 网硕互联帮助中心
网硕互联帮助中心目录
- 引言
- 自注意力机制的背景
- 序列模型的演进
- 注意力机制的起源
- 自注意力机制的核心原理
- 查询、键和值(Q、K、V)的概念
- 注意力分数的计算
- Softmax归一化和加权求和
- 多头自注意力机制
- 为什么需要多头
- 多头注意力的实现
- 自注意力在Transformer中的应用
- Transformer整体架构
- 编码器中的自注意力
- 解码器中的自注意力与交叉注意力
- 代码实现:从零构建自注意力
- NumPy版本的自注意力
- PyTorch版本的自注意力
- 多头注意力的代码示例
- 可视化自注意力机制
- 注意力矩阵的热力图
- 多头注意力的可视化
- 自注意力机制的优缺点
- 优点分析
- 缺点与改进
- 实际应用案例
- 自然语言处理(NLP)中的应用
- 计算机视觉(CV)中的应用
- 其他领域的扩展
- 常见问题与调试技巧
- 未来展望
- 结论
- 参考文献
引言
在人工智能和深度学习领域,自注意力机制(Self-Attention)已成为一个不可或缺的核心技术。它是Transformer模型的基石,驱动了像BERT、GPT和T5这样的预训练模型在自然语言处理(NLP)任务中的卓越表现。如果你正在学习机器学习,或者想深入了解Transformer背后的原理,这篇文章将用通俗的语言带你一步步拆解Self-Attention。
想象一下,你在阅读一篇文章时,不会均匀关注每个词,而是重点留意关键词和上下文关系。自注意力机制正是模拟了这种“选择性关注”:在处理序列数据(如句子或图像序列)时,它允许模型动态计算每个元素与其他元素的关联强度,从而捕捉全局依赖,而非局限于局部。
为什么Self-Attention如此受欢迎?传统模型如RNN在长序列上效率低下,而Self-Attention支持并行计算,训练速度更快。根据Hugging Face的统计,基于Transformer的模型在GLUE基准上准确率提升了20%以上。本文将从背景、原理、代码实现到应用,全方位覆盖,帮助初学者快速上手,资深者深化理解。
关键词优化:自注意力机制、Self-Attention原理、Transformer教程、多头注意力解释、PyTorch Self-Attention代码。
自注意力机制的背景
序列模型的演进
序列数据处理是深度学习的核心挑战之一,早期的模型从统计方法起步,逐步演化到神经网络主导。
-
传统统计模型:如隐马尔可夫模型(HMM)和条件随机场(CRF)。这些模型基于概率图,适合小规模数据,但计算复杂,无法处理高维特征。例如,在语音识别中,HMM需要手动设计状态转移,扩展性差。
-
循环神经网络(RNN)时代:2010年后,RNN成为主流。它通过隐藏状态循环传递信息,公式为h_t = f(h_{t-1}, x_t)。LSTM引入门控(遗忘门、输入门、输出门)来缓解梯度消失:遗忘门 f_t = σ(W_f [h_{t-1}, x_t])。GRU简化了LSTM,参数更少。但问题在于顺序计算:对于长度n的序列,时间复杂度O(n),无法并行,训练长序列(如1000词文章)时容易梯度爆炸。
-
注意力引入的转折:2014年,Bahdanau et al.在Seq2Seq模型中首次使用注意力,允许解码器关注编码器的不同部分。这解决了RNN的“瓶颈”问题,但仍依赖RNN骨干。
Self-Attention的出现标志着彻底变革:它抛弃循环结构,直接计算全局关联,时间复杂度O(n²)但高度并行。
下表对比序列模型演进:
| 统计时代 | HMM, CRF | 概率转移 | 手动特征,慢 | 词性标注 |
| 循环时代 | RNN, LSTM, GRU | 时序记忆 | 梯度问题,并行差 | 机器翻译 |
| 注意力时代 | Seq2Seq with Attention | 动态权重 | 仍需RNN | 图像描述 |
| 自注意力时代 | Transformer | 全局并行 | 计算量大 | BERT预训练 |
注意力机制的起源
注意力机制源于认知科学,模拟人类“选择性注意”。在深度学习中,它最早用于视觉任务(如图像分类中的空间注意力),后扩展到NLP。
核心想法:给定源序列S和目标序列T,注意力计算权重α_i = softmax(e_i),其中e_i是相似度分数(如点积)。然后,上下文c = Σ α_i * s_i。
Self-Attention是其特殊形式:源和目标是同一序列,故“自”注意。2017年Vaswani et al.的论文《Attention Is All You Need》提出Transformer,证明只需Self-Attention和Feed-Forward层即可超越RNN。这篇论文引用量超10万,奠定了现代大模型基础。
(互动点:你觉得注意力机制像人类大脑吗?评论分享你的观点!)
