 网硕互联帮助中心
网硕互联帮助中心上一期《7天学会Redis》已经完结,本周开始整理RocketMQ,欢迎指正,点赞关注哦~
《RocketMQ研读》Day1:RocketMQ 基础架构与核心概念
《RocketMQ研读》Day2:生产者的设计与实践
《RocketMQ研读》Day3:消费者的设计与实践
《RocketMQ研读》Day4:消息存储与复制机制
《RocketMQ研读》Day5:事务机制与顺序消息
《RocketMQ研读》Day6:高级特性与实战案例
《RocketMQ研读》Day7:高可用与集群部署
Day6:高级特性与实战案例
一、延迟消息
1.1 延迟消息的应用场景
延迟消息是指消息发送后,并不立即被消费者消费,而是在指定的延迟时间之后才可被消费。常见的应用场景包括:
-
订单超时取消:下单后30分钟未支付,自动取消订单
-
业务延迟:无人机开机3s后开始推流
-
重试策略:消息处理失败后,延迟一段时间再重试
1.2 延迟消息的实现原理
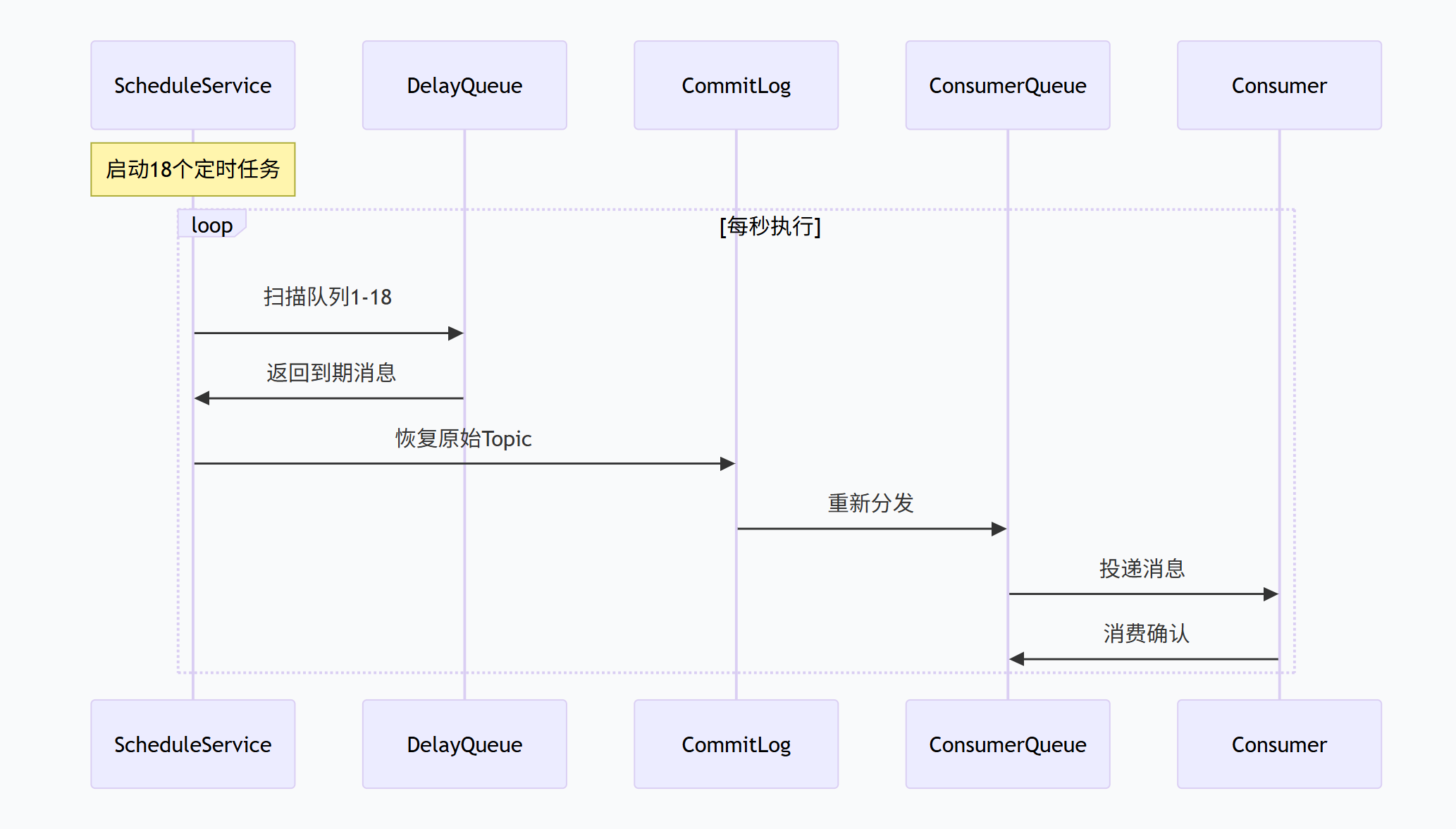
RocketMQ的延迟消息是通过内置的延迟主题(SCHEDULE_TOPIC_XXXX)和延迟队列实现的。支持18个延迟级别(1到18),分别对应: 1s、5s、10s、30s、1m、2m、3m、4m、5m、6m、7m、8m、9m、10m、20m、30m、1h、2h
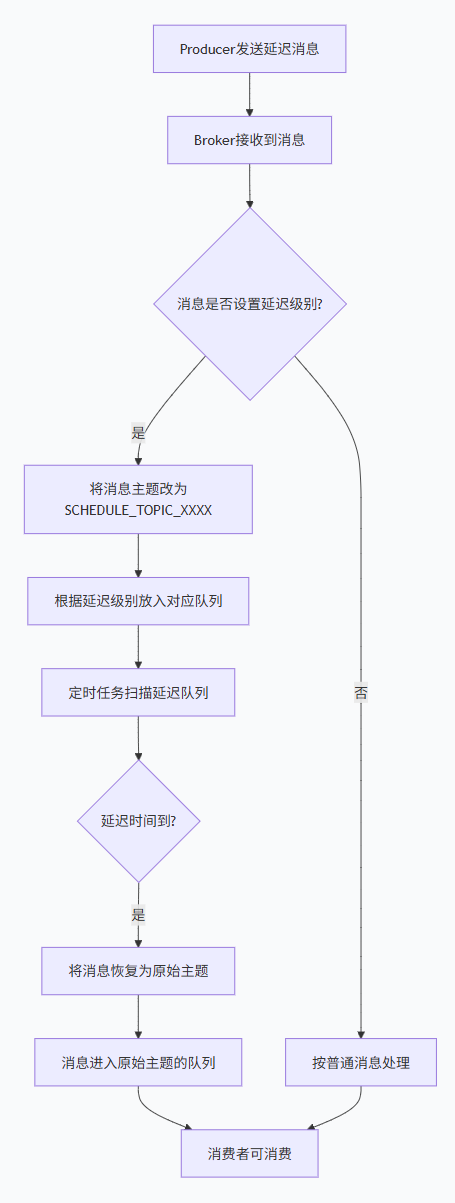
详细流程:
生产者发送消息时,设置延迟级别(message.setDelayTimeLevel(3))。
Broker接收到消息后,发现是延迟消息,则将消息的原主题和队列ID存储到消息属性中,然后改变消息的主题为SCHEDULE_TOPIC_XXXX,队列ID为延迟级别对应的ID。
延迟服务(ScheduleMessageService)会定时(每秒钟)扫描每个延迟级别的队列,检查消息是否到期。
到期后,将消息的主题和队列ID恢复为原始值,然后重新投递到CommitLog中,之后消息会被分发到原始主题的队列中,供消费者消费。
定时扫描
生产避坑:延迟消息的 3 大陷阱
