 网硕互联帮助中心
网硕互联帮助中心接前置文章:
从零构建大模型读书记录(一)——理解大语言模型
从零构建大模型读书记录(二)——处理文本数据
从零构建大模型记录(三)——从零实现 Transformer 核心模块(下)已上传
本文将继续讨论注意力机制

引言
为什么要在神经网络中使用注意力机制呢?
传统的 RNN-based 机器翻译模型在生成目标词时,依赖于有限的上下文信息(如最后一个隐藏状态),难以有效建模长距离依赖,且训练过程串行、效率低。虽然后来的 Seq2Seq+Attention 模型通过引入注意力机制缓解了信息瓶颈问题,但仍受限于 RNN 的串行结构。
Transformer 架构提出“仅使用注意力机制”(Attention is All You Need),通过自注意力机制让每个词元在编码或解码时都能动态关注序列中所有其他词元,并根据语义相关性分配不同权重。这不仅显著提升了对长距离依赖的建模能力,还使得整个网络在训练阶段完全可并行化,极大加速了模型训练,推动了大语言模型的发展。
为直观理解这一机制,我们以一个具体场景为例:将英文句子 “The cat sat on the mat.” 翻译为法语 “Le chat s'est assis sur le tapis.”

一个基础的自注意力框架是怎样的
那么Transformer具体是怎么运行的,一个基础的自注意力框架是怎样的,自注意力机制的目标是为每个词元计算一个上下文向量,下面将以一个不带可训练权重的基础自注意力框架为例展示其运行过程。
1.自注意力的核心思想
“每个词都应当知道句子里其他词在说什么,并根据相关性加权融合。即得到每个词元的上下文向量”
例如,在句子 "The cat sat on the mat" 中:
-
当处理 "sat" 时,模型应关注 "cat"(主语)和 "mat"(地点);
-
当处理 "cat" 时,可能关注 "The"(冠词)和 "sat"(谓语)。
自注意力通过查询(Query)、键(Key)、值(Value) 机制实现这一点。
2.如何得到每个词元的上下文向量(简化演示)
tips:此部分为无参自注意力的简化演示,仅用于理解注意力的加权融合逻辑,并非 Transformer 的实际实现
以"The cat sat on the mat"为例,将其嵌入为3维向量
tensor( [ 2.2315, -0.7460, -0.0614], #The (x^1)
[-0.1235, 0.4462, 0.7265], #cat (x^2)
[ 1.4900, -2.0396, 1.0440], #sat (x^3)
[-0.6735, -0.5763, -0.9291], #on (x^4)
[ 0.7707, 0.5180, 0.2458], #the (x^5)
[ 0.6508, 0.1164, -1.3904]] #mat (x^6)
)
每个词元的上下文向量计算过程如下

2.1 计算注意力分数
实现注意力分数的第一步是计算注意力分数,即计算每个位置 i 的 Query 向量与所有位置 j 的 Key 向量的点积,得到注意力分数 A[i,j];因为点积在向量长度相近时可近似反映语义相似度,常用于衡量两个 token 的相关性。点积越大,说明两个向量方向越一致(夹角越小),语义相似度越高,注意力分数也越高。。例子中词元之间点积计算结果为:
tensor([[ 5.5401, -0.6531, 4.7825, -1.0159, 1.3183, 1.4509], #The与其他词元间的注意力分数,这些数由于未经训练,是随机生成的
[-0.6531, 0.7421, -0.3357, -0.8489, 0.3145, -1.0385],
[ 4.7825, -0.3357, 7.4699, -0.7981, 0.3484, -0.7192],
[-1.0159, -0.8489, -0.7981, 1.6490, -1.0459, 0.7864],
[ 1.3183, 0.3145, 0.3484, -1.0459, 0.9227, 0.2202],
[ 1.4509, -1.0385, -0.7192, 0.7864, 0.2202, 2.3702]],
grad_fn=<MmBackward0>))
2.2 注意力分数归一化
