 网硕互联帮助中心
网硕互联帮助中心大家读完觉得有帮助记得关注和点赞!!!
摘要 无服务器计算提供了弹性扩展和按使用付费的执行模式,使其非常适合AI工作负载。由于这些工作负载在诸如边缘-云-空间三维连续体这样的异构环境中运行,它们通常需要密集的并行计算,而GPU执行此类计算的效率远高于CPU。然而,当前的平台难以有效管理硬件加速,因为静态的用户-设备分配无法在变化的负载或部署位置下确保服务等级目标(SLO)的合规性,而一次性动态选择通常会导致次优或成本效益低下的配置。
为了解决这些问题,我们提出了盖亚(Gaia),一种GPU即服务模型和架构,它将硬件加速变为平台关注的问题。盖亚结合了(i)一个轻量级的执行模式识别器,它在部署时检查函数代码,以发出四种执行模式之一,以及(ii)一个动态函数运行时,它持续重新评估用户定义的SLO,以在CPU和GPU后端之间进行升级或降级。我们的评估表明,它能够为工作负载无缝选择最佳的硬件加速,将端到端延迟降低高达95%。这些结果表明,盖亚能够在异构环境中为无服务器AI实现感知SLO且成本高效的加速。
CCS概念 • 软件及其工程 → 云计算;消息传递;中间件。
关键词 无服务器,FaaS,GPU,AI,边缘,云,低地球轨道,三维连续体
ACM参考格式: Maximilian Reisecker, Cynthia Marcelino, Thomas Pusztai, and Stefan Nastic. 2025. Gaia: Hybrid Hardware Acceleration for Serverless AI in the 3D Compute Continuum. In IEEE/ACM 12th International Conference on Big Data Computing, Applications and Technologies (BDCAT '25), December 1–4, 2025, Nantes, France. ACM, New York, NY, USA, 10 pages. https://doi.org/10.1145/3773276.3774299
本作品采用知识共享署名4.0国际许可协议进行许可。 BDCAT '25, 法国南特 ©2025 版权归所有者/作者所有。 ACM ISBN 979-8-4007-2286-8/2025/12 https://doi.org/10.1145/3773276.3774299
1 引言 无服务器计算提供了弹性扩展和按使用付费的模式,使其非常适合实时数据处理、物联网和AI推理等多种应用[20, 28, 56]。然而,无服务器平台中的硬件加速仍然具有挑战性。函数通常在不知道底层硬件的情况下部署,而开发人员必须手动决定函数应该在CPU还是GPU上运行。将函数静态分配给硬件资源增加了开发人员的复杂性,并且通常导致异构环境下的低效利用,在这些环境中,资源可能无法满足函数需求。
最近,配备星上计算资源和星间链路(ISL)的低地球轨道(LEO)卫星巨型星座的快速增长,使得太空中的新型范式成为可能,例如三维计算连续体[22, 39, 45]中的无服务器计算[7, 31]。三维计算连续体将边缘、云和LEO卫星统一为一个系统,创建了无缝的应用流。在此类环境中,高效的硬件加速变得至关重要。特别是,LEO卫星带来的挑战加剧了这个问题,例如随着卫星进出连接窗口而变化的资源可用性、受限的硬件容量以及随轨道动力学波动的网络条件[6, 16, 26]。因此,在部署时分配给GPU的函数可能在新调度的卫星节点上找不到GPU容量,从而导致调度延迟或失败。此外,一次性的动态决策可能会在临时工作负载高峰期间不必要地分配GPU,导致在资源稀缺且昂贵的环境中产生严重的成本效率低下。因此,函数可能因工作负载漂移而遭受性能下降,或因过度配置的GPU使用而产生额外成本。
