 网硕互联帮助中心
网硕互联帮助中心目录
源码下载
前置点
项目演示
涉及知识点
本文的改进和新增功能
最小堆记录定时器
上传文件功能
下载文件
核心代码
解析session id
Webbench压测
下载并编译
开始压测
可能出现的问题
庖丁解牛(来自原文)
CPP11实现
致谢
源码下载
视频讲解:TinyWebServer服务器讲解
TinyWebServer源代码:https://github.com/markparticle/WebServer
TinyWebServer-v2源代码(本文):https://github.com/KeepTryingTo/TinyWebServer-v2
Linux下C++轻量级Web服务器,助力初学者快速实践网络编程,搭建属于自己的服务器(这是TinyWebServer原作者实现这个项目的目的).
前置点
其实在对TinyWebServer修改之后是否要开源出来其实是非常纠结的,倒不是说代码开不开源问题,而是TinyWebServer原作者的目的就是想要做一个尽量全而轻量的Web服务器,如果添加上传文件以及下载文件功能之后,会让代码变得更庞大,同时对于初学者或者我们自己在看的时候非常不利,这也违背了TinyWebServer原作者写这个项目的初心。本来是想和原作者沟通是否可以合并到分支里面,但是想了一下还是不要了,这样确实会让代码变得更臃肿和不友好,决定还是另起一个项目,这样大家可以根据自己的需求来学习这个项目。在改进,美化界面以及添加的功能的过程中我是借助了AI的,甚至你用AI可能搜出来的代码和我放在上面的一样(![]() )。我主要的改进包括使用最小堆将原作者的双向链表给替换了,但是在进行压测的时候其实QPS都差不多;其次是将所有的界面给美化了,这部分需要自己有HTML,CSS,JAVAScript的基础(AI);最后是添加了上传文件和下载文件的功能。其实我做的改进和新增功能对于原作者来说非常简单,这也是原作者对轻量的初心,只是我自己想要去更深入的了解以及达到自己的目的才添加功能的,并没有违背原作者的想法。
)。我主要的改进包括使用最小堆将原作者的双向链表给替换了,但是在进行压测的时候其实QPS都差不多;其次是将所有的界面给美化了,这部分需要自己有HTML,CSS,JAVAScript的基础(AI);最后是添加了上传文件和下载文件的功能。其实我做的改进和新增功能对于原作者来说非常简单,这也是原作者对轻量的初心,只是我自己想要去更深入的了解以及达到自己的目的才添加功能的,并没有违背原作者的想法。
