 网硕互联帮助中心
网硕互联帮助中心C++后端开发中的缓存技术
缓存技术的运用对于高性能网络应用的运行至关重要。 它作为存储中间状态数据的组件,能够显著加快后续相同数据请求的响应速度。 缓存中保存的数据既可以是其他位置存储数据的副本,也可以是先前计算的结果。 通过缓存技术,您可以将频繁访问的数据或文件以比传统直接访问方式快得多的速度进行存储和检索。
在客户端与服务器之间添加缓存中间层能有效提升系统性能。 这在服务器端编程中尤为有益,既能减轻服务器负载,缩短 Web 应用响应时间,又能全面提升用户体验质量。
在服务器端编程中,缓存技术有多种不同的应用方式。 服务器端缓存可以包括存储高开销数据库查询结果、整张网页内容,甚至是 API 响应数据。 举例来说,服务器端缓存可能涉及网页存储。 基本上,任何被频繁请求、生成耗时较长且访问量大的内容都适合采用缓存。
缓存是 C++后端开发中的关键组件,对于提升应用程序速度和性能至关重要。 现代 C++应用尤其是后端网络服务,通常需要快速响应和低延迟。 缓存技术能显著改善响应时间,减轻数据库负载,最终提供更流畅、更快速的用户体验。 无论是处理每秒高并发请求还是执行复杂运算,这一优势都同样适用。
本章将深入探讨缓存技术的方方面面。 我们将讨论缓存在后端开发中的重要性、各种缓存类型,以及在 C++环境中实现缓存所需的步骤。 同时也会分析缓存决策带来的影响,特别是这些决策如何影响后端服务的性能和扩展性。
服务器端缓存策略
根据后端服务的需求,您可以利用多种不同类型的缓存。 本节我们将探讨四种类型:内存缓存、数据库缓存、CDN 和 HTTP 缓存。
图7.1 服务器端缓存策略类型
内存缓存
内存缓存是一种将数据存储在服务器内存中以实现快速访问的方法。 它特别适用于频繁读取但较少更新的数据。 最知名且广泛使用的内存缓存系统是 Redis,不过 Memcached 等其他系统也常被使用。 由于内存访问速度远快于磁盘访问,内存缓存能显著降低数据检索延迟。 它通常用于缓存复杂计算结果、数据库调用结果和会话数据。
例如,在 C++后端中,您可能使用内存缓存来存储用户会话数据。 由于这些数据经常被访问但很少变化,将其存储在内存中可使应用程序响应更迅速。
数据库缓存
数据库缓存是指缓存对数据库查询的结果。 由于数据库常常会成为性能瓶颈,特别是在处理复杂查询或大型数据集时,缓存数据库结果可以显著提升后端系统的性能。
例如,如果你的 C++后端正在执行复杂的 SQL 查询来获取博客文章,缓存这些查询结果能使应用程序性能更优。 下次需要相同数据时,可以直接从缓存中获取,而无需再次执行相同的 SQL 查询。
内容分发网络(CDN)缓存
CDN 是一种将数据存储在网络边缘的缓存类型。 这种缓存特别适用于不经常变化的静态内容,如图片、CSS 和 JavaScript 文件。 通过将这些内容存储在更接近访问用户的位置,CDN 能显著降低延迟并提升应用程序性能。
在 C++后端环境中,可以使用 CDN 来托管 Web 应用的静态资源。 例如,可以将博客文章中的图片存储在 CDN 上,确保无论用户位于何处都能快速可靠地访问。
HTTP 缓存
HTTP 缓存是指存储 HTTP 请求内容以供后续响应重复使用。 这可以通过多种 HTTP 头来实现,这些头信息控制着缓存的方式、时机和持续时间。 这是一种缓存网页资源的有效方法,能减轻服务器负载并提高响应速度。
可以在 C++后端中利用 HTTP 缓存来缓存特定 API 端点的响应。 例如,如果有一个获取所有博客文章列表的端点,可以缓存该响应,使后续请求的响应速度更快。
这些不同的数据缓存技术各具优势,可应用于多种场景。 选择缓存方法时,应用程序的具体需求、处理的数据类型以及期望实现的性能优化目标通常是重要考量因素。 通过有效运用这些缓存技术,您能显著提升 C++后端服务的性能表现、响应速度以及所提供的用户体验质量。