实现无服务器硬件加速的常见方法包括:(a)静态的最先进方法[30, 41, 42]和商业方法[8, 10, 50]要求开发人员决定是在CPU还是GPU上运行。虽然这提供了细粒度的控制,但它增加了开发人员的复杂性和低效的资源分配,因为异构环境中的平台可能没有能力执行所需的硬件规格。这会导致延迟和潜在错误。(b)动态方法基于当前函数性能[4,5]迁移到GPU,或者基于资源可用性和用户定义的SLO(如性能和成本)在执行前确定[19, 49]。然而,大多数动态方法只做一次性的设备选择,并且不会随着负载变化而重新评估,这可能导致在工作负载漂移下性能下降或成本增加。
现有的支持硬件加速(即GPU无服务器函数执行)的最先进方法,要么依赖于开发人员的静态选择,要么依赖于一次性的动态设备选择[30, 47]。因此,它们无法适应异构和动态的环境,如三维计算连续体。随着卫星进出轨道以及连接窗口的变化,平台必须持续重新评估节点容量和可用的硬件资源。为了弥补这一差距,我们提出了盖亚(Gaia),一个用于无服务器平台中无缝硬件加速的抽象。盖亚使平台能够自动识别函数是需要GPU还是CPU执行,并在运行时动态调整执行,同时确保SLO合规性。我们的贡献包括:
-
盖亚:一种混合加速模型和架构,它抽象了函数需求,并支持在CPU和GPU之间进行无缝的运行时调整,同时遵守SLO。
-
执行模式识别器:在部署时识别具有GPU亲和性操作的函数,为无服务器平台提供提示,无需开发人员干预,例如配置或代码更改。
-
动态函数运行时重配置:在执行过程中随着工作负载或系统条件的变化动态调整硬件分配,必要时将任务执行移动到另一个节点,从而防止一次性决策固有的性能下降和成本效率低下。
本文共有八个部分。第2节介绍了说明性场景和研究问题。第3节描述了盖亚模型以及架构概述。第4节描述了盖亚引入的静态硬件标识符和动态运行时适配及其用法。第5节展示了原型实现细节。第6节讨论了实验和评估,第7节介绍了相关工作。第8节以最终讨论和未来工作结束。
2 说明性场景与研究挑战 为了更好地理解与硬件加速执行相关的挑战,在本节中,我们介绍我们的动机说明性场景和我们的研究挑战。
2.1 说明性场景 在偏远地区早期发现森林砍伐需要及时的数据处理和跨三维连续体的异构资源的有效利用。在我们的森林砍伐用例中(图1),地面传感器和无人机收集环境指标,如高分辨率图像、温度和二氧化碳水平。当在范围内时,无人机将数据卸载到附近的边缘节点;否则,它们直接将数据传输到LEO卫星,确保即使在边缘网络不可用时也能保持高可用性。此外,LEO卫星还可以将来自无人机的地面数据与对地观测(EO)卫星(包括光学和红外数据)的图像进行融合。组合后的数据流通过一个无服务器工作流进行处理,该工作流包括数据摄取、图像分割和模式识别函数,以检测森林砍伐热点。通过将这些任务分布在边缘、云和太空,三维连续体减少了数据传输开销,降低了检测延迟,并支持对每日高达1.5TB的大型EO数据集进行可扩展分析,否则将这些数据传输到地面云服务的成本将非常高昂[3, 17]。盖亚通过抽象CPU/GPU硬件选择来增强此工作流,确保资源密集型函数(如对象检测或准备数据集)无缝利用边缘节点或LEO卫星上的可用GPU,而无需开发人员手动指定执行设备。盖亚静态代码分析器在部署时识别具有GPU亲和性的函数,提供执行提示,防止为轻量级函数(如摄取)不必要地分配GPU。此外,盖亚的自适应运行时重配置允许平台在卫星进出轨道或工作负载强度变化时动态重新分配函数,尽管资源可用性波动,仍能保持SLO合规性。因此,盖亚使森林砍伐检测工作流能够在地面链路拥塞时利用星载GPU,或者在GPU容量有限或不可用时回退到CPU,从而优化性能和成本,同时确保无中断的无服务器执行。