将注意力分数进行归一化,归一化后结果如下:
Attention Weight 2: tensor([[6.6504e-01, 1.3588e-03, 3.1176e-01, 9.4538e-04, 9.7572e-03, 1.1141e-02], #单词The归一化后分数,求和为1
[9.4845e-02, 3.8278e-01, 1.3028e-01, 7.7982e-02, 2.4960e-01, 6.4515e-02],
[6.3619e-02, 3.8089e-04, 9.3475e-01, 2.3987e-04, 7.5490e-04, 2.5956e-04],
[4.0282e-02, 4.7603e-02, 5.0084e-02, 5.7868e-01, 3.9091e-02, 2.4426e-01],
[3.5132e-01, 1.2875e-01, 1.3320e-01, 3.3033e-02, 2.3654e-01, 1.1716e-01],
[2.2166e-01, 1.8390e-02, 2.5308e-02, 1.1406e-01, 6.4745e-02, 5.5584e-01]],
grad_fn=<SoftmaxBackward0>)
Attention Weight 2 Sum: tensor([1.0000, 1.0000, 1.0000, 1.0000, 1.0000, 1.0000],
grad_fn=<SumBackward1>)
2.3 计算上下文向量
通过将嵌入词元与相应的注意力权重相乘,将得到的向量求和计算上下文向量,结果如下
tensor([[ 1.9626, -1.1256, 0.2716], #The与注意力权重相乘求和得到的上下文向量,这个上下文向量包含了注意力分数信息,因此携带该词语位置的向量都融合了全句信息。
[ 0.5403, -0.0738, 0.3074],
[ 1.5353, -1.9535, 0.9718],
[-0.0420, -0.3958, -0.7833],
[ 1.2028, -0.3592, 0.0755],
[ 0.8649, -0.1763, -0.8367]], grad_fn=<MmBackward0>)
2.4 代码示例
"""
如何得到每个词元的上下文向量(无参自注意力简化演示)
"""
import torch
import tiktoken
# ===================== 1. 分词与嵌入 =====================
# 初始化分词器(GPT2)
tokenizer = tiktoken.get_encoding('gpt2')
text = "The cat sat on the mat"
token_ids = tokenizer.encode(text) # 分词结果: [1169, 398, 6356, 286, 262, 1369]
print(f"分词后的token_ids: {token_ids}, shape: {torch.tensor(token_ids).shape}") # shape: [6]
# 定义嵌入层参数
vocab_size = tokenizer.n_vocab # GPT2词汇表大小
embedding_dim = 3 # 自定义嵌入维度(仅演示用)
embedding_layer = torch.nn.Embedding(
num_embeddings=vocab_size,
embedding_dim=embedding_dim
)
# 将 token IDs 转为 PyTorch 张量
input_ids = torch.tensor(token_ids) # shape: [seq_len] = [6]
# 获取嵌入向量:将离散token映射为连续向量
inputs = embedding_layer(input_ids) # shape: [seq_len, embedding_dim] = [6, 3]
print("\\n=== 输入嵌入向量 ===")
print("inputs shape:", inputs.shape) # 输出: torch.Size([6, 3])
print("inputs:\\n", inputs)
