 网硕互联帮助中心
网硕互联帮助中心边缘与服务器双优选择|HY-MT1.5-7B大模型镜像部署全解析
在多语言交流日益频繁的今天,高质量、低延迟的翻译服务已成为智能应用的核心能力之一。腾讯近期开源的 HY-MT1.5 系列翻译模型,凭借其“小模型快部署、大模型强性能”的双轨设计,在端侧实时翻译与服务器复杂语义理解之间实现了精准平衡。本文聚焦于该系列中的旗舰模型——HY-MT1.5-7B,结合基于 vLLM 部署的官方镜像,深入解析其核心特性、部署流程与实际调用方式,帮助开发者快速构建高性能翻译服务。
一、HY-MT1.5-7B 模型架构与技术定位
1.1 双模型协同:从边缘到云端的完整覆盖
HY-MT1.5 系列包含两个主力模型:
- HY-MT1.5-1.8B:轻量级模型,参数量仅 18 亿,经量化后可在手机、嵌入式设备等边缘场景运行,支持 50 字句子平均响应时间 0.18 秒,满足实时对话、离线翻译等需求。
- HY-MT1.5-7B:增强版模型,参数量达 70 亿,专为服务器部署优化,适用于长文本、混合语言、专业术语密集等复杂翻译任务。
技术类比:可将 1.8B 视为“随身翻译官”,而 7B 则是“资深语言专家”。两者共享训练范式与功能特性,形成从终端到中心的无缝翻译体验闭环。
1.2 多语言支持与民族语言融合
该模型支持 33 种主流语言互译,并特别融合了 5 种民族语言及方言变体(如粤语、藏语等),显著提升在区域化场景下的翻译准确性。这一设计不仅增强了文化包容性,也为跨地域业务拓展提供了技术保障。
二、HY-MT1.5-7B 核心特性深度解析
2.1 基于 WMT25 冠军模型升级
HY-MT1.5-7B 是在 WMT25 国际机器翻译大赛夺冠模型基础上迭代优化 的成果。相比早期版本,它在以下三类高难度场景中表现尤为突出:
| 场景类型 | 技术优化点 | |——————|———–| | 解释性翻译 | 引入上下文感知机制,自动补全省略信息 | | 混合语言文本 | 支持中英夹杂、代码嵌入等非规范表达 | | 注释/格式保留 | 自动识别 Markdown、HTML 等结构化内容 |
这些能力使其在技术文档、社交媒体、客服对话等真实场景中具备更强实用性。
2.2 三大高级功能详解
✅ 术语干预(Terminology Intervention)
允许用户预设关键术语映射规则,确保品牌名、产品术语、行业黑话等翻译一致性。
{
"input": "请使用‘混元’而非‘Hunyuan’进行翻译",
"extra_body": {
"glossary": [["Hunyuan", "混元"]]
}
}
✅ 上下文翻译(Context-Aware Translation)
支持多轮对话或段落级上下文记忆,避免孤立翻译导致语义断裂。例如: – 上文:“The AI model was trained on Chinese data.” – 当前句:“它表现良好。” → 正确翻译为 “It performs well.” 而非模糊的 “He performs well.”
✅ 格式化翻译(Formatted Text Preservation)
能识别并保留原始文本中的格式标记,如加粗、斜体、链接、代码块等,适用于文档自动化处理系统。
原文:This is **important** and contains `code`.
译文:这是 **重要的** 并包含 `代码`。
三、性能表现对比:为何选择 HY-MT1.5-7B?