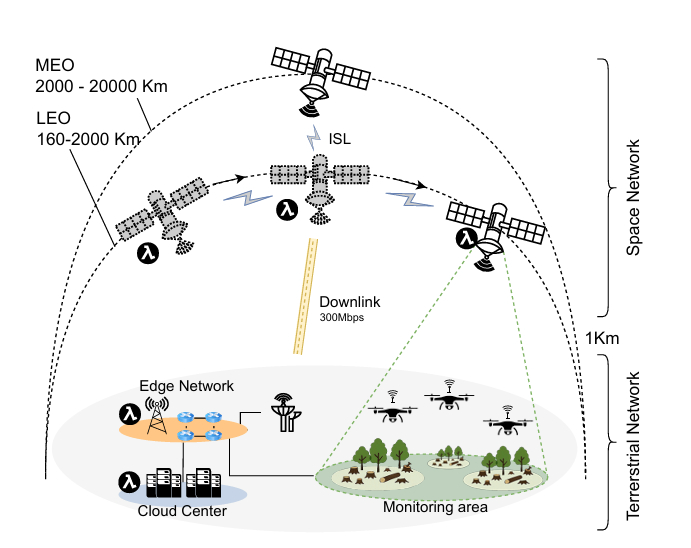
2.2 研究挑战 RC-1:在三维计算连续体的资源约束和动态条件下,无服务器AI函数如何保持最佳执行性能? 三维计算连续体范式通过利用各层的独特优势,统一了边缘-云和LEO卫星。星上处理对于下游应用(如对地观测分析)特别有益,因为它避免了依赖于轨道通过的、成本高昂且容易导致延迟的下行传输,这通常需要数小时[12, 54]。下游应用通常涉及需要硬件加速的AI工作负载,例如GPU。随着卫星进出范围,某些函数必须保持与特定地理监测区域的陆地锚定,需要迁移到不同的卫星并调整执行以维持SLO合规性。虽然GPU在卫星上变得越来越普遍[9, 59],但其容量仍然受到功率限制[13, 37]、热限制和抗辐射加固要求[18, 55, 57]的限制。因此,明智地使用可用容量至关重要。
RC-2:如何无缝识别函数的硬件需求,例如GPU? 识别无服务器函数的硬件需求是一项重要但具有挑战性的任务,以确保其端到端运行时SLO得到满足并且成本得到控制[32, 33]。对于CPU和内存需求,有各种方法可以通过离线分析[11, 46, 51, 58, 62]或通过基于先前结果调整函数资源的在线优化[15, 29, 38, 61]来自动化此过程。对于GPU,无服务器函数通常使用两种方法:一种是细粒度共享方法,将整个GPU分配给一个函数[20, 23, 25];另一种是空间分区[14, 24, 60]。然而,运行中的内核无法被中断;因此,分配在其执行期间持续存在。为了避免资源过少,许多系统倾向于过度配置GPU资源,从而导致容量浪费[36],这在卫星或边缘设备上必须避免。
RC-3:如何动态更改函数运行时在CPU和GPU之间切换,以平衡性能和成本SLO? 通常,无服务器函数依赖于连接硬件和函数之间通信的运行时[21, 52]。然而,开发人员通常必须静态选择函数是应该使用支持GPU的运行时(具有较长的冷启动延迟)还是仅使用CPU的运行时[30, 41, 42]。这可能导致GPU资源的过度配置或将函数限制在CPU上,即使它们可以从GPU中受益。使此决策动态化的一种简单方法是首先在CPU上运行函数,如果它违反了端到端SLO,则将其移动到GPU[48]。一种更复杂的动态方法是预测函数的执行时间,并根据端到端SLO和成本约束动态地将其分配到CPU或GPU[49]。然而,估计函数的执行时间并非易事,并且为每次调用运行此决策逻辑可能会增加相当大的开销。
3 盖亚设计原则与架构 在本节中,我们概述盖亚的设计原则并描述实现这些原则的架构。
3.1 盖亚设计原则 盖亚旨在使硬件加速成为平台关注的问题,同时保持函数的可移植性并减少开发人员的工作量。因此,我们遵循指导我们架构的原则,这些原则在第4节和第5节描述的机制中得到了体现。
-
硬件无关性:函数编写时不绑定硬件加速设备;执行模式在部署时推断并在运行时调整。
-
零开发人员摩擦:无需代码更改;开发人员可以选择自动(盖亚)|cpu|gpu,或者依赖执行模式识别器透明地选择最佳的硬件加速。
-
智能启动与动态切换:在部署函数时,盖亚执行静态分析以确定最适合的初始配置。此决策在运行时定期重新评估,必要时动态切换到不同的执行模式。
-
可观测性设计:每个运行时决策都由遥测数据支持,这些数据监视SLO要求(如延迟和吞吐量),并持久化决策依据(最后模式、测量的延迟)。