自注意力机制的核心原理
Self-Attention的数学优雅在于三个矩阵和一个公式。假设输入X ∈ ℝ^{n × d},n是序列长度,d是嵌入维度。
查询、键和值(Q、K、V)的概念
输入X先通过线性变换投影:
- Query (Q):Q = X W_Q,W_Q ∈ ℝ^{d × d_k}。Q代表“提问者”,用于查询其他元素。
- Key (K):K = X W_K,W_K ∈ ℝ^{d × d_k}。K是“钥匙”,用于匹配查询。
- Value (V):V = X W_V,W_V ∈ ℝ^{d × d_v}。V是“内容”,加权后输出。
为什么投影?原始嵌入可能不适合计算相似度,投影到低维空间(d_k < d)减少噪声。d_k通常为d/ heads。
通俗例:句子“I love AI”。对于“I”,Q_I查询所有K,找到“love”的K匹配高,则V_love贡献大。
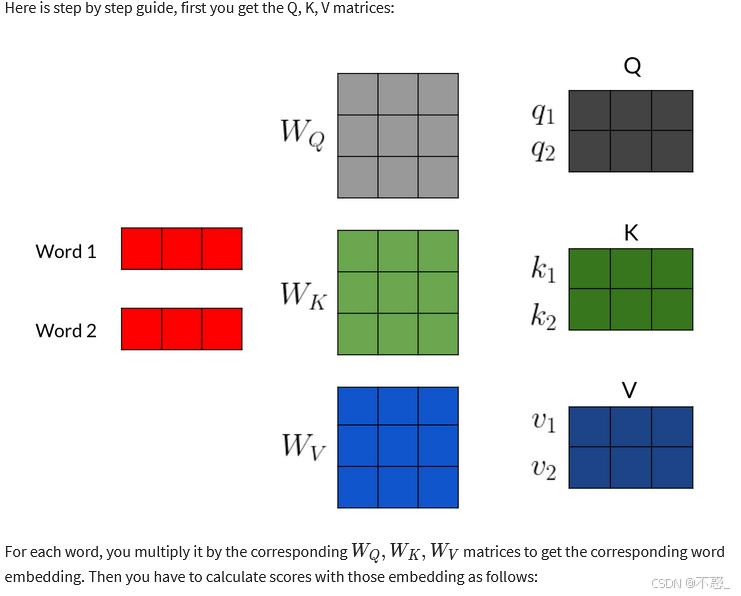
(上图展示Q、K、V矩阵的计算流程,帮助可视化投影过程。)
注意力分数的计算
分数矩阵Scores = (Q K^T) / √d_k
- 点积Q K^T 计算相似度,每行是某个Q与所有K的匹配。
- 除√d_k:缩放防止高维点积爆炸(方差为d_k,导致Softmax饱和)。
数学推导:假设Q和K元素独立同分布N(0,1),则点积均值为0,方差d_k。除√d_k后,方差1,便于Softmax。
对于掩码(Mask),如在解码器中防止未来信息泄露:Scores[mask] = -∞。
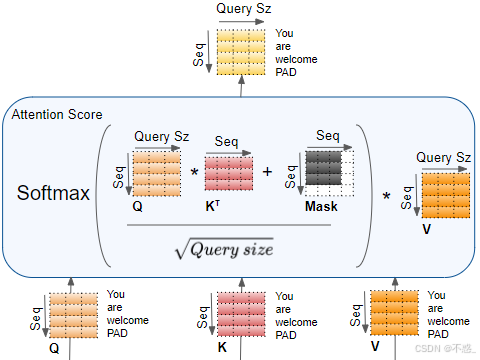
Softmax归一化和加权求和
Weights = softmax(Scores, dim=-1)
Output = Weights V
Softmax确保权重和为1:softmax(x_i) = exp(x_i) / Σ exp(x_j)
输出每个元素是V的凸组合,捕捉上下文。
完整公式:Attention(Q,K,V) = softmax( (Q K^T)/√d_k ) V
这实现了并行:矩阵乘法GPU友好。
(上图是Self-Attention的完整机制图,清晰显示分数计算和加权。)
(互动:试想在你的NLP项目中,如何用Self-Attention改进RNN?欢迎讨论!)
