 网硕互联帮助中心
网硕互联帮助中心ZooKeeper入门实战:从零开始掌握分布式协调服务
在分布式系统中,如何让多个服务节点协同工作?如何实现服务注册与发现?如何保证配置的一致性?答案都在ZooKeeper这个强大的分布式协调服务中。
一、什么是ZooKeeper?
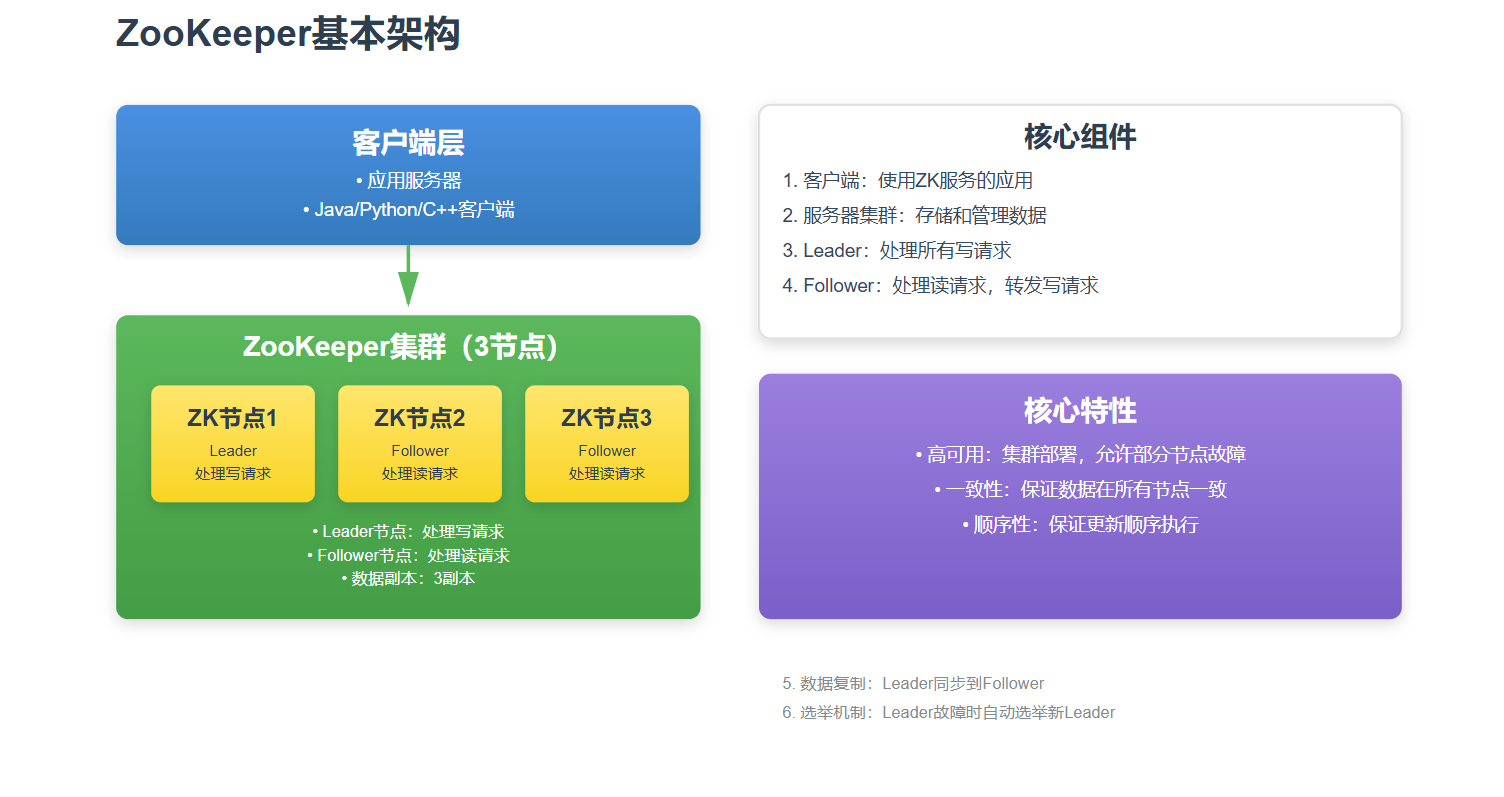
ZooKeeper是一个开源的分布式协调服务,由Apache基金会维护。它最初是雅虎公司为了解决分布式系统中的协调问题而开发的,现在已经成为Hadoop、HBase、Kafka等众多分布式系统的基础设施。
1.1 ZooKeeper的核心特性
- 简单性:提供了一个类似文件系统的层级命名空间
- 高可用性:通过集群部署保证服务的高可用性
- 一致性:保证数据在所有服务器上的一致性
- 实时性:客户端可以实时获取数据的变化通知
1.2 为什么需要ZooKeeper?
