 网硕互联帮助中心
网硕互联帮助中心本文基于 Calibre v2017.1 官方手册,聚焦 nmDRC-H(层级化 DRC) 的核心机制、性能优化手段、多线程运行及特殊场景处理,助力大规模层级化版图实现 “超快速验证 + 低内存占用 + 错误去重”,同时兼容扁平化规则文件,降低迁移成本。
一、nmDRC-H 核心价值与核心机制
nmDRC-H 是针对层级化版图的专用 DRC 工具,核心优势是复用单元(cell)验证结果,抑制重复错误,相比扁平化 nmDRC,可实现:
- 处理时间缩短 50%~90%(层级越深、单元复用率越高,收益越明显);
- 内存占用降低 30%~70%(数据存储在最低层级,避免重复加载);
- DRC 错误计数减少(重复单元的错误仅报告一次)。
Calibre nmDRC-H 可直接使用其平面化版本(Calibre nmDRC)的规则文件。除了层级化处理算法,以及通过层级化错误抑制功能减少设计规则错误数量这两点外,Calibre nmDRC 与 Calibre nmDRC-H 的运行表现基本一致。此外,有部分 SVRF 规范语句仅适用于 Calibre nmDRC-H。在使用 Calibre nmDRC 进行平面化 DRC 检查时,规则文件中若包含这类语句,工具会自动忽略。
Calibre nmDRC-H 对设计不施加任何限制,无论是单元放置时的图形重叠,还是单元放置区域本身的重叠,都可以兼容。
1 .1 Calibre nmDRC-H 结果数据存储
层级化处理的一个重要特性是:Calibre nmDRC-H 会将数据(包括原始图层图形和派生图层图形)保存在尽可能低的层级中。对于原始图层图形,这意味着工具会像用户原始设计那样,在单元内部仅存储一次对应数据。
生成派生图层图形的图层运算,会优先在每个单元内部完成分析;只有在需要结合上下文环境检查数据时,才会将数据提升至更高层级。随后,工具会在最低层级创建派生图层图形,并且和原始图层图形一样,在生成这些图形的单元内部仅存储一次。由于 DRC 结果本质上是映射到 DRC 结果数据库中的派生图层元素,因此 Calibre nmDRC-H 天然具备错误抑制的能力。以图1为例:
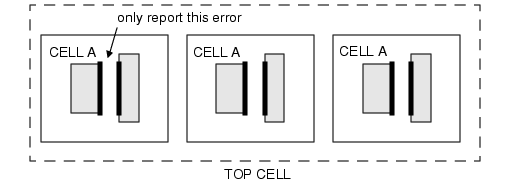
图1 Hierarchical Error Suppression
该设计包含三个单元 A 的实例,且单元 A 内部的两个图形存在间距违规问题。Calibre nmDRC-H 在分析单元 A 时就会检测到该错误,且这个错误的判定与上下文环境无关。因此,工具仅会在单元 A 的模板中存储一次该错误图形,并只报告一次该违规。
而传统的非层级化 DRC 工具会先将单元 A 平面化,导致顶层单元中出现六个图形,并最终报告三个独立的违规错误。在这个示例中,Calibre nmDRC-H 能够自动识别出其中两个错误属于重复错误,从而实现错误抑制。
Calibre nmDRC-H 生成的 ASCII 或二进制 DRC 结果数据库,其格式与平面化版本工具生成的数据库完全一致。同时,工具也会将所有 DRC 结果转换到顶层单元的坐标系中,这与平面化工具的处理逻辑保持一致。
错误抑制的具体执行逻辑如下:
Calibre nmDRC-H 与 Calibre nmDRC 生成的 ASCII 或二进制 DRC 结果数据库,唯一的区别在于前者的 DRC 结果数量通常更少。
1.2 本章小节
- 原始图层数据:按版图层级存储,单元模板(如 cell A)仅存储一次,复用单元无需重复加载;
- 派生图层数据(如错误层):优先在单元内部分析生成,仅当需要跨单元上下文时才 “提升” 层级,同样存储在最低可能层级。
- 若 cell A 包含 1 个间距错误,且版图中 cell A 被实例化 3 次:
- 扁平化 nmDRC:展开 cell A,报告 3 个重复错误;