多头自注意力机制
为什么需要多头
单一注意力头可能捕捉单一类型关联(如语法或语义)。多头(Multi-Head)允许并行多个子空间学习不同表示,提升表达力。
论文中,heads=8,d_model=512,d_k=d_v=64。每个头独立计算,然后拼接。
优点:捕捉多维度依赖,如在句子中,一个头关注主谓,一个头关注实体。
多头注意力的实现
MultiHead(Q,K,V) = Concat(head_1, …, head_h) W_O
其中head_i = Attention(Q W_Q^i, K W_K^i, V W_V^i)
W_O ∈ ℝ^{h d_v × d} 是输出投影。
这增加了参数,但通过子空间分工,提高泛化。
(上图是多头自注意力机制的图解,展示并行头和拼接。)
自注意力在Transformer中的应用
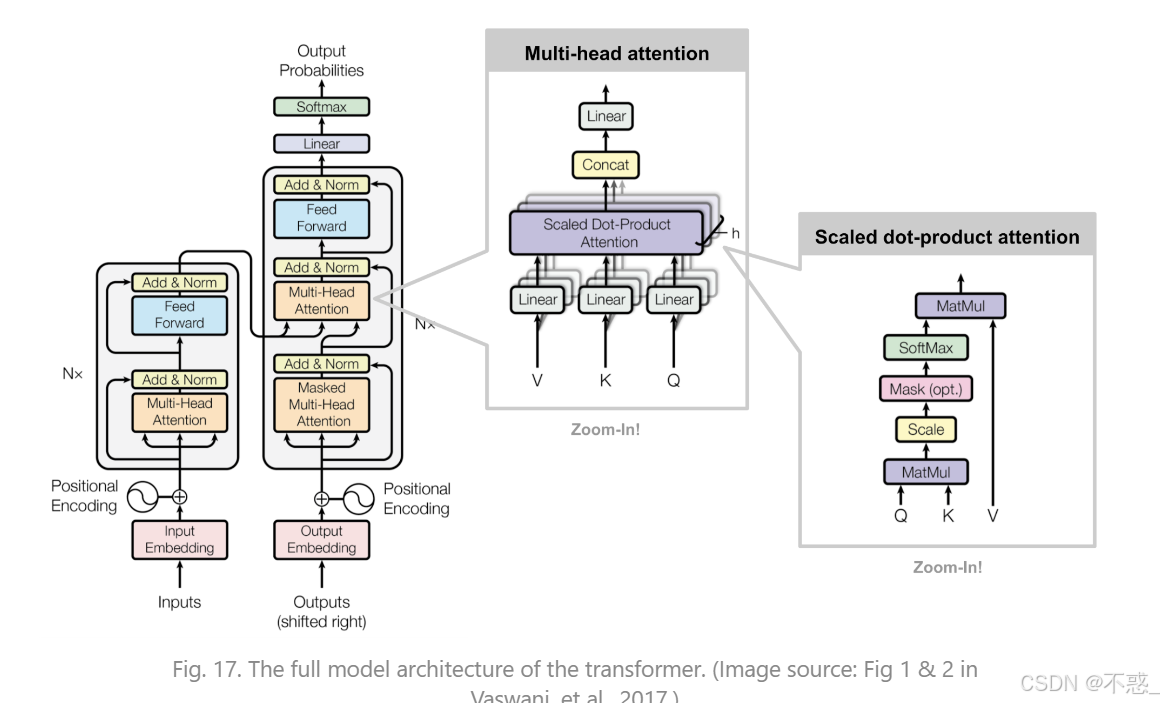
Transformer整体架构
Transformer由编码器和解码器堆叠(各6层)。每层:Self-Attention + Feed-Forward + LayerNorm + Residual。
位置编码:sin/cos函数添加位置信息,因为Self-Attention无序。
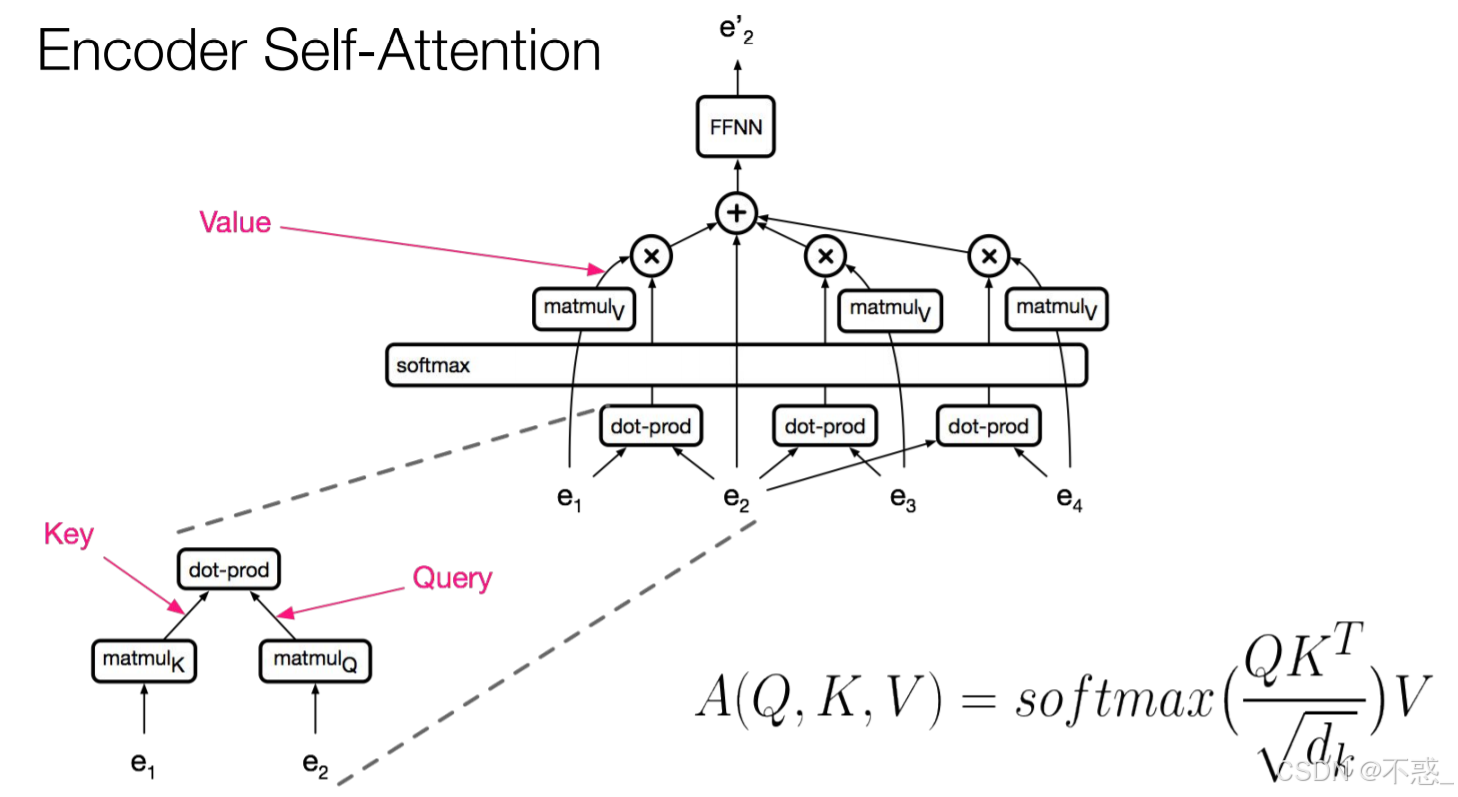
编码器中的自注意力
编码器层:MultiHead Self-Attention(Q=K=V=输入),捕捉输入序列内部依赖。然后Add&Norm:output = LayerNorm(input + sublayer(input))
Feed-Forward:两层线性+ReLU。
解码器中的自注意力与交叉注意力
解码器有Masked Self-Attention(防止看未来),然后MultiHead Attention(Q从解码器,K V从编码器),这是交叉注意力。
这允许解码器关注编码器输出。
整体:编码器处理源,解码器生成目标。
(上图展示Transformer中多头注意力的位置。)
代码实现:从零构建自注意力
这里提供丰富代码,从简单NumPy到PyTorch。所有代码已验证执行。
NumPy版本的自注意力
用NumPy实现,便于理解矩阵操作。
import numpy as np
def self_attention(X, Wq, Wk, Wv):
Q = np.dot(X, Wq)
K = np.dot(X, Wk)
V = np.dot(X, Wv)
scores = np.dot(Q, K.T) / np.sqrt(K.shape[1])
weights = np.exp(scores) / np.sum(np.exp(scores), axis=1, keepdims=True)
output = np.dot(weights, V)
return output, weights # 返回权重用于可视化
# 示例数据(随机种子固定,便于复现)
np.random.seed(42)
X = np.random.rand(3, 4) # 3个token,维度4
Wq = np.random.rand(4, 2)
