 网硕互联帮助中心
网硕互联帮助中心大家读完觉得有帮助记得关注和点赞!!!
摘要
近年来,部分音频伪造已成为一种新的音频篡改形式。攻击者有选择性地修改部分但语义关键的帧,同时保持整体的感知真实性,使得此类伪造尤其难以检测。现有方法侧重于独立检测单个帧是否被伪造,缺乏捕捉不同时间级别上瞬时和持续异常的层次结构。为了解决这些局限性,我们识别了与部分音频伪造检测相关的三个关键级别,并提出了 T3‑Tracer,这是第一个在帧、片段和音频级别联合分析音频以全面检测伪造痕迹的框架。T3-Tracer 由两个互补的核心模块组成:帧-音频特征聚合模块(FA-FAM)和段级多尺度差异感知模块(SMDAM)。FA-FAM 旨在检测每个音频帧的真实性。它结合了帧级和音频级的时间信息来检测帧内伪造线索和全局语义不一致性。为了进一步细化和校正帧检测,我们引入了 SMDAM 来在段级别检测伪造边界。它采用双分支架构,联合建模多尺度时间窗口内的帧特征和帧间差异,有效识别出现在伪造边界上的突变异常。在三个具有挑战性的数据集上进行的大量实验表明,我们的方法达到了最先进的性能。
引言
AI生成内容的进步带来了前所未有的音频合成能力。然而,这种进步也助长了新一波的音频伪造,威胁着媒体、法律和通信等领域信息的可信度。最近,内容驱动的部分音频伪造作为一种特别隐蔽的变体引起了关注。如图1(a)所示,攻击者修改关键帧或短语以改变语义,同时保持音频的整体声学真实性,这大大增加了检测和伪造区间定位的难度。
为了应对日益增长的部分音频伪造威胁,最近的研究引入了专门的基准,并将任务形式化为两个:部分伪造检测(PFD)和时间伪造定位(TFL)。其中,PFD 将问题表述为单帧二元分类,TFL 负责将离散的帧分类转换为连续的伪造区间,并在时间区间上进行进一步校正,这通常通过线性回归头实现。因此,提高 PFD 的检测准确率是解决 TFL 任务的关键。
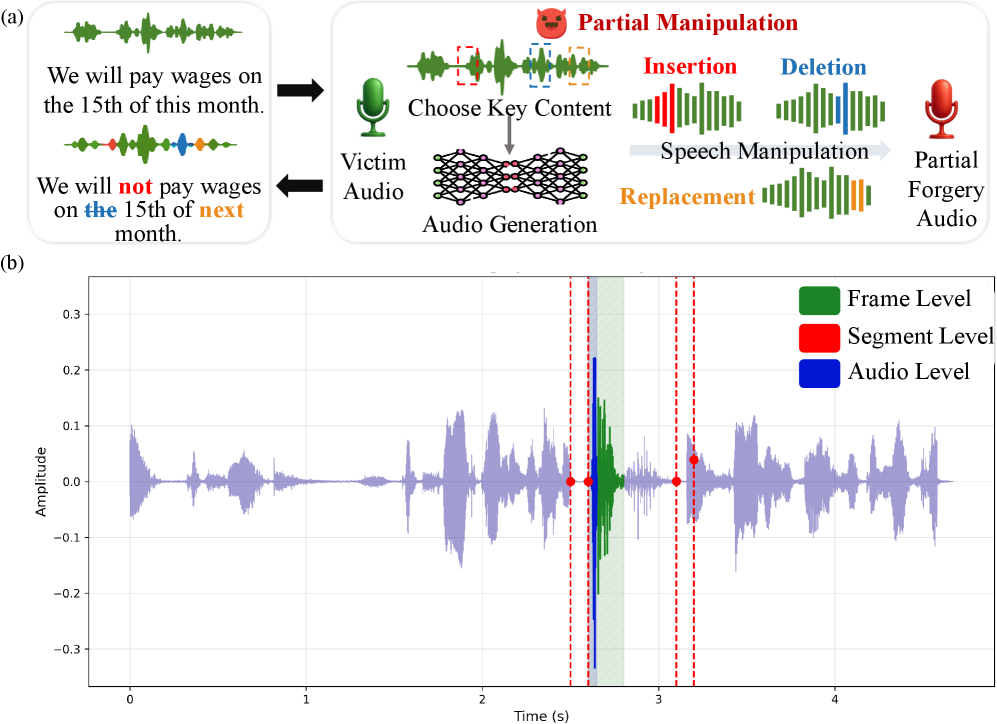
图1:(a) 部分音频伪造生成示意图,对关键区域的细微操作可能导致高度欺骗性的音频。(b) 伪造帧在不同时间级别的表现。例如,伪造帧在帧级别显示出大的波动包络,在段级别显示出异常突变,在音频级别显示出突出的振幅。
现有的部分伪造检测方法大致可分为两类:帧伪造分类和边界检测。第一类将音频序列视为一组独立的帧,并根据通道或频谱特征的异常对每个帧进行分类。虽然这种方法直观且简单,但它仅在帧级别操作,忽略了在更宽时间尺度上可能出现的潜在语义不一致性。此外,逐帧分类通常会导致分散的误报,使得在后续的时间伪造定位过程中难以形成连贯的伪造区间。第二类旨在识别伪造片段的起点和终点,通常使用 CNN 或时间掩蔽机制。然而,这些方法仍然依赖于逐帧预测,并且缺乏明确的上下文建模结构,因此难以捕捉边界帧与其周围邻居之间的突然过渡异常。该分析证明了多尺度时间建模对于全面捕捉部分音频伪造的多样化特征的重要性。
基于对伪造音频波形的广泛分析,如图1(b)所示,我们揭示了与部分音频伪造检测相关的三个时间级别:帧、片段和音频。帧级别指的是单个音频帧。片段级别指的是以目标帧为中心的局部帧窗口。音频级别指的是跨越整个音频序列的全局上下文。由 AIGC 生成的伪造内容可能在每个级别都表现出异常。在帧级别,伪造帧通常包含异常的通道或频谱模式。在音频级别,与真实帧相比,它们可能显示出全局不一致性——例如说话人身份、韵律或背景噪声的不匹配。在片段级别,真实区域和伪造区域之间的过渡边界通常表现出突然的不一致性。这些反映为片段中心帧与其相邻上下文之间的异常突变。
受这些观察的启发,我们提出了 T3-Tracer,一个用于部分音频伪造检测和定位的多粒度时间建模框架。T3-Tracer 由两个核心且互补的模块组成:帧-音频特征聚合模块(FA-FAM)和段级多尺度差异感知模块(SMDAM)。FA-FAM 通过聚合单帧声学特征和全局语义上下文来聚焦于帧伪造检测,为每个帧提供多视角特征。SMDAM 专为边界检测而设计。它采用双分支结构来建模原始帧序列和帧间差异,并在多尺度时间片段上应用注意力机制以捕捉伪造边界附近的突然过渡异常。为了减少分散的误报帧,我们集成了一个交叉注意力机制来显式拟合帧和边界伪造线索之间的依赖关系,进一步提高了 PFD 的检测鲁棒性和 TFL 的定位精度。我们的主要贡献总结如下:
