 网硕互联帮助中心
网硕互联帮助中心目录
DaemonSet(ds)
一、配置文件
1、举例
2、可能问题
3、验证成功
二、节点选择器
1、添加标签
2、验证添加
3、添加节点选择器
4、应用文件并验证
三、滚动更新
Horizontal Poad Autoscaler(HPA)
1、部署资源监控
Ⅰ、下载
①、官方一键 YAML
②、git克隆
③、手动下载二进制
④、拉取metrics-server 镜像
Ⅱ、验证
①、如果下载的是镜像
②、下载的是二进制
Ⅲ、我自己的做法
①、下载二进制文件
②、配置dockerfile
③、打包成镜像
编辑
④、应用在我的集群
编辑
⑤、下载官方yaml文件
⑥、编辑官方yaml文件
⑦、遇到的问题
⑧、验证
2、准备服务应用(如果你全删了的话)
3、配置HPA
编辑
4、压力测试
JOB
DaemonSet(ds)
DaemonSet确保 所有(或指定)节点 上各有一个 Pod 副本;新增节点自动补,节点下线自动删。适用于日志收集(Fluent Bit)、监控代理(node-exporter)、网络插件(Calico)、存储插件等 系统级守护进程。
一、配置文件
1、举例
以下给出一份基础的DaemonSet的yaml创建文件,并给出每一步的解释:
注意只给出基本的配置,其他配置如节点亲和、容忍度等等,如有需要,自行配置~
apiVersion: apps/v1 # DaemonSet 的API版本
kind: DaemonSet # 声明资源类型是 DaemonSet
metadata: # DaemonSet 的元信息
name: fluent # DaemonSet 的名称(自定义)
spec: # DaemonSet 规约(期望状态)
selector: # 选择器
matchLabels: # 配备标签,表示下方的 Pod 模板要有app: fluent-bit
app: fluent-bit
template: # Pod 模板
metadata: # Pod 的元信息
labels: # Pod 的标签,要和上方的匹配标签相同
app: fluent-bit
spec: # Pod 的规约(期望状态)
volumes: # 声明数据卷
– name: varlog # 数据卷名称(自定义)
hostPath:
path: /var/log # 来自宿主机的 /var/log ,是宿主机真实目录
containers: # Pod 管理的容器
– name: fluent-bit # 容器名称(自定义)
image: fluent/fluent-bit:2.1 # 容器的镜像,后面指定了版本
volumeMounts: # 使用数据卷
– name: varlog
mountPath: /var/log # 挂载到容器内的 /var/log ,是容器里访问的目录
updateStrategy: # 更新策略
type: RollingUpdate # 这里的更新策略是滚动更新,也可以设置为OnDelete
注意:DaemonSet没有replicas 的概念,守护进程的创建是根据节点创建,匹配多少节点就是多少,一个节点只有一个,没有副本数的概念,即无法自动扩容什么的
2、可能问题
还是相同的问题,可能是我自己的网络问题,手动拉取镜像是成功的,但是创建DaemonSet时仍然提示无法从docker hub拉取镜像
解决方案:将本地 Docker 镜像加载到 Kind 集群,绕过 Docker Hub 拉取,KinD 的节点本质是 Docker 容器,kind load 会将本地镜像导入到这些节点中,使 Pod 可直接使用。
kind load docker-image fluent/fluent-bit:2.1 –name <你要拉取到的集群名称>
成功后可得到类似信息:

之后通过应用yaml文件创建StatefulSet即可:
kubectl apply -f <你自己的statefulset的配置文件名称>
3、验证成功
验证使用如下方法:
# 查看已创建的 daemonset
kubectl get daemonset
# 查看已有的 Pod ,如果创建成功会多出2个
# 因为未选择部署到哪个节点,所以除了主节点外,给剩下的2个子节点都部署了
kubectl get po
最终可得到类似信息即创建成功: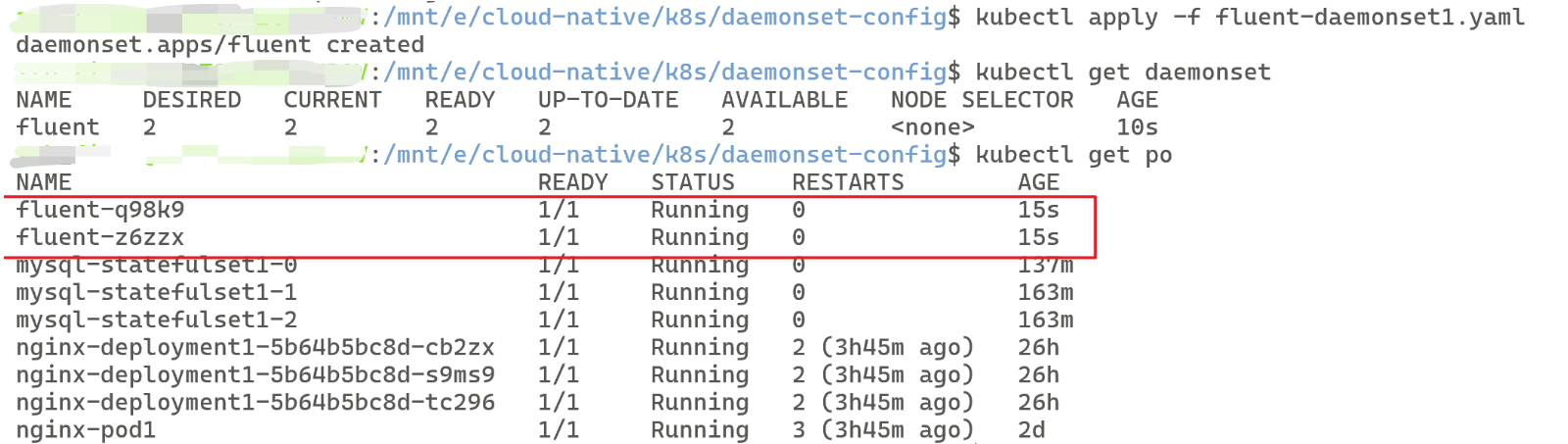