3.2 盖亚架构 盖亚利用静态代码特征来识别硬件执行模式,并通过监控来评估动态运行时更改,以便在异构硬件加速后端上为无服务器函数提供服务,同时将开发人员的负担降至最低。函数部署时带有由静态代码分析器离线推断的初始执行模式;在运行时,盖亚持续评估SLO指标,以升级或降级函数的后端,使性能和成本与三维计算连续体中的SLO保持一致。
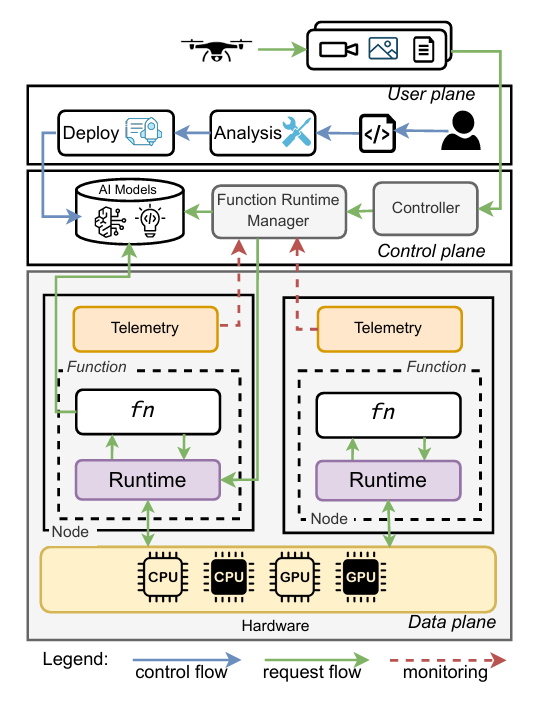
图2所示的盖亚架构分为三个平面:用户平面、控制平面和数据平面。在用户平面中,静态代码分析器对函数进行分类,并使用执行提示注释清单。在控制平面中,协调器执行动态运行时管理,与遥测形成闭环,以实施安全、无缝的模式切换。在数据平面中,函数代码和运行时执行,与底层托管栈接口以利用适当的硬件加速,例如根据需要使用的CPU或GPU后端。
3.2.1 盖亚组件。盖亚由六个主要组件组成:代码分析器、构建和部署、控制器、函数运行时管理器、函数运行时和遥测。
-
代码分析器:代码分析器在部署前检查无服务器函数。它将函数代码解析为抽象语法树(AST),以识别与GPU相关的导入、显式设备调用和张量操作。基于这些启发式方法,它分配一个执行模式(cpu、cpu_preferred、gpu_preferred、gpu),并相应地注释函数清单。这确保了无服务器平台在不需更改用户代码的情况下,在合适的节点上调度函数。
-
构建和部署:盖亚支持三种不同的部署模式,允许开发人员明确指定函数应在CPU、GPU上运行,还是使用盖亚的自适应模式。当选择自适应模式时,在构建和部署期间会调用代码分析器,并将其结果嵌入到无服务器平台的函数部署中。
-
控制器:它管理函数的生命周期,以及函数如何暴露、扩展和更新。它管理传入请求并将其分发给可用的实例,根据需求调整活动实例的数量,并协调更新,以便新版本的函数可以替换旧版本而不会中断正在进行的请求。它还负责根据从函数运行时管理器接收到的硬件加速规范,在节点上调度函数。
-
函数运行时管理器:它监视已部署的函数,并无缝应用函数运行时模式切换。它通过与控制器交互,提供硬件加速提示,以便在性能和成本SLO超出时动态调整函数。在CPU和GPU之间动态切换确保了异构硬件的有效利用,同时最大限度地减少对正在进行的函数执行的干扰。
-
函数运行时:盖亚通过容器垫片支持多个执行后端。默认的容器垫片在CPU上执行函数,而NVIDIA容器运行时垫片支持GPU加速。通过使用适当的垫片重新部署函数来实现执行模式切换,允许盖亚利用GPU资源而无需修改用户工作负载。
-
遥测:该组件收集运行时指标,如请求延迟、吞吐量和资源利用率。这些统计信息被存储并由函数运行时管理器持续监控。遥测提供了反馈循环,允许盖亚做出明智的适配决策,确保执行模式更改基于实际的性能数据。
4 盖亚机制 在本节中,我们介绍了盖亚用于在CPU和GPU之间适配无服务器函数的机制:一个静态的执行模式识别器,它从源代码推断初始模式;以及一个动态函数运行时,它监控延迟和请求速率,以在最小化延迟和成本并满足SLO的前提下进行升级或降级。
4.1 执行模式识别器 执行模式识别器提供了适配函数运行时的第一个决策步骤。其目的是在部署前分析无服务器函数的静态代码,并将其分配到合适的执行模式。通过检查导入、显式硬件调用和计算模式,该组件预测函数是最适合在CPU上执行、需要GPU加速,还是可以在两者上运行但有所偏好。这种静态分类减少了不必要的运行时开销,确保明确的情况(例如,显式GPU使用)得到确定性处理,并将更模糊的情况留给动态运行时适配机制稍后进行微调。
执行模式识别器分析无服务器函数的源代码,以分配四种执行模式之一:cpu、gpu、cpu_preferred和gpu_preferred。