# ===================== 2. 计算注意力分数(点积) =====================
# 点积注意力分数:每个词元与所有词元的相似度
# inputs (6,3) @ inputs.T (3,6) → attn_scores (6,6)
attn_scores = inputs @ inputs.T # shape: [seq_len, seq_len] = [6, 6]
print("\\n=== 注意力分数 ===")
print("attn_scores shape:", attn_scores.shape) # 输出: torch.Size([6, 6])
print("attn_scores:\\n", attn_scores)
# ===================== 3. 注意力分数归一化(Softmax) =====================
# dim=-1: 对最后一维(每个词元的6个分数)做归一化,保证每行和为1
attn_weights = torch.softmax(attn_scores, dim=-1) # shape: [6, 6]
print("\\n=== 归一化注意力权重 ===")
print("Attention Weights shape:", attn_weights.shape) # 输出: torch.Size([6, 6])
print("Attention Weights:\\n", attn_weights)
# 验证每行和为1(归一化效果)
print("Attention Weights Sum (每行和):\\n", attn_weights.sum(dim=-1)) # shape: [6],值全为1.0
# ===================== 4. 计算上下文向量(加权求和) =====================
# attn_weights (6,6) @ inputs (6,3) → all_context_vecs (6,3)
all_context_vecs = attn_weights @ inputs # shape: [seq_len, embedding_dim] = [6, 3]
print("\\n=== 最终上下文向量 ===")
print("Context Vectors shape:", all_context_vecs.shape) # 输出: torch.Size([6, 3])
print("Context Vectors:\\n", all_context_vecs)
3.为自注意力机制添加可训练权重
上述演示了自注意力权重的计算过程,虽然直观,但缺乏学习能力。
真实模型通过引入可训练的 Q/K/V 投影矩阵,使注意力机制能够根据任务动态调整关注重点。”;在真实的 Transformer 中(如 GPT):嵌入层是通过大量文本训练得到的;“The” 和 “cat” 会因经常共现而嵌入向量靠近;自注意力会真正学会:生成 “cat” 时关注 “The”,生成 “sat” 时关注 “cat” 和 “mat”。但在随机初始化阶段,模型尚未学习到任何语义模式,注意力权重接近随机分布。那么自注意力机制如何进行训练呢,首先需要为自注意力机制添加可训练权重,通过引入可训练权重,可以使模型学会产出“好的”上下文向量。
自注意力的核心可学习参数为 W_Q、W_K、W_V 和输出投影矩阵。在端到端训练中,这些参数通过反向传播迭代更新,最终让模型具备*任务导向的动态聚焦能力—— 即针对不同任务和输入,自动识别最相关的词元。
W_Q, W_K, W_V可以类比为可学习的“软”数据库检索。W_K类比为数据库中的索引/键(Index/Key);W_V类比为数据库中的实际数据/记录(Value/Record)W_Q类比为用户发起的查询请求(Query);Attention Score类比为相似度匹配分数;Output类比为加权检索结果。
以"The cat sat on the mat"为例,将其嵌入为3维向量
tensor( [ 2.2315, -0.7460, -0.0614], #The (x^1)
[-0.1235, 0.4462, 0.7265], #cat (x^2)