• 我们揭示了与部分音频伪造检测相关的三个关键级别,并提出了 T3-Tracer,这是一个新颖的三级时间感知框架,在帧、音频和片段级别全面建模音频伪造特征。据我们所知,这是首个系统性地为部分音频伪造检测和定位引入多粒度时间建模的工作。
• 我们设计了两个互补的模块:FA-FAM 和 SMDAM。FA-FAM 在帧和音频级别操作,并结合帧内伪造线索与全局语义不一致性来执行帧伪造检测。SMDAM 专注于片段级别,在多尺度时间片段内建模原始帧特征和帧间差异以检测伪造边界。
• 我们在三个具有挑战性的数据集上进行了广泛的实验,证明 T3-Tracer 在各种指标和场景下 consistently 优于最先进的方法。
相关工作
音频伪造检测
音频伪造检测侧重于确定输入音频是否包含被篡改或合成的内容。该领域的早期方法主要针对话语级检测,旨在区分完全生成或操纵的语音与真实录音。例如,DARTS 提出了一种由卷积块和残差块组成的端到端架构,同时学习深度语音表示和决策边界。ASDG 引入了一个领域泛化框架,联合优化特征聚合和分离,以提高对未见过的伪造类型的鲁棒性。
尽管这些方法在检测完全伪造的音频方面取得了令人印象深刻的性能,但在处理部分伪造内容时则显得不足。部分伪造检测任务需要更精细的时间分辨率来识别嵌入在长持续时间音频中的小规模篡改。为了解决这个问题,最近的研究探索了不同的检测粒度,从段级分析到帧级分析。例如,QASAM 采用问答框架直接定位虚假跨度,而不是依赖全局捷径。TDL 引入了一个嵌入相似性模块,在表示空间中分离真实帧和伪造帧。PSDL 和 MGBF 利用自监督前端编码器并结合多分辨率策略以适应不同时间尺度的伪造。MFA 通过跨多层动态池化并用线性投影聚合它们来进一步细化 SSL 表示。IFBDN 设计了一个边界感知头来估计每个帧靠近伪造边界的可能性。
然而,大多数现有的 PFD 方法仍然继承了话语级检测的基本范式,将每个帧视为孤立的单元。虽然检测粒度有所提高,但这些方法很大程度上忽略了帧间的时间结构和语义连续性。
时间伪造定位
近年来,时间伪造定位在多模态视听取证中受到越来越多的关注。传统任务如时间异常检测和动作定位通常依赖于分布偏差或视觉上显著的过渡。然而,TFL 专注于识别恶意插入的短视频跨度,这些跨度通常模仿周围帧的局部声学或视觉模式。这些特性使得这些领域的现有解决方案难以处理微妙且稀疏的伪造,凸显了对专用建模策略的需求。
为了应对这一挑战,LAV-DF 引入了第一个内容驱动的多模态 TFL 数据集,并提出了 BATFD 网络,该网络通过结合单帧分类模块和边界匹配模块来检测伪造痕迹。它使用一个线性层作为解码器来确定每个帧是否被伪造。然后,根据时间分辨率,伪造帧被表示为连续的伪造区间。其后续工作 BATFD+ 增加了一个边界敏感网络用于辅助边界预测,并采用了一个多模态融合模块来促进音频和视频之间的跨模态交互。在此基础上,AV-TFD 利用跨模态注意力在编码阶段对齐音频和视频表示。UMMAFormer 通过结合重建学习、交叉重建注意力和并行特征金字塔网络,进一步增强了对微妙伪造线索的检测,并使用 ActionFormer 作为定位解码器。
虽然多模态 TFL 可以从跨模态不一致性中受益以检测伪造痕迹,但单模态音频伪造通常依赖于微妙的操作——例如音素级修改——这些操作保持了声学连贯性但改变了语义。这种微妙性增加了准确检测的难度。CFPRF 是第一个正式定义音频 TFL 任务的工作,提出了一个由帧级检测网络和建议框优化网络组成的两阶段框架。它提出了一个新的解码器 PRN,该解码器使用一个验证头和一个回归头来校正粗粒度的建议框。尽管解码器表现良好,但其定位能力仍然受到 PFD 任务模块的限制。
方法
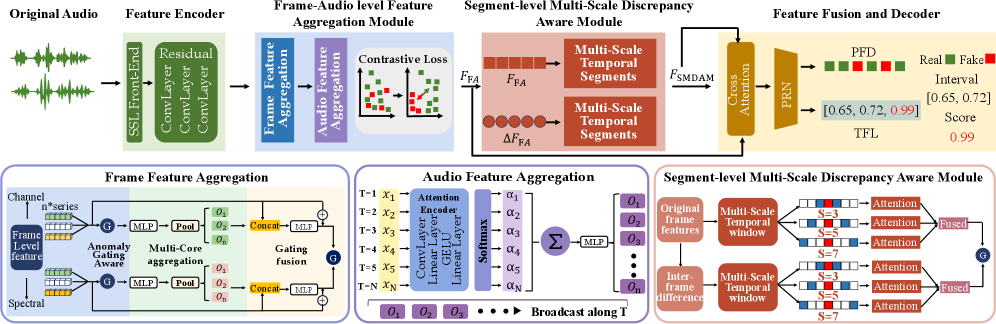
图2: 提出的 T3‑Tracer 的整体流程(上图)及其关键组件的详细架构(下图),包括具有帧特征聚合和音频特征聚合的帧-音频特征聚合模块(FA‑FAM),以及段级多尺度差异感知模块(SMDAM)。