| 延迟级别超出范围 | delayLevel=0(立即发送) | 严格使用 1-18(delayLevel=5 对应 30分钟) |
| 未处理超时 | 业务逻辑未处理延迟消息 | 消费端需判断 msg.getDelayLevel() |
| 时间轮未预热 | 首次使用时间轮延迟 50ms | 启动时预热(ScheduleMessageService.start()) |
二、过滤消息:精准投递的利器
2.1 Tag过滤机制
Tag过滤是RocketMQ最常用的过滤方式,基于消息的Tag属性进行简单高效的过滤。
实现原理:
Tag编码:每个Tag被编码为整数hashCode
订阅关系:消费者订阅时指定Tag或Tag表达式
快速匹配:Broker通过hashCode快速过滤,无需解析消息内容
Tag表达式语法:
-
单个Tag:"TAG_A"
-
多个Tag(或关系):"TAG_A || TAG_B"
-
所有Tag:"*"(默认)
2.2 SQL92过滤机制
SQL92过滤提供更强大的过滤能力,支持对消息的用户属性进行复杂条件过滤。
支持的操作符:
-
数值比较:=, >, >=, <, <=, BETWEEN
-
逻辑运算:AND, OR, NOT
-
空值判断:IS NULL, IS NOT NULL
-
模式匹配:LIKE
-
集合操作:IN
2.3 应用示例
@RocketMQMessageListener(
topic = "MULTI_TENANT_TOPIC",
consumerGroup = "tenant-a-consumer",
selectorType = SelectorType.SQL92,
selectorExpression = "tenantId = 'TENANT_A' AND env = 'PROD'"
)
public class TenantAConsumer implements RocketMQListener<Message> {
@Override
public void onMessage(Message message) {
// 处理租户A的消息
processForTenantA(message);