函数代码首先被解析成AST(第1行),并初始化标志以记录相关模式(第2行)。然后逐个节点遍历AST(第3行)。深度学习框架(如PyTorch或TensorFlow)的导入设置dl_import标志(第5行)。显式的GPU调用,如torch.device("cuda")或.to("cuda"),设置gpu_explicit标志(第7行)。分析张量操作以估计工作负载大小;根据结果,标记big_ops或small_ops(第9行)。
在决策时(从第12行开始),算法遵循分层过程。显式GPU调用强制使用gpu模式。大型张量操作结合深度学习导入,导致gpu_preferred。小型张量操作或没有重度使用的导入导致cpu_preferred。当未检测到与GPU相关的活动时,执行模式默认为cpu。算法最终返回选择的模式及其推理原因(第23行)。
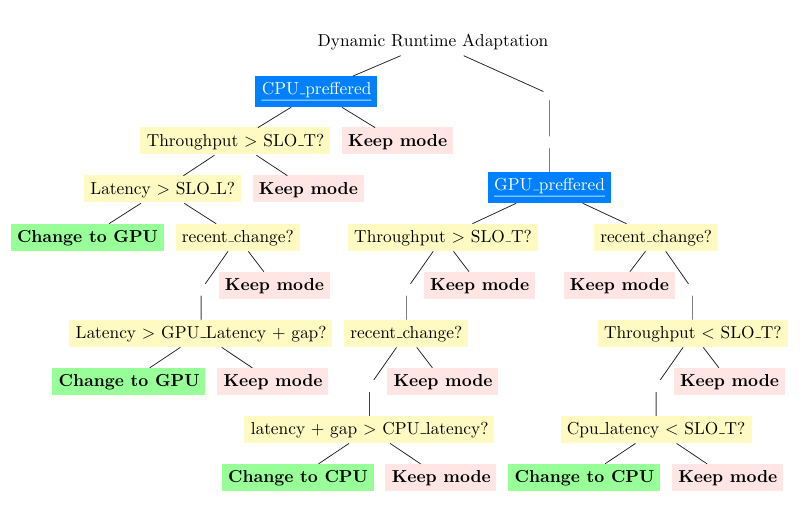
4.2 动态函数运行时适配 动态函数运行时适配持续监控已部署的无服务器函数,并在cpu_preferred和gpu_preferred之间调整它们的执行模式。为了实现这一点,动态函数运行时适配向编排器提供关于函数应在CPU还是GPU上执行的适应性提示;然后编排器处理调度决策。它依赖于从遥测收集的请求速率和延迟指标,以及可配置的阈值,来决定函数是否应该切换其执行环境。这确保了当工作负载证明合理时,函数可以从GPU加速中受益,同时在CPU足够时避免不必要的GPU使用。
函数运行时适配如图3所示,并在算法2中以伪代码形式描述。算法首先检查当前的执行模式(第1行)。如果函数以cpu_preferred模式运行,则仅在请求速率超过冷启动缓解阈值时才考虑切换到GPU(第2行)。在此条件下,高延迟或最近一次更改且性能比保存的GPU延迟加上安全裕度更差(第3行)会触发切换到GPU(第4行)。如果函数以gpu_preferred模式运行(第7行),重新评估器在满足两个条件时考虑切换回CPU。首先,当请求速率很高,但观察到的延迟加上裕度仍然比保存的CPU延迟差时(第8行),模式切换到CPU(第9行)。其次,当请求速率低于较低阈值且CPU性能可接受时(第11行),函数也切换到CPU(第12行)。如果这些条件都不适用,函数保持其当前模式(第15行)。
-
冷启动缓解:为了防止由冷启动伪影引起的模式切换,盖亚加入了请求速率保护机制。仅当观察到的请求速率超过可配置的阈值时才考虑模式更改,确保来自很少调用的函数的异常延迟不会影响决策。额外的保护措施,例如CPU和GPU延迟之间的性能差距裕度,可以防止模式之间的不必要振荡。
5 原型实现 盖亚的原型已作为开源项目提供¹。盖亚动态运行时适配使用Python编写,而静态代码分析器使用Go编写。
-
执行模式识别器:静态分析器在部署时检查Python函数。它将函数源代码解析为抽象语法树(AST),并评估诸如框架导入(例如PyTorch、TensorFlow)、显式GPU调用和张量操作等指标。为了将盖亚分类集成到部署管道中,Knative func CLI扩展了一个新的–deployment-mode标志(auto、cpu、gpu)。当设置为auto时,静态分析器会自动调用,其决策通过注释和资源限制嵌入到Knative Service清单中。这确保了Kubernetes调度器将函数正确地放置在CPU或GPU节点上。
-