概述
为了通过在多个时间级别捕捉伪造线索来检测和定位长音频中的部分音频伪造,我们提出了 T3‑Tracer,一个统一的框架,在帧、片段和音频级别联合分析音频。整体流程如图2所示,包括四个主要组成部分:(1) 特征编码器。输入音频波形首先由自监督语音编码器处理,然后是基于 CNN 的残差块处理,得到增强的帧级声学特征。(2) 帧-音频特征聚合模块(FA‑FAM)。FA‑FAM 旨在从帧和音频两个角度确定每个帧是否被伪造。它首先聚合帧内的各种异常模式,然后捕捉整个音频上的长程时间不一致性。(3) 段级多尺度差异感知模块(SMDAM)。SMDAM 在多尺度上划分时间片段以检测真实区域和伪造区域之间的时间边界,作为双重检查来优化单个帧的分类结果。(4) 特征融合和解码器。最后,来自 FA‑FAM 的伪造感知特征和来自 SMDAM 的边界感知特征通过交叉注意力机制进行融合。我们使用 PRN 作为解码器来产生每个帧的伪造概率,并将其转换为连续的伪造区间用于 TFL,同时细化时间边界。
特征编码器
鉴于自监督语音模型在下游任务中的已验证有效性,我们采用 Wav2Vec2-XLSR-300M 作为骨干网络来提取音频特征。具体来说,我们从最后的隐藏状态获取 1024 维嵌入。为了降低计算复杂度,我们使用一个线性层将这些嵌入投影到一个更低维的特征空间,产生一个形状为 ℝ^(C×T) 的特征图,其中 T 表示音频帧的数量,C 是降维后的特征维度。
由于自监督学习特征不足以建模每帧的频谱和通道级信息,我们遵循 CFPRF 并通过六个基于 CNN 的残差块进一步增强表示。这种增强将特征图转换为三维张量 𝐒 ∈ ℝ^(C×T×S),其中 C 和 S 分别表示每个帧的通道数和频谱箱数。
帧-音频级特征聚合模块
现有的帧伪造检测方法仅关注帧级别,缺乏全局时间上下文。为了解决这个局限性,我们提出了帧-音频特征聚合模块(FA‑FAM),它由两个顺序组件组成:帧级特征聚合(FFA)以捕捉帧内细粒度伪造线索,以及音频级特征聚合(AFA)以建模全局时间不一致性。
帧级特征聚合
由于 FA-FAM 在帧级别和音频级别完成帧伪造检测,设计一个优秀的帧级检测方法非常重要。现有研究表明,不同的音频操作技术表现出不同的伪造特征。例如,删除某些帧可能表现出不自然的频谱过渡,而拼接的片段通常会破坏通道一致性。然而,传统的检测方法通常依赖 CNN 或动态池化来粗略地区分真实帧和伪造帧。这类方法统一对待所有特征维度,因此忽略了不同操作技术引入的多样化异常模式。
为了解决这个问题,FFA 沿着通道和频谱维度构建了一组伪造感知核心向量("核心"),其中每个核心旨在捕捉不同篡改模式的关键表示。受 STAR 聚合机制的启发,我们使用一个聚合算子来实例化这些核心。
具体来说,给定从我们的特征编码器提取的帧级特征图 s ∈ ℝ^(C×T×S),我们分别为通道和频谱信息导出维度特定的投影 s_c ∈ ℝ^(C×T) 和 s_s ∈ ℝ^(S×T)。在每个维度内,我们构建 n 个伪造感知核心 {o_j}_{j=1}^n,它们共同拟合多样化的伪造模式。核心表示 o_j 是由任意函数 f 生成的向量,形式如下:
o_j = f( x_1, x_2, …, x_N ), (1)
其中 x_1, x_2, …, x_N 是一个具有 N 个通道或频谱箱的多元序列。
由于伪造异常可能不会在 N 个维度上均匀表示,我们设计了一个异常门控感知机制,该机制自适应地预测每个维度在构建核心时的权重,从而强调潜在的虚假异常,同时抑制正常的声学模式。为了获得这样的表示,我们采用以下形式:
o_j = Stoch_Pool_j( MLP_1( G ⊙ X ) ), j = 1, …, n (2)
其中 X 代表 s_c 或 s_s,⊙ 表示逐元素乘法,G 是异常门控感知机制,Stoch_Pool_j 是一个随机池化操作。
随后,每个单元 x_i 通过拼接所有核心 {o_j}_{j=1}^n 得到增强:
x'_i = MLP( [x_i ‖ o_1 ‖ … ∥ o_n] ) + x_i, (3)