}
}
三、批量消息
3.1、什么是批量消息?
批量消息是指生产者将多条业务逻辑相关的消息组合成一个“批”(Batch),一次性发送到Broker。Broker收到后,会将其作为一批数据进行存储和处理,而消费者拉取和消费时,仍然以单条消息为单位。
核心价值:将多次网络往返(RTT)、多次序列化、多次存储系统调用的开销,压缩为一次,从而在发送大量小消息时,带来巨大的性能提升。
3.2、核心应用场景
批量消息适用于高吞吐、可批量处理的场景,其本质是用稍高的延迟换取极高的吞吐。
| 日志采集与上报 | 应用将多行日志、多个监控指标打包,定期批量发送到消息队列。 | 这是最经典的场景。将每秒成千上万条小日志合并为每秒几十个批次,网络和Broker压力骤降。 |
| 数据同步与ETL | 从数据库Binlog捕获一批变更记录,批量发送到数据仓库或搜索索引。 | 减少对下游系统的连接压力,提高数据同步的吞吐量。 |
| 离线消息推送 | 向百万用户发送系统通知时,按用户标签分批,每批包含数千个用户ID。 | 极大减少推送服务与消息队列之间的交互次数。 |
| 交易流水记录 | 在支付系统中,将短时间内产生的多笔交易流水合并发送到结算Topic。 | 降低核心交易链路的网络开销,将计算与记录解耦。 |
3.3 工作流程
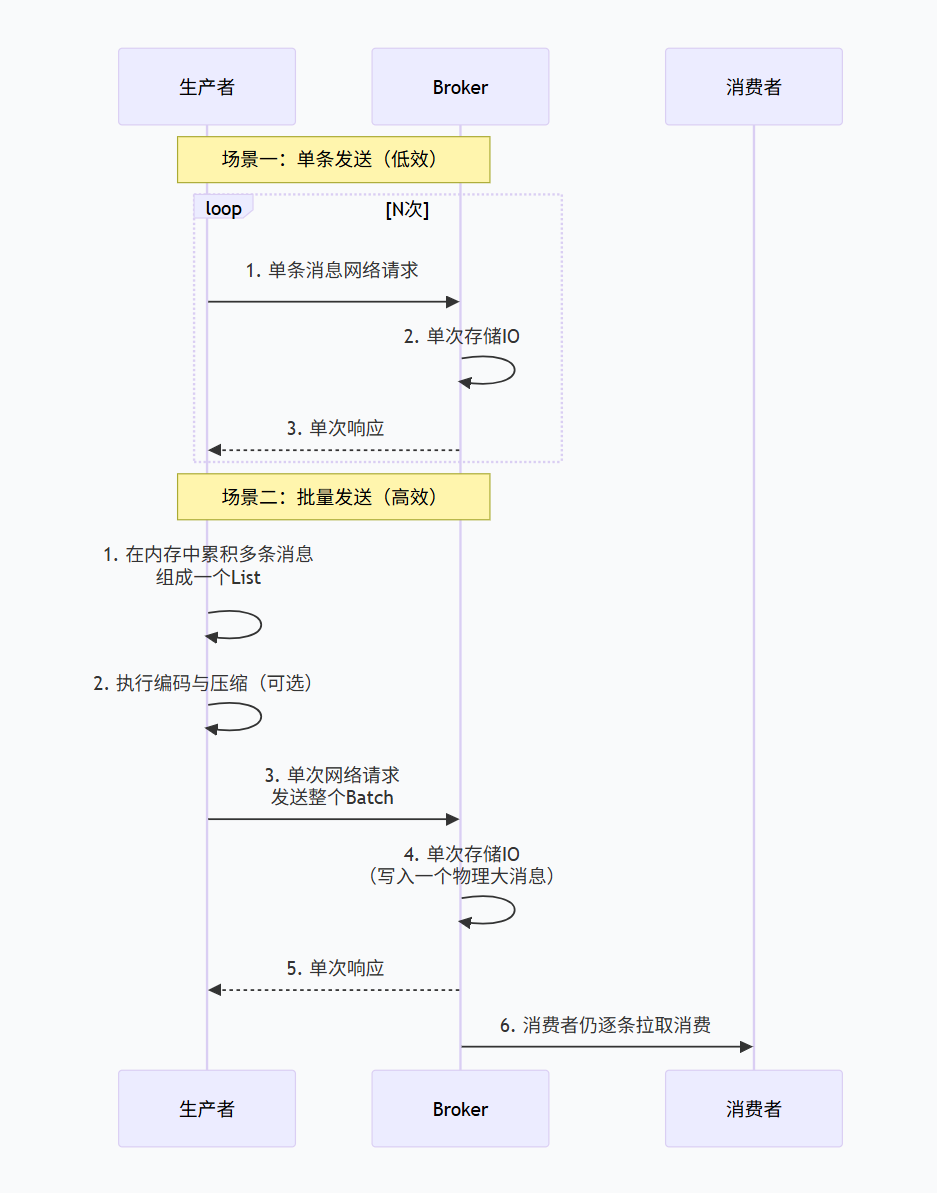
流程详解:
生产者累积:生产者应用在内存中累积多条消息(Message对象),放入一个 List。
编码与压缩(可选):RocketMQ会将这个 List 序列化为一个大的字节数组。为了进一步提升性能,可以启用压缩(如LZ4、Zstd),这对文本类小消息效果显著。
批量发送:调用 producer.send(batchList),将整个批次通过一次网络请求发送给Broker。
Broker处理:Broker收到这个批量消息后,会将其作为一个特殊的“大消息” 写入CommitLog。但在逻辑上,它会解析出内部包含的每一条子消息,并为其单独构建ConsumeQueue索引。