二、节点选择器
创建DaemonSet时,如果你不指定你要部署的节点,DaemonSet将会默认部署在非主节点上,而节点选择器(nodeselector)就是帮助我们指定要部署节点的工具
1、添加标签
为你想要部署的节点添加对应标签:
# 这里的no是node节点的简称
kubectl label no <要部署的节点> <要加的标签>
2、验证添加
kubectl get no –show-labels
可得到类似结果:
3、添加节点选择器
# 位于 Pod 模板的规约内,和容器同级
template:
spec:
nodeSelector: # 节点选择器
type: slave # 要匹配的节点所具有的标签
4、应用文件并验证
# 应用文件
kubectl apply -f <你自己的daemonset文件>
# 获取daemonset,ds是daemonset的简写
kubectl get ds
# 查看 Pod ,看daemonset创建了多少容器
kubectl get po
对比如图:(我将应用配置文件前后均截屏,大家可对比看一下)

由于我只给一个子节点加了标签,所以部署了DaemonSet的节点只有加了type= slave 的,另一个没有加的就没有署DaemonSet,要想让另一个节点也加上守护进程,只要也加上标签type= slave即可
三、滚动更新
DaemonSet的滚动更新默认是RollingUpdate,也有OnDelete,Pod 模板任何字段(env、volume、资源限制、标签等)发生变化, DaemonSet就会进行更新
下方是对Deployment、StatefulSet、DaemonSet的滚动更新策略对比总结
| Deployment | RollingUpdate(默认)、Recreate | ✅(maxSurge+maxUnavailable) | ✅(partition 通过 Argo/Kruise 等旁路实现) | ✅(kubectl rollout pause/resume) | ✅(kubectl rollout undo) | 无序并行,可批量 |
| StatefulSet | RollingUpdate(默认)、OnDelete | ❌(一次只动一个 Pod) | ✅(原生 partition 字段) | ❌(无官方暂停) | ✅(kubectl rollout undo) | 逆序(从最高序号开始) |
| DaemonSet | RollingUpdate(默认)、OnDelete | ✅(maxUnavailable 节点级并发) | ✅(OpenKruise partition 或手工分批) | ❌(无官方暂停) | ✅(kubectl rollout undo) | 按节点滚动,一节点一 Pod |
亲和力、污点容忍在后面的学习中展开
Horizontal Poad Autoscaler(HPA)
Horizontal Pod Autoscaler(HPA)是 Kubernetes 官方提供的 水平 Pod 自动扩缩容控制器,可以根据 CPU、内存或自定义指标实时调整 Deployment / StatefulSet / ReplicaSet 的 Pod 副本数,业务高峰自动加副本,低谷自动减副本,无需人工干预。
其实Horizontal Pod Autoscaler(HPA)就是通过追踪分析Pod的负载变化,来自动调整Pod的副本数。我们原来是通过kubectl scale来扩容缩容或者是改变yaml文件,这比较麻烦,通过HPA就可以让其自动扩容缩容
1、部署资源监控
HPA要想实现自动水平 Pod 自动扩缩容,其前提是要对你的Pod的负载进行监控分析,所以我们需要一个插件帮助我们正确分析监控,这里我采用常用的metrics-server。
metrics-server 默认由 Kubernetes 官方 以 Deployment + Service 的形式部署在 kube-system 命名空间,并作为 kube-controller-manager 的 Metrics API 插件 运行
Ⅰ、下载
下载有多种方法,这里我提供四种:
①、官方一键 YAML
# 下载并直接安装最新版
kubectl apply -f https://github.com/kubernetes-sigs/metrics-server/releases/latest/download/components.yaml
