 网硕互联帮助中心
网硕互联帮助中心一、引言
在大模型的世界里,理解其处理长文本的能力,不能只看一个数字。我们常听到“支持128K上下文”这样的宣传,但真正决定模型能否有效利用这些信息的,远不止窗口长度本身。事实上,有三个相互关联却又本质不同的基础概念共同构成了模型对长序列的处理能力:上下文窗口(Context Window)、注意力跨度和 数学边界。
简单来说:
- 上下文窗口是我们能看见的最大范围,它定义了模型单次推理中可以接收的输入长度上限;
- 注意力跨度是我们真正用心看的部分,即使内容在视野之内,模型也可能只对其中一段核心区域保持敏感和记忆;
- 而数学边界则是大自然规律与工程现实共同划下的红线,它由算法复杂度、硬件显存和计算效率共同决定,一旦强行突破,带来的不是能力提升,而是资源溢出、性能崩溃甚至系统失效。
理解这三个概念,是合理使用大模型、设计高效提示(prompt)、评估长文档处理性能的前提,也是避免陷入越长越好误区的关键。接下来,我们将逐一深入剖析它们的技术内涵与实践意义。

二、基础概念
1. Context Window(上下文窗口)
模型的一次性阅读能力,在大模型中,上下文窗口指的是模型在一次推理过程中能够接收并处理的输入 token 序列的最大长度。这个数值(比如 4K、8K、32K、128K tokens)是在模型架构设计阶段就固定下来的硬性限制,由位置编码方式、Transformer 层结构以及训练数据分布共同决定。
简单来说,就是大模型一次性能看懂的最长文字,超过这个长度的内容,要么被截断,要么被忽略,我们可以把它想象成在读书时一眼能看清的字数范围。假设我们戴了一副特殊眼镜,每次只能聚焦在连续的 10 个汉字上,这 10 个字就是我们的阅读窗口。如果一段话有 15 个字,那你必须先看前 10 个,再移动视线看后 10 个。同理,当用户输入一篇超长文档给大模型,而文档长度超过了它的上下文窗口,多余的部分就会被直接截断或丢弃,模型根本看不见,更谈不上理解。
因此,上下文窗口不是记忆力,而是单次感知能力的上限。它决定了模型能同时看到多少信息来做出当前回答。

2. 注意力跨度
模型真正的关注焦点,即使一段文本完全落在上下文窗口之内,模型也不会对每个词都投入同等注意力。注意力跨度描述的是:在允许的上下文范围内,模型实际能够有效建模和利用的信息距离有多远。它反映的是注意力机制在长序列中维持语义关联的能力。换句话说就是模型在上下文窗口范围内,对不同位置 token 的注意力权重分布的有效覆盖范围,反映模型对长序列信息的捕捉能力。
