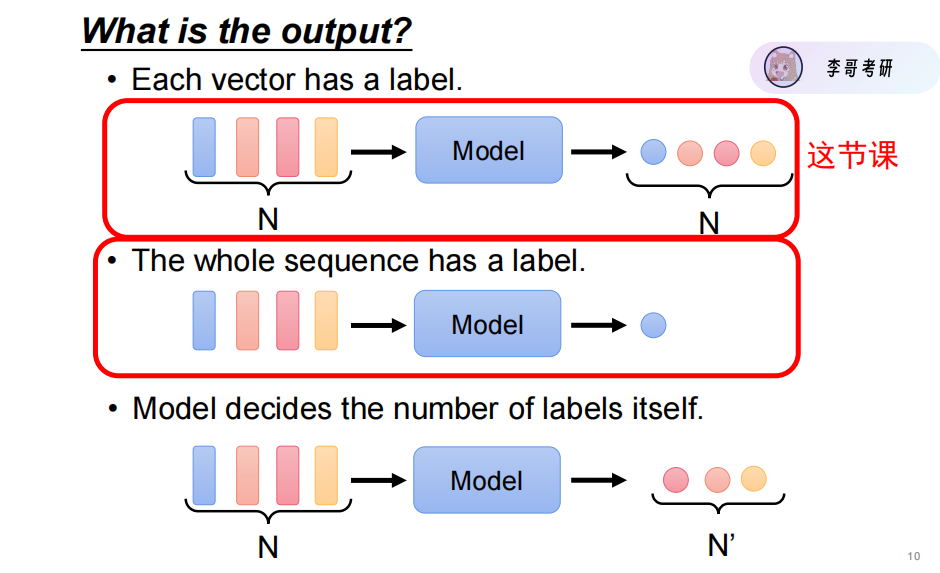
这里主要学习固定输出格式的方法。
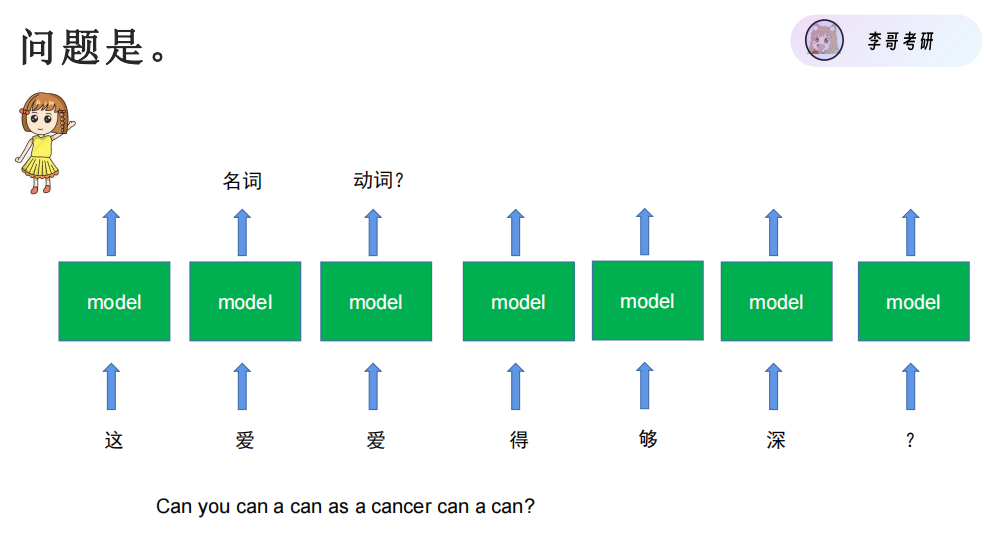
相同的输入汉字,得到的输出结果应该得不同。