项目演示
web服务器演示
涉及知识点
- 使用 线程池 + 非阻塞socket + epoll(ET和LT均实现) + 事件处理(Reactor和模拟Proactor均实现) 的并发模型
- 使用状态机(主从状态机结合)解析HTTP请求报文,支持解析GET和POST请求
- 访问服务器数据库实现web端用户注册、登录功能,可以请求服务器图片和视频文件
- 实现同步/异步日志系统(生产者和消费者模式),记录服务器运行状态
- 经Webbench压力测试可以实现上万的并发连接数据交换
- 实现线程池和数据库连接池
本文的改进和新增功能
- [√] 最小堆替换原作者实现的双向链表
- [√] 实现了上传文件功能
- [√] 实现了下载文件功能
- [√] 美化了所有界面
-
[√] 服务器生成session id和保存cookie状态,过期时间设置为30分钟
注:整个改进的过程中很多时候都借助了AI,特别是美化界面部分。
最小堆记录定时器
实现堆的过程中主要包含了向上调整堆,向下调整堆,添加节点,删除堆顶节点以及删除指定节点.这里的节点是指定时器,是根据定时器时间大小来进行构建最小堆的,并且保存节点采用的是vector数组以及哈希map来记录当前节点的索引(建议大家直接在网上搜索看资料或者视频更清楚)。
- 向上调整堆:将当前节点对应时间和父节点对应时间进行比较,如果小于父节点的时间就交换,同时哈希map记录的索引也需要交换,因为使用vector数组保存的节点。
- 向下调整堆:将当前节点和其左右子节点的时间进行对比,选择最小的孩子时间节点进行交换,哈希map记录的索引也需要进行交换。
- 添加节点:直接在vector数组最后添加节点,同时哈希map记录索引,最后调用向上调整函数调整堆即可。
- 删除堆顶节点:如果直接删除堆顶节点比较复杂,因此将堆顶节点和最后一个节点进行交换,删除最后一个节点,同时调用向下调整函数即可恢复最小堆结构。
- 删除指定节点:如果直接删除指定节点比较麻烦,和删除堆顶节点一样,将其和最后一个节点进行交换,并删除最后一个节点,同时从删除当前节点位置调用向下和向上调整函数即可恢复最小堆结构。
上传文件功能
上传文件时需要注意的问题比较多,具体实现大家可以看源代码,主要问题如下:
- 原作者实现的代码对于请求body部分大小是有限的,如果直接对其缓冲区大小进行调整,将报错std::bad_alloc,因此对于稍微小的文件可以一次请求成功,但是对于稍微大一点的,比如1KB就会上传失败。
