 网硕互联帮助中心
网硕互联帮助中心概叙
科普文:软件架构数据库系列之【五大 MVCC 核心组件总览:MySQL MVCC实现原理】-CSDN博客
科普文:软件架构数据库系列之【可见性判断函数 changes_visible:源码解读MySQL MVCC实现原理】-CSDN博客
科普文:软件架构数据库系列之【MVCC:MySQL数据库,单独一个session中的select语句是否会开启事务?】-CSDN博客

undo日志和版本链并不直接构成Read View,但它们共同在InnoDB的MVCC机制中实现了数据的版本管理和可见性判断。
undo日志和版本链共同记录了数据的历史版本,并通过roll_pointer指针将这些版本连接起来。而Read View则用于在执行查询操作时判断数据版本的可见性。
这三者协同工作,实现了InnoDB的MVCC机制,从而提高了数据库的并发性能和一致性。
下面是对这三者如何协同工作的详细解释:
1. undo日志的作用
undo日志是MySQL InnoDB引擎用于记录数据修改前的状态(旧值)的日志。当事务执行失败或需要回滚时,undo日志提供了恢复数据一致性的手段。此外,undo日志还是实现MVCC机制的关键组成部分,因为它保存了数据的历史版本,使得其他事务在读取数据时可以通过undo日志获取旧版本数据,从而避免读写冲突。
2. 版本链的构成
版本链是由undo日志通过roll_pointer指针连接形成的一个单向链表。每当一行数据被修改时,InnoDB会保留修改前的数据到undo日志中,并通过roll_pointer指针将新版本的记录与旧版本的undo日志连接起来。这样,就形成了一个包含数据所有历史版本的版本链。版本链的链首是最新版本的数据记录,而链尾则是数据最初的状态或某个较早的版本。
3. Read View如何判断数据版本的可见性
Read View是InnoDB在执行快照读操作时生成的一个一致性视图。它记录了当前系统中所有活跃事务的事务ID(即未提交的事务ID),以及一个最小活跃事务ID(min_trx_id)和一个表示下一个待分配事务ID的值(max_trx_id)。
当事务执行查询操作时,InnoDB会根据Read View和版本链来判断数据版本的可见性。具体规则如下:
- 如果数据版本的trx_id(即修改该版本数据的事务ID)小于Read View中的min_trx_id,表示这个数据版本是在当前事务开启之前就已经提交的事务生成的,因此对当前事务可见。
- 如果数据版本的trx_id大于或等于Read View中的max_trx_id,表示这个数据版本是由将来启动的事务生成的,因此对当前事务不可见(但如果数据版本的trx_id恰好是当前事务自己的ID,则可见)。
- 如果数据版本的trx_id在Read View的min_trx_id和max_trx_id之间,则需要进一步判断。如果trx_id在Read View的活跃事务ID列表(m_ids)中,表示生成该数据版本的事务仍然活跃(未提交),因此该数据版本对当前事务不可见。如果trx_id不在m_ids中,则表示生成该数据版本的事务已经提交,因此该数据版本对当前事务可见。
三者之间的关系:MySQL MVCC实现原理
| undo 日志 | 存储数据修改前的旧值,是版本链中历史版本的物理载体 | 为版本链提供每个历史版本的具体数据内容;通过 DB_ROLL_PTR 被串联成链式结构 |
| 版本链 | 通过 DB_ROLL_PTR 将当前行与多个 undo 日志关联,形成按时间倒序的历史版本链 | 依赖 undo 日志存储历史数据;为 Read View 提供可回溯的多个版本供可见性判断 |
| Read View | 定义当前事务的可见事务范围与规则(如哪些事务ID提交的版本可见) | 基于版本链中的 DB_TRX_ID 和 undo 日志中的历史版本,判断具体哪个版本对当前事务可见 |
- 关联纽带:DB_ROLL_PTR是连接当前行数据与其历史版本undo日志的“指针”,通过单向链表结构形成版本链。
- 版本链方向:链首是当前最新版本(数据行本身),链尾是最早的历史版本(最久远的undo日志);每次更新操作会生成新undo日志,并将DB_ROLL_PTR指向新日志。
- MVCC依赖:事务通过Read View判断当前版本是否可见,不可见时沿DB_ROLL_PTR回溯版本链,找到满足隔离级别要求的历史版本数据(如REPEATABLE READ下读取事务开始时的快照版本)。
- Undo日志作用:不仅用于事务回滚,更是MVCC多版本数据的物理存储载体,通过版本链实现不同事务读取不同时间点的数据状态。
简言之,InnoDB通过DB_ROLL_PTR将每行数据的当前版本与历史undo日志串联成版本链,再结合Read View的可见性判断逻辑,实现MVCC的多版本数据隔离与访问。
一、核心组件定义
1. undo 日志(Update Undo Log)
- 作用:记录数据行修改前的旧值(如 UPDATE/DELETE 操作前的字段值),用于支持事务回滚和 MVCC 历史版本数据获取。
- 存储位置:写入 undo 页(独立于数据页的存储区域),包含被修改行的原始数据内容及关联的事务信息。