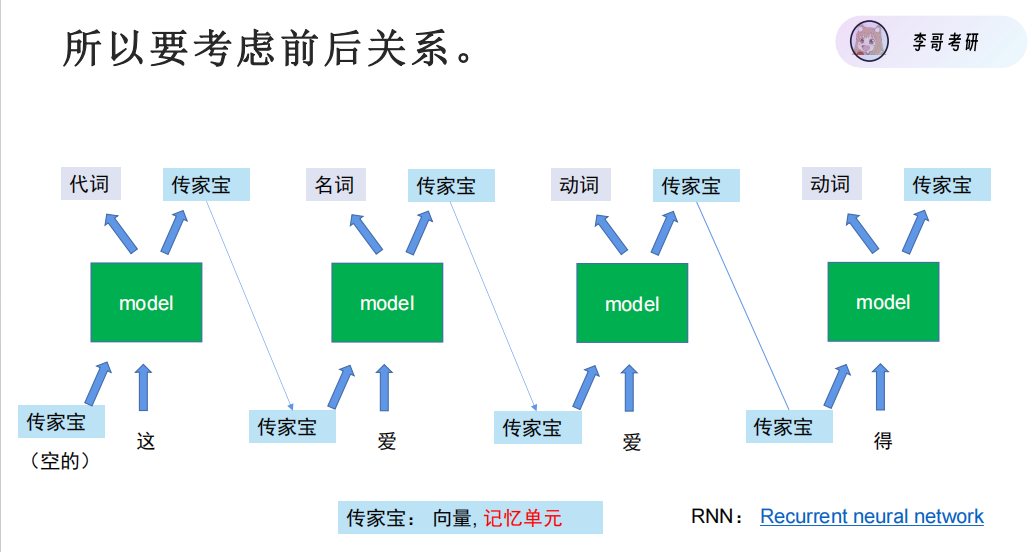
RNN循环神经网络,有一个记忆单元可以考虑前后关系
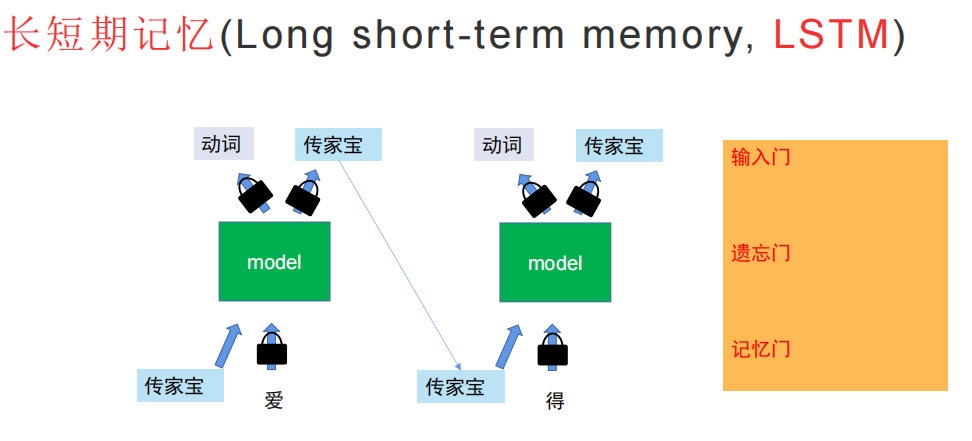
LSTM让部分字不允许进入记忆单元。