消费者消费:对消费者完全透明。消费者拉取消息时,从ConsumeQueue中获取的仍然是单条消息的索引,并从CommitLog中读取对应的数据段。消费逻辑感知不到消息最初是批量发送的。
3.4 应用示例
/**
* 自适应批量消息处理器
* 处理大小混合的消息场景
*/
@Service
public class AdaptiveBatchProcessor {
// 大小消息阈值(1KB)
private static final int SMALL_MESSAGE_THRESHOLD = 1024;
/**
* 自适应批量处理
*/
public void adaptiveBatchProcess(List<MessageExt> messages) {
// 1. 分离大小消息
Map<Boolean, List<MessageExt>> partitioned = messages.stream()
.collect(Collectors.partitioningBy(
msg -> msg.getBody().length <= SMALL_MESSAGE_THRESHOLD
));
List<MessageExt> smallMessages = partitioned.get(true);
List<MessageExt> largeMessages = partitioned.get(false);
// 2. 小消息批量处理
if (!smallMessages.isEmpty()) {
processSmallMessagesBatch(smallMessages);
}
// 3. 大消息单独处理
if (!largeMessages.isEmpty()) {
processLargeMessagesSeparately(largeMessages);
}
}
/**
* 小消息批量处理(高吞吐)
*/
private void processSmallMessagesBatch(List<MessageExt> messages) {
// 按业务类型分组批量处理
Map<String, List<MessageExt>> grouped = messages.stream()