数据库缓存过程
数据库缓存是一个能显著优化应用程序与其数据库间交互的过程。 对于像 MongoDB 这样的 NoSQL 数据库,其缓存过程遵循以下基本步骤:
查询执行
最初,应用程序执行数据库查询。 该查询可能涉及数据获取、更新、删除或创建操作。
查询结果存储
当数据库查询结果返回后,应用程序不会在使用后立即丢弃这些数据,而是将其存储在缓存中。 缓存通常实现为键值存储,其中查询语句作为键,查询结果作为值。 需要注意的是,缓存数据代表特定时间点的数据快照,当数据库数据发生变化时不会自动更新。
缓存检索
当应用程序下次需要执行相同查询时,会首先检查缓存。 如果缓存中存在该查询的条目(缓存命中),应用程序可以直接返回缓存结果,而无需再次查询数据库。 这显著降低了数据库负载,并提升了应用程序性能,因为从缓存读取通常比执行数据库查询更快。
缓存失效
当数据库中与缓存查询对应的数据被更新时,相应的缓存条目就会过时或"失效"。 应用程序需要制定策略来处理这些情况。 可以选择使失效的缓存条目无效(从缓存中移除),或者用新数据更新缓存条目。 这一步至关重要,因为如果处理不当,应用程序可能会继续使用过时数据,从而导致数据不一致。
例如,我们考虑一个使用 MongoDB 数据库的博客应用。 该应用需要频繁获取所有博客文章的列表以显示在首页上。 与其每次执行相同的高成本数据库查询,应用可以将结果缓存起来。 当用户访问首页时,应用首先检查缓存。 如果数据存在(缓存命中),应用就直接提供缓存数据,从而降低数据库负载并提高响应速度。 然而,当新增博客文章时,缓存的文章列表就会过时。 应用需要处理这一事件并相应地更新或使缓存失效。 这可以通过设置数据库触发器或采用事件驱动架构来实现。
缓存管理同样是实现数据库缓存的关键环节,包括设置合适的缓存大小、制定缓存满载时的淘汰策略(如 LRU 最近最少使用算法)、处理缓存未命中(当请求数据不在缓存中时)以及为缓存条目设置合理的存活时间(TTL)。
实现数据库缓存
使用 MongoDB 实现数据库缓存需要在应用程序和 MongoDB 数据库之间添加一个新的抽象层。 我们可以使用 Redis——一个非常适合缓存需求的高性能内存数据结构存储——来满足我们的缓存需求。Redis 是专门为缓存而设计的。
由于这部分通常是博客中最受读者关注的部分,我们将重点放在负责获取博客文章的博客应用功能上。 以下是我们如何修改此功能以包含缓存的简化示例。
假设我们有一个名为 fetchPosts()的函数,它从 MongoDB 数据库中检索所有博客文章:
std::vector<Post> fetchPosts(mongocxx::collection& postCollection) {
std::vector<Post> posts;
auto cursor = postCollection.find({});
for(auto&& doc : cursor) {
Post post;
// Assume that fillPostFromDoc() fills a Post object from a BSON document.
fillPostFromDoc(post, doc);
posts.push_back(post);
}
return posts;
}
接下来,我们将使用 Redis 为该函数添加缓存功能。 请注意,上述示例程序假设您已运行 Redis 实例并建立了连接。 我们将使用 cpp_redis 库来实现 C++与 Redis 的交互。
#include <cpp_redis/cpp_redis>
// Assume that redisClient is a connected cpp_redis::client instance.