在分布式系统中,我们经常面临以下挑战:
- 服务注册与发现:微服务架构中,服务如何相互发现?
- 配置管理:多个服务实例如何保持配置一致?
- 分布式锁:如何避免多个服务同时操作同一资源?
- Leader选举:如何从多个服务节点中选出一个主节点?
- 分布式协调:如何协调多个服务节点的行为?
ZooKeeper正是为了解决这些问题而生的!
二、ZooKeeper的数据模型
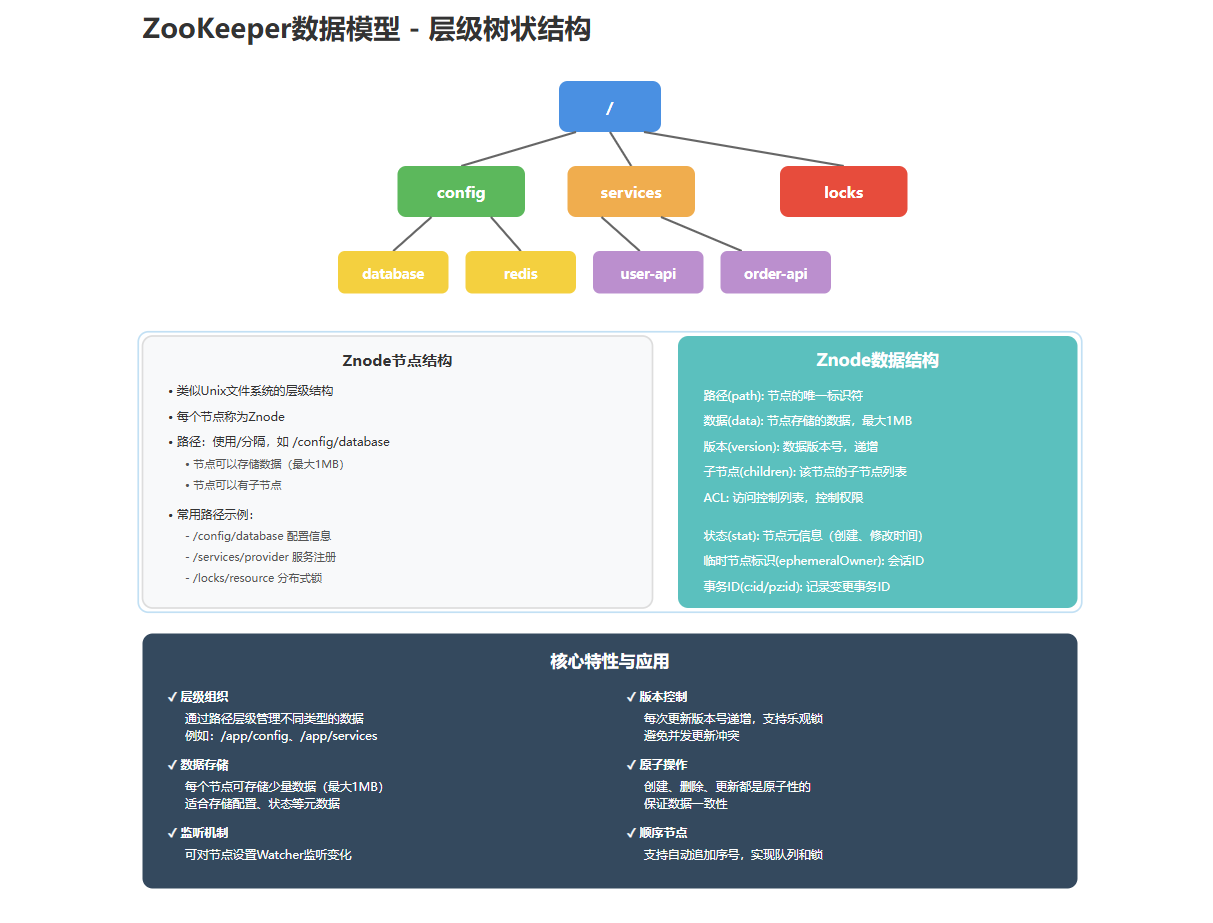
ZooKeeper的数据模型类似于Unix文件系统,采用层级化的树状结构。树中的节点被称为"Znode"。
2.1 Znode的类型
根据节点的生命周期和特性,Znode可以分为四种类型:
1. 持久节点(PERSISTENT)
- 节点创建后会一直存在,直到显式删除
- 适用于存储配置信息、服务列表等数据
- 示例:/config/database
2. 临时节点(EPHEMERAL)
- 节点的生命周期与客户端会话绑定
- 客户端会话结束后,节点自动删除
- 适用于服务注册、心跳检测等场景
- 示例:/services/provider-001
3. 持久顺序节点(PERSISTENT_SEQUENTIAL)
- 基本特性与持久节点相同
- 创建时自动在节点名后追加10位数字序号
- 适用于分布式队列、全局ID生成等场景
- 示例:/tasks/seq-0000000001
4. 临时顺序节点(EPHEMERAL_SEQUENTIAL)
- 基本特性与临时节点相同
- 创建时自动追加序号
- 适用于分布式锁、Leader选举等场景
- 示例:/locks/resource-0000000001

2.2 Znode的结构
每个Znode包含以下信息:
public class ZnodeData {
String path; // 节点路径
byte[] data; // 节点数据(最大1MB)
int version; // 数据版本号
int cversion; // 子节点版本号
int aversion; // ACL版本号
long ephemeralOwner; // 临时节点所属会话ID
long dataLength; // 数据长度
int numChildren; // 子节点数量
long pzxid; // 最后修改子节点的事务ID
}
三、ZooKeeper的基本操作
ZooKeeper提供了丰富的API来进行节点操作,主要包括以下几类:
3.1 创建连接
首先需要创建ZooKeeper客户端连接:
public class ZooKeeperConnection {
private static final int SESSION_TIMEOUT = 30000; // 30秒会话超时
private static final String CONNECTION_STRING = "localhost:2181";
private ZooKeeper zooKeeper;
private CountDownLatch connectedLatch = new CountDownLatch(1);
public ZooKeeper connectSync() throws IOException, InterruptedException {
zooKeeper = new ZooKeeper(CONNECTION_STRING, SESSION_TIMEOUT, event -> {
if (event.getState() == Event.KeeperState.SyncConnected) {
connectedLatch.countDown();
}
});
connectedLatch.await(10, TimeUnit.SECONDS);