- 类型:仅 Update Undo Log(用于 MVCC 和回滚),Insert Undo Log(仅用于回滚,事务提交后可删除)。
-
1. DB_ROLL_PTR(回滚指针)
- 是InnoDB每行数据记录(聚簇索引页内)的隐藏字段之一,类型为指针(通常存储undo页的偏移地址或页内位置信息)。
- 作用:指向该行最近一次修改(INSERT/UPDATE)所生成的undo日志记录,是串联历史版本的关键“链条”。
-
2. Undo日志(Update Undo Log)
- 当事务对某行数据执行UPDATE或DELETE操作时,InnoDB 不会直接覆盖原数据,而是将修改前的旧值(即被更新字段的原内容)写入undo日志(存于undo页中)。
- 该undo日志记录了数据修改前的完整状态(或部分关键字段),用于支持事务回滚(回退到修改前状态)和MVCC(提供历史版本数据)。
2. 版本链(Version Chain)
- 作用:通过 DB_ROLL_PTR(回滚指针)将同一行数据的不同历史版本(包括当前版本)串联成单向链表,实现按时间倒序的历史版本追溯。
- 结构:链首是当前最新版本的数据行(存储于数据页),链中每个节点通过 DB_ROLL_PTR 指向下一个更早的 undo 日志记录(即上一版本的数据),最终形成“当前行→undo 日志1→undo 日志2→…”的链式结构。
3. Read View(读视图)
- 作用:定义当前事务的可见事务范围与数据版本规则,是判断某行数据版本是否对当前事务可见的逻辑依据。
- 关键字段:
- creator_trx_id(创建该视图的事务ID)、up_limit_id(最小可见事务ID)、low_limit_id(最大不可见事务ID)、trx_ids[](创建视图时仍活跃的未提交事务ID集合)。
- 生命周期:在事务首次执行 SELECT 时创建(REPEATABLE READ 隔离级别下复用,READ COMMITTED 下可能每次新建)。
二、三者的关联流程
1. 数据修改与版本链构建(通过 undo 日志)
- 当事务对某行数据执行 UPDATE 或 DELETE 时:
① InnoDB 不会直接覆盖原数据,而是先将当前行的原始数据(即修改前的值)写入 undo 日志(生成一条 Update Undo Log 记录);
② 更新数据页中的当前行内容(新值),并修改该行的 DB_TRX_ID(事务ID)为当前事务ID;
③ 将当前行的 DB_ROLL_PTR 指针指向刚写入的 undo 日志记录(即该行的第一个历史版本)。
- 若同一行数据被 多次更新(如事务 T1 更新后,事务 T2 再次更新):每次更新都会生成新的 undo 日志(记录当前版本的旧值),并将 DB_ROLL_PTR 指向最新的 undo 日志,形成 “当前行→最新 undo 日志→次新 undo 日志→…” 的单向版本链(链首是当前最新版本,链尾是最早版本)。
2. 事务读取数据时通过 Read View 判断可见性
- 当事务 T 执行 SELECT 查询时:
① InnoDB 会先获取当前事务的 Read View(根据隔离级别决定是否复用已有视图);
② 从数据页中读取目标行的 当前版本(即最新数据行),检查其 DB_TRX_ID(最后修改事务ID)是否对当前事务可见(通过 changes_visible 函数,结合 Read View 的 up_limit_id、low_limit_id 和 trx_ids[] 判断);
- 若可见(如 DB_TRX_ID 属于已提交事务且在允许范围内),直接返回该版本数据;
- 若不可见(如 DB_TRX_ID 是未提交事务或晚于当前视图的事务),则需要通过版本链回溯。
3. 版本链回溯与历史版本可见性判断
- 若当前版本不可见,InnoDB 会根据当前行的 DB_ROLL_PTR 指针,定位到对应的 undo 日志记录(即上一历史版本的数据),从中提取该版本的完整数据内容,并检查该版本的 DB_TRX_ID(记录在 undo 日志或关联信息中)是否对当前事务可见:
- 若可见(如该历史版本的 DB_TRX_ID 已提交且符合 Read View 规则),返回该历史版本数据;
- 若仍不可见,继续通过该历史版本记录中的 DB_ROLL_PTR 指针,回溯到更早的 undo 日志,重复判断过程,直到找到可见版本或遍历完所有历史版本(最终返回空或报错)。
三、版本链的构建过程(以UPDATE为例)
1. 初始插入(INSERT):新插入的行数据会记录当前事务的DB_TRX_ID(事务ID),但此时无历史版本,DB_ROLL_PTR通常为NULL(或指向无效位置)。
2. 首次更新(UPDATE):事务T1修改某行数据时,InnoDB会:
① 将该行修改前的旧值(即更新前的完整行或关键字段)写入undo日志(生成一条Update Undo Log记录);
② 更新当前行的数据内容(新值);
③ 将当前行的DB_TRX_ID更新为T1的事务ID;
④ 将DB_ROLL_PTR指向刚刚写入的undo日志记录(即该行的第一个历史版本)。
3. 后续更新(多次UPDATE)
- 当同一行数据被事务T2再次更新时,InnoDB会:
① 将当前行(即T1修改后的版本)的当前数据(旧值)写入新的undo日志;
② 更新当前行的数据内容(T2修改的新值);