std::vector<Post> fetchPosts(mongocxx::collection& postCollection) {
std::vector<Post> posts;
std::string cacheKey = "posts";
cpp_redis::reply redisReply = redisClient.get(cacheKey);
redisClient.sync_commit();
// Cache miss: key doesn't exist in Redis.
if(redisReply.is_null()) {
// Fetch posts from MongoDB.
auto cursor = postCollection.find({});
for(auto&& doc : cursor) {
Post post;
fillPostFromDoc(post, doc);
posts.push_back(post);
}
// Cache the result in Redis. Assume that postsToJson() converts a vector of Post objects to a JSON string.
// The third argument is the TTL (time-to-live) of the cache entry, after which it'll be automatically deleted.
// Here it's set to 60 seconds.
redisClient.set(cacheKey, postsToJson(posts), 60);
redisClient.sync_commit();
}
// Cache hit: key exists in Redis.
else {
// Assume that jsonToPosts() converts a JSON string to a vector of Post objects.
posts = jsonToPosts(redisReply.as_string());
}
return posts;
}
必须牢记,当博客文章被添加、更新或删除时,我们需要更新或使缓存失效。 可以通过修改相应函数来实现,同时更新或删除 Redis 中的 posts 键。
void addPost(mongocxx::collection& postCollection, const Post& post) {
// Add post to MongoDB.
postCollection.insert_one(postToDoc(post)); // Assume that postToDoc() converts a Post object to a BSON document.
// Invalidate the cache.
redisClient.del(std::vector<std::string>{"posts"});
redisClient.sync_commit();
}
这些是简化示例,实际应用需要更复杂的缓存管理策略。 例如,您可能只想缓存热门博客文章或获取成本较高的文章,或者使用更智能的缓存失效策略来尽可能保持缓存的新鲜度。
高级缓存策略
采用高级缓存策略可以显著提升博客应用的性能。 缓存策略的选择取决于应用程序的具体需求和限制条件。 让我们在博客应用中实施其中一种策略。
缓存单篇博客文章
在前面的示例中,我们缓存了整个博客文章列表。 但如果单篇文章的获取成本较高,单独缓存它们可能更有优势。 缓存键可以采用 post:<id> 的形式,其中<id> 是博客文章的 ID。
// 假设 redisClient 是一个已连接的 cpp_redis::client 实例。
Post fetchPost(mongocxx::collection& postCollection, const std::string& postId) {
Post post;
std::string cacheKey = "post:" + postId;
cpp_redis::reply redisReply = redisClient.get(cacheKey);
redisClient.sync_commit();
if(redisReply.is_null()) {
// Fetch post from MongoDB.
bsoncxx::document::view_or_value filter = document{} << "_id" << bsoncxx::oid(postId) << finalize;
auto maybeResult = postCollection.find_one(filter);
if(maybeResult) {
fillPostFromDoc(post, maybeResult.value());
// Cache the post in Redis for 60 seconds.
redisClient.set(cacheKey, postToJson(post), 60);
redisClient.sync_commit();
}
else {
// Handle the case when the post doesn't exist.
}
}
else {
post = jsonToPost(redisReply.as_string());
}
return post;
}
旁路缓存/延迟加载
在之前的示例中,我们一直使用一种称为"旁路缓存"或"延迟加载"的策略。 这意味着我们只在数据被请求且缓存中不存在时,才会将数据加载到缓存中。 当数据库读取成本较高且数据需要频繁读取时,这种方式非常有效。 然而,它可能导致缓存未命中时的高延迟,因为请求必须直达数据库。
直写式缓存
直写策略确保缓存与数据库之间的数据一致性。 当数据被写入时,它会同时写入缓存和数据库。 缓存始终与数据库保持同步,读取操作具有低延迟,因为它们总是命中缓存。
实现直写缓存需要修改写操作(如 addPost()、updatePost()和 deletePost())以同时更新缓存。
void updatePost(mongocxx::collection& postCollection, const Post& post) {
// Update post in MongoDB.