return zooKeeper;
}
}
关键参数说明:
- connectionString:服务器地址,格式为host:port,多个服务器用逗号分隔
- sessionTimeout:会话超时时间,单位毫秒
- watcher:监听器,用于接收ZooKeeper的事件通知
3.2 创建节点
// 创建持久节点
String path = zooKeeper.create(
"/config/database", // 节点路径
"mysql://localhost:3306/db".getBytes(), // 数据
ZooDefs.Ids.OPEN_ACL_UNSAFE, // 权限(开放)
CreateMode.PERSISTENT // 节点类型
);
// 创建临时节点
String tempPath = zooKeeper.create(
"/services/provider-001",
"192.168.1.100:8080".getBytes(),
ZooDefs.Ids.OPEN_ACL_UNSAFE,
CreateMode.EPHEMERAL
);
// 创建顺序节点
String seqPath = zooKeeper.create(
"/tasks/task-",
"task data".getBytes(),
ZooDefs.Ids.OPEN_ACL_UNSAFE,
CreateMode.PERSISTENT_SEQUENTIAL
);
// 返回路径如:/tasks/task-0000000001
生产环境最佳实践:
3.3 读取节点数据
// 读取数据
byte[] data = zooKeeper.getData("/config/database", false, null);
String config = new String(data);
// 读取数据并监听变化
Stat stat = new Stat();
byte[] data = zooKeeper.getData("/config/database", watcher, stat);
System.out.println("版本号:" + stat.getVersion());
System.out.println("数据大小:" + stat.getDataLength());
数据版本控制:
- 每次数据更新都会增加版本号
- 可以使用CAS(Compare-And-Swap)机制进行乐观锁更新
- Stat对象包含节点的详细元信息
3.4 更新节点数据
// 获取当前状态
Stat stat = zooKeeper.exists("/config/database", false);
// 使用版本号更新(乐观锁)
Stat newStat = zooKeeper.setData(
"/config/database",
"mysql://prod-db:3306/appdb".getBytes(),
stat.getVersion() // 指定版本号
);
注意事项:
3.5 删除节点
// 删除节点(需要指定版本号)
Stat stat = zooKeeper.exists("/config/old", false);
if (stat != null) {
zooKeeper.delete("/config/old", stat.getVersion());
}
// 递归删除节点及其子节点
public void deleteRecursive(String path) throws Exception {
List<String> children = zooKeeper.getChildren(path, false);