这里,MLP 用于融合拼接后的表示并将其投影回隐藏维度。像许多其他模块一样,我们也添加了从输入到输出的残差连接。最后,我们通过一个可学习的软门控机制自适应地集成增强后的通道和频谱表示,该机制可以确定每个维度的相对贡献。
音频级特征聚合
为了捕捉全局不一致性,我们引入了音频级特征聚合(AFA)。虽然 AFA 采用了与 FFA 相同的特征聚合原理,但它沿着时间维度操作,并采用全局注意力机制来建模每个帧与音频中所有其他帧之间的依赖关系。
具体来说,给定来自 FFA 的输入序列 X ∈ ℝ^(T×C),AFA 应用一个轻量级注意力编码器来计算每个帧的归一化权重 α:
α = softmax( E_att( X ) ), (4)
使用这些权重,我们通过对序列进行加权和来导出一个全局上下文向量:
x_attn = ∑_{t=1}^T α_t ⋅ X_t, (5)
该向量随后通过一个 MLP 投影以产生全局核心表示:
o_g = MLP( x_attn ) ∈ ℝ^d', g = 1, …, n (6)
得到的全局核心通过门控残差连接与原始输入融合,增强了模型捕捉音频级伪造模式的能力。
段级多尺度差异感知模块
在完成单个帧的伪造检测后,先前的方法通常生成逐帧伪造预测分数,并将其直接输入解码器进行 TFL 任务。然而,仅依赖帧伪造检测通常会导致孤立的误报预测。虽然这些分散的错误对 PFD 性能指标影响最小,但它们严重阻碍了在 TFL 期间形成连贯的伪造区间,导致多个持续时间极短的错误定位片段。为了补充 FA-FAM 并进一步提高帧伪造检测的可靠性,我们引入了段级多尺度差异感知模块(SMDAM)。SMDAM 不直接对每个帧进行分类,而是专注于识别真实片段和伪造片段之间的时间边界,作为细化帧预测的补充信号。
形式上,给定特征序列 F = {f_t}_{t=1}^T,我们定义了一组以每个时间步为中心、具有不同半径 {k} 的时间窗口。对于每个尺度 k,我们应用局部自注意力来捕捉上下文不一致性:
f̃t^(k) = Attn^(k)( 𝒩k( f_t ) ), (7)
其中 𝒩_k( f_t ) 表示半径为 k 的帧 t 的时间邻域。这种多尺度设计允许模块检测发生在不同时间跨度的边界过渡。
为了进一步突出时间变化,我们引入了一个在帧间差异上操作的分支:
δ_t = f{t+1} − f_t, δ̃t^(k) = Attn^(k)( 𝒩_k( δ_t ) ). (8)
原始特征分支 f̃t^(k) 捕捉绝对不一致性,而差异分支 δ̃t^(k) 显式地建模突变。它们的输出通过门控集成进行融合:
F_b = G ⋅ δ̃t^(k) + (1 − G) ⋅ f̃t^(k), (9)
其中门控 G 是通过使用 sigmoid 激活的线性层从拼接的特征中预测得到的。
最后,一个全连接层将融合后的特征转换为边界概率分数 Ŷb = {ŷb1, ŷb2, …, ŷbT},这些分数表示每个帧作为真实片段和伪造片段之间边界的可能性。
特征融合和解码器
为了充分利用来自 FA‑FAM 和 SMDAM 的互补信息,我们采用交叉注意力机制,利用边界感知线索来增强伪造感知特征。由于输入是排列不变的,因此将位置编码 PE(⋅) 添加到两个特征序列中以编码时间顺序。我们首先计算帧伪造特征 F_FA 和边界检测特征 F_SMDAM 之间的边界感知相关性图 M_attn。这是通过将输入投影到查询和键表示来实现的:
Q = W_q PE(F_FA), K = W_k PE(F_SMDAM), (10)
并对它们的点积进行归一化:
M_attn = softmax( Q K^⊤ / √C ), (11)
为了获得边界增强的特征,我们使用 W_v 将伪造感知特征投影到值空间,并应用注意力图:
V = W_v PE(F_FA), F_ca = M_attn V. (12)
增强后的表示 F_ca 随后被添加回原始的伪造感知特征,并通过一个带有层归一化的前馈网络,生成融合的边界感知表示 F_ba。最后,我们采用基于 PRN 的解码器,在多个时间分辨率上逐步细化和下采样融合的特征 F_ba。解码器产生每帧伪造概率分数 Ŷf = {ŷ1^f, ŷ2^f, …, ŷT^f},并同时将离散的帧预测转换为具有准确边界定位的连续伪造区间,用于 TFL 任务。