bsoncxx::document::view_or_value filter = document{} << "_id" << bsoncxx::oid(post.id) << finalize;
bsoncxx::document::view_or_value update = document{} << "$set" << open_document << "title" << post.title << "body" << post.body << close_document << finalize;
postCollection.update_one(filter, update);
// Update cache.
std::string cacheKey = "post:" + post.id;
redisClient.set(cacheKey, postToJson(post));
redisClient.sync_commit();
}
以下是实现应用缓存时可以考虑的一些策略。 根据您的具体需求和数据特性,您可以选择使用不同的策略或多种策略的组合。
使用 gRPC 提升缓存性能
gRPC 是一个高性能、开源、通用的 RPC 框架。 它在改善服务器端缓存方面能成为得力工具,原因如下。gRPC 允许客户端应用程序像调用本地对象一样直接调用服务器应用程序的方法,使分布式应用和服务的构建更加便捷。
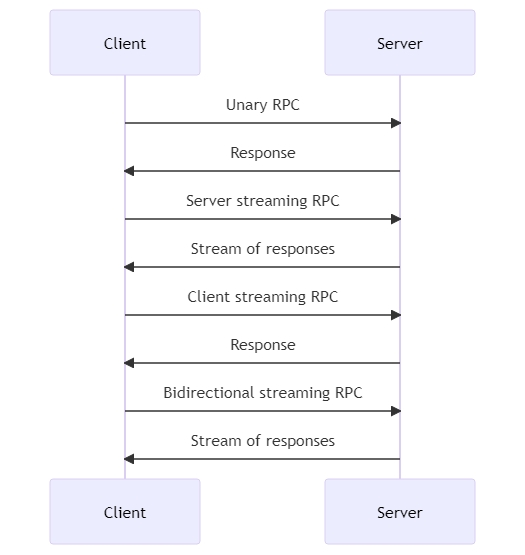
图 7.2 gRPC 工作原理
要利用 gRPC 实现服务器端缓存,我们需要在.proto 文件中定义服务。 该服务应包含可缓存数据获取方法。gRPC 会根据我们的服务定义自动生成代码。
定义服务
在.proto 文件中定义服务:
syntax = "proto3";
service BlogService {
rpc GetPost(GetPostRequest) returns (Post);
rpc ListPosts(Empty) returns (PostList);
}
message GetPostRequest {
string id = 1;
}
message Post {
string id = 1;
string title = 2;
string body = 3;
}
message PostList {
repeated Post posts = 1;
}
message Empty {}
数据获取
在生成的服务实现中,获取数据时使用缓存:
class BlogServiceImpl final : public BlogService::Service {
public:
grpc::Status GetPost(grpc::ServerContext* context, const GetPostRequest* request, Post* response) override {
// Fetch the post from cache or from MongoDB.
Post post = fetchPost(postCollection, request->id());
// Fill the response with the fetched post.
response->set_id(post.id);
response->set_title(post.title);
response->set_body(post.body);
return grpc::Status::OK;
}
grpc::Status ListPosts(grpc::ServerContext* context, const Empty* request, PostList* response) override {
// Fetch the list of posts from cache or from MongoDB.
std::vector<Post> posts = fetchPostList(postCollection);
// Fill the response with the fetched posts.