.collect(Collectors.groupingBy(
msg -> msg.getTags()
));
for (List<MessageExt> group : grouped.values()) {
// 批量数据库操作
batchInsertToDatabase(group);
// 批量更新缓存
batchUpdateCache(group);
// 批量发送下游消息
batchSendDownstream(group);
}
}
/**
* 大消息单独处理(保证可靠性)
*/
private void processLargeMessagesSeparately(List<MessageExt> messages) {
for (MessageExt message : messages) {
try {
// 单独处理每个大消息
processSingleLargeMessage(message);
} catch (Exception e) {
log.error("处理大消息失败: msgId={}", message.getMsgId(), e);
// 大消息失败需要特殊处理
handleLargeMessageFailure(message, e);
}
}
}
}
四、重试队列与死信队列
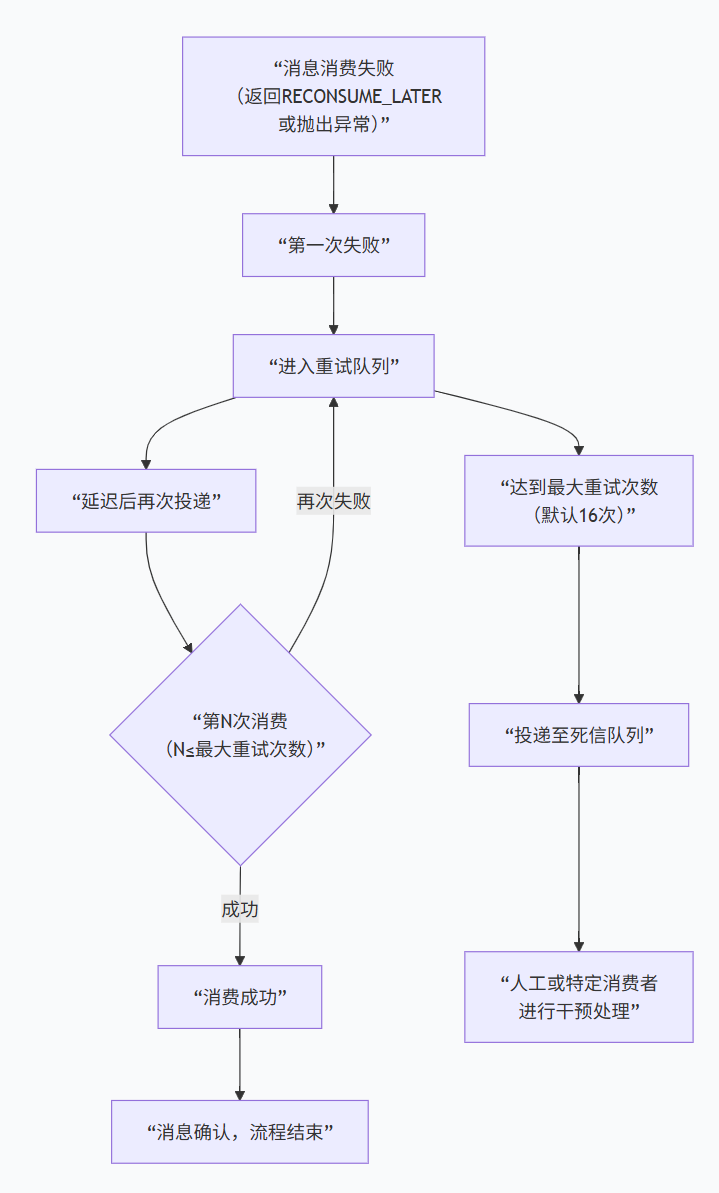
4.1 运转流程
4.2 重试队列
触发条件:当消费者监听器返回 RECONSUME_LATER 或抛出异常时,当前消费被视为失败。
本质:重试队列是一个逻辑上的、特殊命名的Topic,由Broker进行特殊管理和调度,以实现延迟重试的功能。
-
例如,消费者组 MyConsumerGroup 的重试队列Topic名为 %RETRY%MyConsumerGroup。
-
这个 Topic 与普通 Topic 在存储层面有重要区别
不写入 ConsumeQueue:为重试队列(%RETRY%…)创建的消息,不会像普通消息那样在 Broker 的 commitlog 目录下生成对应的 ConsumeQueue 索引文件。这意味着它更偏向于一个逻辑队列,Broker 内部使用了不同的机制来管理和调度这些待重试的消息
