 网硕互联帮助中心
网硕互联帮助中心前言:在商铺查询等高并发读场景下,引入 Redis 缓存可以极大地减轻数据库压力并提升响应速度。然而,引入缓存也带来了新的挑战——数据一致性。当数据库的数据发生变更时,如何保证 Redis 中的缓存数据同步更新?本文基于黑马点评项目中的“店铺更新”模块,复盘 Cache Aside Pattern(旁路缓存模式)的选型逻辑,并深入探讨更新策略、操作顺序以及原子性保证等核心问题。
一、 核心背景与挑战
在我们的业务场景中,如果仅仅修改了数据库,而没有操作 Redis,会发生严重的数据不一致问题:用户 A 修改了店铺信息(更新 DB),但 Redis 中依然存储着旧的店铺信息。当用户 B 发起查询请求时,会命中 Redis 并获取到过期数据(脏读)。
解决这个问题通常有三种经典模式:
选型结论: 综合考虑实现的复杂度和对数据可靠性的要求,我们选择了最通用的 Cache Aside Pattern。但在具体落地时,我们需要在多个技术岔路口做出正确的决策。
二、 深度复盘:三个关键技术决策
1. 策略选择:更新缓存还是删除缓存?
当数据库数据发生变更时,我们需要同步处理 Redis,此时有两种选择:是直接把新数据写入 Redis(更新),还是直接废弃 Redis 中的数据(删除)?
我们选择了删除缓存。
- 成本分析:如果采用“更新缓存”方案,在写多读少的场景下会造成严重的性能浪费。假设一个店铺信息被连续修改了 10 次(比如店主正在频繁调整营业时间),但期间没有一个用户来查询。如果每次都更新缓存,Redis 中会被写入 10 次数据,但前 9 次都是无效计算。
- 懒加载思想:采用“删除缓存”策略,本质上是一种 Lazy Loading(懒加载)。业务只负责失效缓存,只有当真正有用户来查数据时,才去查询数据库并写入缓存。这能有效节省计算资源和内存。
2. 时序选择:先删缓存,还是先改数据库?
确定了“删除缓存”策略后,操作顺序至关重要。是先删 Redis 再改 DB,还是先改 DB 再删 Redis?
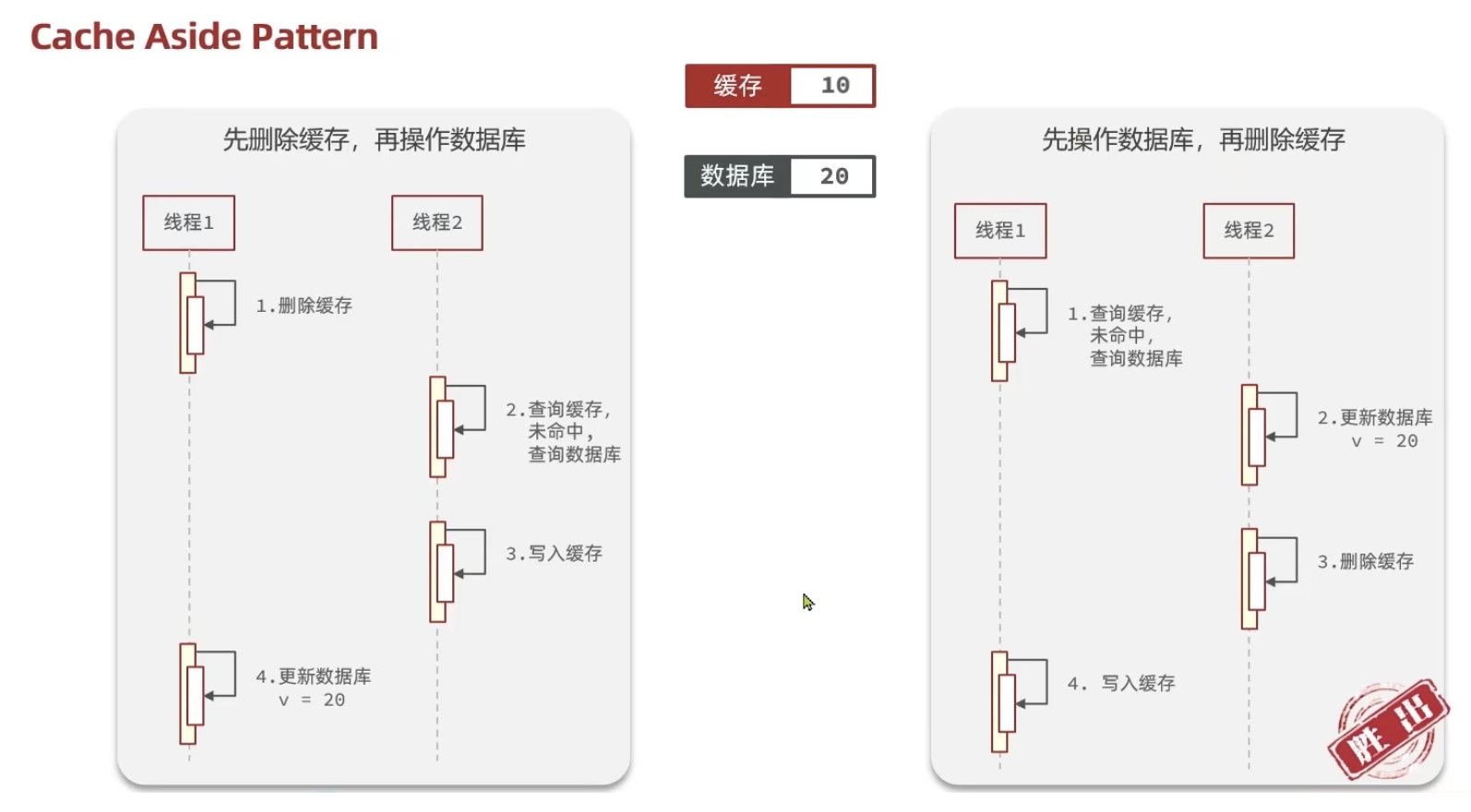
我们坚决选择了先改数据库,再删缓存。
在这种方案下,要产生脏数据,必须严格同时满足以下 3 个苛刻条件(这是一场极其巧合的“赛跑”):
让我们看看这有多难发生:
- 线程 B(读操作):它的流程是 读 DB + 写 Redis。这两个都是极快的操作(读通常比写快)。
- 线程 A(写操作):它的流程是 写 DB + 删 Redis。写 DB 涉及锁行、事务提交、磁盘 IO,是很慢的操作。
在计算机世界里,因为“读”远快于“写”,所以“读线程”很难被“写线程”反超并完成整套动作。
最后一道防线:即使真的发生了那亿万分之一的概率,我们还有 Redis 数据的过期时间(TTL)。缓存过期后,数据自然会纠正过来,从而保证最终一致性。
那如果采用“先删缓存,再改数据库”,这就会在多线程并发下会发生严重的竞态条件(Race Condition):
在这种方案下,假设线程A、B如下:
线程 A(写):动作是 删缓存 -> 写数据库。
线程 B(读):动作是 查缓存(Miss) -> 查数据库 -> 写入缓存。
执行流程为:
1.线程 A 删了缓存。
2.线程 A 开始写数据库(这是一个漫长的 IO 过程,假设需要 100ms)。
3.在这 100ms 内,线程 B 进来了,发现没缓存,去查库,查到了旧值。
4.线程 B 把旧值写入 Redis。
5.线程 A 终于写完数据库了(变成新值)。