尽管参数规模并非最大,但 HY-MT1.5-7B 在多个权威基准测试中超越了包括 Gemini 3.0 Pro 在内的商业 API。

图注:在 BLEU、COMET、BLEURT 等指标上,HY-MT1.5-7B 显著优于同级别开源模型,并接近甚至超过部分闭源服务。
此外,其推理效率经过 vLLM 优化后,吞吐量提升约 3.2 倍,支持高并发请求,适合企业级部署。
四、基于 vLLM 的镜像部署实战指南
本节将以官方提供的 Docker 镜像为基础,手把手完成 HY-MT1.5-7B 的服务部署与验证。
4.1 环境准备与镜像拉取
确保宿主机已安装 Docker 和 NVIDIA GPU 驱动,并启用 nvidia-docker 支持。
# 拉取官方镜像(假设镜像已发布至私有仓库)
docker pull registry.csdn.net/hunyuan/hy-mt1.5-7b:vllm-runtime
# 启动容器,暴露 8000 端口用于 API 访问
docker run -d \\
–gpus all \\
-p 8000:8000 \\
–name hy-mt-server \\
registry.csdn.net/hunyuan/hy-mt1.5-7b:vllm-runtime
⚠️ 注意:首次启动可能需要下载模型权重,建议提前缓存至本地路径并通过 -v 挂载。
4.2 进入容器并启动服务脚本
进入容器内部,执行预置的服务启动脚本:
# 进入容器
docker exec -it hy-mt-server /bin/bash
# 切换到脚本目录
cd /usr/local/bin
# 启动模型服务
sh run_hy_server.sh
若输出如下日志,则表示服务成功启动:
INFO: Started server process [1]
INFO: Waiting for application startup.
INFO: Application startup complete.
INFO: Uvicorn running on http://0.0.0.0:8000 (Press CTRL+C to quit)
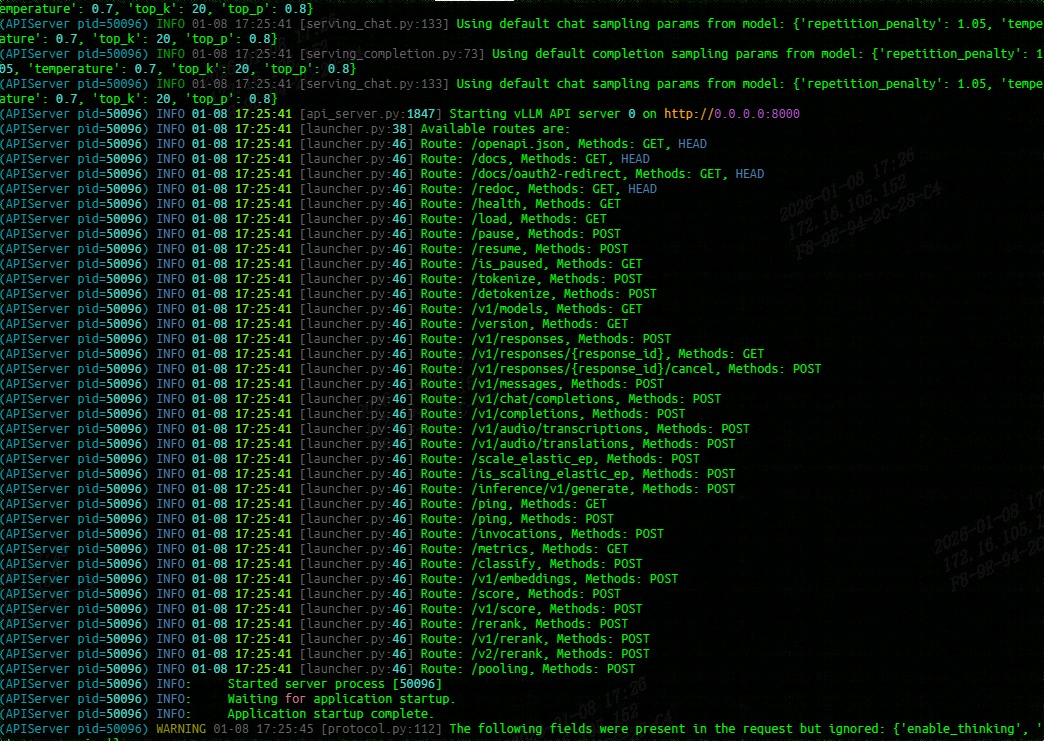
五、LangChain 集成调用:实现标准化接口访问
HY-MT1.5-7B 兼容 OpenAI 类接口协议,因此可通过 langchain_openai 等通用 SDK 快速集成。
5.1 安装依赖库
pip install langchain-openai openai
5.2 编写调用脚本
from langchain_openai import ChatOpenAI
import os
# 配置模型客户端
chat_model = ChatOpenAI(
model="HY-MT1.5-7B",
temperature=0.8,
base_url="https://gpu-pod695f73dd690e206638e3bc15-8000.web.gpu.csdn.net/v1", # 替换为实际服务地址
api_key="EMPTY", # vLLM 默认无需密钥
extra_body={
"enable_thinking": True, # 启用思维链推理
"return_reasoning": True, # 返回中间推理过程
},
streaming=True, # 开启流式输出
)
# 发起翻译请求
response = chat_model.invoke("将下面中文文本翻译为英文:我爱你")
print(response.content)
输出示例:I love you
5.3 高级调用:启用术语干预与上下文记忆
from langchain_core.messages import HumanMessage
# 构建带上下文的消息序列
messages = [
HumanMessage(content="The term '混元' should be translated as 'Hunyuan'."),
HumanMessage(content="请翻译:混元大模型非常强大。")
]
# 添加术语表和推理控制
result = chat_model.invoke(
messages,