- nmDRC-H:仅在 cell A 模板中存储 1 个错误,报告 1 次(自动关联所有实例化位置)。
二、nmDRC-H 与扁平化 nmDRC 的关键差异
在 DRC 汇总报告和结果数据库中,Calibre nmDRC 对平面化结果和层级化结果的展示方式有所不同。层级化结果展示提供了多种配置选项,帮助用户更高效地解读结果。
若要在 Calibre RVE 中按单元查看 DRC 结果,需要在规则文件中添加语句:DRC Cell Name YES CELL SPACE XFORM。该配置会让 Calibre nmDRC 在单元坐标系中展示结果,而非顶层单元坐标系。
| DRC 汇总报告 | 仅展示平面化结果数量 | 优先展示层级化结果数量,括号内标注预估的平面化结果数量;默认不展示单元独立统计数据(如需查看单元统计数据,可启用 DRC Summary Report HIER 选项) |
| DRC 结果数据库与 RDB 文件 | 存储平面化结果 | 每个 DRC 结果仅存储一次;结果位置映射到层级结构中层级最低、最靠左的错误单元实例的顶层边界内;默认不存储单元专属数据(如需存储单元相关结果,需配置 DRC Cell Name YES CELL SPACE XFORM) |
| Calibre RVE 结果展示 | 仅提供平面化视图 | 默认展示顶层单元结果(如需查看单元级结果,可选择 高亮 > 上下文高亮 功能) |
三、核心配置与运行方式
| 基础层级化运行 | calibre -drc -hier rule_file | 小规模层级化版图 | -hier:启用层级化模式 |
| 单机多线程加速 | calibre -drc -hier -turbo rule_file | 单机多核 CPU | -turbo:启用单机多线程(自动适配核心数) |
| 超缩放加速(推荐) | calibre -drc -hier -turbo -hyper rule_file | 单机多核高性能场景 | -hyper:并行处理层操作,比单纯 -turbo 快 2 倍 |
| 分布式加速 | calibre -drc -hier -turbo -remote host1,host2 -hyper rule_file | 超大规模版图(需多主机) | -remote:指定分布式主机列表;-remotefile:从文件读取主机配置 |
3.1 多线程运行模式
Calibre nmDRC-H 和 Calibre nmLVS-H 均支持多线程运行模式,可显著缩短工具的运行时间。多线程(MT)模式会调用同一台主机的多个 CPU 核心,通过命令行选项 -turbo 启用;Calibre MTflex 模式则可调用多台主机组成的网络中的 CPU 资源,通过命令行选项 -remote 或 -remotefile 启用。
3.2 超并行扩展模式
超并行扩展模式支持在多线程或 Calibre MTflex 运行过程中,对图层运算进行并行处理。该模式通过命令行选项 -hyper 启用,无需额外的许可证,仅需满足常规多线程或 Calibre MTflex 模式的授权要求。相较于普通多线程运行,超并行扩展模式通常能将运行时间再缩短一半,同时还能提升处理器资源的利用率。因此,只要硬件支持多线程或 Calibre MTflex 模式,建议优先启用超并行扩展模式,除非有明确的技术原因限制。
超并行扩展模式对层级化对象的计数方式,与传统层级化运行有所不同。具体来说,该模式会将工具内部识别的极小单元(如过孔和接触孔)进行平面化处理;同时,也会根据 Layout Base Layer 语句(或适用情况下的 Layout Top Layer 语句)的配置,对内部识别的顶层单元进行平面化。这意味着超并行扩展模式与传统层级化运行的对象计数结果可能存在差异,此为正常现象。两种模式的结果数量不同,并不代表某一方遗漏了另一方检测到的结果,而是因为超并行扩展模式会选择性地对部分数据进行平面化处理,进而影响最终的结果计数。