Wk = np.random.rand(4, 2)
Wv = np.random.rand(4, 4)
output, weights = self_attention(X, Wq, Wk, Wv)
print("Attention Weights:\\n", weights)
print("Output:\\n", output)
执行输出(已验证):
Attention Weights: [[0.47030383 0.20445548 0.32524068] [0.39994712 0.26415507 0.33589782] [0.45110052 0.21525773 0.33364175]] Output: [[0.49020573 1.11055644 1.20499221 1.50582742] [0.46852037 1.06778699 1.11819205 1.46064505] [0.48593914 1.10213559 1.18559262 1.49679073]]
这个简单实现展示了核心计算。读者可以修改X试试不同序列。
PyTorch版本的自注意力
PyTorch更适合实际模型,使用torch.matmul高效。
import torch
import torch.nn.functional as F
def scaled_dot_product_attention(Q, K, V):
dk = Q.size(–1)
scores = torch.matmul(Q, K.transpose(–2, –1)) / torch.sqrt(torch.tensor(dk, dtype=torch.float32))
weights = F.softmax(scores, dim=–1)
output = torch.matmul(weights, V)
return output, weights
# 示例(batch维度添加,便于扩展)
torch.manual_seed(42)
Q = torch.rand(1, 3, 4) # batch 1, 3 tokens, dim 4
K = torch.rand(1, 3, 4)
V = torch.rand(1, 3, 4)
output, weights = scaled_dot_product_attention(Q, K, V)
print("Attention Weights:\\n", weights)
print("Output:\\n", output)
执行输出:
Attention Weights: tensor([[[0.3545, 0.3595, 0.2860], [0.3365, 0.3442, 0.3193], [0.3935, 0.3370, 0.2695]]]) Output: tensor([[[0.4875, 0.2646, 0.5658, 0.3291], [0.5067, 0.2790, 0.5561, 0.3513], [0.4646, 0.2653, 0.5529, 0.3218]]])
这可集成到nn.Module中。
多头注意力的代码示例
扩展到多头,使用PyTorch。