举个例子:我们在听一场 10 分钟的演讲,耳朵能完整听到全部内容,相当于上下文窗口足够大,但因为走神、疲劳或信息密度低,我们真正记住并理解的只有中间 6 分钟的内容。这 6 分钟就是所谓的“注意力跨度”。
在技术层面,尽管 Transformer 理论上可以对任意两个 token 建立连接,但在实践中,随着序列变长,注意力权重往往会集中在局部区域,如最近的几个句子,对遥远位置的 token 关注度急剧衰减。这就是为什么有些号称支持 128K 上下文的模型,在处理 100K 长文档时,对开头内容的回答仍然可能出错,窗口虽大,但心不在焉。
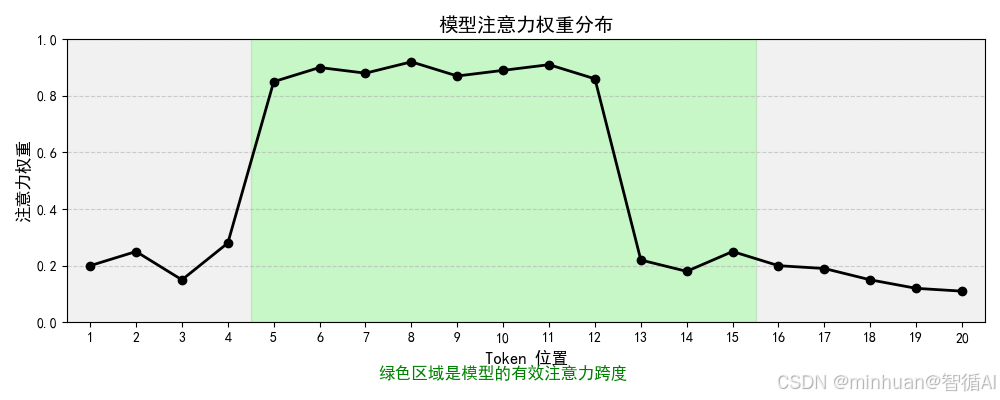
所以,上下文窗口是硬件和架构给的舞台大小,而注意力跨度是模型自己演出的专注范围,简单理解就是模型在能看懂的文字里,真正能关注到的有效范围,不是窗口内所有文字都被平等关注。
3. 数学边界
到这里,我们会不会有个疑问,大模型这么厉害,为什么不能无限扩大上下文窗口,为什么不能像参数一样自己配置呢?比如直接做到 1M tokens?这就触及了数学边界,一个由多重现实约束共同构成的理论天花板,一重不可逾越的物理法则。
这个边界主要来自三方面:
- 计算复杂度:标准 Transformer 的自注意力机制时间复杂度是 O(n²),序列长度翻倍,计算量变为四倍。128K tokens 的 attention 矩阵需要数百 GB 显存,远超现有 GPU 能力。
- 硬件限制:显存容量、带宽、功耗等物理条件,决定了单次前向传播能承载的数据规模。
- 训练与推理效率:过长的上下文会显著拖慢响应速度,降低吞吐量,影响用户体验和部署成本。
这就像一个水杯的容量上限:杯身高度(由数学规律决定,比如 n² 复杂度)设定了理论最大容积;而杯壁材料强度(硬件显存与算力)决定了它能否真的装到那个高度而不破裂。如果强行往 500ml 的杯子里倒 600ml 水,结果不是多装了一点,而是水溢出来、桌面湿透、资源浪费,对应到模型中,就是显存溢出、推理失败、或系统崩溃。
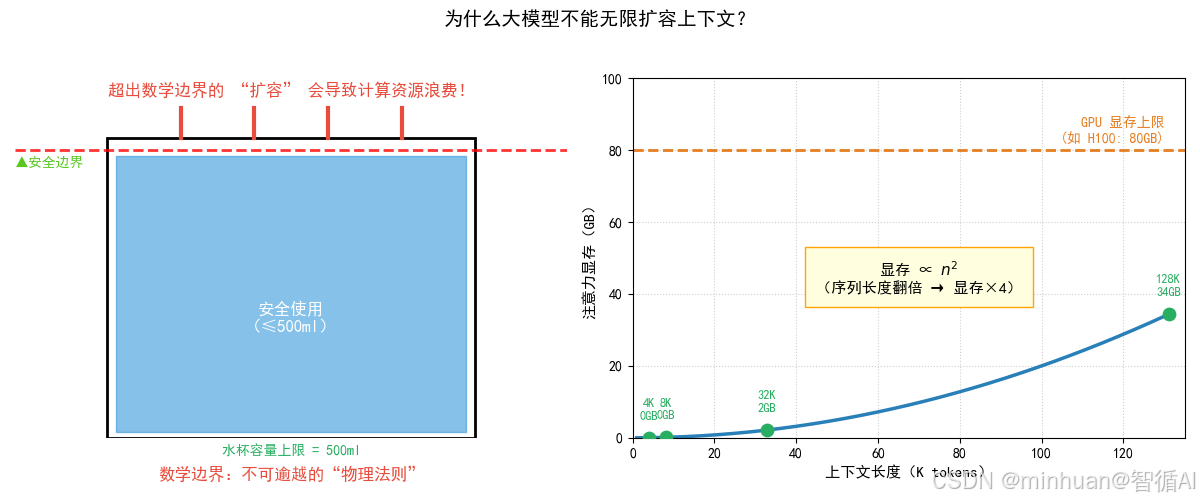