- 为了实现上传稍微大一点的文件,这里采用比较粗暴的形式,既然一次上传不完所有文件内容,那么可以分批次请求上传文件内容,然后将所有上传的内容进行合并得到完整的文件内容,这是目前的实现方式,同时也会将分块保存的文件给删除掉。
- 除了后端逻辑实现部分之外,还需要注意前端部分的实现,哪怕借助AI也需要非常小心和大量的调整。
- 前端部分除了实现upload.html页面之外,还需要考虑分块上传文件的过程,这部分涉及HTML,CSS以及JavaScript知识点,大家可以去了解一下,我也边写同时借助AI来了解。

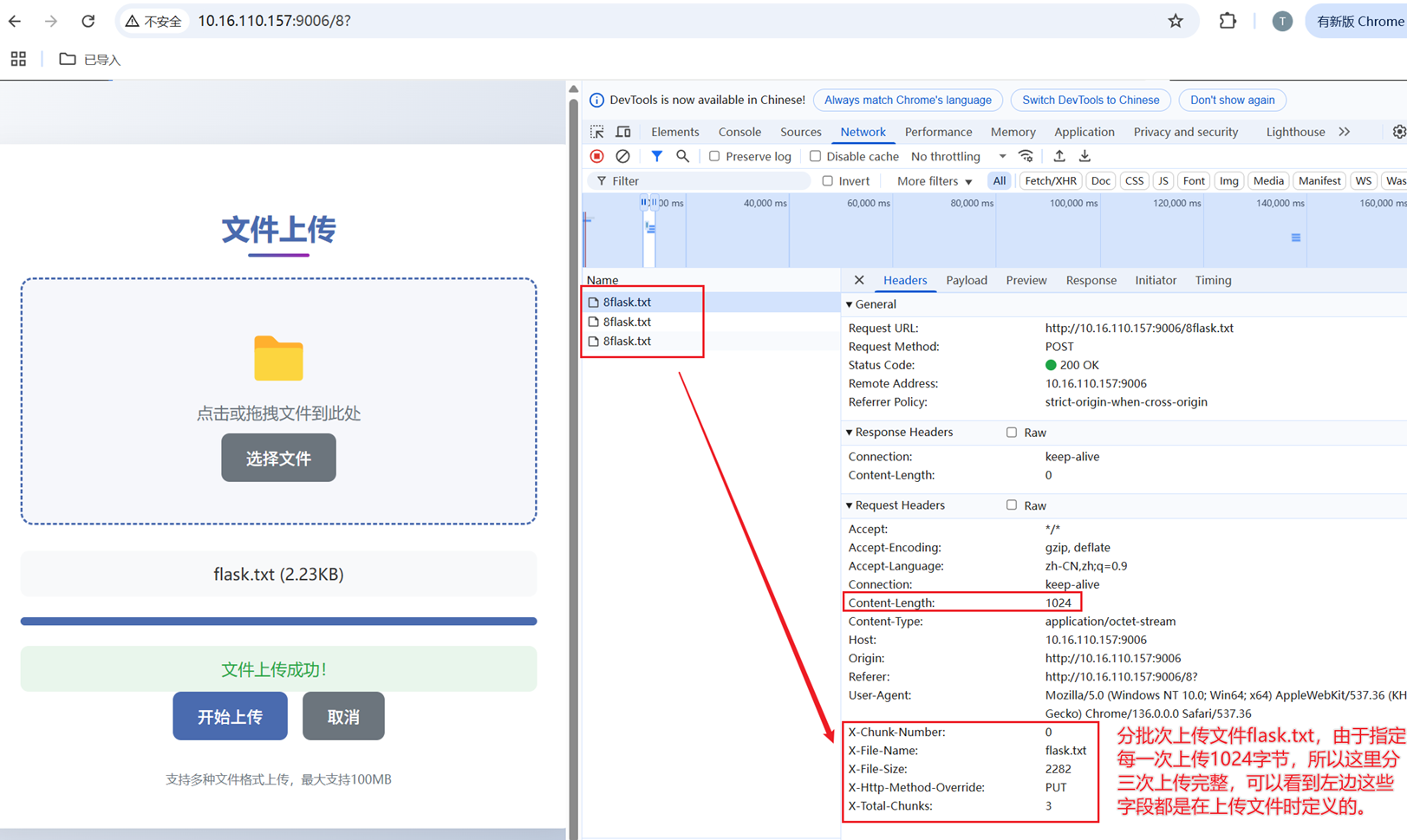
下载文件
下载文件的实现相比上传文件要简洁的多,当然并不代表简单,如下问题:
- 这部分首先需要实现download.html前端部分的网页,实现的过程中需要考虑怎么将服务器部分要下载的文件显示到前端,那么就需要我们在点击进入下载页面的时候,向服务器发送请求,服务器会把可以下载的文件列表通过响应的方式给浏览器(客户端),浏览器接收之后就可以将内容显示出来,当然这部分还是涉及大量的HTML,CSS以及JavaScript的知识点,但是并不妨碍我们理解后端的逻辑。
- 点击要下载的文件时,浏览器向服务端发送请求,服务端将要下载的文件通过响应的方式发送浏览器,注意这里有一个字段Content-Disposition要非常小心,Content-Disposition是 HTTP 响应头中的一个重要字段,主要用于控制客户端(如浏览器)如何处理服务器返回的内容,特别是在文件下载场景。
- Content-Disposition添加的时序位置也是有要求的,如果添加的时机不对,也会导致失败(主要是自己的经验不足,导致踩坑):
// HTTP响应的标准格式
HTTP/1.1 200 OK // 状态行
Content-Type: text/html // 响应头
Content-Length: 1234 // 响应头
Content-Disposition: attachment // 响应头
// 空行
<html>…</html> // 响应体
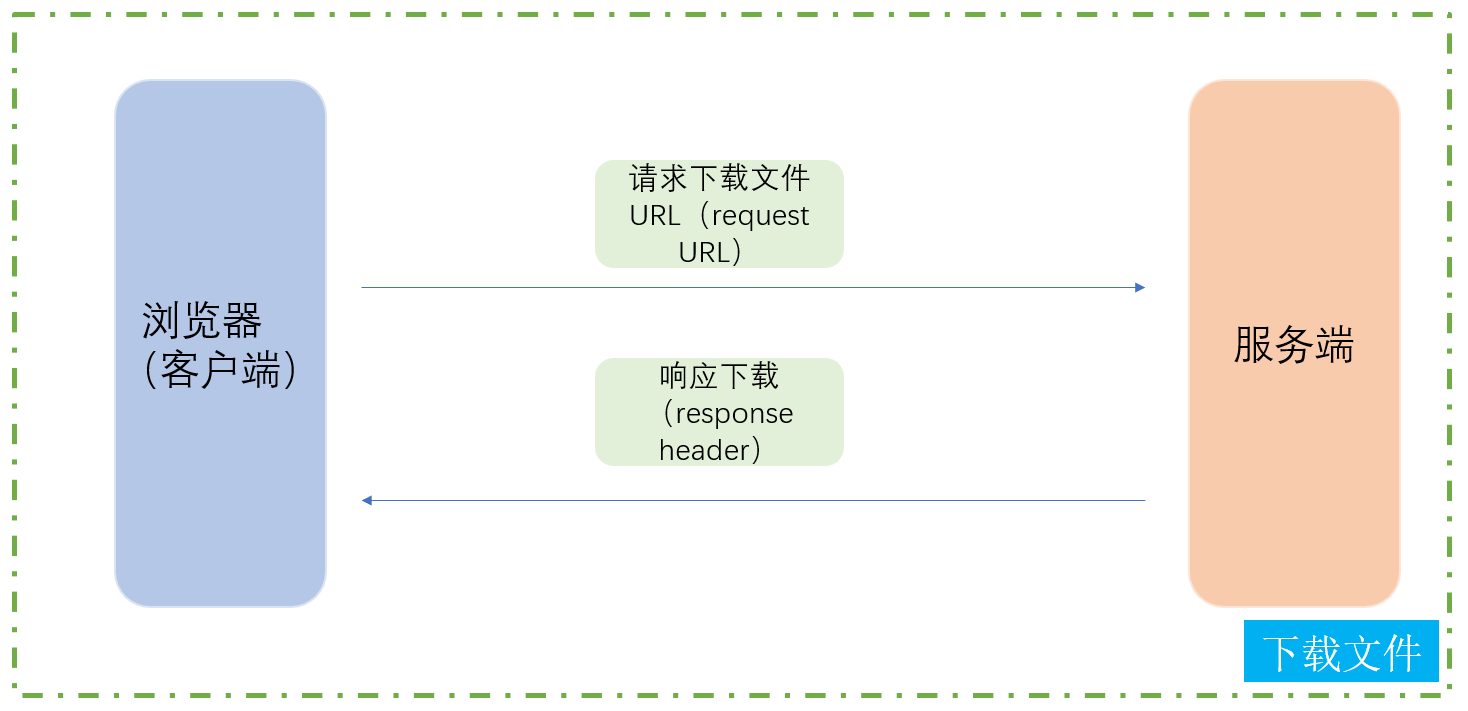
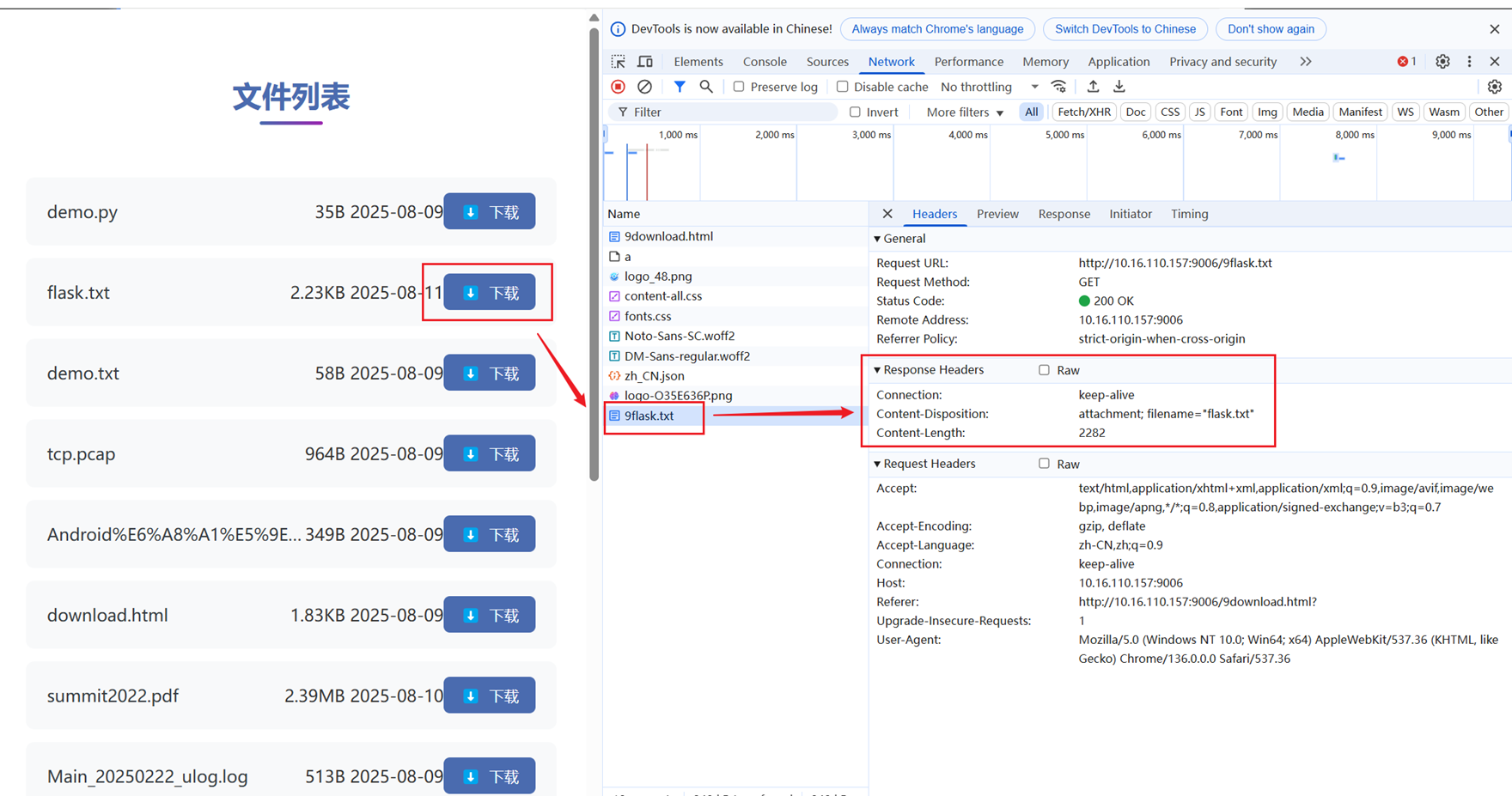
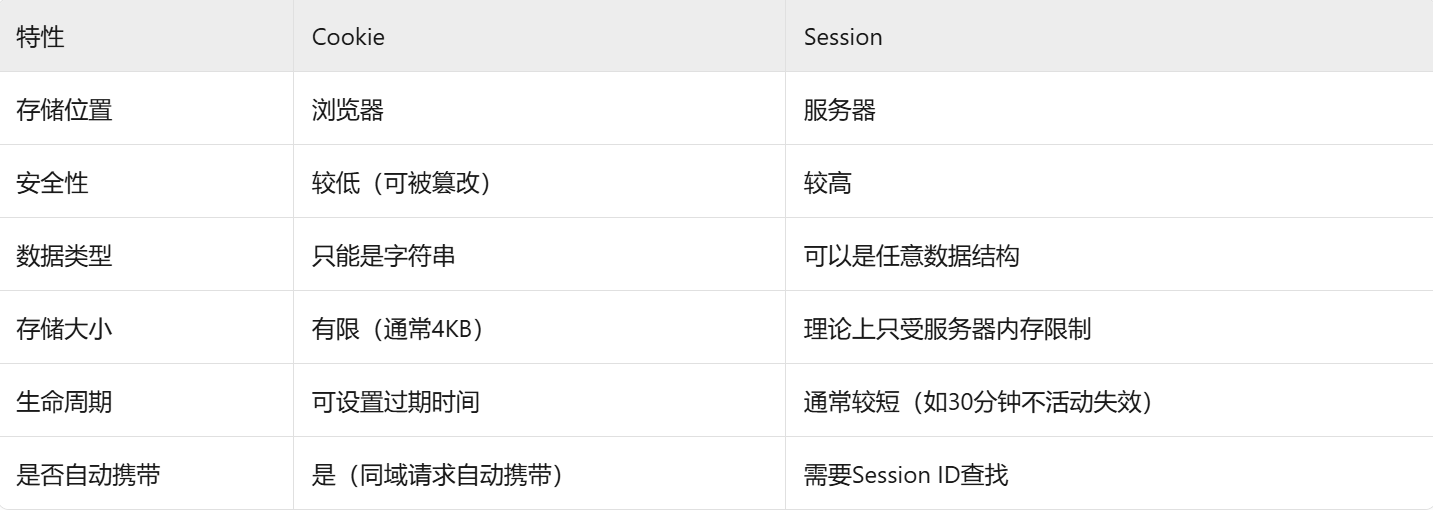
