 网硕互联帮助中心
网硕互联帮助中心一、什么是 MRR(Multi-Range Read)?
MRR(Multi-Range Read) 是 MySQL 从 5.6 版本开始引入的一种优化技术,主要用于优化 基于非聚簇索引(Secondary Index)进行范围查询或 IN 查询后回表(lookup)主键数据 的 I/O 效率。
在没有 MRR 的情况下,MySQL 执行器会逐行通过二级索引查到主键值后,立即去聚簇索引(InnoDB 的主键索引)中查找对应的完整行数据。这种“随机 I/O”模式在大量回表操作时效率极低。
MRR 的核心思想是:将多个需要回表的主键值先收集起来,排序后再批量顺序读取聚簇索引中的数据页,从而将原本的随机 I/O 转化为近似顺序 I/O,大幅提升磁盘读取效率(尤其对机械硬盘效果显著)。
二、MRR 的工作原理
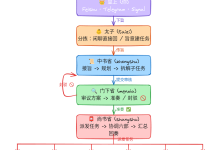
1. 基本流程(以 InnoDB 引擎为例):
MRR 在 Server 层中“发挥作用”,但需要存储引擎配合才能生效
2. 关键参数
- read_rnd_buffer_size:控制 MRR 缓冲区大小(单位字节),默认 256KB。增大该值可提升 MRR 批量处理能力,但会占用更多内存。
- optimizer_switch 中的 mrr 和 mrr_cost_based:
- mrr=on/off:是否启用 MRR。
- mrr_cost_based=on/off:是否基于成本模型决定是否使用 MRR(默认 on)。若设为 off,则只要可能就强制使用 MRR。
可通过以下命令查看:
SELECT @@optimizer_switch;
— 示例输出中包含:mrr=on,mrr_cost_based=on
三、MRR 的适用场景
MRR 主要在以下场景下生效:
二级索引范围查询 + 回表
SELECT * FROM t WHERE idx_col BETWEEN 100 AND 200;
IN 查询 + 回表
SELECT * FROM t WHERE idx_col IN (1, 5, 10, 100);
JOIN 中使用二级索引进行 lookup(Batched Key Access, BKA)
BKA 是 MRR 的扩展,用于优化 JOIN。当使用 JOIN 且驱动表结果用于被驱动表的索引查找时,BKA 会利用 MRR 批量获取被驱动表的数据。
⚠️ 注意:MRR 仅适用于 需要回表 的情况。如果查询是覆盖索引(Covering Index),即所有字段都在二级索引中,则无需回表,MRR 不会触发。
四、MRR 的优势与局限
优势:
- 显著减少随机 I/O:将多次随机磁盘访问合并为顺序访问,对 HDD 性能提升明显(SSD 上也有一定收益)。
- 提高缓存命中率:顺序读取更利于 InnoDB Buffer Pool 的局部性原理。
- 与 BKA 联动优化 JOIN:在多表连接中大幅减少嵌套循环的 I/O 开销。
局限:
- 增加 CPU 和内存开销:需要排序主键值,消耗 CPU;缓冲区占用内存。
- 可能打乱结果顺序:若查询依赖原始顺序(如无 ORDER BY 但应用假定顺序),需注意 MRR 可能改变返回顺序(不过 MySQL 通常会保证逻辑正确性)。
- 成本模型可能误判:在 mrr_cost_based=on 时,优化器可能因统计信息不准而错误地禁用 MRR。
- 对 SSD 效果减弱:SSD(Solid State Drive,固态硬盘) 随机读性能接近顺序读,MRR 收益不如 HDD(Hard Disk Drive,机械硬盘) 明显。
五、MRR 与相关技术对比
| MRR | 优化二级索引回表 | 是 | 随机 → 顺序 |
| 覆盖索引(Covering Index) | 避免回表 | 否 | 完全避免回表 I/O |
| ICP(Index Condition Pushdown) | 减少回表次数 | 是 | 在存储引擎层过滤,减少不必要的回表 |
| BKA(Batched Key Access) | 优化 JOIN 中的 lookup | 是 | 基于 MRR 实现批量回表 |
实际中,MRR 常与 ICP、BKA 配合使用,形成组合优化。
六、MRR 如何与 Buffer Pool 交互?