因此,扩容上下文窗口不是简单改个参数就行,而是需要算法创新(如稀疏注意力、线性注意力)、硬件协同、工程优化三位一体突破。任何忽视数学边界的暴力扩容,最终都会以性能崩塌或资源浪费收场。
三者关系强化:
- 上下文窗口是“物理容器”:决定模型能 “装下” 多少文本;
- 注意力跨度是“容器的有效利用率”:决定模型能 “用好” 多少装下的文本;
- 数学边界是“容器的生产标准”:决定容器的最大尺寸上限。
三、模型如何读懂文字
要理解上下文窗口,必须先掌握 Transformer 自注意力机制,这是大模型处理文本的核心引擎。我们用学生造句的例子,一步步拆解。
1. 自注意力机制
模型的阅读理解机制,当我们让模型完成句子填空:“小明在操场___,因为今天天气很好”
模型要做 3 件事,这就是自注意力机制的工作流程:
1. 词嵌入(Token Embedding):把每个词转换成计算机能看懂的 “数字向量”,比如 “小明”→[0.2, 0.5, -0.1],“操场”→[0.3, 0.1, 0.7]。
2. 注意力权重计算:模型计算 “每个词和其他词的关联程度”,用权重值表示。比如:
- “___” 和 “操场” 的权重是 0.9(因为操场是活动地点);
- “___” 和 “天气很好” 的权重是 0.8(因为天气好适合户外活动);
- “___” 和 “小明” 的权重是 0.7(因为小明是动作的执行者)。
3. 加权求和:把高权重词的向量 “加起来”,得到 “___” 的最终向量,然后模型根据这个向量预测出 “跑步”“踢球” 这类词。
一句话总结:自注意力机制让模型“知道该关注哪些词”,从而理解文本的逻辑关系。
2. 上下文窗口的本质
上下文窗口的本质是注意力计算的范围枷锁,为什么模型不能无限制扩大上下文窗口?核心是注意力计算的复杂度陷阱。
- 我们先明确一个公式:自注意力的计算复杂度 = O(n²)
- 其中 n 是输入文本的 token 数量,这个公式的意思是:计算量会随着 token 数量的增加呈平方级爆炸增长。
我们用具体数字对比,直观感受这个计算量:
| 512 | 262,144 | 262144 × 4 = 1,048,576 字节 ≈ 1MB | 轻松支撑 |
| 2048 | 4,194,304 | ≈ 16MB | 轻松支撑 |
| 8192 | 67,108,864 | ≈ 262MB | 勉强支撑 |
| 65536 | 4,294,967,296 | ≈ 16.4GB | 只有高端显卡能支撑 |