RNN与LSTM都太慢了,无法并行。
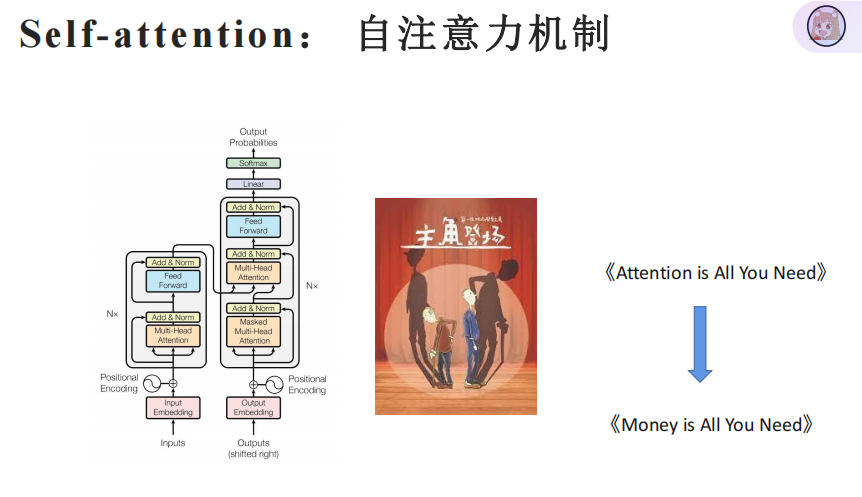
直到transformer的出现,《Attention is All You Need》,可以大规模并行训练,才有大模型的出现。