for(const Post& post : posts) {
Post* postInResponse = response->add_posts();
postInResponse->set_id(post.id);
postInResponse->set_title(post.title);
postInResponse->set_body(post.body);
}
return grpc::Status::OK;
}
};
建立 gRPC 服务器
设置一个使用服务实现的 gRPC 服务器:
int main() {
std::string serverAddress("0.0.0.0:50051");
BlogServiceImpl service;
grpc::ServerBuilder builder;
builder.AddListeningPort(serverAddress, grpc::InsecureServerCredentials());
builder.RegisterService(&service);
std::unique_ptr<grpc::Server> server(builder.BuildAndStart());
std::cout << "Server listening on " << serverAddress << std::endl;
server->Wait();
return 0;
}
通过这种方式,gRPC 帮助抽象了远程过程调用的复杂性,使您能够专注于应用逻辑本身。 通过为应用程序操作定义服务,您可以无缝集成缓存、提升性能并有效扩展应用。gRPC 使用 HTTP/2 协议,其性能效率远高于 HTTP/1。 这是因为 HTTP/2 支持请求/响应多路复用,允许多个请求和响应同时传输。 它还支持服务器推送,可进一步优化缓存机制。
缓存淘汰策略
缓存淘汰是高速缓存层管理中的关键流程,该存储层保存着系统可能再次使用的数据。 缓存淘汰的主要目的是通过移除部分现有条目为新条目腾出空间。 当缓存已满且需要容纳新条目时,这一过程就变得必要。 决定应移除哪个现有条目的方法或策略被称为缓存淘汰策略。 存在多种不同的缓存淘汰策略,但在本次讨论中,我们将重点介绍三种最常用的策略:最近最少使用(LRU)、最不经常使用(LFU)和随机替换(RR)。
最近最少使用(LRU)
最近最少使用(LRU)策略是最流行的缓存淘汰策略之一。 顾名思义,该策略会移除最长时间未被使用或请求的条目。 其基本假设是:如果一个条目长时间未被请求,那么它在近期被请求的可能性较低。 例如,在一个博客应用中缓存最近访问的博客文章时,当缓存空间不足时,LRU 策略会要求我们丢弃最长时间未被访问的文章。
实现 LRU 缓存可以高效地通过哈希表与双向链表的组合来完成。 哈希表提供了对缓存的常数时间访问,确保数据能被快速检索。 而双向链表则允许我们在常数时间内添加或移除条目,使其成为维护基于使用顺序的理想数据结构。
最不经常使用(LFU)
最不经常使用(LFU)策略是另一种常见的缓存淘汰策略。 该策略会淘汰被请求频率最低的缓存项。 其原理在于:如果某个项目很少被请求,那么它近期再次被请求的可能性也较低。 实现 LFU 缓存可能比 LRU 更复杂,但在某些场景下能获得更好的效果。 它需要记录访问频率,可以通过一个哈希映射来存储缓存项,再用另一个来记录访问频率。
随机替换(RR)
随机替换(RR)是一种以简单著称的缓存淘汰策略。 当缓存已满时,随机选择一个条目进行淘汰,为新条目腾出空间。 这种方法实现简单,但完全不考虑使用模式,可能导致频繁访问的重要项目被意外淘汰。
缓存淘汰策略在优化缓存空间使用方面起着至关重要的作用。 通过确保缓存中保存最相关的数据,这些策略可以显著提高后端应用的效率和性能。 但需要注意的是,最佳策略的选择通常取决于应用程序的具体访问模式。 例如,博客网站可能更适合采用 LRU 或 LFU 策略,因为某些博文很可能比其他内容被更频繁地访问。 而对于访问模式更难预测的应用程序,RR 策略可能是更好的选择。 因此,理解应用程序特性及其数据访问模式是选择最有效缓存淘汰策略的关键。
LRU 实现方案
最近最少使用(LRU)缓存策略的实现包含两个主要组件:用于常量时间数据访问的哈希表,以及用于常量时间数据添加和删除的双向链表。 在以下示例中,我们将使用 C++标准模板库为假设的博客应用实现一个 LRU 缓存:
#include <unordered_map>
#include <list>
#include <iostream>
// Implementing an LRU Cache using C++ STL
class LRUCache {
public:
LRUCache(int capacity): size(capacity) {}
int get(int key) {
if(cache.find(key) == cache.end()) return -1;