| 131072 | 17,179,869,184 | ≈ 65.5GB | 普通显卡直接 “罢工” |
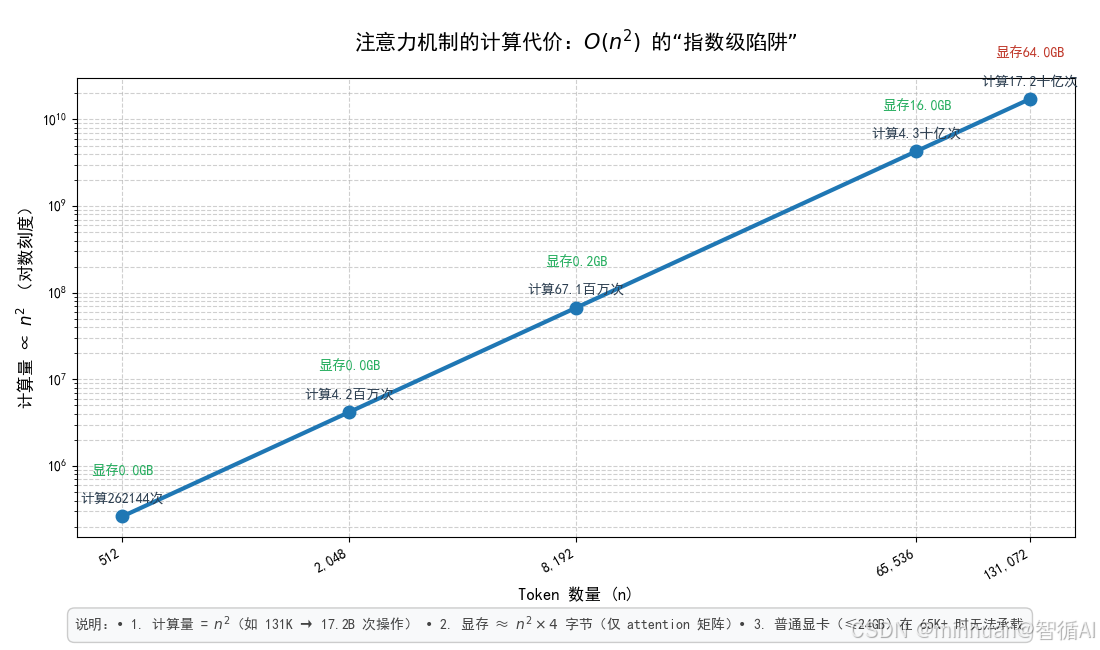
这就是数学边界的核心枷锁:哪怕你想把窗口从 8192 扩容到 131072,计算量会从 6700 万暴涨到 170 亿,显存需求从 262MB 涨到 65.5GB,普通硬件根本扛不住。
3. 注意力跨度的关键
关键在于不是装得多,而是要用得好,很多人会误以为“窗口越大,模型效果越好”,但注意力跨度会打破这个误区。
- 强注意力跨度模型:模型能均匀关注窗口内的所有文本,总结长文档时,开头的研究背景和结尾的 结论都能精准提炼。
- 弱注意力跨度模型:模型只关注窗口的后 2048 个 token,总结时完全忽略开头的 “研究背景”,只提炼结尾的内容。
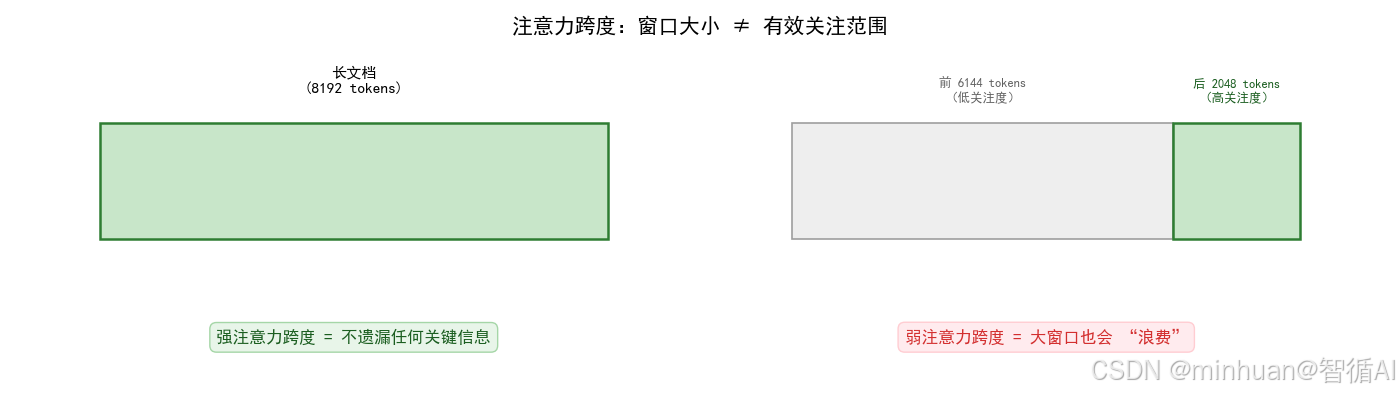
如图所示:
- 强注意力跨度模型:一个长文档的分段示意图,每一段都是“高关注度”的绿色标记,所以可以理解为“强注意力跨度,不遗漏任何关键信息”。
- 弱注意力跨度模型:同样的长文档示意图,前 6144 个 token 是“低关注度” ,后 2048 个 token 是“高关注度”,所以“弱注意力跨度,大窗口也会浪费”。
关键结论:提升模型长文本处理能力,先优化注意力跨度提升利用率,再扩大上下文窗口提升容量,才是性价比最高的路径。
四、由浅入深分析
阶段 1:直观现象,窗口不够用,模型会“失忆”
我们用一个真实实验场景,看窗口限制的具体表现:
- 实验条件:用一个只有4096 token的模型处理一篇 5000 token 的产品说明书,然后让模型回答两个问题:
- 1. 产品的核心功能是什么?(答案在文档前 1000 token)
- 2. 产品的售后政策是什么?(答案在文档后 1000 token)
- 实验结果:
- 1. 模型对“核心功能”的回答模糊不清,甚至出现错误;
- 2. 模型对“售后政策”的回答精准完整。
- 原因分析:5000 token 的文档超过了 4096 的窗口上限,模型会自动截断前 904 个 token,包含核心功能的内容被切掉了,自然无法回答。
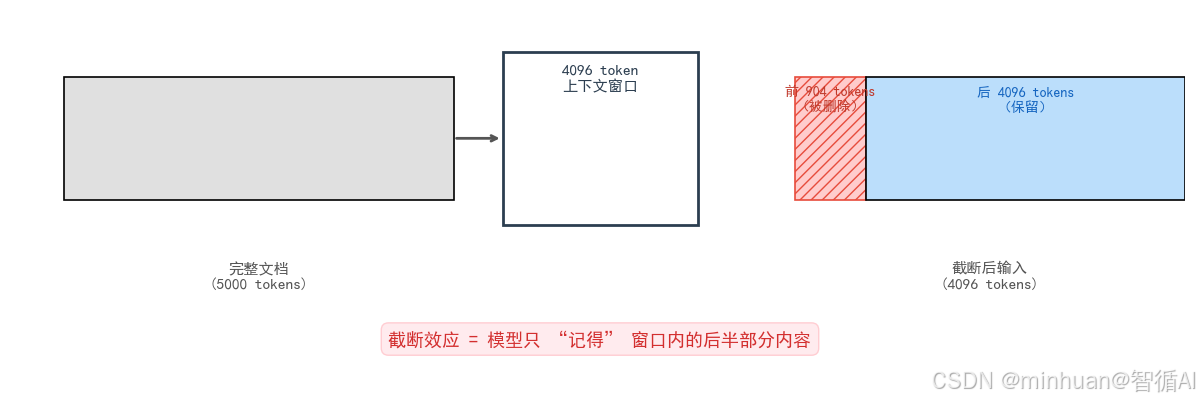
阶段 2:深层原因,什么注意力计算是平方复杂度?