[ 1.4900, -2.0396, 1.0440], #sat (x^3)
[-0.6735, -0.5763, -0.9291], #on (x^4)
[ 0.7707, 0.5180, 0.2458], #the (x^5)
[ 0.6508, 0.1164, -1.3904]] #mat (x^6)
)
添加可训练权重的词元的上下文向量计算过程如下:
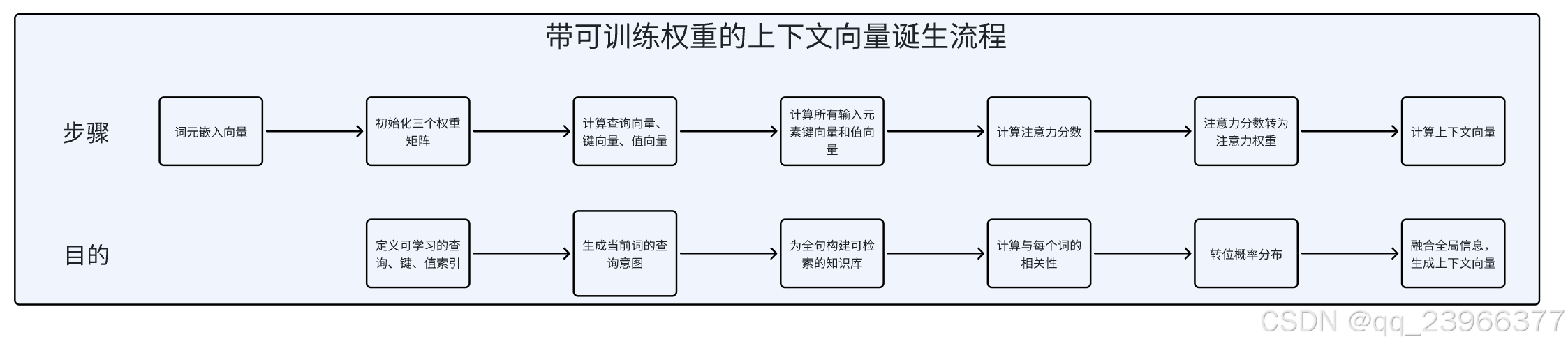
3.1 初始化权重矩阵
初始化3个权重矩阵:用于将原始嵌入投影到三个不同的语义子空间。这些矩阵是模型参数,在后续训练中通过反向传播更新
W_query Parameter containing:
tensor([[0.2961, 0.5166],
[0.2517, 0.6886],
[0.0740, 0.8665]]) # shape (3, 2)
W_key Parameter containing:
tensor([[0.1366, 0.1025],
[0.1841, 0.7264],
[0.3153, 0.6871]]) # shape (3, 2)
W_value Parameter containing:
tensor([[0.0756, 0.1966],
[0.3164, 0.4017],
[0.1186, 0.8274]]) # shape (3, 2)
3.2 计算查询向量、键向量、值向量
以第二个词元cat为例,通过矩阵乘法计算查询向量、键向量和值向量,假设输入嵌入维度为3,输出嵌入维度为2。计算示例:第一行第一列= (-0.1235* 0.2961) + (0.4462 * 0.2517) + (0.7265 * 0.0740)≈ -0.0366 + 0.1123 + 0.0538 ≈ 0.1295,以此类推。计算结果代表cat在当前上下文中发出的“查询请求”,它想知道哪些词与自己相关
query_2 tensor([0.1295, 0.8730])
key_2 tensor([0.2943, 0.8107])
value_2 tensor([0.2180, 0.7561])
3.3 计算所有词元键向量和值向量
得到所有输入词元的键向量和值向量,虽然计算的是cat的上下文向量,但是仍然需要所有词元的值向量和键向量,因为它们参与了计算相对于cat的注意力权重;可以通过矩阵乘法计算所有词元的的值向量和键向量,计算示例:第一行第一列2.2315×0.1366+(−0.7460)×0.1841+(−0.0614)×0.3153k1(1)=2.2315×0.1366+(−0.7460)×0.1841+(−0.0614)×0.3153=0.1481(第一个The的嵌入向量与W_K做矩阵乘法)。结果如下:
keys tensor([[ 0.1481, -0.3554], #cat对所有输入原属的键向量
[ 0.2943, 0.8107],
[ 0.1572, -0.6116],
[-0.4910, -1.1261],
[ 0.2781, 0.6242],
[-0.3280, -0.8041]])
values tensor([[-0.0745, 0.0883], #cat对所有输入原属的值向量
[ 0.2180, 0.7561],
[-0.4089, 0.3374],
[-0.3435, -1.1327],
[ 0.2513, 0.5630],
[-0.0788, -0.9757]])
3.4 计算注意力分数
计算cat的注意力分数(未缩放),使用cat作为查询词元和第3步的键向量计算注意力分数,计算示例:以cat为例,注意力分数=0.1295×0.2943 + 0.8730×0.8107 ≈ 0.0381 + 0.7078 ≈ 0.7458
attn_scores_2: tensor([-0.2911, 0.7458, -0.5136, -1.0466, 0.5809, -0.7444]) #cat与键向量之间点击点积计算得到未缩放的注意力分数
#分析可知:
#“cat” 与自己(i=2)得分最高(0.7458)→ 自关注很常见
#与 “the”(i=5)得分次高(0.5809)→ 可能因冠词-名词共现
#与 “sat”(i=3)得分很低(-0.5136)→ 当前权重下未捕捉主谓关系(因为未训练!)