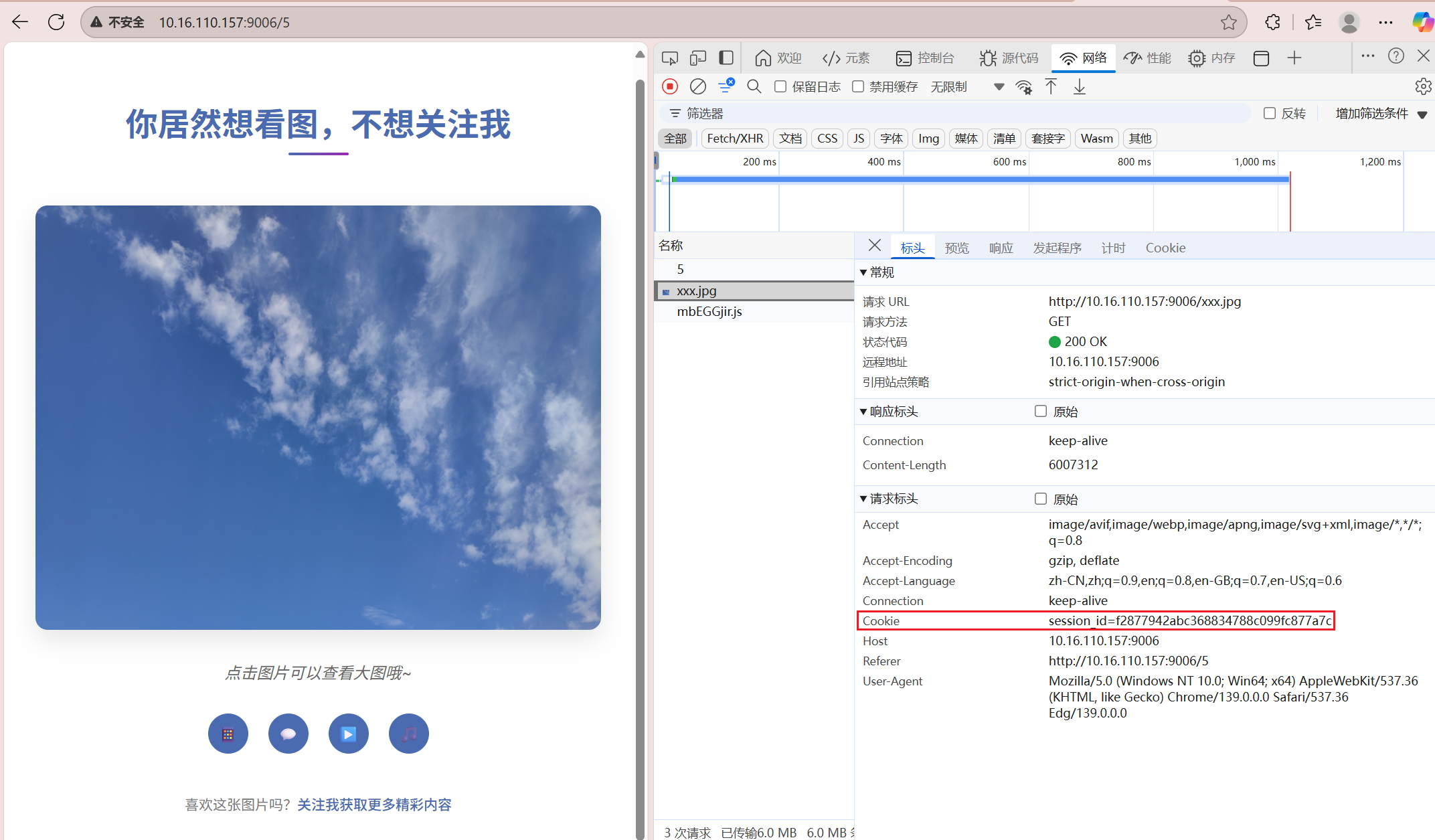
服务器生成session id和保存cookie状态
Cookie 是存储在客户端(浏览器)的小型文本数据(通常有大小限制,如4KB)Session 是存储在服务端的用户状态信息(大小理论上只受服务器内存限制)它们通常配合使用,形成这样的工作流程:
- 用户首次访问 → 服务端创建Session并生成唯一Session ID;
- 服务端通过Set-Cookie将Session ID发送给浏览器;
- 浏览器后续请求自动携带这个Cookie(Session ID);
- 服务端通过Session ID查找对应的Session数据
核心代码
生成32位session id → 保存session id(便于后面验证)→ 验证session id函数 → 销毁session id
std::string http_conn::generate_session_id(){
// 16字节随机数缓冲区(128位)
std::array<unsigned char, 16> bytes{};
// 使用硬件熵源初始化随机数生成器
std::random_device rd;
// 填充随机字节(保留低8位)
for(auto & b : bytes){
b = static_cast<unsigned char>(rd() & 0xFF);
}
// HEX转换表(小写字母)
static const char* hex_chars = "0123456789abcdef";
// 预分配32字符缓冲区
std::string session_id;
session_id.resize(32);
// 将每个字节转为两个HEX字符
for(size_t i = 0; i < bytes.size(); i++){
session_id[i * 2] = hex_chars[bytes[i] >> 4]; // 高4位
session_id[i * 2 + 1] = hex_chars[bytes[i] & 0x0F]; // 低4位
}
return session_id;
}
bool http_conn::create_session(const std::string& username){
session_lock.lock();
try {
if(m_has_session && strlen(m_session_id_buf) > 0){