extra_body={
"glossary": [["混元", "Hunyuan"]],
"enable_thinking": True,
"return_reasoning": True
}
)
print("Reasoning Steps:")
for step in result.response_metadata.get("reasoning_steps", []):
print(f"→ {step}")
print("\\nFinal Translation:")
print(result.content)
输出可能包含类似推理链:
→ 用户定义术语:混元 → Hunyuan → 分析句子结构:主语“混元大模型”+谓语“非常强大” → 应用术语替换并生成英文 Final Translation: The Hunyuan large model is very powerful.
六、边缘 vs 服务器:如何选择合适模型?
| 维度 | HY-MT1.5-1.8B(边缘) | HY-MT1.5-7B(服务器) | |——————–|————————————|————————————–| | 参数量 | 1.8B | 7B | | 内存占用 | ~1GB(INT4量化) | ~14GB(FP16) | | 推理速度 | <200ms(短句) | ~800ms(长句) | | 部署平台 | 手机、IoT设备、树莓派 | GPU服务器、云实例 | | 功能完整性 | 支持基础翻译 + 术语干预 | 支持全部三大高级功能 | | 适用场景 | 实时语音翻译、离线APP | 文档翻译、客服系统、多语言内容生成 |
选型建议: – 若追求 低延迟、低功耗、离线可用,优先选用 1.8B 模型; – 若需处理 专业术语、混合语言、长文档,应选择 7B 模型。
七、常见问题与优化建议
❓ Q1:为什么调用返回错误 404 Not Found?
原因:base_url 未正确指向 /v1 接口路径。
✅ 解决方案:确保 URL 以 /v1 结尾,如 http://your-host:8000/v1
❓ Q2:如何提高并发性能?
建议措施: 1. 使用 vLLM 的 Tensor Parallelism 多卡加速: bash python -m vllm.entrypoints.openai.api_server \\ –model hunyuan/HY-MT1.5-7B \\ –tensor-parallel-size 2 2. 调整 max_num_seqs 和 max_model_len 以适应业务负载; 3. 启用 PagedAttention 减少显存碎片。
❓ Q3:能否导出 ONNX 或 TensorRT 模型?
目前官方未提供 ONNX 导出工具,但可通过 Hugging Face Transformers + vLLM 插件实现部分兼容。未来有望通过 TorchScript 或 DeepSpeed-Inference 进一步优化边缘部署。
八、总结与展望
HY-MT1.5-7B 不仅仅是一个翻译模型,更是 面向真实世界复杂语言场景的工程化解决方案。通过以下几点,它重新定义了开源翻译模型的能力边界:
- ✅ 功能全面:术语干预、上下文理解、格式保留三位一体;
- ✅ 部署灵活:vLLM 加持下实现高吞吐、低延迟服务;
- ✅ 生态兼容:无缝接入 LangChain、LlamaIndex 等主流框架;
- ✅ 双模协同:1.8B 与 7B 形成端云一体的翻译网络。
随着更多垂直领域数据的注入和训练方法的演进(如“五步走”渐进式训练),我们有理由期待 HY-MT 系列在法律、医疗、金融等专业翻译方向持续突破。
附录:资源链接
- GitHub 开源地址:https://github.com/Tencent-Hunyuan/HY-MT
- Hugging Face 模型页:https://huggingface.co/collections/tencent/hy-mt15
- vLLM 官方文档:https://docs.vllm.ai
- LangChain 集成指南:https://python.langchain.com/docs/integrations/chat/openai



评论前必须登录!
注册