动态函数运行时管理器:动态函数运行时管理器作为一个Python服务实现,作为Kubernetes Deployment运行。它使用Kubernetes API来检查Knative Service规范,并查询遥测服务(即Prometheus)以检索运行时指标。当满足定义的条件时,管理器更新Knative Service清单以修补资源注释,允许Knative在适当的硬件上无缝推出新版本。
6 评估 为了评估盖亚,我们设计了一组代表常见和对比工作负载类型的工作负载。我们旨在跨不同执行模式(CPU vs. GPU)和使用场景评估我们的框架,突出优势和局限性。每个工作负载被顺序部署和执行,以确保隔离的测量。我们的目标是通过平衡性能和成本权衡,为具有不同特征的工作负载确定最佳执行模式。
-
实验工作负载:我们使用四个代表性工作负载评估该框架,这些工作负载对CPU/GPU执行的不同方面施加压力。我们的工作负载是:(1)矩阵乘法模型,一种密集型计算任务,其复杂性随输入大小增长,揭示了决策运行时适应执行模式的能力。(2)使用ResNet-18的图像分类[27],以及(3)使用TinyLlama的大型语言模型(LLM)推理[2]代表了受益于GPU加速的现实AI任务,范围从中度到高度需求的推理。(4)空闲等待函数,由wait_time参数化,提供了一个没有有用计算的退化情况,作为性能比较的下限。尽管我们的说明性场景(第2.1节)重点介绍了三维计算连续体中的森林砍伐,但盖亚专注于跨不同工作负载的硬件加速,与特定应用领域无关。因此,为了评估盖亚,我们使用受控且具有代表性的AI工作负载,包括计算密集型任务、小型AI模型和大型语言模型(LLM),这些反映了典型实际用例(包括我们说明的场景)的计算和内存特征。因此,我们的实验设计隔离了盖亚的贡献,并促进了对其决策逻辑的可重现、硬件无关的评估。
-
指标与基线:对于所有实验工作负载,我们收集延迟和成本。结果针对CPU、GPU和盖亚收集,价格基于微软Azure定价模型[1]。我们的目标是为每个用例评估在CPU和GPU上执行的性能和成本权衡。
6.1 实验设置 为了评估盖亚,我们部署了一个MicroK8s [35]集群,包含三个具有不同硬件配置的节点,以模拟三维计算连续体的异构环境。一个节点具有4个vCPU,无GPU,8GB RAM;以及两个工作节点。第一个工作节点有8个vCPU,32 GB RAM,无GPU;另一个工作节点有16个vCPU,64 GB RAM,和一个GPU NVIDIA GeForce RTX 3090 24GB。每个节点运行Ubuntu Server for ARM 24.04 LTS。实验工作流作为Knative [44]服务部署。为避免结果偏差,所有实验执行5次,显示的结果为相应的平均值。
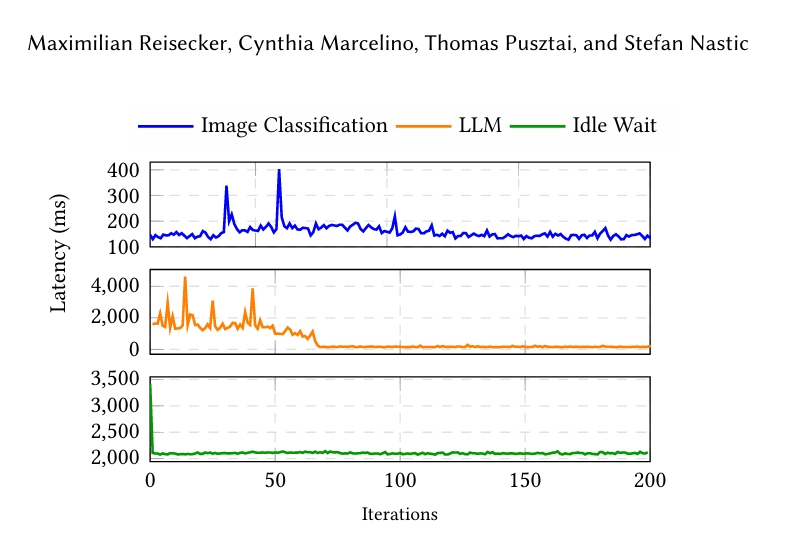
6.2 实验结果 6.2.1 总体延迟。图4显示,一旦盖亚将后端从CPU升级到GPU,它能将延迟降低高达95%。
-
图像分类:盖亚维持了145毫秒的中位响应时间,偶尔峰值达到403毫秒。然而,延迟峰值并不足够高,因此图像分类完全在CPU上运行。
-
LLM:在此实验中,盖亚显示出特征性的双区域曲线:初始稳定响应时间主要在1.3-2.3秒(偶尔异常值高达4.6秒),随后急剧下降到稳定在140-200毫秒左右的波段。一旦SLO被违反,盖亚的运行时策略从CPU绑定路径切换到加速路径(GPU或等效的快速层),从而显著降低延迟。
-
空闲等待:盖亚首先因为高延迟将执行模式更改为GPU。之后,算法检测到延迟没有显著差异,因此将执行模式更改回CPU,维持接近2秒的延迟。
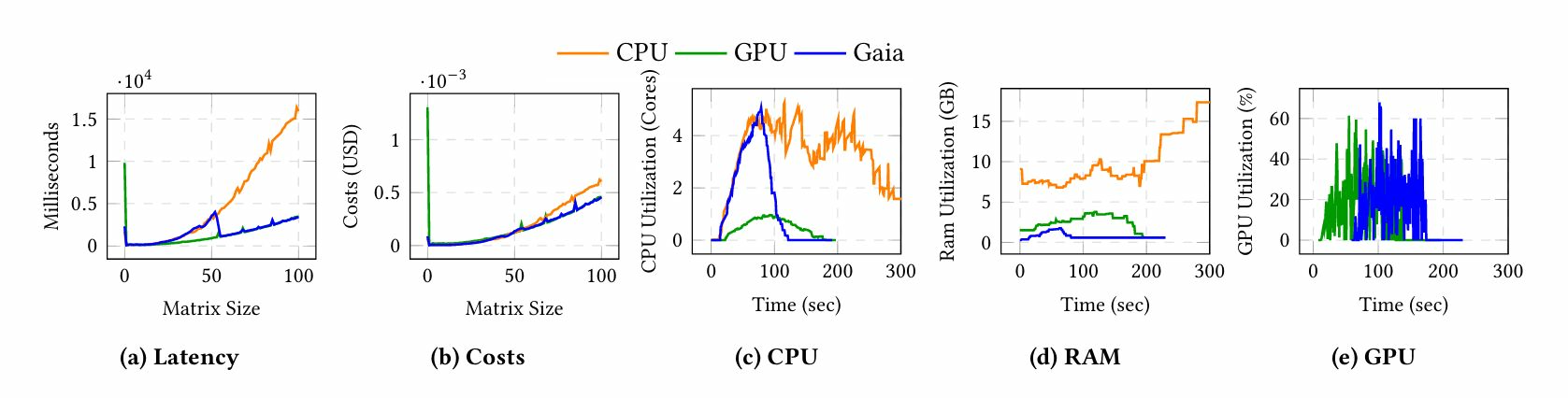
矩阵乘法:Gaia在达到SLO后升级至GPU,与CPU相比,在延迟和成本上产生明显的阶跃式下降。