std::string session_id(m_session_id_buf);
printf("strlen(session id) = %d\\n", session_id.size());
printf("%s %d session id = %s\\n", __FILE__, __LINE__, session_id.c_str());
sessions[session_id] = session_info(username);
sessions_st.insert(session_id);
m_session_id = session_id; // 其实在解析头部信息的时候就赋值过了,这里只是重复的赋值一遍
}else{
std::string session_id = generate_session_id();
printf("%s %d session id = %s\\n", __FILE__, __LINE__, session_id.c_str());
sessions[session_id] = session_info(username);
m_session_id = session_id;
sessions_st.insert(session_id);
m_has_session = true;
m_need_set_cookie = true;
}
session_lock.unlock();
return true;
}catch(…){
// std::cout<<"username = "<<username<<std::endl;
printf("%s %d throw ERROR and username = %s\\n", __FILE__, __LINE__, username.c_str());
session_lock.unlock();
return false;
}
return false;
}
bool http_conn::validate_session(const std::string& session_id){
session_lock.lock();
auto it = sessions.find(session_id);
if(it != sessions.end() && it -> second.is_valid){
// 检查session id是否过期(是否超过规定的30分钟)
time_t now = time(NULL);
if(now – (it -> second).last_access < 1800){
it -> second.last_access = now;
session_lock.unlock();
return true;
}else{
// 否则删除过期的session id
sessions.erase(it);
}
}
session_lock.unlock();
return false;
}
void http_conn::destroy_session(const std::string& session_id){
session_lock.lock();
sessions.erase(session_id);
session_lock.unlock();
m_session_id = "";
m_is_logged_in = false;
}
解析session id
当服务器生成session id之后发送给浏览器(客户端),那么浏览器保存着session id,后面请求页面的时候使用这个session id作为身份,因此需要解析header中的session id。
if(strncasecmp(text, "Cookie:", 7) == 0){
// text 形如 "Cookie: a=1; session_id=abcd…; b=2"
const char* p = text + 7;
p += strspn(p, " \\t");
const char* sid = strcasestr(p, "session_id=");
if (sid) {
sid += 11; // 跳过 "session_id="
size_t n = 0;
while (sid[n] && sid[n] != ';' && sid[n] != ' ' && n < 64) n++;
// 只接受 32 位十六进制
if (n == 32) {
bool ok = true;
// 确保session id是合法的
for (size_t i = 0; i < 32; ++i) {
char c = sid[i];
if (!((c >= '0' && c <= '9') || (c >= 'a' && c <= 'f'))) { ok = false; break; }
}
if (ok) {
memcpy(m_session_id_buf, sid, 32);