for (String child : children) {
deleteRecursive(path + "/" + child);
}
zooKeeper.delete(path, –1);
}
3.6 获取子节点列表
// 获取子节点列表
List<String> children = zooKeeper.getChildren("/services", false);
// 遍历子节点
for (String child : children) {
String childPath = "/services/" + child;
byte[] data = zooKeeper.getData(childPath, false, null);
System.out.println(child + " -> " + new String(data));
}
四、Watcher监听机制

Watcher是ZooKeeper的核心特性之一,允许客户端监听节点变化并接收实时通知。
4.1 Watcher的工作原理
重要特性:
4.2 可监听的事件类型
public enum EventType {
None(–1), // 连接状态变化
NodeCreated(1), // 节点被创建
NodeDeleted(2), // 节点被删除
NodeDataChanged(3), // 节点数据被修改
NodeChildrenChanged(4),// 子节点列表变化
DataWatchRemoved(5), // Watcher被移除
ChildWatchRemoved(6) // 子节点Watcher被移除
}
4.3 Watcher使用示例
public class ConfigWatcher implements Watcher {
private ZooKeeper zooKeeper;
@Override
public void process(WatchedEvent event) {
switch (event.getType()) {
case NodeDataChanged:
System.out.println("配置数据已变更:" + event.getPath());
// 读取新配置
try {
byte[] data = zooKeeper.getData(event.getPath(), this, null);
System.out.println("新配置:" + new String(data));
} catch (Exception e) {
e.printStackTrace();
}
break;
case NodeDeleted:
System.out.println("配置节点已删除");
break;
default:
break;
}
}
}
4.4 Watcher的最佳实践
五、实战应用
5.1 服务注册与发现
场景描述:
微服务架构中,服务提供者启动时将自己的地址注册到ZooKeeper,服务消费者从ZooKeeper获取服务提供者列表。
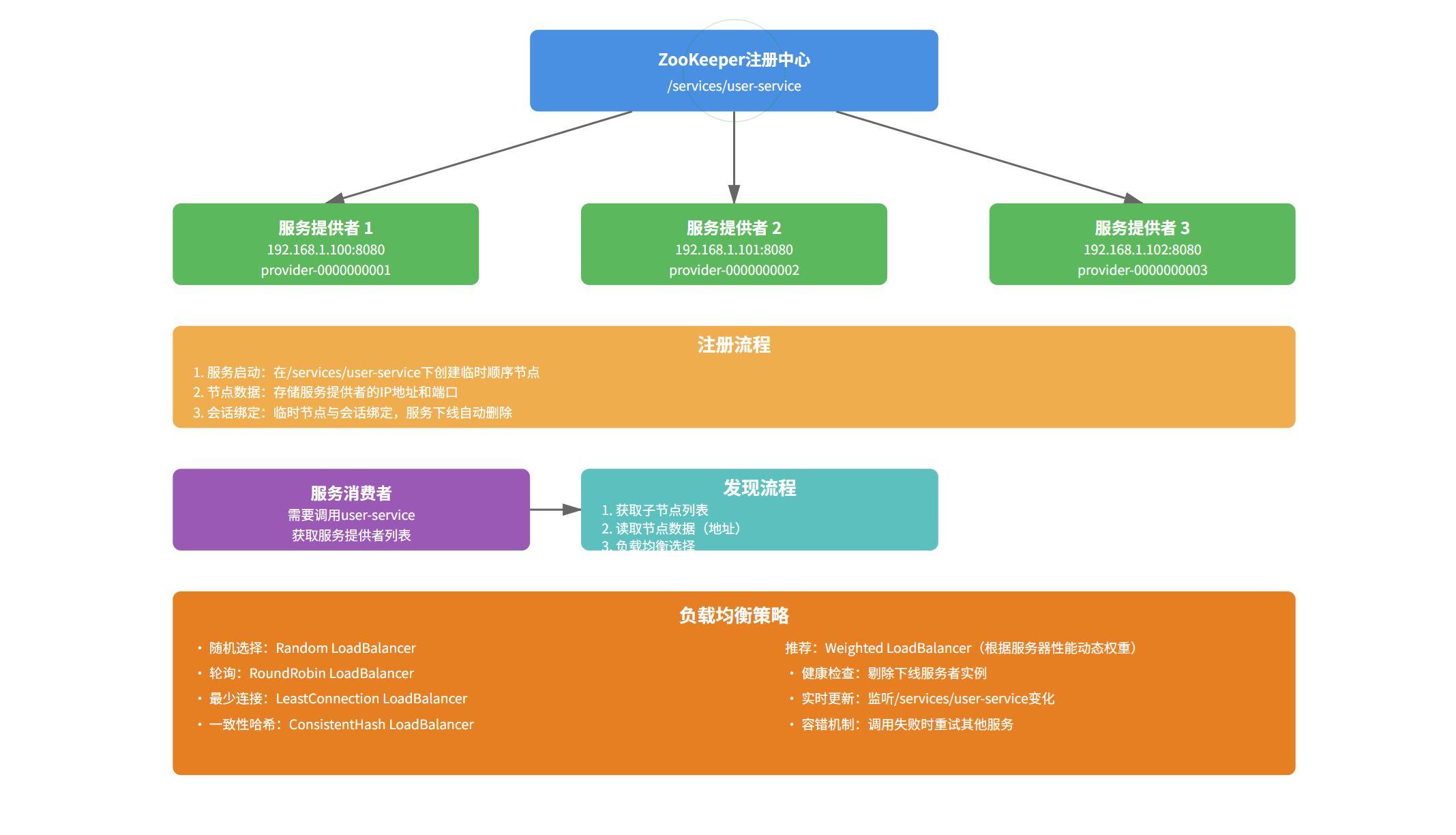
实现方案:
// 服务提供者注册
public class ServiceProvider {
private ZooKeeper zooKeeper;
private String servicePath = "/services/user-service";
public void register(String address) throws Exception {
// 创建临时节点,会话断开后自动删除
String path = zooKeeper.create(
servicePath + "/provider-",
address.getBytes(),