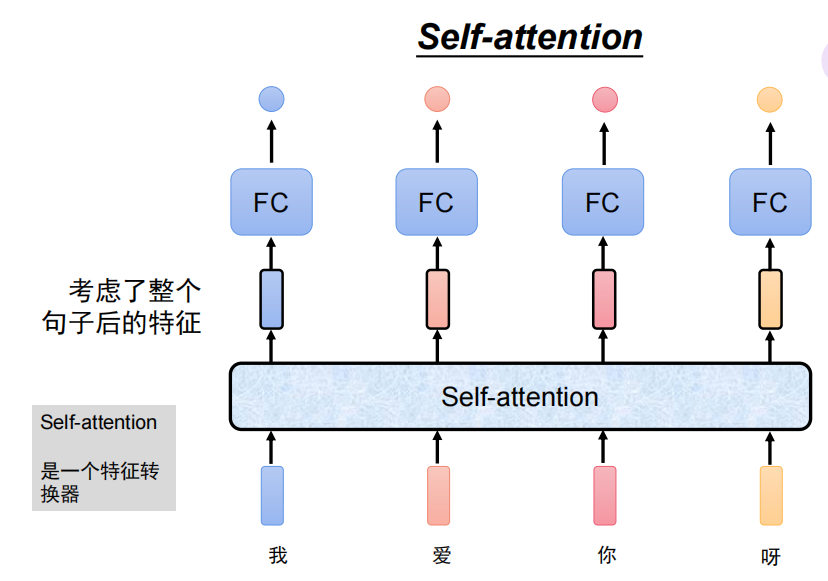
自注意力机制self-attention
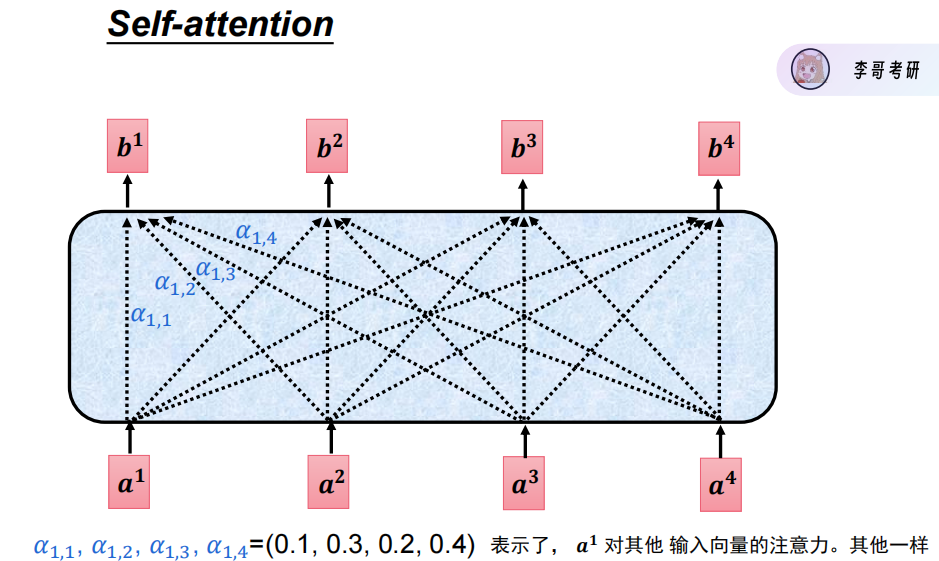