m_session_id_buf[32] = '\\0';
m_has_session = true;
}
}
}
if(strlen(m_session_id_buf) > 0){
m_has_session = true;
m_session_id = std::string(m_session_id_buf);
sessions_st.insert(m_session_id);
}
}
Webbench压测
原理: 父进程fork若干个子进程,每个子进程在用户要求时间或默认的时间内对目标web循环发出实际访问请求,父子进程通过管道进行通信,子进程通过管道写端向父进程传递在若干次请求访问完毕后记录到的总信息,父进程通过管道读端读取子进程发来的相关信息,子进程在时间到后结束,父进程在所有子进程退出后统计并给用户显示最后的测试结果,然后退出。
下载并编译
wget http://home.tiscali.cz/~cz210552/distfiles/webbench-1.5.tar.gz
解压:tar zxvf webbench-1.5.tar.gz
切换目录:cd webbench-1.5
编译:make
安装:sudo make install
注意:目前1.5版本的webbench支持http协议,不支持https协议。

开始压测
webbench -c 10500 -t 5 http://10.16.110.157:9006/
模式1 proactor + LT + LT:./server -m 0 -c 1 -a 0
Speed=4317024 pages/min, 8058445 bytes/sec. Requests: 359752 susceed, 0 failed.
模式2 proactor + LT + ET:./server -m 1 -c 1 -a 0
Speed=4208976 pages/min, 7856733 bytes/sec. Requests: 350748 susceed, 0 failed.
模式3 proactor + ET + LT:./server -m 2 -c 1 -a 0
Speed=4085856 pages/min, 7636944 bytes/sec. Requests: 340485 susceed, 3 failed.
模式4 proactor + ET + ET:./server -m 3 -c 1 -a 0