# 等 30-60 秒
kubectl get pods -n kube-system -l k8s-app=metrics-server
②、git克隆
# 安装git(如果你没有安装过的话)
yum install git -y
# 获取metrics-server
git clone -b <你要下载的版本号> https://github.com/kubernetes-sigs/metrics-server
# 修改配置
# 进入metrics-server的deploy文件夹,找到你的deployment的yaml文件
# 添加如下内容
hostNetwork: true
registry.cn-hangzhou.aliyuncs.com/google_containers/metrics-server:<你要下载的版本号>
–kubelet-insecure-tls
–kubelet-preferred-address-types=InternalIP
# 根据集群版本进入对应子目录
cd deploy/kubernetes
kubectl apply -f .
③、手动下载二进制
进入github的metrics-server下载网址https://github.com/kubernetes-sigs/metrics-server/releases,选择你要下载的版本,指定路径到本地后再kubectl apply -f <你的文件名>

④、拉取metrics-server 镜像
# 最新版 v0.8.0
docker pull registry.k8s.io/metrics-server/metrics-server:v0.8.0
# 镜像架构:linux/amd64,大小 ≈ 82 MB [^124^]
镜像已内置 /metrics-server 可执行文件,无需再下载二进制
Ⅱ、验证
①、如果下载的是镜像
# 查看docker里的使用镜像即可
docker images
②、下载的是二进制
ls -lh ./metrics-server
file ./metrics-server
# 输出类似结果
-rwxr-xr-x 1 root root 35M Jun 14 12:34 ./metrics-server
./metrics-server: ELF 64-bit LSB executable, x86-64, …
注意下载完二进制文件后,建议把它打包成镜像,当然你也可以直接跑,如果只是单片测试的话
Ⅲ、我自己的做法
①、下载二进制文件
将下载的二进制文件放在"E:\\cloud-native\\k8s\\metrics-server\\metrics-server-linux-amd64"
②、配置dockerfile
在和二进制文件同目录下编写dockerfile:
FROM scratch
COPY metrics-server-linux-amd64 /metrics-server
USER 65534
EXPOSE 4443
ENTRYPOINT ["/metrics-server"]
③、打包成镜像
docker build -t metrics-server:v0.8.0
# 验证
docker images
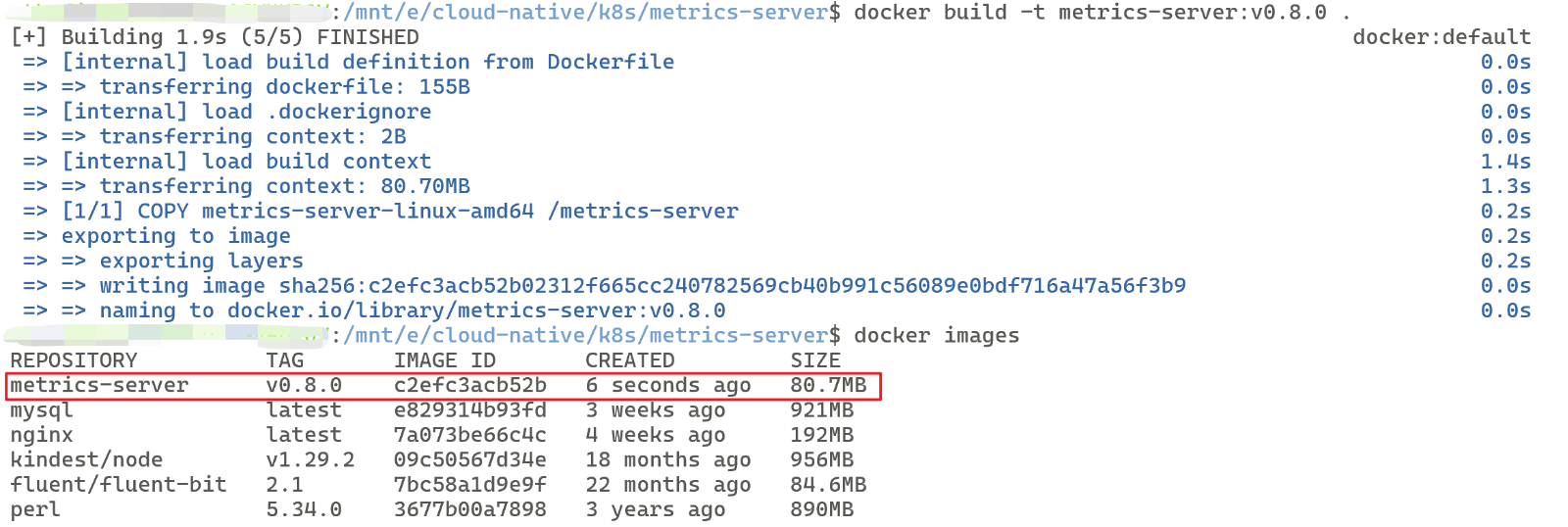
④、应用在我的集群
kind load docker-image metrics-server:v0.8.0 –name my-multi-node-cluster1

⑤、下载官方yaml文件
wget https://github.com/kubernetes-sigs/metrics-server/releases/download/v0.8.0/components.yaml
⑥、编辑官方yaml文件
# 将官方yaml文件中的镜像改为:
image: metrics-server:v0.8.0
# 在spec.template.spec.containers[0].args内改为:
kubectl -n kube-system patch deployment metrics-server \\
–type='json' \\
-p='[