③ 保持DB_TRX_ID为T2的事务ID;
④ 将DB_ROLL_PTR指向新写入的undo日志记录(覆盖之前的指针)。
- 最终效果:DB_ROLL_PTR形成一个单向链表,链首是当前最新版本的数据行,链中每个节点(undo日志)依次记录了该行更早的历史版本(按更新时间倒序排列)。
四、版本链的构建过程(详细示例)
1.基本数据结构
InnoDB每行记录都包含3个隐藏字段:
- DB_TRX_ID(6字节):最近修改该行的事务ID
- DB_ROLL_PTR(7字节):回滚指针,指向undo日志记录
- DB_ROW_ID(6字节):行ID(隐藏主键)
undo日志类型
- INSERT undo log:仅在事务回滚时需要,提交后可直接丢弃
- UPDATE undo log:用于MVCC和事务回滚,需要持久化
2. 版本链的形成过程
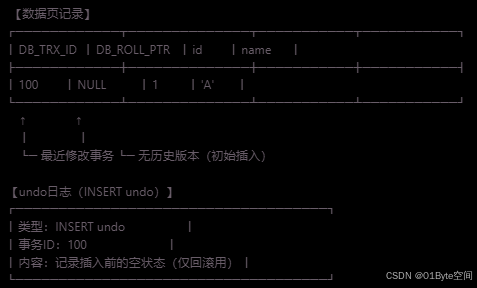
2.1 初始插入(事务ID=100)
— 事务ID=100插入一行
INSERT INTO t VALUES(1, 'A');
- 数据页中的记录:
[DB_TRX_ID=100, DB_ROLL_PTR=null, 1, 'A']
- undo日志:记录插入前的空状态(用于回滚)
2.2 第一次更新(事务ID=200)
— 事务ID=200更新该行
UPDATE t SET name='B' WHERE id=1;

2.3 第二次更新(事务ID=300)
— 事务ID=300再次更新
UPDATE t SET name='C' WHERE id=1;

3.MVCC可见性判断流程图(事务ID=250读取时)
3.1 前提:
- 当前活跃事务ID范围:假设无其他活跃事务,事务250开始时,已提交事务ID≤200,未提交事务ID=300(正在更新)。
- 数据页当前版本:DB_TRX_ID=300(未提交),版本链为 300→200→100。
当某个事务(如ID=250)读取该行时:
- RC:取最新已提交版本
- RR:取事务开始时已提交的最新版本
- 300>250不可见
- 200<250且已提交→返回'B'
- (如果200未提交则继续找100)

3.2 关键实现细节
版本链组织:
- 通过DB_ROLL_PTR形成单向链表,最新修改在链首
- 每个undo记录包含前一个版本的DB_TRX_ID和DB_ROLL_PTR
undo日志持久化:
- 存储在系统表空间的回滚段(rollback segment)中
- update undo日志在事务提交后不会立即删除,要确保MVCC能读到
purge机制:
- 后台线程定期清理不再需要的undo日志
- 当没有活跃事务需要访问旧版本时,对应的undo日志可被清除
二级索引处理:
- 二级索引不直接存储版本信息
- 通过主键回表查询时再应用MVCC规则
3.3不同操作的影响
DELETE操作:
- 标记删除记录,创建delete mark undo日志
- 只有在purge线程真正清理时才物理删除
UPDATE操作导致列变化:
- 如果新行不能放在原位置(如变长列增大)
- 采用"delete mark + insert"方式,产生两条undo记录
这种机制使得InnoDB能够:
- 实现非锁定读(快照读)
- 支持事务回滚
- 保证不同隔离级别下的可见性规则
- 高效处理并发读写冲突
4.MySQL MVCC机制代码示例
MVCC(多版本并发控制)是InnoDB存储引擎的核心特性,下面我将通过几个代码示例来展示MVCC的工作原理。
4.1 基本MVCC行为示例
— 创建测试表
CREATE TABLE mvcc_test (
id INT PRIMARY KEY,
data VARCHAR(100),
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP
) ENGINE=InnoDB;
— 插入初始数据
INSERT INTO mvcc_test (id, data) VALUES (1, 'Initial Data');
— 事务1 – 读取数据(快照读)
START TRANSACTION;
SELECT * FROM mvcc_test WHERE id = 1; — 会看到'Initial Data'
— 此时不提交,保持事务打开
— 在另一个会话中执行:
— 事务2 – 更新数据
START TRANSACTION;
UPDATE mvcc_test SET data = 'Updated Data' WHERE id = 1;
SELECT * FROM mvcc_test WHERE id = 1; — 会看到'Updated Data'
COMMIT;
— 回到事务1 – 再次读取(仍然看到旧版本)
SELECT * FROM mvcc_test WHERE id = 1; — 仍然看到'Initial Data'
COMMIT;
4.2 显示事务ID和版本信息的示例
— 启用事务ID显示(需要MySQL 8.0+)
SET SESSION innodb_status_output_locks=ON;
SET SESSION innodb_status_output=ON;