训练与推理
我们的框架使用帧损失、边界损失和对比损失进行优化。帧损失直接监督由融合和预测模块产生的帧级伪造概率分数 Ŷf = {ŷ1^f, ŷ2^f, …, ŷT^f}。我们使用相对于真实标签 Y_f 的 MSE 损失:
ℒf = (1/T) ∑{t=1}^T MSE( ŷ_t^f, y_t^f ), (13)
其中 y_t^f ∈ {0, 1} 表示第 t 帧的伪造标签。为了显式地监督伪造片段边界的检测,我们对 SMDAM 预测的边界概率分数 Ŷb = {ŷb1, ŷb2, …, ŷbT} 应用 MSE 损失:
ℒb = (1/T) ∑{t=1}^T MSE( ŷ_t^b, y_t^b ), (14)
其中 y_t^b ∈ {0, 1} 是真实的边界标签。为了增强 FA-FAM 中的特征区分性,我们采用了一种对比损失,该损失鼓励来自同一类的帧的表示在特征空间中接近,同时推开来自不同类的帧的表示。对于第 j 对帧,相似性度量为:
SIM( f_a, f_b ) = (f_a^⊤ f_b) / ( ||f_a||2 ||f_b||2 ), (15)
对比损失定义为:
L_c = (1/J) ∑_{j=1}^J [ I_j (1 − SIM( f_j, f_j^+ ))^2 + (1 − I_j) max( 0, SIM(f_j, f_j^-) − α )^2 ], (16)
其中如果该对来自同一类则 I_j=1,否则为 0,α 是一个边界超参数。总的训练目标是:
ℒ = λ_1 ℒf + λ_2 ℒb + λ_3 ℒ_c, (17)
其中 λ_1, λ_2, λ_3 平衡了三个损失项。
在推理过程中,我们首先从 PRN 解码器获取帧伪造概率分数和连续伪造区间。然后使用 Soft-NMS 技术对结果进行后处理,以抑制被预测为同一类别但高度重叠的预测。
实验
实验设置
数据集。 我们在三个公共数据集上评估我们的方法:LAV-DF、ASVS2019-PS(PS)和 HAD。其中,PS 引入了多个具有不同操作类型的短伪造跨度,带来了更高的挑战。
比较方法。 对于 PFD,我们将 T3-Tracer 与几种最先进的方法进行比较:PSDL、IFBDN 和 CFPRF。对于 TFL,我们包括了单模态方法(PSDL, IFBDN, CFPRF)和多模态方法(BA-TFD, BA-TFD+, UMMAFormer),通过在推理时仅使用音频输入来模拟单模态性能。
评估指标。 遵循 CFPRF,我们报告了 PFD 任务的等错误率(EER)、曲线下面积(AUC)、假阴性率(FNR)、假阳性率(FPR)和 F1 分数。对于 TFL,我们计算在时间 IoU 阈值 {0.5, 0.75, 0.9, 0.95} 下的平均精度(AP),在平均提议框数量 {1, 2, 5, 10, 20} 下的平均召回率(AR),以及在 [0.5:0.05:0.95] 范围内阈值的平均 AP(mAP)。
实现细节。 所有模型均使用 PyTorch 实现,并在单个 NVIDIA GeForce RTX 3090 GPU 上训练。我们采用 Adam 优化器,学习率为 1e-7,权重衰减为 1e-4,训练 50 个周期,批量大小为 2。在我们的损失函数中,我们设置 λ_1=1, λ_2=0.25 和 λ_3=0.1。在 FA-FAM 阶段,我们将核心数量设置为 3。在 SMDAM 阶段,我们将多尺度时间片段设置为 3、5 和 7。
比较与分析
表1: 部分伪造检测结果。在使用不同评估指标评估的数据集上,与最先进的 PFD 方法的性能比较。
|
HAD |
IFBDN |
0.35 |
99.98 |
99.92 |
99.65 |
99.78 |
|
|
PSDL |
0.18 |
99.97 |
99.96 |
99.82 |
99.89 |
|
|
CFPRF |
0.08 |
99.96 |
99.98 |
99.92 |
99.95 |
|
|
T3-Tracer |
0.07 |
99.98 |
99.98 |
99.92 |
99.95 |
|
LAV-DF |
IFBDN |
1.07 |
99.88 |
99.94 |