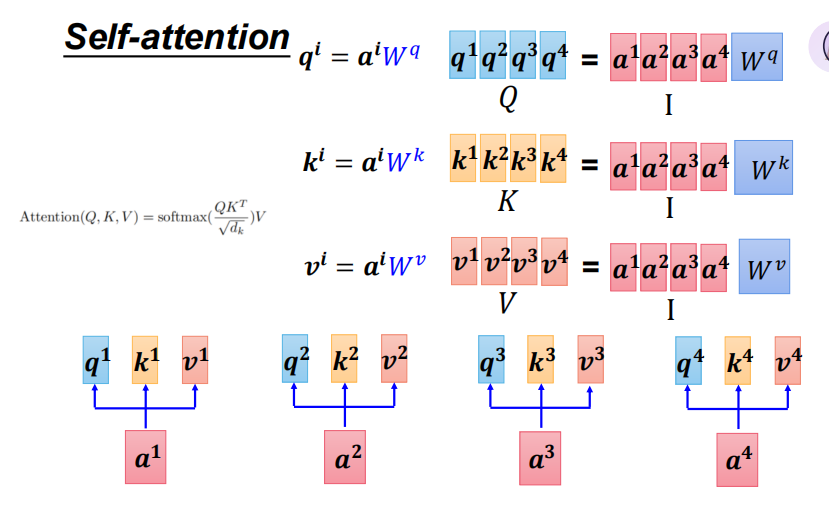
以上三张图为QKV计算公式
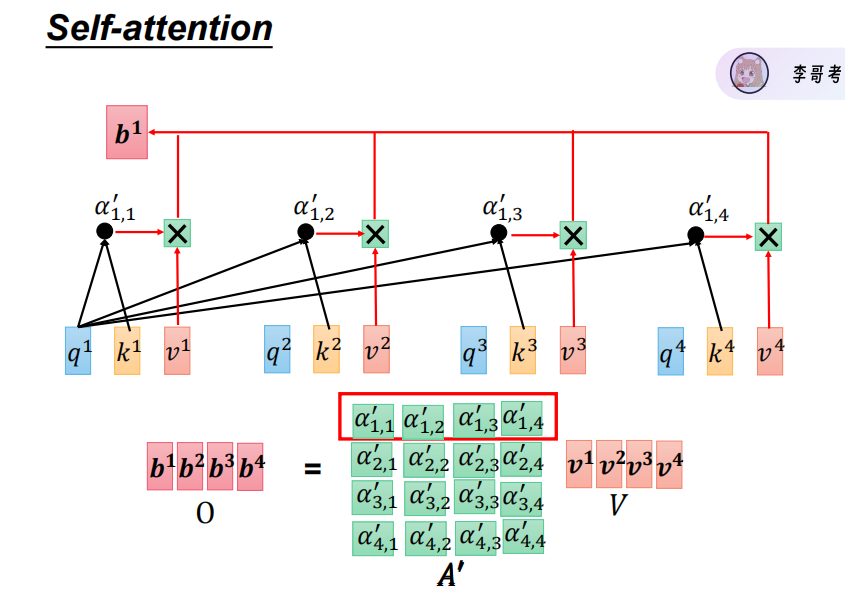
多个字成为矩阵
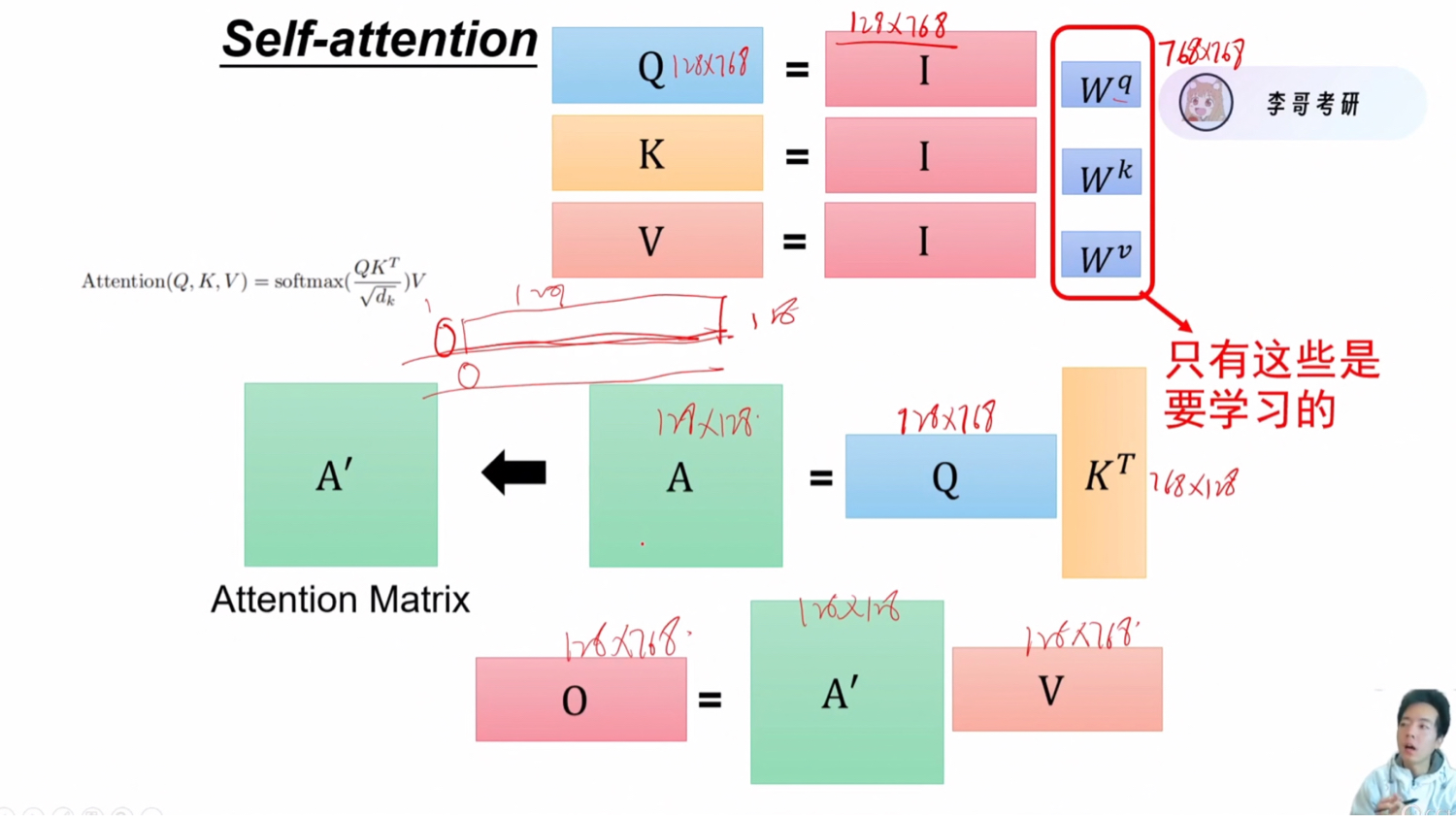