— 查看事务和锁信息
SHOW ENGINE INNODB STATUS;
— 创建带有事务ID跟踪的表
CREATE TABLE mvcc_with_tx (
id INT PRIMARY KEY,
data VARCHAR(100),
tx_id BIGINT UNSIGNED,
start_time TIMESTAMP,
end_time TIMESTAMP
) ENGINE=InnoDB;
— 创建触发器来跟踪事务
DELIMITER //
CREATE TRIGGER before_mvcc_with_tx_insert
BEFORE INSERT ON mvcc_with_tx
FOR EACH ROW
BEGIN
SET NEW.tx_id = (SELECT txn_id FROM information_schema.innodb_trx
ORDER BY txn_started DESC LIMIT 1);
SET NEW.start_time = NOW();
END//
DELIMITER ;
— 测试事务ID跟踪
START TRANSACTION;
INSERT INTO mvcc_with_tx (id, data) VALUES (1, 'Test Data');
COMMIT;
4.3 MVCC与隔离级别示例
— 设置不同的隔离级别并观察MVCC行为
— READ COMMITTED 示例
SET SESSION TRANSACTION ISOLATION LEVEL READ COMMITTED;
START TRANSACTION;
SELECT * FROM mvcc_test WHERE id = 1; — 会看到已提交的更改
COMMIT;
— REPEATABLE READ 示例(MySQL默认)
SET SESSION TRANSACTION ISOLATION LEVEL REPEATABLE READ;
START TRANSACTION;
SELECT * FROM mvcc_test WHERE id = 1; — 会看到事务开始时的快照
— 在另一个会话中更新数据并提交
— 再次查询仍然看到旧数据
SELECT * FROM mvcc_test WHERE id = 1;
COMMIT;
4.4 模拟MVCC版本链的简化实现(伪代码)
# 简化的MVCC版本链模拟
class MVCCRow:
def __init__(self, data, tx_id, is_deleted=False):
self.data = data
self.tx_id = tx_id # 创建该版本的事务ID
self.is_deleted = is_deleted
self.next = None # 指向下一个版本
class MVCCTable:
def __init__(self):
self.head = None
self.current_tx_id = 0
def begin_transaction(self):
self.current_tx_id += 1
return self.current_tx_id
def insert(self, data, tx_id):
new_row = MVCCRow(data, tx_id)
new_row.next = self.head
self.head = new_row
def update(self, data, tx_id, visible_tx_id):
# 找到当前事务可见的最新版本
current = self.head
while current and current.tx_id > visible_tx_id:
current = current.next
if current:
new_row = MVCCRow(data, tx_id)
new_row.next = current.next
current.next = new_row
def select(self, tx_id):
current = self.head
result = []
while current:
if current.tx_id <= tx_id and not current.is_deleted:
result.append((current.data, current.tx_id))
current = current.next
return result
# 使用示例
table = MVCCTable()
tx1 = table.begin_transaction()
table.insert("Initial Data", tx1)
tx2 = table.begin_transaction()
table.update("Updated Data", tx2, tx1)
print(table.select(tx1)) # 看到初始数据
print(table.select(tx2)) # 看到更新后的数据
备注:这些示例展示了MVCC在不同场景下的行为。在实际的MySQL实现中,这些机制要复杂得多,但基本原理是相同的:通过维护数据的多个版本来实现高并发性能,同时保持数据一致性。




评论前必须登录!
注册