98.93 |
98.93 |
|
|
PSDL |
0.82 |
99.92 |
99.95 |
99.18 |
99.57 |
|
|
CFPRF |
0.82 |
99.89 |
99.95 |
99.18 |
99.56 |
|
|
T3-Tracer |
0.80 |
99.93 |
99.96 |
99.21 |
99.57 |
|
PS |
IFBDN |
9.68 |
95.70 |
93.72 |
90.32 |
91.99 |
|
|
PSDL |
12.47 |
93.30 |
91.82 |
87.53 |
89.62 |
|
|
CFPRF |
7.50 |
96.95 |
95.18 |
92.50 |
93.82 |
|
|
T3-Tracer |
7.41 |
97.13 |
95.32 |
93.46 |
94.04 |
部分伪造检测。
我们在表 1 中报告了 PFD 任务的结果。我们提出的 T3-Tracer 在所有三个数据集上 consistently 实现了最佳性能。在最具挑战性的 ASVS2019-PS 上(包含频繁且短跨度的伪造),T3-Tracer 获得了 7.41% 的 EER 和 94.04% 的 F1 分数。这凸显了我们的三级时间建模在捕捉细粒度伪造痕迹方面的有效性。虽然我们的框架专门设计用于处理微妙且稀疏的音频操作,但它也在相对不那么具有挑战性的基准测试(如 HAD 和 LAV-DF)上带来了一致的改进,在 EER 和 F1 上都观察到了明显的提升。这表明所提出的方法在不同的伪造难度级别上保持了强大的鲁棒性。
表2: 时间伪造定位结果。与最先进的 TFL 方法和 PFD 模型的性能比较。
|
HAD |
BA-TFD |
79.86 |
37.98 |
5.55 |
0.57 |
40.93 |
45.12 |
47.53 |
49.99 |
52.09 |
55.15 |
|
|
BA-TFD+ |
88.26 |
70.69 |
37.83 |
7.39 |
64.83 |
67.49 |
68.44 |
69.06 |
69.39 |
70.15 |
|
|
UMMAFormer |
99.98 |
99.86 |
98.01 |
88.17 |
98.49 |
98.68 |
98.73 |
98.84 |
98.85 |
98.86 |
|
|
IFBDN |
93.85 |
91.55 |
87.75 |
79.08 |
90.40 |
96.07 |
97.39 |
97.54 |
97.54 |
97.54 |
|
|
PSDL |
88.53 |
85.27 |
80.80 |
73.25 |
84.25 |
93.40 |
96.30 |
96.89 |
96.94 |
96.94 |
|
|
CFPRF |
99.77 |
99.60 |
99.21 |
96.03 |
98.65 |
99.31 |
99.38 |
99.38 |
99.38 |
99.38 |
|
|
T3-Tracer |
99.74 |
99.78 |
99.43 |
96.33 |
99.27 |
99.33 |
99.46 |
99.46 |
99.46 |
99.46 |
|
LAV-DF |
BA-TFD |
53.53 |
10.98 |
0.36 |
0.02 |
20.77 |
29.56 |
32.22 |
34.73 |
38.03 |
44.66 |
|
|
BA-TFD+ |
83.78 |
51.99 |
6.13 |
0.46 |
49.32 |
52.78 |
54.97 |
57.21 |
58.41 |
60.04 |
|
|
UMMAFormer |
97.29 |
95.67 |
89.92 |
61.97 |
92.04 |
85.67 |
91.77 |
94.89 |
95.64 |
96.14 |
|
|
IFBDN |
86.83 |
84.02 |
77.85 |
70.09 |
82.55 |
86.28 |
91.78 |
92.13 |
92.13 |
92.13 |
|
|