ZooDefs.Ids.OPEN_ACL_UNSAFE,
CreateMode.EPHEMERAL_SEQUENTIAL
);
System.out.println("服务注册成功:" + path);
}
}
// 服务消费者发现
public class ServiceConsumer {
private ZooKeeper zooKeeper;
public List<String> discover(String serviceName) throws Exception {
String path = "/services/" + serviceName;
List<String> providers = zooKeeper.getChildren(path, false);
List<String> addresses = new ArrayList<>();
for (String provider : providers) {
byte[] data = zooKeeper.getData(path + "/" + provider, false, null);
addresses.add(new String(data));
}
return addresses;
}
}
生产环境增强:
5.2 分布式配置中心
场景描述:
多个微服务实例需要共享配置,配置变更后需要实时推送到所有实例。
实现方案:
public class ConfigCenter {
private ZooKeeper zooKeeper;
private volatile ConfigData currentConfig;
public void init(String configPath) throws Exception {
// 监听配置变化
watchConfig(configPath);
// 加载初始配置
loadConfig(configPath);
}
private void watchConfig(String path) throws Exception {
zooKeeper.exists(path, event -> {
if (event.getType() == Event.EventType.NodeDataChanged) {
try {
loadConfig(path);
watchConfig(path); // 重新注册Watcher
} catch (Exception e) {
e.printStackTrace();
}
}
});
}
private void loadConfig(String path) throws Exception {
byte[] data = zooKeeper.getData(path, false, null);
ConfigData newConfig = parseConfig(data);
this.currentConfig = newConfig;
System.out.println("配置已更新:" + newConfig);
}
public ConfigData getConfig() {
return currentConfig;
}
}
配置格式示例:
{
"database": {
"url": "jdbc:mysql://localhost:3306/appdb",
"username": "admin",
"password": "password"
},
"redis": {
"host": "localhost",
"port": 6379
}
}
5.3 分布式锁
场景描述:
多个服务实例同时操作同一资源时,需要使用分布式锁保证互斥访问。
实现方案:
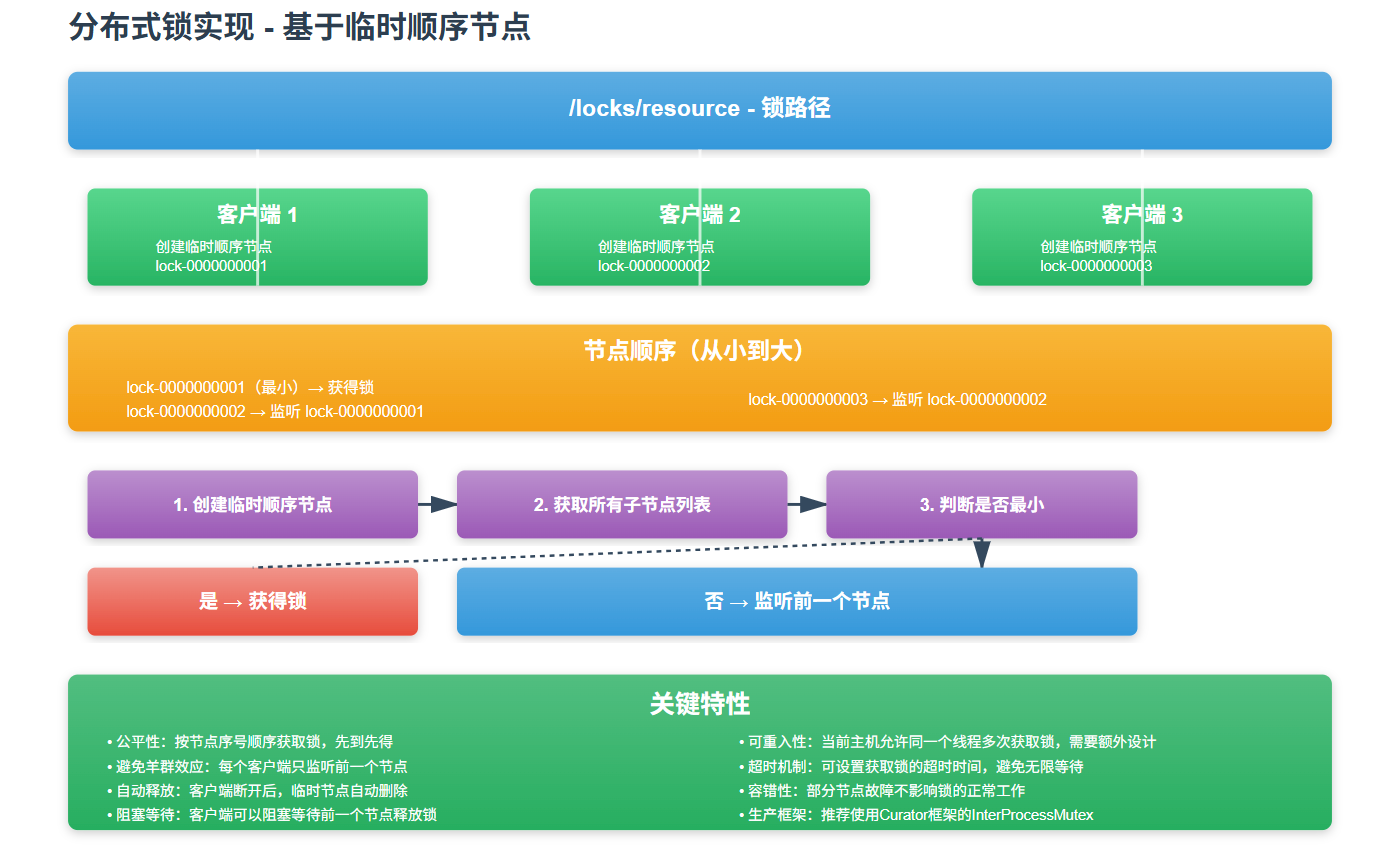
使用临时顺序节点实现公平锁:
public class DistributedLock {
private ZooKeeper zooKeeper;
private String lockPath;
private String currentLock;
public boolean lock(long timeout, TimeUnit unit) throws Exception {
// 创建临时顺序节点
currentLock = zooKeeper.create(
lockPath + "/lock-",
null,
ZooDefs.Ids.OPEN_ACL_UNSAFE,
CreateMode.EPHEMERAL_SEQUENTIAL
);
// 检查是否是最小的节点
while (true) {
List<String> locks = zooKeeper.getChildren(lockPath, false);
Collections.sort(locks);
String current = currentLock.substring(currentLock.lastIndexOf('/') + 1);
int index = locks.indexOf(current);
if (index == 0) {
return true; // 获得锁
}
// 监听前一个节点
String previousLock = locks.get(index – 1);
final CountDownLatch latch = new CountDownLatch(1);
Stat stat = zooKeeper.exists(
lockPath + "/" + previousLock,
event -> {
if (event.getType() == Event.EventType.NodeDeleted) {
latch.countDown();
}
}
);
if (stat == null) {
continue; // 前一个节点已不存在,重新检查
}
// 等待前一个节点释放
latch.await(timeout, unit);
}
}
public void unlock() throws Exception {
zooKeeper.delete(currentLock, –1);
}
}
使用示例:
DistributedLock lock = new DistributedLock(zk, "/locks/order-resource");
try {
if (lock.lock(10, TimeUnit.SECONDS)) {
// 执行业务逻辑
processOrder();
}
} finally {
lock.unlock();
}
锁的实现要点:
5.4 Leader选举
场景描述:
在集群环境中,需要从多个节点中选出一个Leader节点负责执行特定任务。

实现方案:
public class LeaderElection {
private ZooKeeper zooKeeper;
private String electionPath;
private String currentNode;
public void elect() throws Exception {
// 创建临时顺序节点
currentNode = zooKeeper.create(
electionPath + "/node_",
null,
ZooDefs.Ids.OPEN_ACL_UNSAFE,
CreateMode.EPHEMERAL_SEQUENTIAL
);
// 检查是否是Leader
checkLeader();