3.3 层级化运行效率
不同图层运算的性能表现存在差异。在选择各类图层运算及相关选项时,需要注意以下几点性能相关的特性:
尺寸检查类运算(如 Enclosure 包围检查、External 外部检查、Internal 内部检查)的运行速度,慢于大多数其他运算。尤其是在使用以下过滤条件时,性能差异会更为明显:带约束的 PROJECTING 投影过滤、未使用 OPPOSITE 关键字的区间约束、NOT PROJECTING 非投影过滤、NOTCH 缺口过滤或 SPACE 间距过滤、CONNECTED 连通过滤或 NOT CONNECTED 非连通过滤。
两层布尔运算的速度,通常快于多边形拓扑运算。
对于单层布尔运算(AND 运算,且约束条件不为 >= 1 或 > 1;XOR 异或运算),以及 Magnify 放大运算和 Rotate 旋转运算,Calibre nmDRC-H 会采用平面化处理方式。这会导致输出图层以独占式平面化实例的形式存在,对性能影响较大。
当测量约束包含 0 但不包含 90,或包含 90 但不包含 0 时,Angle 角度运算会以平面化方式执行,同样会带来较大的性能开销。
只有当某一单元的所有实例,在设计的平面化视图中具有一致的旋转或反射变换属性时,Shift 平移、Grow 扩张、Shrink 收缩运算才能在该单元内部完成。否则,输入图形必须被提升至具备上述变换属性的最低层级中进行处理,以确保运算结果与平面化视图的分析结果一致。
网面积比累积图层,在执行 Net Area Ratio Print 网面积比打印前,会被自动平面化。
相较于平面化模式,Rectangles 矩形提取运算在层级化模式下的处理逻辑更为复杂,属于运行速度较慢的层级化运算之一。
3.4 平面化实例化
Calibre nmDRC-H 支持图层以层级化和平面化两种形式存在。
一个图层可分为以下三种存在形式:
Calibre nmDRC-H 通过以下三种方式生成图层的平面化实例:
为了支持非层级化图层运算,或兼容平面化与层级化实例的共存,工具会自动执行所需的平面化处理,无需用户手动干预。
3.5 路径长度差异
在某些特殊情况下,层级化运行中 Path Length 路径长度运算的结果,可能与平面化运行的结果存在差异。这类情况通常出现在多边形顶点交汇的奇异点位置。
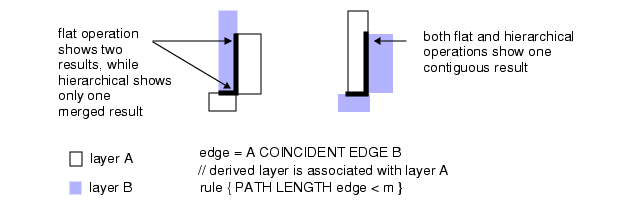
图2 层级化与平面化结果对比示意图
在图 2 左侧的示例中,有两个图层 A 的多边形在顶点处接触。使用平面化 Calibre nmDRC 分析时,会得到两个结果,此为预期结果;而使用层级化 Calibre nmDRC 分析时,仅会得到一个结果 —— 原因是派生的边缘图层是一个合并后的图层,层级化引擎不会保留原始图层 A 多边形与派生边缘图层之间的关联关系,因此在该场景下仅输出一个结果。这种结果数量的差异,仅会出现在图层 A 多边形存在奇异点的位置。
图 2 右侧展示的是常规对比案例。若在 Coincident Edge 重合边缘运算中互换图层 A 和图层 B 的顺序,也会得到类似的结果。后续的图层派生操作就利用了这一特性。
为了消除类似图 2 左侧场景中结果数量的差异,可以参考以下处理方法:
multi_A = A TOUCH B > 1
// 多个图层A的多边形与一个图层B的多边形接触
// multi_A 图层可能存在奇异点
single_A = A NOT TOUCH B > 1 // 该图层不存在奇异点
edge1 = multi_A COINCIDENT EDGE B
// 平面化运算在奇异点处显示2个结果
edge2 = B COINCIDENT EDGE multi_A