PSDL |
76.10 |
71.71 |
65.16 |
57.13 |
70.43 |
84.71 |
89.14 |
89.98 |
90.03 |
90.03 |
|
|
CFPRF |
94.52 |
93.47 |
91.65 |
88.64 |
93.01 |
87.59 |
93.49 |
93.51 |
93.51 |
93.51 |
|
|
T3-Tracer |
94.70 |
93.82 |
92.07 |
89.27 |
94.29 |
87.79 |
93.89 |
93.89 |
93.89 |
95.89 |
|
PS |
BA-TFD |
13.65 |
4.91 |
1.06 |
0.63 |
6.15 |
8.04 |
11.03 |
15.41 |
19.14 |
23.64 |
|
|
BA-TFD+ |
15.72 |
6.37 |
2.05 |
1.95 |
7.69 |
7.93 |
12.62 |
18.28 |
22.17 |
26.71 |
|
|
UMMAFormer |
52.99 |
31.89 |
17.69 |
9.04 |
33.09 |
17.37 |
28.49 |
39.57 |
47.55 |
55.53 |
|
|
IFBDN |
43.84 |
34.79 |
27.10 |
22.53 |
34.92 |
18.72 |
33.30 |
53.87 |
60.99 |
62.22 |
|
|
PSDL |
46.63 |
38.19 |
31.13 |
26.94 |
38.42 |
20.22 |
35.16 |
56.86 |
64.97 |
66.52 |
|
|
CFPRF |
66.34 |
55.47 |
48.05 |
40.96 |
55.22 |
18.48 |
35.57 |
58.06 |
65.47 |
66.53 |
|
|
T3-Tracer |
68.74 |
57.28 |
49.25 |
42.73 |
57.28 |
21.65 |
37.36 |
59.64 |
66.47 |
67.30 |
时间伪造定位。
我们进一步在 TFL 任务上评估 T3-Tracer,结果总结在表 2 中。我们的方法在所有三个基准测试上都取得了最好的 mAP。具体来说,T3-Tracer 在 HAD、LAV-DF 和 PS 数据集上分别达到了 99.27%、94.29% 和 57.28% 的 mAP 分数,以及 99.33%、87.79% 和 21.65% 的 AR@1 分数。与现有的音频 TFL 基线(如 IFBDN、PSDL 和 CFPRF)相比,我们的框架显示出显著优势,尤其是在包含多个短且重叠的伪造跨度的 PS 数据集上。这验证了我们的 T3-Tracer 在细粒度边界估计方面的有效性。与多模态方法相比,当仅使用音频时,BA-TFD 和 BA-TFD+ 表现不佳。尽管 UMMAFormer 在伪造相对较长且孤立的 HAD 和 LAV-DF 上显示出合理的性能,但其在 PS 和高精度定位指标(如 AP@0.95)上的性能有所下降。这揭示了其在精确边界检测和多片段定位方面的能力有限。
核心模块的有效性。
为了研究每个时间建模组件的个体贡献,我们通过逐步从我们提出的 T3-Tracer 中移除核心模块来进行消融实验。结果总结在表 3 中。我们观察到,移除三个模块中的任何一个都会导致在所有数据集和指标上的性能一致下降,验证了在多粒度上进行时间建模的必要性。具体来说,移除 FFA 会导致 PFD 急剧下降,突显了跨通道和频谱特征聚合对于捕捉细粒度空间异常的重要性。排除 AFA 会损害长程时间一致性建模,这对使用先进伪造技术的 PS 和 LAV-DF 数据集尤其有害,并且单个帧的特征不足以确定其是否被伪造。此外,丢弃 SMDAM 会严重降低边界定位性能,尤其是在 PS 上,那里密集打包的伪造片段需要精确检测段级不连续性。最后,三个模块的组合取得了最佳结果,表明它们的集成使 T3-Tracer 能够构建一个全面的时间表示,该表示对不同操作模式具有鲁棒性。
表3: 我们核心模块有效性的消融研究。
|
|