// 监听前一个节点
watchPreviousNode();
}
private void checkLeader() throws Exception {
List<String> nodes = zooKeeper.getChildren(electionPath, false);
Collections.sort(nodes);
String current = currentNode.substring(currentNode.lastIndexOf('/') + 1);
int index = nodes.indexOf(current);
if (index == 0) {
onBecomeLeader();
} else {
onBecomeFollower();
}
}
private void onBecomeLeader() {
System.out.println("成为Leader节点");
// 开始执行Leader任务
}
private void onBecomeFollower() {
System.out.println("成为Follower节点");
// 等待Leader变更
}
}
六、最佳实践
6.1 部署架构
集群规模:
- 开发环境:3节点(允许1个节点故障)
- 生产环境:5-7节点(允许2-3个节点故障)
- 避免使用偶数个节点
服务器配置:
- CPU:4核以上
- 内存:4GB以上
- 磁盘:使用SSD,数据目录独立
- 网络:低延迟、高带宽
6.2 配置优化
zoo.cfg关键配置:
# 基本配置
tickTime=2000 # 心跳时间间隔(毫秒)
initLimit=10 # 初始同步时限(tickTime倍数)
syncLimit=5 # 数据同步时限(tickTime倍数)
dataDir=/var/lib/zookeeper # 数据目录
clientPort=2181 # 客户端连接端口
# 集群配置
server.1=zk1:2888:3888 # 节点1配置
server.2=zk2:2888:3888 # 节点2配置
server.3=zk3:2888:3888 # 节点3配置
# 性能优化
maxClientCnxns=60 # 最大客户端连接数
autopurge.snapRetainCount=3 # 保留快照数量
autopurge.purgeInterval=1 # 清理间隔(小时)
preAllocSize=64M # 预分配事务日志大小
# 集群配置(3节点集群示例)
server.1=192.168.1.101:2888:3888
server.2=192.168.1.102:2888:3888
server.3=192.168.1.103:2888:3888
6.3 客户端配置
// 生产环境推荐的客户端配置
public ZooKeeper createProductionClient() throws IOException {
// 连接字符串:所有集群节点
String connectionString = "zk1:2181,zk2:2181,zk3:2181";
// 会话超时:根据业务场景设置
int sessionTimeout = 30000; // 30秒
// 连接超时
int connectionTimeout = 10000; // 10秒
ZooKeeper zk = new ZooKeeper(
connectionString,
sessionTimeout,
event -> handleEvent(event)
);
return zk;
}
七、总结
ZooKeeper作为分布式协调服务,在微服务、大数据、分布式系统中扮演着重要角色。主要功能点:


评论前必须登录!
注册