{"op":"add","path":"/spec/template/spec/containers/0/args/-","value":"–kubelet-insecure-tls"},
{"op":"add","path":"/spec/template/spec/containers/0/args/-","value":"–kubelet-preferred-address-types=InternalIP,Hostname,InternalDNS,ExternalDNS,ExternalIP"}
]'
⑦、遇到的问题
-
健康检查失败,探针配置可能未被正确应用,端口未对齐
# 解决方法
apiVersion: v1
kind: Service
spec:
ports:
– port: 443
targetPort: 4443 # 指向容器实际端口
name: https
readinessProbe:
httpGet:
path: /readyz
port: 4443 # 直接写数字,与 –secure-port 一致
scheme: HTTPS
livenessProbe:
httpGet:
path: /livez
port: 4443 # 同上
scheme: HTTPS
-
它 连不上任何节点的 kubelet 10250 端口,导致采集不到节点/容器指标,readiness 探针返回 500
-
metrics-server 在 Pod 网络里拿到的节点 IP(如 10.244.x.x)不是节点宿主机的真实 IP;
-
-
Kind 节点里的 kubelet 默认只监听 127.0.0.1:10250,外部 Pod 无法访问。
# 让 metrics-server 使用宿主机网络(这样它就能连 127.0.0.1:10250)
kubectl -n kube-system patch deployment metrics-server \\
–type='json' \\
-p='[{"op":"add","path":"/spec/template/spec/hostNetwork","value":true}]'
⑧、验证

2、准备服务应用(如果你全删了的话)
配置一个有资源限制的Deployment,这里我不演示了,详情配置可以看我的k8sday06深入控制器(1/3)
3、配置HPA
apiVersion: autoscaling/v2 # 自动缩放器的 API 版本
kind: HorizontalPodAutoscaler # 声明资源类型是 HPA
metadata: # 元数据
name: web-hpa # 自动缩放器的名称(自定义)
spec: # 自动缩放器的规约(期望状态)
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment # 被自动缩放的资源类型
name: nginx-deployment1 # 被自动缩放的资源名称(已存在的)
minReplicas: 1 # 最小副本数
maxReplicas: 5 # 最大副本数
# targetCPUUtilizationPercentage已经废除,需要使用 metrics 指标
# 目标 CPU 利用率(%)指标(设置的比较小方便测试)
metrics:
– type: Resource
resource:
name: cpu # 资源名称(自定义)
target:
type: Utilization
averageUtilization: 3 # 目标 CPU 利用率(%)指标(设置的比较小方便测试)
注意你的deployment要有资源限制
验证成功:
kubectl get hpa
# 刚开始可能在你的TARGETS那里显示是 <unknown>/3%
# 过一会就1%/3% 正常了(不到 1min),如果时间久了还是<unknown>/3%
# 可能是你的deployment没有限制资源等等

4、压力测试
由于不知是不是我的网络问题,在配置高并发Deployment测压时,明明本地有镜像就是死活不用,即使我已经使用镜像摘要来要求,就是用不了,所以没办法做压力测试了,大家可以自行配置,这里我给出我的使用nginx镜像的高并发Deployment配置文件,大家可以直接使用,按理来说应该是没有什么大问题的:
# 高并发Deployment测压
apiVersion: apps/v1
kind: Deployment
metadata:
name: siege-deploy