结论:只要线程 A 的写数据库操作还没做完,这期间进入的所有查询请求(线程 B、C、D…)全都会拿到旧值并反写回 Redis。这个“空窗期”太长了(取决于数据库写操作的时间),所以极易发生。
正确方案(先改 DB):虽然“先改 DB 再删缓存”在极端情况下也会有短暂不一致,但由于数据库的写操作通常比读操作慢得多,上述竞态条件发生的概率极低。配合过期时间(TTL),这是目前业界公认的最优解。
你可以想象成是我们在 FPS 里面抓 timing, Redis 的速度极快,你很难抓到 timing,但是 DB 的速度相对慢,容易被抓 timing。
3. 原子性保证:如何确保两步都成功?
“修改数据库”和“删除缓存”是两个独立的操作。如果第一步(改 DB)成功了,第二步(删 Redis)失败了(比如 Redis 宕机),数据依然不一致。
解决方案:在代码层面,我们利用 Spring 的事务传播机制和代码执行顺序来兜底。通过在方法上添加 @Transactional 注解,确保数据库操作的原子性。
1.利用“短路”机制保护 Redis:我们将 delete Redis 放在最后,如果前面的数据库更新失败(抛出异常),代码会直接中断,delete 语句根本不会被执行。天然保证了 “DB 失败, Redis 不动”
2.利用 DB 回滚兜底:如果数据库更新成功,但随后的 Redis 删除超时报错,异常会触发 Spring 的事务回滚机制,将数据库瞬间恢复为旧值。
结论:虽然我们无法“回滚” Redis 的操作,但通过让数据库陪着 Redis 一起失败,我们成功实现了 同时成功,同时失败 的最终一致性效果。
三、 代码落地与实战
ShopServiceImpl/update
// ShopServiceImpl/update
@Override
@Transactional // 核心:事务管理,保证更新操作的原子性
public Result update(Shop shop) {
Long id = shop.getId();
if (id == null) {
return Result.fail("店铺 id 不能为空!");
}
// 1. 先更新数据库
// 思考:为什么先更库?为了避免多线程下,缓存被旧数据覆盖(竞态条件)
updateById(shop);
// 2. 后删除缓存
// 思考:采用删除而非更新,贯彻“懒加载”思想,避免无效写操作
stringRedisTemplate.delete(CACHE_SHOP_KEY + id);
return Result.ok();
}
// ShopServiceImpl/query
// 6.数据库存在 – 写入 redis (设置 TTL 兜底)
stringRedisTemplate.opsForValue().set(CACHE_SHOP_KEY + id , JSONUtil.toJsonStr(shop), CACHE_SHOP_TTL , TimeUnit.MINUTES);
return shop;
四、 总结与展望
通过 Cache Aside Pattern 配合“先更库、后删缓存”的策略,我们在黑马点评项目中较好地解决了缓存一致性问题。但需要承认的是,这种方案只能保证最终一致性,无法保证强一致性(在删除缓存动作完成前的毫秒级窗口内,用户读到的仍是旧数据)。
后续挑战: 解决了缓存一致性后,在高并发场景下,我们还面临着三个更棘手的挑战:
下一篇文章,我将重点复盘如何利用缓存空对象,手写解决缓存穿透难题。






评论前必须登录!
注册