moveToFront(key);
return cache[key].second;
}
void put(int key, int value) {
if(cache.find(key) != cache.end())
removeKey(key);
else if(cache.size() == size)
removeKey(lru.back());
addToFront(key, value);
}
private:
typedef std::pair<int, int> Pair;
typedef std::list<int>::iterator ListIterator;
std::unordered_map<int, std::pair<int, ListIterator>> cache;
std::list<int> lru;
int size;
void addToFront(int key, int value) {
lru.push_front(key);
cache[key] = {value, lru.begin()};
}
void removeKey(int key) {
lru.erase(cache[key].second);
cache.erase(key);
}
void moveToFront(int key) {
lru.erase(cache[key].second);
lru.push_front(key);
cache[key].second = lru.begin();
}
};
在这段代码中,我们定义了一个名为 LRUCache 的类来实现最近最少使用(LRU)缓存。LRUCache 类包含两个私有成员:一个名为 cache 的哈希映射和一个名为 lru 的双向链表。 哈希映射 cache 用于存储缓存的键值对。 键是数据的唯一标识符,值是实际数据。 哈希映射允许我们在给定键的情况下以恒定时间访问任何值,使其成为实现此目的的高效数据结构。
双向链表 lru 用于记录键的使用顺序。 最近使用的键位于链表前端,而最久未使用的键位于链表末端。 当缓存已满且需要添加新键值对时,该链表能让我们快速定位并移除最久未使用的键。LRUCache 类包含一个 get()函数,用于检查键是否存在于缓存中。 若键存在,该函数会将其移至 lru 链表前端,标记为最近使用的键。 随后返回与该键关联的值。 若键不存在于缓存中,则函数返回预定义的缓存未命中值。
put()函数用于向缓存中添加新的键值对。 如果该键已存在于缓存中,函数会先移除旧的键值对再添加新值。 这确保了缓存中始终保存着指定键的最新值。 当缓存达到容量上限时,函数会先移除最近最少使用的键值对,再添加新条目。 这正是 LRU(最近最少使用)策略的应用场景。moveToFront()、removeKey()和 addToFront()是辅助函数,用于维护 lru 链表和缓存哈希表。moveToFront()函数将指定键移动到 lru 链表的最前端。removeKey()函数会从缓存和 lru 链表中同时移除指定键。addToFront()函数则将新键添加到 lru 链表前端,并将其关联值存入缓存。
这段代码实现了一个有趣的 LRU 缓存方案。 其 get 和 put 操作的时间复杂度均为 O(1),这意味着无论缓存规模如何,这些操作都能在恒定时间内完成。 这种 LRU 缓存设计模式非常适合资源有限且效率至关重要的现实场景,例如数据库查询、网页缓存以及操作系统中的内存管理等应用场景。
LFU 实现
实现最不经常使用(LFU)缓存策略比 LRU 稍复杂,因为它需要跟踪数据的访问频率。 让我们考虑使用 C++标准库(STL)实现一个简单的 LFU 缓存:
#include <unordered_map>
#include <list>
#include <iostream>
class LFUCache {
int cap, size, minFreq;
std::unordered_map<int, std::pair<int, int>> m; //Key to {value,freq};
std::unordered_map<int, std::list<std::list<int>::iterator>> freq; //Freq to key list;
std::unordered_map<int, std::list<int>> l; //key to iterator;
public:
LFUCache(int capacity) {
cap = capacity;
size = 0;
}
int get(int key) {
if(m.find(key) != m.end()) {
freq[m[key].second].erase(l[key]);