1. 提升 Buffer Pool 命中率(Cache Locality)
在非 MRR 模式下:
- 回表操作按二级索引的顺序进行,而二级索引的主键值通常是无序的(除非是自增主键且插入有序)。
- 导致聚簇索引页的访问呈随机分布,可能频繁访问不同数据页,超出 Buffer Pool 容量后造成大量换入换出(thrashing)。
启用 MRR 后:
- 主键值被排序,回表时按主键升序访问聚簇索引。
- 聚簇索引在物理上按主键顺序存储,因此连续的主键往往落在相邻的数据页中。
- 这使得:
- 已加载到 Buffer Pool 的页更可能被后续请求复用(空间局部性增强);
- 即使页不在内存中,顺序读也更容易触发 InnoDB 的线性预读(linear read-ahead),提前加载后续页。
结果:Buffer Pool 命中率提高,物理 I/O 次数进一步减少。
2. 激活 InnoDB 预读机制(Read-Ahead)
InnoDB 有两种预读机制:
- 随机预读(Random Read-Ahead):当某个区(extent, 1MB)中有一定数量的页被访问,就预读整个区(MySQL 5.6+ 默认关闭)。
- 线性预读(Linear Read-Ahead):当顺序访问某个区中的多个页(由 innodb_read_ahead_threshold 控制,默认 56 页),则预读下一个区。
MRR 排序后的主键访问模式天然符合线性预读的触发条件。例如:
主键排序后:1001, 1002, …, 1100
→ 对应聚簇索引页可能是 page#100, page#101, page#102…
→ 顺序访问 → 触发 linear read-ahead → 提前加载 page#103~112
这在扫描大量数据时尤为有效,大幅减少 I/O 等待。
注意:若 read_rnd_buffer_size 设置过小,MRR 批次太小,可能不足以触发预读。
3. 减少 Buffer Pool 污染(Pollution)
在高并发 OLTP 场景中,大量随机回表可能导致:
- 大量“一次性”数据页被加载进 Buffer Pool;
- 挤占热点数据页,导致缓存效率下降(即“缓存污染”)。
MRR 通过集中、批量、顺序访问,使得:
- 数据页访问更集中;
- 更容易形成“热区”,而非分散的冷页;
- 有利于 InnoDB 的 old sublist 机制(将新读入的页先放入 old 区,避免立即淘汰热数据)。
七、总结(Summary)
MRR(Multi-Range Read)是 MySQL 针对 二级索引回表操作 的一项重要 I/O 优化技术。
其核心在于 将离散的主键查找请求缓冲、排序后批量顺序执行,从而将高成本的随机 I/O 转化为高效的顺序 I/O。
它在机械硬盘环境下效果尤为显著,同时为 BKA(批量键访问)提供基础支持,极大提升了复杂查询(尤其是多表 JOIN)的性能。
尽管 MRR 会带来一定的 CPU 和内存开销,且在 SSD 环境下收益减弱,但在大多数 OLTP 和混合负载场景中,合理启用 MRR 仍是提升查询效率的有效手段。
八、面试可能问到的问题
问题 1:
MySQL 中的 MRR(Multi-Range Read)是什么?它在什么场景下生效?为什么能提升性能?
考察点:对 MRR 原理、适用条件和性能收益的理解。
问题一:
MRR主要用于优化通过二级索引进行范围查询或 IN 查询后回表(lookup)主键数据的过程。
问题二: 生效场景
MRR 在以下条件同时满足时才会被优化器考虑使用:
- 查询使用了非聚簇索引(Secondary Index);
- 该索引不能覆盖查询所需的所有字段(即需要回表);
- 查询条件涉及多个离散值或范围,例如 WHERE idx_col IN (1, 5, 100) 或 BETWEEN;
- 优化器认为启用 MRR 能降低执行成本(可通过 optimizer_switch='mrr=on,mrr_cost_based=off' 强制开启)。
问题3. 工作原理与性能提升原因
在没有 MRR 时,MySQL 会逐行通过二级索引拿到主键后立即回表,导致大量随机 I/O。
而 MRR 的做法是:
- 先将所有需要回表的主键值收集到一个缓冲区(read_rnd_buffer);
- 对这些主键排序;
- 然后按主键顺序批量访问聚簇索引
这样做的好处是:
- 将原本的随机 I/O 转化为近似顺序 I/O,大幅减少磁盘寻道时间(尤其对 HDD 效果显著);
- 提升 InnoDB Buffer Pool 的空间局部性,提高缓存命中率;
- 更容易触发 InnoDB 的线性预读(linear read-ahead),进一步减少物理 I/O。
问题 2:
MRR 和覆盖索引(Covering Index)都能优化查询性能,它们有什么区别?在什么情况下应该优先考虑哪一种?
考察点:对不同优化技术的对比分析能力,以及实际调优中的权衡思维。
问题1. 核心区别
| 目标 | 优化必须回表时的 I/O 效率 | 避免回表,完全从索引中获取数据 |
| 是否需要访问聚簇索引 | 是(但以更高效方式) | 否 |
| I/O 类型 | 将随机 I/O 转为顺序 I/O | 完全消除回表 I/O |
| 存储开销 | 无额外索引开销 | 需要创建包含更多列的宽索引,占用更多磁盘和内存 |
| 适用查询 | SELECT * 或含非索引列的查询 | SELECT 列全部包含在索引中的查询 |
问题2. 优先级原则:
覆盖索引 > MRR
-
首选覆盖索引:
如果业务查询的字段集合固定且不大,应优先设计覆盖索引。因为不回表是最彻底的优化,无论底层是 HDD 还是 SSD 都有显著收益,且 CPU 开销更低。
示例:
— 若经常查 (user_id, status),可建联合索引
CREATE INDEX idx_user_status ON orders(user_id, status);
SELECT user_id, status FROM orders WHERE user_id = 123; — 覆盖索引,无需回表 -
次选 MRR:
当无法使用覆盖索引时(如 SELECT *、查询字段太多、或字段含大文本),MRR 成为重要的兜底优化手段,尤其在 HDD 环境或大批量回表场景下。
问题3. 实际调优建议
- 覆盖索引虽好,但不是万能的:索引过宽会拖慢写入性能、增大 Buffer Pool 压力;
- MRR 是执行层的运行时优化,无需改表结构,但依赖查询模式和硬件特性;
- 最佳实践:先尝试覆盖索引,若不可行再确保 MRR 可用并合理配置 read_rnd_buffer_size。
总结一句话
覆盖索引是从“要不要回表”上做根本性优化,MRR 是在“不得不回表”的前提下做效率优化——前者优先级更高。





评论前必须登录!
注册