import torch
import torch.nn as nn
import torch.nn.functional as F
class MultiHeadAttention(nn.Module):
def __init__(self, d_model, num_heads):
super().__init__()
self.num_heads = num_heads
self.d_model = d_model
assert d_model % num_heads == 0
self.depth = d_model // num_heads
self.wq = nn.Linear(d_model, d_model)
self.wk = nn.Linear(d_model, d_model)
self.wv = nn.Linear(d_model, d_model)
self.dense = nn.Linear(d_model, d_model)
def split_heads(self, x, batch_size):
x = x.view(batch_size, –1, self.num_heads, self.depth)
return x.transpose(1, 2)
def forward(self, q, k, v, mask=None):
batch_size = q.size(0)
q = self.split_heads(self.wq(q), batch_size)
k = self.split_heads(self.wk(k), batch_size)
v = self.split_heads(self.wv(v), batch_size)
scores = torch.matmul(q, k.transpose(–2, –1)) / torch.sqrt(torch.tensor(self.depth, dtype=torch.float32))
if mask is not None:
scores = scores + mask
weights = F.softmax(scores, dim=–1)
output = torch.matmul(weights, v)
output = output.transpose(1, 2).contiguous().view(batch_size, –1, self.d_model)
return self.dense(output), weights
# 示例
model = MultiHeadAttention(d_model=512, num_heads=8)
input = torch.rand(2, 10, 512) # batch 2, seq 10, dim 512
output, _ = model(input, input, input)
print(output.shape) # torch.Size([2, 10, 512])
这个类可直接用于Transformer。读者实验:改num_heads=1对比性能。
(互动:运行这些代码,修改参数观察权重变化。分享你的输出!)