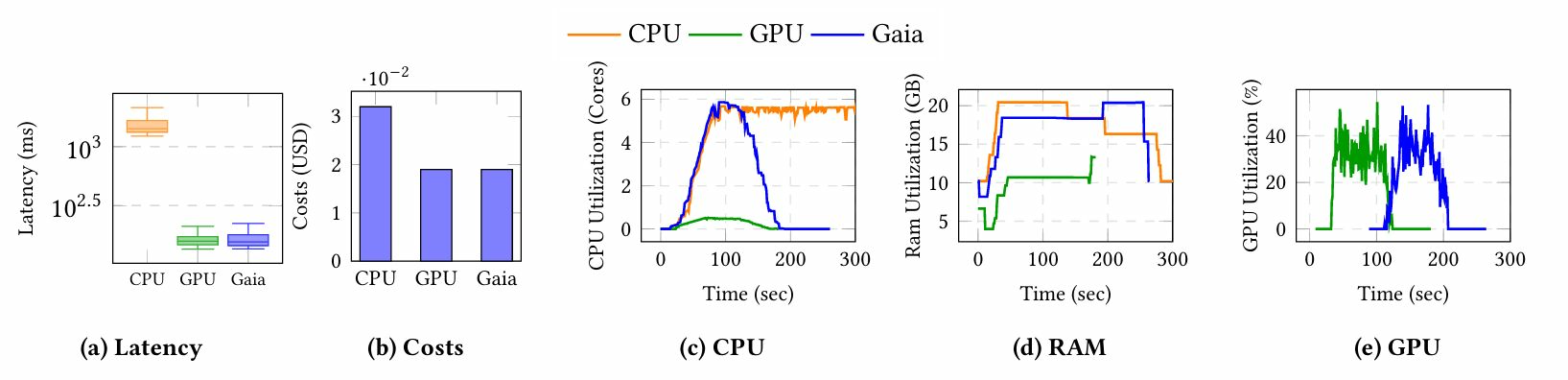
大语言模型(LLM):初始CPU阶段触发升级;切换至GPU后,延迟在加速层以更低成本实现稳定。
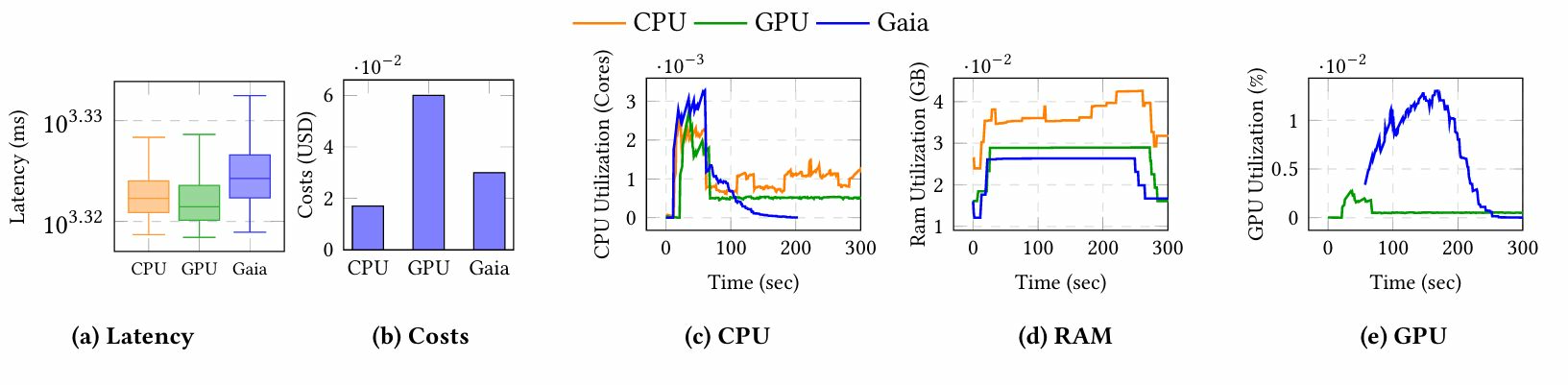
空闲等待:GPU升级后未带来延迟降低,Gaia再次降级回CPU。
6.2.2 矩阵乘法结果。图5显示,随着矩阵大小的增加,盖亚执行模式识别器返回CPU,这解释了盖亚在升级到GPU之前的初始高延迟。
-
延迟:显示所有模式对于小矩阵表现相似。在达到SLO后,盖亚切换到GPU后端,与CPU相比,响应时间实现了明显的阶跃下降。图5a中的箱线图捕捉了这种分布变化:随着大小的增加,CPU发展出长尾,而盖亚在升级后延迟显著降低。
-
成本:随着执行时间随矩阵大小增长,CPU成为最昂贵的选项(图5b)。盖亚早期跟踪类似CPU的成本,然后在升级后遵循较低的GPU成本曲线,因为请求完成得更快。GPU在开始时由于冷启动成本而承担最大成本,但一旦预热后具有竞争力。
-
CPU/RAM使用情况:图5c和图5d显示,对于相同的工作负载窗口,GPU支持的执行使用的CPU和RAM显著少于CPU函数。两个橙色垂直标记表示盖亚的切换点。图5e显示盖亚比GPU模式更晚使用GPU:后者在冷启动后立即在GPU上运行(尽管冷启动时间较长),而盖亚仅在SLO被违反时才升级,最大限度地减少了在昂贵或不必要的加速上花费的时间。
6.2.3 LLM推理结果。对于提示(“法国的首都是什么?”),盖亚最初识别为CPU;一旦运行延迟违反SLO,盖亚就升级到GPU。升级后,盖亚在延迟和成本上与GPU模式表现无异,同时避免了大的GPU冷启动惩罚。
-
延迟:图6a中的箱线图显示,一旦升级,盖亚与GPU保持一致,而剩余的异常值归因于升级前的CPU阶段,CPU总体上表现出更高的延迟。
-
成本:图6b显示,使用测量的总值(CPU: 0.03206, GPU: 0.01914, Gaia: 0.01910),盖亚和GPU比CPU便宜40%。在升级后延迟直接崩溃后(图6a),盖亚和GPU是相同的。
-
资源使用情况:在CPU上,利用率很高;在盖亚升级到GPU后,CPU负载下降,GPU利用率上升以高效地服务推理(图6c和图6e)。每个请求的RAM(图6d)由于在GPU上服务时间更短而稳定/下降。
6.2.4 空闲函数结果。图7显示,盖亚在高延迟时短暂升级到GPU,发现没有改进,然后返回到CPU。净效应:类似CPU的延迟和成本,伴有一次短暂的GPU绕行。
-
延迟:高初始延迟触发升级到GPU,但由于任务不适合GPU,延迟并未下降;因此,盖亚降级回CPU(图7a)。箱线图确认盖亚与CPU保持一致,除了短暂的GPU窗口期。
-
成本:成本曲线在GPU间隔期间显示出一个小的凸起,然后收敛到CPU成本轨迹(图7b)。
-
资源使用情况:资源跟踪(图7c和图7d)在不同模式下保持相似;在GPU上没有出现持续的CPU或RAM缓解,因为工作负载花费时间等待而不是计算。
7 相关工作 在本节中,我们分析了最先进的挑战,以及它们与盖亚在三维计算连续体和GPU支持的无服务器计算方面的区别。
7.1 三维计算连续体中的无服务器计算
-
HyperDrive[45]提出了三维连续体中无服务器计算的架构,其特点是包含一个考虑环境动态和异构特性(如节点邻近度、热条件和功率约束)的函数调度器。虽然HyperDrive考虑了环境特征,但它不会在运行时根据工作负载特定特征进行适配。
-
OrbitFaaS[53]介绍了一种利用原位计算能力的对地观测数据处理的元服务器平台。OrbitFaaS引入了轨道模型和通信抽象,可在三维连续体中实现优化的数据处理和AI工作负载。