维度的变化
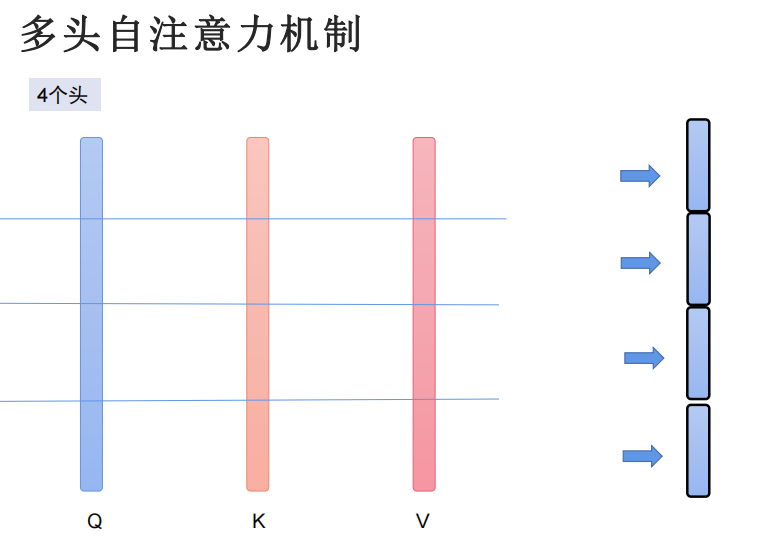
多头自注意力机制
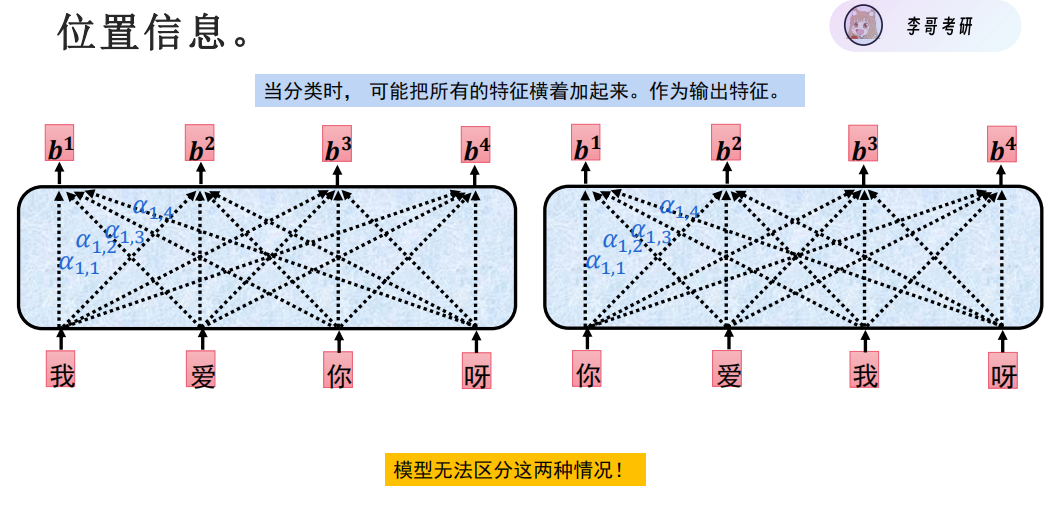