if(freq[m[key].second].empty()) freq.erase(m[key].second);
++m[key].second;
freq[m[key].second].push_back(key);
l[key] = –freq[m[key].second].end();
if(minFreq == m[key].second – 1 && freq.find(minFreq) == freq.end())
++minFreq;
return m[key].first;
}
return -1;
}
void put(int key, int value) {
if(cap <= 0) return;
int storedValue = get(key);
if(storedValue != -1) {
m[key].first = value;
return;
}
if(size >= cap ) {
m.erase(freq[minFreq].front());
l.erase(freq[minFreq].front());
freq[minFreq].pop_front();
if(freq[minFreq].size() == 0) freq.erase(minFreq);
–size;
}
m[key] = {value, 1};
freq[1].push_back(key);
l[key] = –freq[1].end();
minFreq = 1;
++size;
}
};
get 和 put 函数与 LRU 缓存中的功能非常相似。 但它们还会调整元素的访问频率。 在本实现中,我们使用了三种数据结构。m 用于记录键到{值,频率}的映射。freq 是一个从频率到具有该频率的键列表的映射。 最后,l 用于追踪指向键在列表中位置的迭代器。
get 函数会增加被访问键的频率,并调整该键在 freq 映射中的位置。put 函数首先通过 get 函数检查键是否已在缓存中。 如果键不在缓存中且缓存大小小于容量,则添加键值对;否则在添加新键值对前移除最不常使用的键值对。
该 LFU 缓存实现确保当缓存已满且需要插入新数据点时,会移除使用频率最低的数据。 这种模式适用于某些特定类型的数据访问模式,其中访问频率能有效预测未来的访问情况。
RR 实现方案
随机替换(RR)是一种通过随机选择候选项目进行替换的缓存算法。 该算法非常简单高效,因为它不需要维护任何关于项目使用频率或最近使用情况的额外信息。
以下是 C++实现示例:
#include <iostream>
#include <vector>
#include <unordered_map>
#include <cstdlib>
class RRCache {
private:
int capacity;
std::vector<int> keys;
std::unordered_map<int, int> cache;
public:
RRCache(int capacity) {
this->capacity = capacity;
}
int get(int key) {
if(cache.find(key) != cache.end()) {
return cache[key];
} else {
return -1;
}
}
void put(int key, int value) {
if(cache.size() == capacity) {
int indexToRemove = rand() % keys.size();
int keyToRemove = keys[indexToRemove];
cache.erase(keyToRemove);
keys[indexToRemove] = keys.back();
keys.pop_back();
}
cache[key] = value;
keys.push_back(key);
}
};
int main() {
RRCache cache(2);
cache.put(1, 1);
cache.put(2, 2);
std::cout << cache.get(1) << std::endl; //returns 1
cache.put(3, 3); //evicts key 1 or 2 randomly
std::cout << cache.get(1) << std::endl; //returns -1 if key 1 is evicted, 1 otherwise
std::cout << cache.get(2) << std::endl; //returns -1 if key 2 is evicted, 2 otherwise
cache.put(4, 4); //evicts key 2 or 3 randomly
std::cout << cache.get(1) << std::endl; //always returns -1