Speed=3805128 pages/min, 7113030 bytes/sec. Requests: 317091 susceed, 3 failed.
模式5 reactor + LT + ET:./server -m 1 -c 1 -a 1
Speed=2533716 pages/min, 4729760 bytes/sec. Requests: 211143 susceed, 0 failed.
注:和原作者测试的结果比起来结果还变差了,我感觉改进的最小堆思路应该是没有什么问题,可能是没有做什么优化,我在实现最小那部分的时候对于构建堆,删除元素以及堆的调整都是采用原始堆的思想,完全没有做什么性能上的优化,但是可以给大家提供一个思路去学习。
可能出现的问题
问题1:web服务器启动之后,Chrome浏览器连接报错:拒绝连接(可是之前都还行),如果换edge浏览器就可以正常访问,
# 强制刷新页面(绕过缓存)
Ctrl + Shift + R (Windows/Linux)
Cmd + Shift + R (Mac)
庖丁解牛(来自原文)
近期版本迭代较快,以下内容多以旧版本(raw_version)代码为蓝本进行详解.
- 小白视角:一文读懂社长的TinyWebServer
- 最新版Web服务器项目详解 – 01 线程同步机制封装类
- 最新版Web服务器项目详解 – 02 半同步半反应堆线程池(上)
- 最新版Web服务器项目详解 – 03 半同步半反应堆线程池(下)
- 最新版Web服务器项目详解 – 04 http连接处理(上)
- 最新版Web服务器项目详解 – 05 http连接处理(中)
- 最新版Web服务器项目详解 – 06 http连接处理(下)
- 最新版Web服务器项目详解 – 07 定时器处理非活动连接(上)
- 最新版Web服务器项目详解 – 08 定时器处理非活动连接(下)
- 最新版Web服务器项目详解 – 09 日志系统(上)
- 最新版Web服务器项目详解 – 10 日志系统(下)
- 最新版Web服务器项目详解 – 11 数据库连接池
- 最新版Web服务器项目详解 – 12 注册登录
- 最新版Web服务器项目详解 – 13 踩坑与面试题
CPP11实现
更简洁,更优雅的CPP11实现:Webserver
致谢
Linux高性能服务器编程,游双著.
感谢qinguoyi提供的TinyWebServer,让我学习到了很多知识点,也希望我给出的能给大家带来收益。







评论前必须登录!
注册