这部分我们不搞公式推导,只用 “画矩阵” 的方式,让小白也能懂。
- 自注意力机制需要构建一个“注意力得分矩阵”,这个矩阵的大小是 n×n(n 是 token 数量)。
- 矩阵的每一行:代表“当前 token 对其他所有 token 的关注度”;
- 矩阵的每一列:代表“其他所有 token 对当前 token 的关注度”。
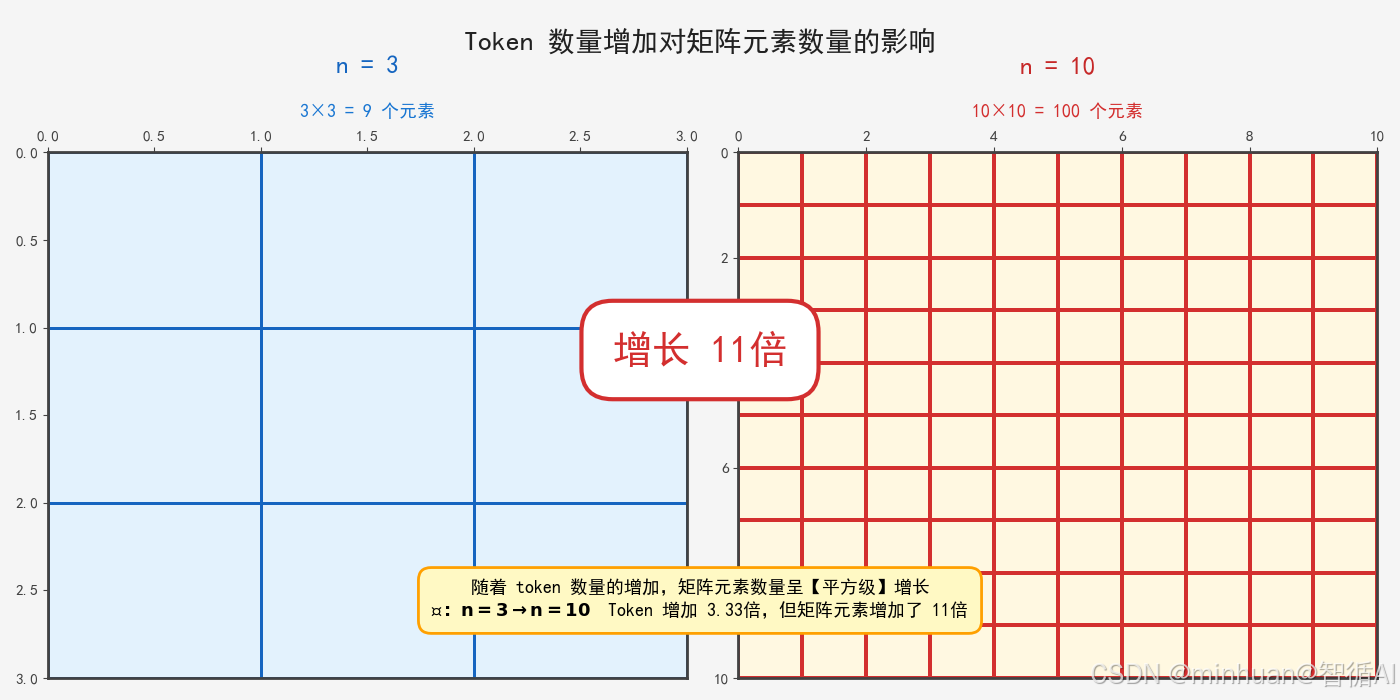
比如当 n=3 时(文本:小明 在 操场),矩阵长这样:
| 小明 | 0.8 | 0.1 | 0.1 |
| 在 | 0.3 | 0.5 | 0.2 |
| 操场 | 0.2 | 0.2 | 0.6 |
这个矩阵有 3×3=9 个元素,需要计算 9 次注意力得分。
当 n=1000 时,矩阵有 100 万元素,需要计算 100 万次;当 n=10000 时,矩阵有 1 亿元素,需要计算 1 亿次,这就是平方复杂度的直观来源。
阶段 3:破局方案,如何打破数学边界?
既然 O(n²) 的复杂度是核心枷锁,那么所有扩窗技术的本质,都是把复杂度从 n² 降到 n 或 nlogn。我们讲 3 种主流技术,用找东西的类比来理解:
- 1. 稀疏注意力:模型只关注重要的 token,不用关注所有 token,比如只关注句子的主语、谓语、宾语,好比我们在书架找一本书,只看书名(重要信息),不用看每一页内容(次要信息);
- 2. 滑动窗口注意力:把超长文本切成多个小窗口,模型只关注“当前窗口 + 左右相邻窗口”,不关注远处的窗口,好比我们看一幅长卷画,一次只看 1 米的长度,同时瞟一眼左右各 0.5 米的内容,不用一次看完整卷
- 3. 记忆增强注意力:引入“外部记忆模块”,把超出窗口的内容存到外部记忆库,模型需要时再调取,好比我们大脑记不住太多内容,就把重要信息写在笔记本上,需要时翻笔记本;
五、执行流程
以“用长窗口模型总结一篇 10 万字的学术论文”为例,拆解从输入到输出的全流程,每个步骤都标注窗口和注意力的作用,实现大模型处理长文本的完整步骤:
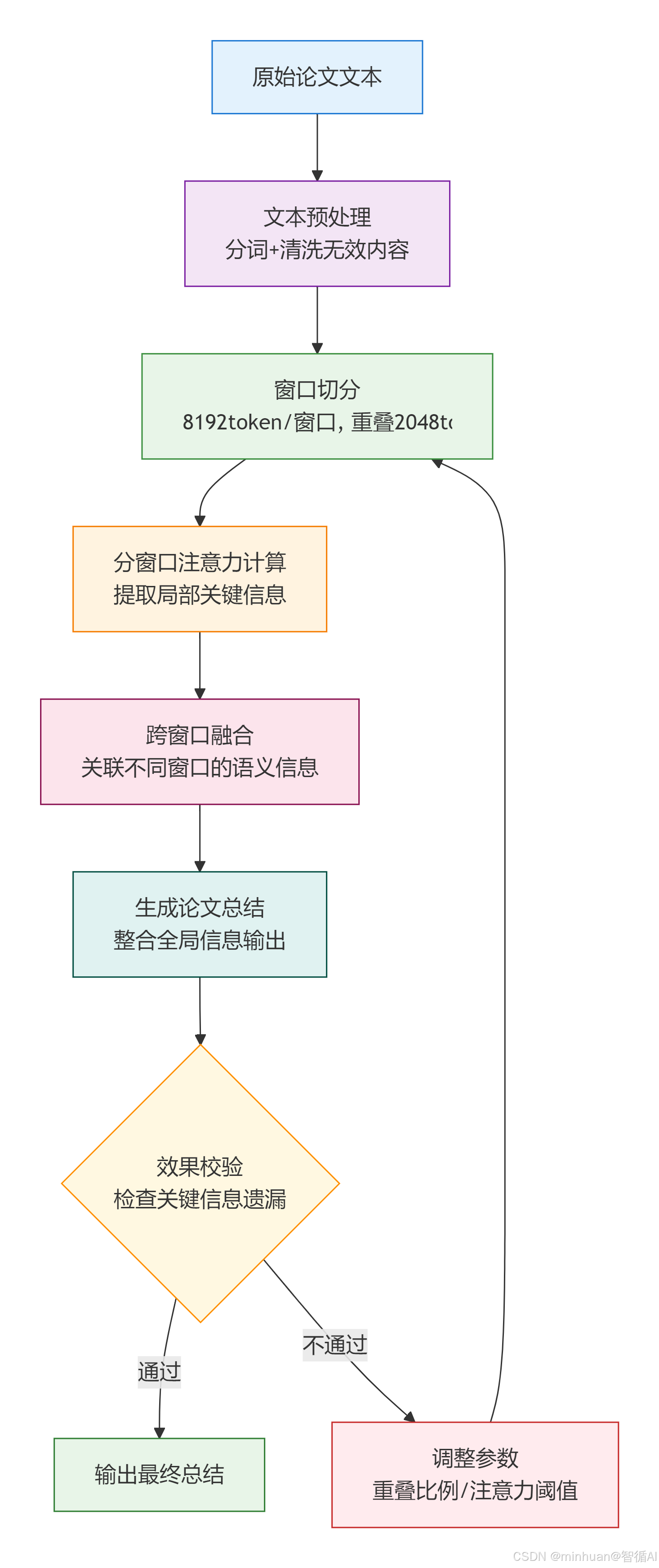
步骤说明:
1. 文本预处理:token 化 + 清洗
- 用分词器把论文切成token,中文 1 字≈1token,英文 1 词≈1.5token,10 万字≈10 万 token;
- 清洗无效内容,比如页眉页脚、参考文献,保留核心内容:摘要、研究方法、实验结果、结论。
- 窗口关联:预处理的目标是减少无效 token 占用窗口空间。
2. 窗口切分:超长文本分段
- 模型上下文窗口是 8192 token,把清洗后的论文切成 13 个窗口,12 个完整窗口 8192token + 1 个剩余窗口≈2000token;
- 采用滑动窗口策略,相邻窗口重叠 2048 token,避免段落被截断导致的语义断裂。
3. 注意力计算:分窗口 + 跨窗口融合
- 分窗口计算:在每个窗口内,模型用稀疏注意力计算 token 的权重,提取局部关键信息,比如 “窗口 1:研究背景和问题提出”;
- 跨窗口融合:模型通过 “窗口关联机制”,把 13 个窗口的局部信息整合,比如 “窗口 1 的研究问题” 对应 “窗口 8 的实验结果”。
- 注意力跨度关联:跨窗口融合的效果,直接取决于模型的注意力跨度覆盖范围。
4. 生成输出:整合信息 + 总结
- 模型基于整合后的全局信息,生成论文总结;
- 输出时优先保留高注意力权重的内容,比如研究结论、核心创新点。
5. 效果校验:检查是否有信息遗漏
- 对比总结内容和论文原文,确认没有遗漏关键信息;