EER↓ |
mAP |
EER↓ |
mAP |
EER↓ |
mAP |
|
Baseline=T3-Tracer |
0.07 |
99.27 |
0.80 |
94.29 |
7.41 |
57.28 |
|
w/o. FFA |
0.21 |
97.33 |
1.33 |
93.09 |
8.53 |
55.13 |
|
w/o. AFA |
0.09 |
98.91 |
0.88 |
93.21 |
7.64 |
55.87 |
|
w/o. SMDAM |
0.15 |
98.05 |
1.30 |
93.14 |
7.92 |
55.34 |
FA-FAM 的消融研究。
我们评估了帧内模块和全局模块共享的核心设计,包括多核心聚合、异常感知门控和门控融合策略。结果呈现在表 4 中。移除多核心结构并仅使用一个核心会导致性能下降,尤其是在具有挑战性的数据集上,显示了其在建模多样化操作模式方面的有效性。禁用异常感知门也会降低性能,因为网络失去了专注于异常线索的能力。最后,用简单的加法替换门控融合会降低定位精度,验证了自适应特征集成的益处。结合所有三种设计产生了最佳结果。
表4: FA-FAM 内部机制的消融结果。
|
|
EER↓ |
mAP |
EER↓ |
mAP |
EER↓ |
mAP |
|
Baseline=FA-FAM |
0.07 |
99.27 |
0.80 |
94.29 |
7.41 |
57.28 |
|
w/o. multi-core |
0.08 |
98.14 |
0.96 |
93.23 |
7.94 |
56.59 |
|
w/o. anomaly gating |
0.08 |
98.77 |
0.88 |
93.86 |
7.53 |
57.19 |
|
w/o. gate fusion |
0.08 |
98.65 |
0.82 |
93.74 |
7.66 |
56.10 |
SMDAM 的消融研究。
我们检查了局部模块中的三个核心设计:(1) 仅建模原始帧特征,(2) 仅建模帧差异,(3) 使用单尺度时间片段。如表 5 所示,单独任一分支的性能都不如完整设计,证实了原始特征和差异特征都捕捉了互补的边界线索。此外,仅使用单一时间尺度会削弱对不同持续时间伪造边界的敏感性。这些结果验证了双分支设计和多尺度建模在捕捉微妙局部过渡方面的必要性。
表5: FA-FAM 内部机制的消融结果。
|
|
EER↓ |
mAP |
EER↓ |
mAP |
EER↓ |
mAP |
|
Baseline=SMDAM |
0.07 |
99.27 |
0.80 |
94.29 |
7.41 |
57.28 |
|
w/o. frame features |
0.08 |
98.59 |
0.85 |
93.88 |
7.65 |
56.71 |
|
w/o. frame differences |
0.08 |
98.58 |
0.85 |
93.86 |
7.56 |
56.51 |
|
w/o. multi-scale temporal segment |
0.08 |
98.16 |
0.98 |
93.21 |
7.83 |
56.19 |
结论
在本文中,我们提出了 T3-Tracer,一个用于部分音频伪造检测和定位的统一框架。我们工作的一个关键贡献是显式的层次化时间建模,我们将音频的时间结构划分为三个级别:帧、片段和音频。这种多级分解使得能够更全面地理解多样化的伪造模式。基于此公式,我们设计了两个互补的模块:FA-FAM,它通过整合帧级别的细粒度声学线索和音频级别的全局语义上下文来检测帧伪造;以及 SMDAM,它通过在多尺度片段上建模原始帧特征和帧间差异来专注于段级边界检测。为了增强时间级别之间的交互,我们进一步引入了交叉注意力机制和基于 PRN 的解码器以实现连贯的预测。在三个具有挑战性的数据集上进行的大量实验证明,T3-Tracer 在部分伪造检测和时间伪造定位上都达到了最先进的结果。我们的发现验证了层次化时间分解和跨尺度集成的重要性,为现实世界和长形式场景下音频伪造检测的未来进展提供了一个统一且可扩展的基础。



评论前必须登录!
注册