-
Komet[43]提出了一种针对LEO定制的无服务器平台,可在卫星轨道轨迹上无缝复制函数数据。
-
Databelt[40]通过沿着工作流执行路径主动放置函数状态,实现有状态的无服务器函数执行。 然而,OrbitFaaS、Komet和Databelt侧重于函数之间的数据管理和交换,并未提供工作负载感知的执行,这影响了函数的性能。
-
ML-SDN[34]提出了一种无服务器软件定义网络(SDN)架构,该架构动态编排通信和计算资源以满足多样化的6G服务等级协议(SLA)。通过动态调整工作负载,ML-SDN提高了端到端的学习性能。
-
Krios[7]引入了无服务器函数的调度抽象,使得函数能够放置在特定的地理区域。Krios软件定义的LEO区域利用卫星路径预测模型来主动预测无服务器函数的切换。 然而,ML-SDN和Krios主要关注网络和控制平面编排,并未提供允许平台无缝决定硬件加速的函数抽象。
-
Cosmos[39]提出了边缘-云-太空三维连续体中函数放置的性能-成本权衡模型。然而,Cosmos没有解决特定的节点需求。
尽管讨论的最新技术支持在三维计算连续体中进行无服务器执行,但它们要么侧重于网络或特定的编排组件,没有考虑无服务器函数的异构工作负载特征。相比之下,盖亚无缝识别硬件加速,并引入运行时工作负载适配以满足节点和用户定义的性能要求。
7.2 GPU支持的无服务器计算 有几种方法支持无服务器平台中的GPU。
-
Kim等人[30]、OSCAR扩展[41]和KaaS[42]要求开发人员明确指定函数是在CPU还是GPU上执行。一些商业平台,包括RunPod[50]、Cerebrium[8]和Beam Cloud[10],提供GPU共享,但不包含用于CPU与GPU执行的自动化决策过程。虽然这种方法在配置正确时提供了对资源分配的完全控制并确保了高效的GPU使用,但它增加了开发复杂性并存在低效资源利用的风险。
-
动态方法,如Llama[49]和DGSF[19],在运行前基于资源可用性或用户定义的SLO(如性能、成本)自动确定执行设备。虽然它们允许高效的资源使用和适应工作负载变化,但它们也引入了额外的决策开销并增加了系统复杂性。
-
Protean[5]提出了一种支持GPU的无服务器框架,该框架利用新一代NVIDIA GPU功能,如多实例GPU(MIG)和多进程服务(MPS),以提高SLO合规性并降低成本。尽管Protean避免了CPU相关的开销并最大化GPU性能,但它所有任务都专门在GPU上运行,牺牲了灵活性,并且当工作负载不需要GPU加速时可能产生不必要的成本。
尽管现有的工作推进了GPU支持的无服务器计算,但它依赖于手动开发人员干预或在执行前执行静态设备选择。相比之下,盖亚结合了执行前决策和运行时工作负载适配,使平台能够在执行期间根据性能和成本要求无缝调整硬件加速。
8 结论 在本文中,我们提出了盖亚(Gaia),一种GPU即服务模型和架构,它将设备选择从开发人员转移到平台。盖亚结合了一个执行模式识别器(从源代码分配初始硬件加速模式)和一个动态函数运行时(根据SLO重新评估此选择)。我们的实验结果表明,盖亚升级了可加速的工作负载,并降级了不可加速的工作负载。在矩阵乘法、图像分类、LLM推理和一个空闲基线上,将端到端延迟降低了高达95%。
在未来的工作中,我们将通过结合预测性的、基于学习的策略和工作流级目标来增强动态运行时决策。此外,我们将把三维计算连续体的动态性,包括LEO切换、功率和热约束以及间歇性链路,集成到我们的放置和模式决策中。



评论前必须登录!
注册