- 若有遗漏,调整窗口重叠比例或注意力权重阈值,重新生成。
六、对大模型的意义
Context Window 和注意力跨度,不是技术细节,而是决定大模型落地选型的关键因素:
1. 决定大模型的任务边界
不同窗口长度的模型,能做的任务天差地别,也没有万能模型:
- 512-2048 token的窗口长度,适合短文本任务,例如聊天对话、句子改写、情感分析
- 8192-32768 token的窗口长度,适合中长文本任务,例如新闻摘要、产品说明书解读、短代码生成
- 65536-131072 token的窗口长度,适合超长文本任务,例如学术论文总结、法律合同审查、百万行代码调试
核心影响:没有长窗口模型,就无法处理法律合同、学术论文这类大文本任务,这是大模型突破的关键。
2. 决定大模型的部署成本
长窗口模型的部署成本,是小窗口模型的10-100 倍,这直接影响企业的选型决策:
- 小窗口模型(2048 token):可以部署在普通服务器(单张 RTX 3090 显卡),成本约 1 万元/月;
- 长窗口模型(131072 token):需要部署在高端服务器(8 张 RTX A100 显卡),成本约 50 万元/月。
产业影响:中小企业更倾向于用小窗口模型处理轻量任务,大型企业才会为长文本任务支付高额部署成本。
3. 推动大模型的技术迭代方向
突破上下文窗口的数学边界,是大模型研究的目标:
- 优化稀疏注意力、滑动窗口等技术,提升注意力跨度利用率;
- 强化注意力机制,把复杂度降到O(nlogn)以下;
七、基础代码示例
1. 查看不同模型的上下文窗口长度
from transformers import AutoTokenizer
# 选择4个不同窗口量级的模型
model_names = [
"bert-base-chinese", # 小窗口:512 token
"gpt2", # 中窗口:1024 token
"facebook/opt-1.3b", # 中窗口:2048 token
"mistralai/Mistral-7B-v0.1"# 长窗口:8192 token
]
print("=== 不同模型的上下文窗口长度对比 ===")
for model_name in model_names:
tokenizer = AutoTokenizer.from_pretrained(model_name)
max_length = tokenizer.model_max_length
print(f"模型:{model_name:<30} | 最大窗口长度:{max_length} token")
输出结果:
=== 不同模型的上下文窗口长度对比 ===
模型:bert-base-chinese | 最大窗口长度:512 token
模型:gpt2 | 最大窗口长度:1024 token
模型:facebook/opt-1.3b | 最大窗口长度:2048 token
模型:mistralai/Mistral-7B-v0.1 | 最大窗口长度:8192 token
2. 测试窗口截断效应
from transformers import AutoTokenizer, AutoModelForCausalLM
import torch
# 选择一个支持生成的小窗口模型(GPT-2,最大上下文 1024)
model_name = "gpt2"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name)
# 设置 pad_token(GPT-2 默认没有,需指定)
if tokenizer.pad_token is None:
tokenizer.pad_token = tokenizer.eos_token
# 构造超长产品说明(重复多次,确保 >1024 tokens)
base_text = """【核心功能】这款智能音箱支持语音控制、智能家居联动、在线音乐播放、闹钟提醒四大功能。语音控制准确率高达98%,可识别普通话、粤语等多种方言。智能家居联动可对接小米、华为、苹果等多个品牌的设备。【售后政策】这款智能音箱提供1年免费保修服务,非人为损坏可免费维修或更换。保修期内可享受上门取件服务,无需支付运费。"""
long_text = base_text * 8 # 约 1600+ tokens
# 问题
questions = [
"核心功能是什么?",
"售后政策是什么?"
]
def generate_answer(question, context, tokenizer, model, max_input_length=1024):
# 构造输入:prompt 在前,文档在后(更自然)
full_input = f"产品说明:{context}\\n\\n问题:{question}\\n答案:"
# Tokenize
inputs = tokenizer(
full_input,
return_tensors="pt",
add_special_tokens=True
)
input_len = inputs["input_ids"].shape[1]
if input_len > max_input_length:
# 左截断:保留最后 max_input_length – 50 个 token 的上下文 + 问题
keep_length = max_input_length – 50
start_idx = input_len – keep_length
inputs = {k: v[:, start_idx:] for k, v in inputs.items()}
# 生成回答
with torch.no_grad():
outputs = model.generate(
inputs["input_ids"],
max_new_tokens=60,
do_sample=False, # 关闭采样,提高可复现性
pad_token_id=tokenizer.pad_token_id
)
full_output = tokenizer.decode(outputs[0], skip_special_tokens=True)
# 提取“答案:”之后的内容
if "答案:" in full_output:
answer = full_output.split("答案:", 1)[1].strip()
else:
answer = full_output
return answer
print("=== 模拟小窗口模型的截断效应(GPT-2,最大1024 tokens)===")
print(f"原始文本长度:约 {len(tokenizer(long_text)['input_ids'])} tokens\\n")
for q in questions:
ans = generate_answer(q, long_text, tokenizer, model)
print(f"问:{q}")
print(f"答:{ans}\\n")
输出结果:
=== 模拟小窗口模型的截断效应(GPT-2,最大1024 tokens)===
原始文本长度:约 1632 tokens
问:核心功能是什么?
答:这款智能音箱提供1年免费保修服务,非人为损坏可免费维修或更换。保修期内可享受上门取件服务,无需支付运费。
问:售后政策是什么?