// 互换输入图层顺序;平面化运算在奇异点处显示1个结果
edge1 { PATH LENGTH edge1 < m }
edge2 { PATH LENGTH edge2 < m }
// 结果数量可能不同,但输出内容一致
edge = single_A COINCIDENT EDGE B
// single_A 图层无需针对奇异点做特殊处理
edge { PATH LENGTH edge < m }
3. 6 图层面积打印
在平面化工具中,首次生成某一图层时,会在运行日志中打印该多边形类型图层的总面积,以及其他相关统计数据。而层级化工具默认不会执行此操作,因为计算总面积会耗费大量时间。不过,用户可以通过配置 **DRC Print Area 规范语句 **,主动要求工具输出该信息。
该语句会指示层级化 Calibre 工具,在生成图层时计算并打印其平面化面积,同时输出该图层的其他相关统计数据。
相关主题图层面积打印图层周长打印
3.7 掩膜结果输出中的文本对象
通过配置 DRC Map Text 规范语句,可让 Calibre nmDRC-H 将输入版图数据库中的所有文本对象,转移到 Calibre nmDRC 掩膜数据结果数据库中。输入数据库与结果数据库中的文本对象,会保持相同的层级结构;但如果 Calibre nmDRC-H 在层级化处理过程中对某一单元实例进行了扩展或平面化操作,工具会将该单元内的文本对象相应地提升至更高层级。
用户可以结合使用 DRC Map Text YES 语句与 DRC Map Text Layer 语句,指定需要将哪些图层的输入文本对象写入输出结果。
默认情况下,即使文本图层被映射到其他图层,Calibre 工具也会保留几何输入版图数据库中的 TEXTTYPE 属性。若通过 Layer Map TEXTTYPE 规范语句映射文本对象,几何 DRC 结果数据库中的文本会被写入映射的目标图层,但原始的 TEXTTYPE 属性会被保留。示例如下:
LAYER MAP 10 TEXTTYPE 1 10 // 将图层10、文本类型1映射为Calibre图层10
LAYER mapped_text 10
TEXT LAYER 10 // 定义Calibre图层10为文本图层
DRC MAP TEXT YES // 将文本对象输出到掩膜结果中
DRC MAP TEXT LAYER mapped_text // 输出的文本图层保留原始文本类型1
在上述示例中,图层 10、文本类型 1 的文本对象被映射为 Calibre 图层 10,且输出结果中的文本对象仍保留文本类型 1。若在 Layer Map 语句中为文本对象指定了与输入不同的目标文本类型,则输出时会使用该目标文本类型。
相关主题文本对象映射文本图层映射图层映射
四、 Calibre nmDRC-H 对 Hcell 的使用
Hcell 语句用于 Calibre nmLVS-H 工具,作用是建立版图单元与源文件单元之间的对应关系。在电路提取过程中,版图中的 Hcell 会被完整保留。类似的效果也会出现在层级化 DRC 运行中。
只有当用户需要按照下述流程操作(即后续将掩膜结果图层用于 LVS 验证)时,才应在 Calibre nmDRC-H 的规则文件中添加 Hcell 或 Layout Preserve Cell List 规范语句。不建议单纯为了阻止 Calibre nmDRC-H 自动扩展单元而使用这些语句。
所有层级化 Calibre 工具的初始化阶段,都会基于原始输入版图数据库构建内部层级化数据库。为了优化 Calibre 算法的运行性能,工具会对原始数据库进行多项修改,其中最显著的就是自动扩展部分单元实例,以及自动创建新的单元和实例。工具自动扩展单元实例的原因有很多,其根本目的都是为了优化层级结构,提升算法运行效率。但版图 Hcell 的扩展可能会给 Calibre nmLVS-H 工具带来问题。因此,在 Calibre nmLVS-H 进行连通性提取的层级化数据库构建阶段,无论性能代价如何,工具都不会自动扩展规则文件中通过 Hcell 语句、Hcell 列表或 Layout Preserve Cell List 语句指定的任何版图单元。