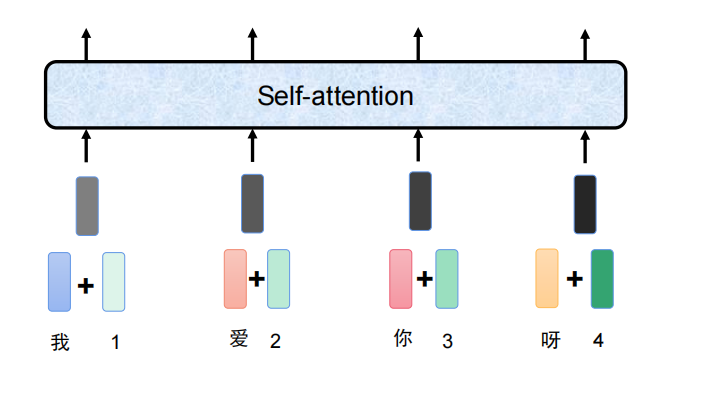
字与位置信息的直接加,离谱
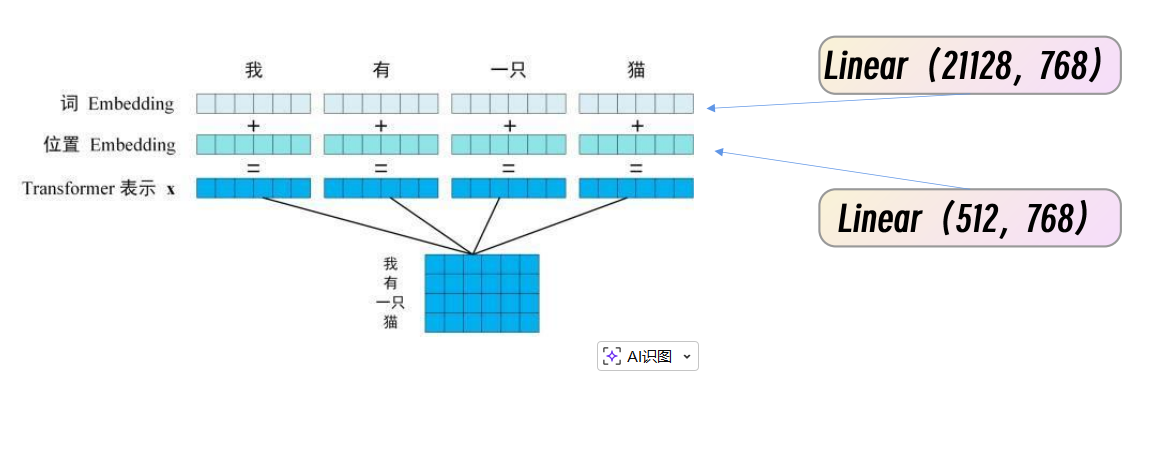
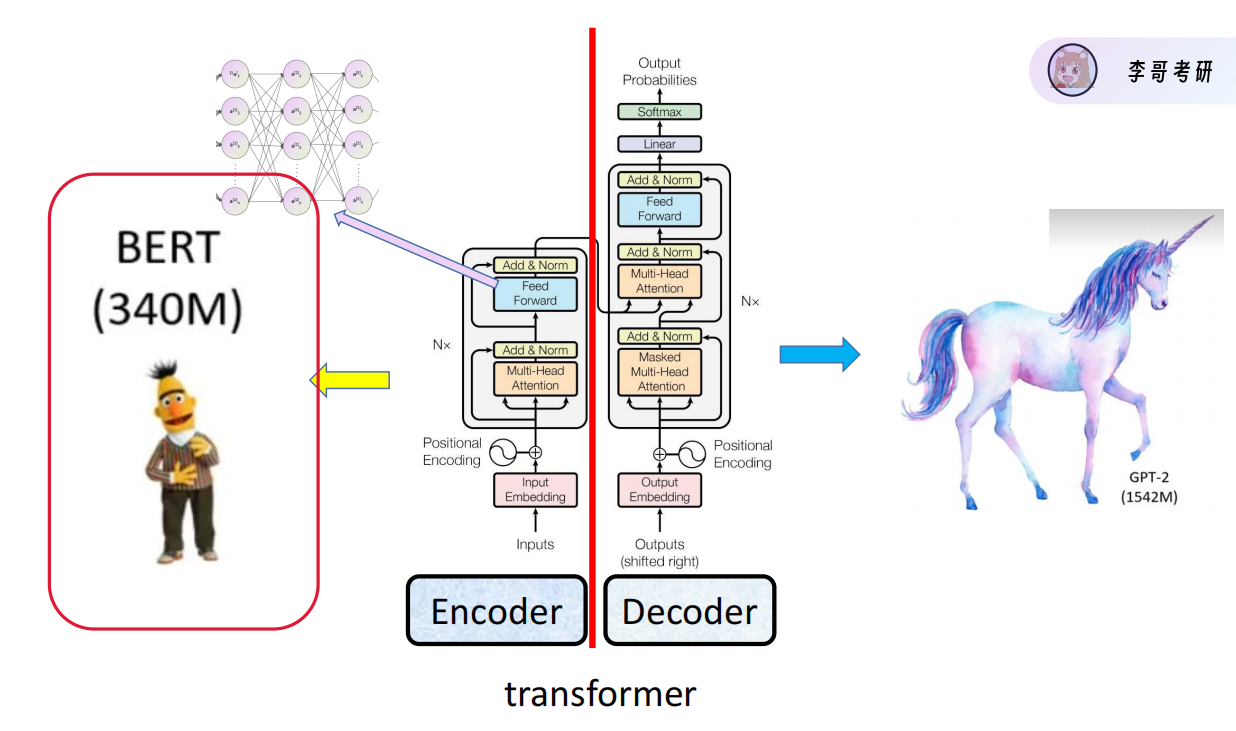
论文结构的再理解