3.5 注意力分数转为注意力权重
将注意力分数转换为注意力权重,通过缩放注意力分数(通过嵌入维度的平方根进行缩放可以防止嵌入维度太大影响训练效率,当嵌入维度较大时,点积的方差会增大,导致 softmax 进入饱和区(梯度接近 0),缩放可缓解此问题,所以叫缩放点积注意力机制)并使用softmax计算注意力权重,计算示例:以cat注意力分数缩放为例,缩放分数=0.7458/根号2=0.527,之后进行softmax归一化训练,Softmax 将分数转换为概率分布:每个权重 = exp(score) / 所有 exp(score) 之和。
最终得到权重形式如下:
attn_weights_2: tensor([0.1408, 0.2932, 0.1203, 0.0825, 0.2609, 0.1022])
#这些权重完全由当前 W_Q/W_K 决定。如果模型经过训练,W 会调整使得“sat”在生成时更关注“cat”,但现在是随机的。
3.6 计算上下文向量
通过将注意力权重作为加权因子对值向量进行加权求和来计算,用于衡量每个值向量的重要性,计算示例,0.1408×(−0.0745)+0.2932×0.2180+0.1203×(−0.4089)+0.0825×(−0.3435)+0.2609×0.2513+0.1022×(−0.0788)=0.0334。上下文向量形式如下:
context_vec_2 tensor([0.0334, 0.2284])
#这就是 “cat” 的上下文感知表示:
#它不再只是原始嵌入 [-0.1235, 0.4462, 0.7265]而是融合了全句信息的2D向量,后续会送入 FFN 或下一层,输出维度是可以改变的,不一定固定为2
3.7 代码示例
"""
引入可训练的Q/K/V权重矩阵的自注意力机制(完整版本)
代码仅以'cat'词元(第2个token)为例演示,实际中所有词元并行计算
"""
import torch
torch.manual_seed(123) # 固定随机种子,保证结果可复现
# ===================== 1. 初始化输入嵌入(模拟值) =====================
# 模拟6个词元的3维嵌入向量,对应句子:The cat sat on the mat
inputs = torch.tensor(
[[2.2315, -0.7460, -0.0614], # The (token 0)
[-0.1235, 0.4462, 0.7265], # cat (token 1,重点演示此词元)
[1.4900, -2.0396, 1.0440], # sat (token 2)
[-0.6735, -0.5763, -0.9291], # on (token 3)
[0.7707, 0.5180, 0.2458], # the (token 4)
[0.6508, 0.1164, -1.3904]] # mat (token 5)
) # shape: [seq_len, d_in] = [6, 3]
print("输入嵌入 inputs shape:", inputs.shape) # 输出: torch.Size([6, 3])
# 选取第2个词元(cat)作为演示的查询词元
x_2 = inputs[1] # shape: [d_in] = [3]
print("\\ncat词元的原始嵌入 x_2 shape:", x_2.shape) # 输出: torch.Size([3])
# ===================== 2. 定义维度与初始化Q/K/V权重矩阵 =====================
d_in = inputs.shape[1] # 输入嵌入维度: 3
d_out = 2 # Q/K/V输出维度: 2(可自定义,通常d_out=d_model/h,h为注意力头数)
# 初始化可训练权重矩阵(实际训练时requires_grad=True)
# W_query: [d_in, d_out] = [3, 2]
W_query = torch.nn.Parameter(torch.rand(d_in, d_out), requires_grad=False)
# W_key: [d_in, d_out] = [3, 2]
W_key = torch.nn.Parameter(torch.rand(d_in, d_out), requires_grad=False)
# W_value: [d_in, d_out] = [3, 2]
W_value = torch.nn.Parameter(torch.rand(d_in, d_out), requires_grad=False)
print("\\n=== Q/K/V权重矩阵 ===")
print("W_query shape:", W_query.shape, "\\n", W_query)
print("W_key shape:", W_key.shape, "\\n", W_key)
print("W_value shape:", W_value.shape, "\\n", W_value)
# ===================== 3. 计算单个词元(cat)的Q/K/V =====================
# query_2: x_2 (3) @ W_query (3,2) → [2]
query_2 = x_2 @ W_query # shape: [d_out] = [2]