spec:
replicas: 5 # 并发 Pod 数
selector:
matchLabels:
app: siege
template:
metadata:
labels:
app: siege
spec:
containers:
– name: siege
# 注意这里的镜像,要填你自己的镜像版本
image: nginx@sha256:6c0218f1687660914d2ce279489e9b6d62a5a48d06ab2e27b7710c19d5e904e5
# 使用镜像的 sha256 摘要
imagePullPolicy: IfNotPresent # 确保显式设置
command:
– /bin/sh
– -c
– |
while true; do
# 每个 shell 里开 50 条后台并发 curl
for i in $(seq 50); do
curl -s http://nginx-deployment.default.svc.cluster.local &
done
wait # 等这一轮 50 个请求完成,再下一轮
done
# 当然你的command命令也可以通过写死循环什么的来提高压力,或用什么专业的测压软件都是可以的
JOB
用于运行一次性任务,例如批量处理任务或数据迁移任务。它会创建一个或多个 Pod 来完成任务,并在任务完成后Pod自动清理。
给出一个用于计算圆周率的任务的yaml配置文件:
apiVersion: batch/v1 # Job 属于 batch 组
kind: Job # 声明资源类型是 Job 类型
metadata: # 元数据
name: pi-job # Job 名称,可自定义
namespace: default # 所在命名空间
spec: # Job 的期望状态
suspend: false # 1.21+:true=暂停调度,默认 false
completions: 4 # 需要成功完成的 Pod 数为4个
parallelism: 2 # 并发运行的 Pod 数为2个,即一次性运行2个 Pod
backoffLimit: 4 # 最大重试次数(失败后不再创建)
activeDeadlineSeconds: 100 # Job 运行期限:100s ,超过时间未结束自动失败
manualSelector: true # 是否使用selector选择器,默认 false
selector: # 选择器,用于手动选择 Pod 标签
matchLabels: # 下方应有 app: pi 标签
app: pi
ttlSecondsAfterFinished: 100 # 完成后 100s 自动清理(需开启 TTL 特性)
template: # Pod 模板(与 Pod spec 结构一致)
metadata: # Pod 的元信息
labels: # Pod 的标签,要和上方的匹配标签相同
app: pi
spec:
restartPolicy: Never # Job 只能 Never 或 OnFailure
#因为 Job 执行的是一次性任务,所以不需要 Always 重启策略
containers:
– name: pi-container # 容器名称,可自定义
image: perl:5.34.0 # 容器镜像
# 容器命令 计算 π 到 20 位
command: ["perl", "-Mbignum=bpi", "-wle", "print bpi(20)"]
resources: # 资源请求和限制
requests: # 最少资源请求
cpu: 100m # 容器请求 100毫核 CPU资源
memory: 128Mi # 容器请求 128Mi 内存
创建完成后,创建Job即可,可以使用-w实时监控(当然我忘了~),可以看到类似画面:

可以看到是一次性运行2个Pod,运行完之后过一会这些Job都会自动清理,如图:
CronJob类似,只不过CronJob是管理Job的,这里就不演示了
由于不知是不是我的网络问题,导致我的镜像拉取每次都只能通过手动拉取然后导入集群,比较麻烦,而且有的时候甚至导入了集群也无法使用,我有点苦恼TVT
所以最终我决定,直接从kind的集群配置文件出发,将原来的集群删除,重新创建集群,重新配置一遍,看看能不能解决我的问题,当然,有大佬教教我怎么解决就更好了QAQ





评论前必须登录!
注册