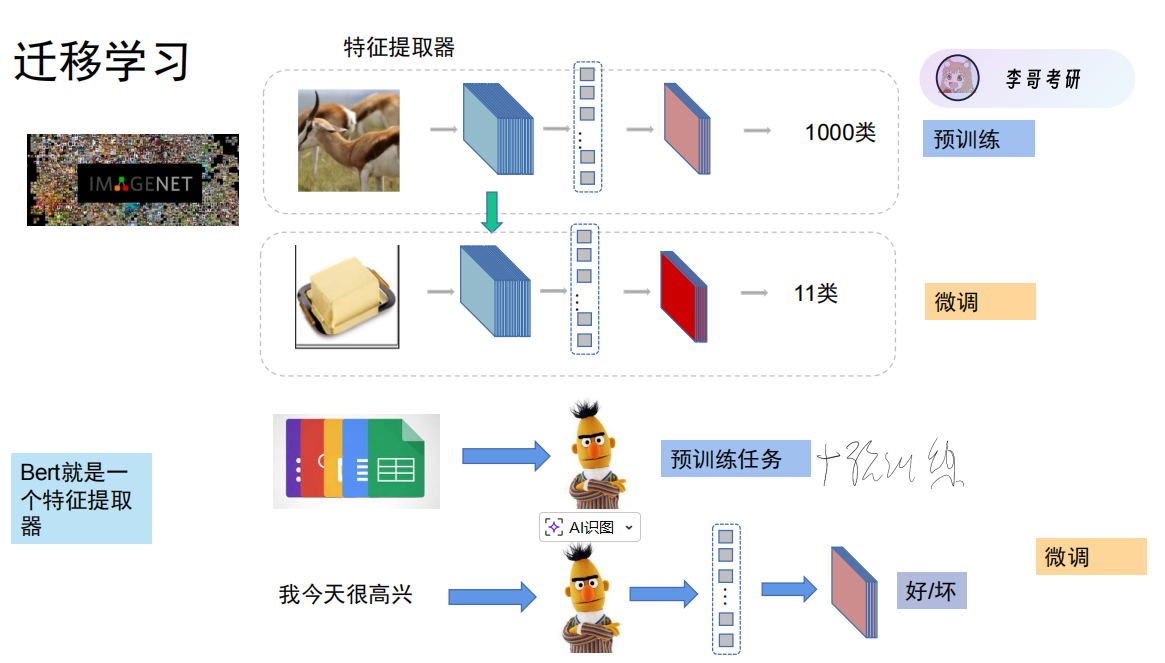
通过预训练任务,模型获得了特征提取能力


Bert的输入,除了字和位置信息之外,多一些片段信息

只输出CLS用的比较多。






评论前必须登录!
注册