在许多 Calibre nmDRC-H 的应用流程中,工具的目标是修改数据库,而非执行传统的 DRC 检查。Calibre nmDRC-H 生成的输出数据库,可能会用于后续的 LVS 验证。在这种情况下,不建议 DRC 流程扩展某些单元(单元扩展本质上是将其从层级结构中移除),因为这些单元可能会在后续的 LVS 流程中被指定为 Hcell。因此,无论性能代价如何,Calibre nmDRC-H 同样会禁止扩展规则文件中通过 Hcell 或 Layout Preserve Cell List 规范语句指定的任何版图单元。
需要注意的是,这并不意味着 DRC 运算不会跨 Hcell 边界处理数据。若在 Calibre nmDRC-H 中执行数据缩放等运算,数据很可能会从部分单元中被提升至更高层级。Hcell 仅会在层级结构中被保留,但其内部的数据仍有可能被提升到 Hcell 之外。
五. 关键 SVRF 配置语句(nmDRC-H 专属 / 优化)
(1)层级化结果呈现配置
- DRC CELL NAME YES CELL SPACE XFORM:
- 作用:在结果数据库中保留单元名称和单元空间坐标,支持在 Calibre RVE 中按单元查看结果(默认显示顶层坐标);
- 适用场景:单元级调试(如定位某个单元的重复错误)。
- DRC SUMMARY REPORT HIER:
- 作用:在 DRC 汇总报告中显示层级化错误计数(默认先显示层级化计数,括号内为预估扁平化计数);
- 示例:报告显示 METAL_SPACING: 2 (estimated flat: 100),表示层级化模式下仅 2 个独特错误,扁平化模式会报告 100 个重复错误。
(2)性能优化配置
- LAYOUT BASE LAYER <layer_name>(必选,超缩放模式):
- 作用:指定基础层,帮助工具优化层级化数据库构建,避免性能下降;
- 注意:超缩放(-hyper)模式下必须配置,否则会严重影响效率(优先于 LAYOUT TOP LAYER)。
- DRC PRINT AREA <layer_name>:
- 作用:强制层级化模式打印图层的扁平化面积(默认不打印,节省时间);
- 适用场景:需要验证图层面积统计的场景。
(3)文本对象映射配置(掩模结果输出)
- DRC MAP TEXT YES:
- 作用:将输入版图中的文本对象传递到掩模结果数据库(GDSII/OASIS);
- 关联语句:DRC MAP TEXT LAYER <layer_name>:指定需要映射文本的图层。
- 示例:
svrf
LAYER MAP 10 TEXTTYPE 1 10 ; 图层10.1映射到Calibre图层10
LAYER mapped_text 10
TEXT LAYER 10 ; 标记为文本层
DRC MAP TEXT YES ; 输出文本对象到掩模结果
DRC MAP TEXT LAYER mapped_text ; 仅映射mapped_text层的文本
(4)Hcell 相关配置(适配后续 LVS 流程)
- HCELL <cell_name1> [cell_name2 …] / LAYOUT PRESERVE CELL LIST <cell_list>:
- 作用:禁止工具自动扩展指定单元(保留层级结构),用于后续 Calibre nmLVS-H 流程(避免 LVS 无法识别 hcell);
- 注意:不可用于单纯阻止单元扩展以提升性能,仅适用于 “DRC→LVS” 联动流程。





评论前必须登录!
注册