# key_2: x_2 (3) @ W_key (3,2) → [2]
key_2 = x_2 @ W_key # shape: [d_out] = [2]
# value_2: x_2 (3) @ W_value (3,2) → [2]
value_2 = x_2 @ W_value # shape: [d_out] = [2]
print("\\n=== cat词元的Q/K/V向量 ===")
print("query_2 shape:", query_2.shape, "\\n", query_2)
print("key_2 shape:", key_2.shape, "\\n", key_2)
print("value_2 shape:", value_2.shape, "\\n", value_2)
# ===================== 4. 计算所有词元的K/V矩阵 =====================
# keys: inputs (6,3) @ W_key (3,2) → (6,2)
keys = inputs @ W_key # shape: [seq_len, d_out] = [6, 2]
# values: inputs (6,3) @ W_value (3,2) → (6,2)
values = inputs @ W_value # shape: [seq_len, d_out] = [6, 2]
print("\\n=== 所有词元的K/V矩阵 ===")
print("keys shape:", keys.shape, "\\n", keys)
print("values shape:", values.shape, "\\n", values)
# ===================== 5. 计算cat词元的注意力分数(未缩放) =====================
# attn_scores_2: query_2 (2) @ keys.T (2,6) → (6)
attn_scores_2 = query_2 @ keys.T # shape: [seq_len] = [6]
print("\\n=== cat词元的未缩放注意力分数 ===")
print("attn_scores_2 shape:", attn_scores_2.shape, "\\n", attn_scores_2)
# ===================== 6. 缩放+Softmax得到注意力权重 =====================
d_k = keys.shape[-1] # 键向量维度: 2
# 缩放:分数 / √d_k,防止点积值过大导致Softmax饱和
scaled_scores_2 = attn_scores_2 / (d_k ** 0.5) # shape: [6]
# Softmax归一化得到注意力权重
attn_weights_2 = torch.softmax(scaled_scores_2, dim=-1) # shape: [6]
print("\\n=== cat词元的注意力权重 ===")
print("attn_weights_2 shape:", attn_weights_2.shape, "\\n", attn_weights_2)
print("attn_weights_2 sum:", attn_weights_2.sum()) # 验证和为1.0
# ===================== 7. 计算cat词元的上下文向量 =====================
# context_vec_2: attn_weights_2 (6) @ values (6,2) → (2)
context_vec_2 = attn_weights_2 @ values # shape: [d_out] = [2]
print("\\n=== cat词元的最终上下文向量 ===")
print("context_vec_2 shape:", context_vec_2.shape, "\\n", context_vec_2)
总结
本文系统介绍了自注意力机制的基本原理与实现流程,并构建了一个简化的自注意力框架,从无参版本到引入可训练权重的完整形式,逐步揭示了其如何为每个词元生成上下文感知的表示。
然而,基础自注意力仍有局限:
-
缺乏因果约束:在语言生成任务中,模型不能“偷看”未来词;
-
单头表达能力有限:单一注意力头可能无法捕捉多样化的语义关系;
-
易过拟合:尤其在小数据集上,高维注意力权重可能导致泛化能力下降。
为此,现代大语言模型引入了多项增强设计:
因果注意力(Causal Attention):通过掩码机制确保解码时仅关注已生成的词元,保障自回归生成的合理性;
多头注意力(Multi-Head Attention):并行使用多个注意力头,分别学习不同子空间的语义关系(如语法、指代、主题等),再融合输出,显著提升模型表达能力;
注意力 Dropout:在训练时随机置零部分注意力权重,防止模型过度依赖特定词对,增强鲁棒性。
这些改进共同构成了 Transformer 的强大基础,使其不仅能高效处理长序列,还能在海量文本中学习复杂的语言规律。从“Attention is All You Need”到如今的千亿参数大模型,自注意力机制始终是驱动自然语言处理进步的核心引擎。
后续改进将在下一篇文章中继续展开介绍,欢迎大家点赞收藏关注,一起交流学习!
下一篇文章已上传:从零构建大模型记录(三)——从零实现 Transformer 核心模块(下)









评论前必须登录!
注册