特殊处理:其消息的存储和延迟投递由 Broker 的 ScheduleMessageService(定时消息服务)统一管理。
重试策略:采用指数退避延迟,延迟级别逐渐增加,避免对系统造成连续冲击。
-
第1次重试:延迟 10 秒
-
第2次重试:延迟 30 秒
-
第3次重试:延迟 1 分钟
-
… 后续延迟越来越长,最大间隔为2小时。
-
默认最多重试16次。超过后,消息进入死信队列。
特性:
-
自动创建:无需手动创建。
-
自动订阅:原始消费者组会自动订阅自己的重试队列Topic。
-
重试队列不保证顺序
因为重试队列的核心机制是延迟投递,每条消息根据其重试次数被赋予不同的延迟级别
假设两条先后失败的消息 M1(第1次重试)和 M2(第1次重试),它们都被延迟10秒。但由于网络、线程调度等细微差异,它们被重新投递回消费者组的顺序无法保证一定是 M1 先于 M2。在并发消费的场景下(MessageListenerConcurrently),这个顺序会被进一步打乱。
-
结论:如果你需要严格的消息顺序,必须使用 MessageListenerOrderly,并且在消费失败时,顺序监听器会挂起队列而不是将消息发往重试队列,所以,这本身也说明了重试会破坏顺序。
4.3 死信队列
触发条件:当消息在重试队列中达到最大重试次数(默认16次)后仍消费失败,就会被自动转移到死信队列。与重试队列类似,死信队列(%DLQ%… Topic)也是在消息即将被投入时,由 Broker 自动创建的,无需运维人员预先在控制台创建。
本质:同样是一个特殊命名的Topic,格式为 %DLQ%。
-
例如,消费者组 MyConsumerGroup 的死信队列Topic名为 %DLQ%MyConsumerGroup。
特性:
-
消息的终点站:进入死信队列的消息不会再被任何消费者自动消费。
-
保留原信息:消息的所有属性(原始Topic、Tag、Key、Body、重试次数)都会被保留,便于排查。
-
大部分情况需要人工干预:开发工程师须额外订阅这个死信队列Topic,或通过控制台查看,来分析和处理这些“死亡”消息。





评论前必须登录!
注册