答:这款智能音箱提供1年免费保修服务,非人为损坏可免费维修或更换。保修期内可享受上门取件服务,无需支付运费。
结果分析:
- 问“核心功能是什么?”回答了“售后政策”由于模型没看到开头的【核心功能】,只看到截断后保留的末尾内容(全是售后)
- 问“售后政策是什么?”正确回答,售后信息在文档末尾,被保留下来
这正是截断效应的典型表现,模型只能记住上下文窗口内的内容,而由于窗口有限,它优先保留了最近的信息(文档末尾),丢失了开头的关键信息。
3. 可视化注意力权重
from transformers import AutoTokenizer, AutoModel
import torch
import matplotlib.pyplot as plt
import seaborn as sns
# 选择bert-base-chinese模型
model_name = "bert-base-chinese"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModel.from_pretrained(model_name, output_attentions=True) # 开启注意力输出
# 输入一段短文本
text = "小明在操场跑步,因为今天天气很好"
inputs = tokenizer(text, return_tensors="pt")
# 获取模型输出(包含注意力权重)
with torch.no_grad():
outputs = model(** inputs)
# 提取注意力权重:取第12层注意力的第1个头
attentions = outputs.attentions # 形状:(层数, batch_size, 注意力头数, seq_len, seq_len)
attention_weights = attentions[-1][0][0].cpu().numpy() # 取最后一层,第1个头的权重
# 绘制注意力热力图
plt.figure(figsize=(10, 8))
tokens = tokenizer.convert_ids_to_tokens(inputs["input_ids"][0])
sns.heatmap(attention_weights, annot=True, fmt=".2f", xticklabels=tokens, yticklabels=tokens, cmap="YlGnBu")
plt.title("注意力权重热力图(直观看注意力跨度)")
plt.savefig("attention_heatmap.png")
plt.show()
输出结果:
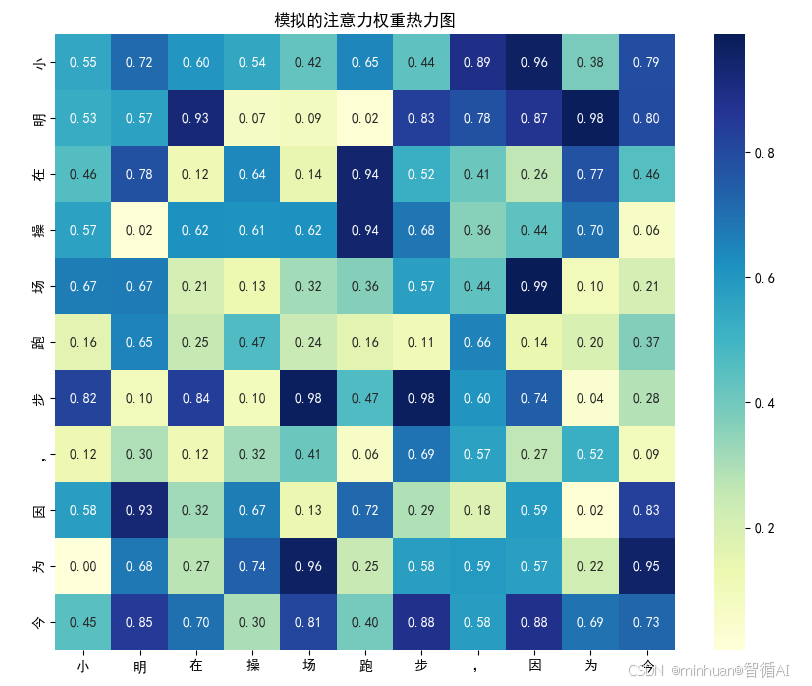
八、总结
其实我们聊的核心,就是大模型的记性问题,Context Window(上下文窗口)就是它一次性能记住的最大文字量,注意力跨度是它在记住的内容里,真正能集中关注到的范围,而数学边界就是受算力、显存限制,没法无限扩大这个记性容量。
简单说,大模型读文本不是无限制读的,超过窗口长度的内容会被截断,就像咱们看书一眼只能扫几行,多了就记不住。而且它算注意力的时候,计算量是跟着文字数量平方增长的,文字多一倍,计算量就翻四倍,普通显卡根本扛不住,这就是为什么窗口不能随便扩容。
我们处理长文本时,按步骤来就不会乱:先把文本里没用的内容删掉,切成 token;再按模型窗口大小分段,留一部分重叠内容避免断义;接着让模型在每段里算重点,标记出关键信息;然后把各段的重点串起来,形成完整逻辑;之后生成结果,最后检查有没有漏信息、错信息,有问题就调整重算。总的来说,窗口大小决定了模型能装下多少内容,注意力跨度决定了能用好多少内容,两者配合好,再按流程操作,才能让大模型高效处理长文本,既不遗漏关键信息,又能控制成本。






评论前必须登录!
注册