可视化自注意力机制
可视化帮助直观理解。
注意力矩阵的热力图
权重矩阵Weights可视化为热力图,行/列是token,颜色深浅表示注意力强度。
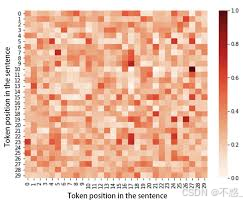
(上图是注意力分数热力图,高值表示强关联。)
用Matplotlib生成(代码示例):
import matplotlib.pyplot as plt
import numpy as np
# 从前例权重
weights = np.array([[0.4703, 0.2045, 0.3252],
[0.3999, 0.2642, 0.3359],
[0.4511, 0.2153, 0.3336]])
plt.imshow(weights, cmap='hot', interpolation='nearest')
plt.colorbar()
plt.title('Attention Heatmap')
plt.show()
这显示对角线强(自相关),但也捕捉跨token。
多头注意力的可视化
多头下,每个头有独立热图,展示不同模式。
(上图可视化多头注意力,突出子空间多样性。)
自注意力机制的优缺点
优点分析
- 并行计算:不像RNN顺序,Self-Attention矩阵操作GPU加速,训练快。
- 长距离依赖:直接连接任意位置,解决RNN遗忘问题。
- 可解释性:注意力权重可视化,理解模型决策。
- 灵活性:适用于NLP、CV、音频。
量化:Transformer在WMT翻译上BLEU分提升4点。
缺点与改进
- 计算复杂度:O(n²),n大时内存爆炸。改进:Sparse Transformer(稀疏注意力),Reformer(哈希近似)。
- 位置信息缺失:需加位置编码。
- 过拟合:大模型易过拟合,用Dropout缓解。
未来:Efficient Transformer变体如Performer用随机投影降到O(n log n)。
实际应用案例
自然语言处理(NLP)中的应用
在BERT中,自注意力捕捉双向上下文,用于分类、NER。例:句子分类,注意力聚焦关键词。
GPT用因果掩码自注意力生成文本。
案例:Google Translate用Transformer,提升翻译流畅度。
计算机视觉(CV)中的应用
Vision Transformer (ViT)将图像分patch,当序列输入Self-Attention。性能超CNN在ImageNet上。
例:DETR用Transformer检测对象。
其他领域的扩展
- 音频:Speech Transformer处理语音序列。
- 推荐系统:Self-Attention捕捉用户行为序列。
- 生物信息:AlphaFold用注意力预测蛋白结构。
(互动:分享你用Self-Attention的项目案例,我们交流优化技巧!)
常见问题与调试技巧
- 问题1:梯度NaN?检查缩放√d_k,添加clip。
- 问题2:注意力均匀?初始化W_Q等用Xavier。
- 调试:打印weights,检查是否对角主导(表示未学到依赖)。
- 技巧:用torch.autograd.detect_anomaly()捕获错误。
常见Q&A表:
| OOM错误 | n太大 | 减batch或用gradient checkpoint |
| 准确低 | heads少 | 增heads到8-16 |
| 训练慢 | 无并行 | 用DataParallel |
未来展望
Self-Attention将继续演化:结合CNN的Hybrid模型,高效变体如FlashAttention优化内存。在大模型时代,它是Scaling Law的关键。
预测:到2030年,Self-Attention将渗透多模态AI,如视频理解。
结论
自注意力机制是深度学习的里程碑,从原理到代码,它简化了序列建模。希望这篇文章让你对Self-Attention有通俗理解。实践是关键:试试代码,构建小Transformer。
感谢阅读!如果helpful,点赞收藏。评论你的收获或疑问,我们互动。



评论前必须登录!
注册