std::cout << cache.get(2) << std::endl; //returns -1 if key 2 is evicted, 2 otherwise
std::cout << cache.get(3) << std::endl; //returns -1 if key 3 is evicted, 3 otherwise
std::cout << cache.get(4) << std::endl; //always returns 4
return 0;
}
在这段代码中,我们维护了一个 vector 类型的 keys 来存储当前缓存中的所有键,以及一个 unordered map 类型的 cache 来存储键值对。
get 函数会直接返回键对应的值(如果该键存在于缓存中)。
put 函数会检查缓存是否已达到容量上限。 如果已满,它会从 keys 向量中随机选择一个键,将其从缓存和向量中移除,然后将新的键值对添加到缓存和向量中。
这种方法的缺点之一是没有考虑缓存中项目的使用频率或最近使用情况。 但其优势在于简单高效,适用于其他替换方法效果不佳或维护额外数据结构开销过大的应用场景。
缓存错误排查
虽然缓存能显著加快数据检索速度并减轻数据库或外部服务的负载,但它也带来了一系列开发者需要应对的独特挑战,特别是在多用户可能同时与数据交互的后端应用中。 这些挑战包括缓存失效、缓存雪崩以及分布式系统中的数据一致性维护。
缓存失效
当缓存中的数据因源数据变更而失效时,就会出现缓存失效这一常见问题。 缓存数据与源数据之间的这种差异可能导致向用户提供过时信息,从而引发数据不一致和潜在错误。
处理缓存失效有几种策略:
● 一种方法是使用生存时间(TTL)策略。 在这种方法中,每个缓存项在加入缓存时会获得一个时间戳。 如果请求该缓存项时发现时间戳超过特定阈值,则缓存失效,并从数据源获取最新数据。 这种方法确保数据不会无限期留在缓存中,并能定期刷新。 但可能不适合频繁或不可预测变化的数据。
● 另一种方法是直写(Write-Through)策略。 这种方法会同时更新缓存和源数据。 这能确保缓存始终反映数据的最新状态,保持一致性。 但由于每次写入操作都需要更新缓存和源数据,这种方法可能较慢。
● 回写策略是另一种方法,其中更改首先在缓存中进行,然后异步更新源数据。 这可以提高性能,因为写操作速度更快。 但如果系统在源数据更新前崩溃,会增加数据丢失的风险。
缓存雪崩
缓存雪崩是另一个挑战,当多个线程试图同时生成相同数据时发生,通常在缓存失效后。 这可能导致数据库负载过重并降低性能。
有几种策略可以防止缓存雪崩:
● 缓存锁定是一种技术,当线程获取到空值或已失效的缓存项时,会立即用占位符值替换它。 在该线程获取新数据期间,其他线程只会看到占位符并知道需要等待。 这样可以防止多个线程同时尝试获取相同数据。
● 随机提前过期是另一种防止缓存雪崩的策略。 不同于一次性使所有缓存项失效,而是为它们分配略微随机的 TTL 值。 由于并非所有项都在同一时间刷新,这能分散数据库的负载压力。
节点不一致性
在分布式系统中,保持多个节点间的一致性可能具有挑战性。 如果每个节点都维护自己的缓存,那么在一个节点上对数据所做的更改不会立即反映在其他节点的缓存中。 这可以通过分布式缓存同步来解决,但需要更多资源且可能变得复杂。
通过理解这些挑战并实施有效的应对策略,开发者可以确保构建可靠的缓存系统,从而减少数据库的不必要负载并提升用户体验。 尽管存在复杂性,缓存在提升性能和效率方面的优势使其成为现代计算中一项有价值的技术。
总结
本章深入探讨了缓存概念及其在服务器端编程中的核心作用。 我们了解到缓存是一种将频繁访问数据存储在"缓存"中的技术,可显著提升应用性能并降低网络延迟。 采用的缓存类型主要取决于后端系统需求及被缓存数据的特性。 以数据库缓存为例,其重点在于存储数据库查询结果,这对减轻数据库负载和提升应用响应速度至关重要。
随后我们详细介绍了在基于 MongoDB 的博客应用中实现缓存的完整流程。 这个实践练习生动展示了缓存插入、缓存检索和缓存淘汰的核心概念,并演示了从简单的生存时间(TTL)方法到更复杂的透写与回写等多种实现策略。 此外,我们还探讨了如何利用 Google 的 gRPC 框架通过 HTTP/2 协议和二进制数据格式等高级特性来增强服务端缓存,从而显著提升数据传输效率。
最后,我们探讨了缓存淘汰策略,如最近最少使用(LRU)、最不经常使用(LFU)和随机替换(RR),并讨论了它们各自的适用场景和实现细节。 在此过程中,我们还发现了使用缓存时可能遇到的潜在陷阱和常见问题,包括缓存失效、缓存雪崩和一致性问题。 最后我们学习了有效处理这些问题的策略,例如使用缓存锁定策略或缓存预热策略来防止缓存雪崩。 本章全面介绍了服务端编程中的缓存机制,并详细阐述了如何在实际应用中有效实施和管理缓存。








评论前必须登录!
注册