 网硕互联帮助中心
网硕互联帮助中心奈飞(Netflix)作为全球最大的流媒体平台之一,其业务的核心竞争力高度依赖算法的持续优化。从用户看到的个性化推荐,到内容制作的决策,再到流媒体体验的流畅度,算法贯穿了奈飞的全业务链条。所谓 “奈飞工厂”,可以理解为其围绕算法驱动业务的整套研发、应用与迭代体系,而 “算法优化实战” 则体现在解决实际业务问题的具体实践中。
一、核心算法应用场景与优化实战案例
奈飞的算法优化始终围绕 **“提升用户体验”和“降低业务成本”** 两大目标,聚焦于以下关键场景:
1. 个性化推荐:从 “猜你喜欢” 到 “让你离不开”
推荐系统是奈飞的核心,直接影响用户观看时长和留存率。其优化历程充满实战性的突破:
-
早期:从竞赛到协同过滤的突破
2009 年,奈飞通过 “Netflix Prize” 竞赛悬赏 100 万美元,目标是将其推荐系统的预测准确率提升 10%。最终获胜团队提出的 “矩阵分解” 算法(如 SVD++),相比传统协同过滤,更好地处理了用户 – 物品交互的稀疏性问题,将预测误差降低了 10.06%。
实战挑战:用户数据规模激增(当时已达千万级用户),传统模型计算效率不足。
优化方案:采用分布式矩阵分解(如基于 Spark 的并行计算),平衡精度与速度。 -
中期:引入深度学习与多模态特征
随着用户行为数据(点击、暂停、回看)和内容元数据(演员、类型、台词、海报)的丰富,单一协同过滤难以捕捉复杂模式。奈飞引入了:- 神经协同过滤(NCF):用神经网络替代矩阵分解,更好地学习非线性交互;
- 多模态融合:将文本特征(剧情描述)、视觉特征(海报风格)、音频特征(预告片背景音乐)通过注意力机制融合,解决 “冷启动” 问题(如新内容无用户交互数据时,依赖内容自身特征推荐)。
实战挑战:多模态数据异构性强,融合难度大。
优化方案:设计跨模态注意力网络,动态调整不同特征的权重(如对新用户,优先依赖内容特征;对老用户,侧重行为特征)。
-
当前:实时化与上下文感知
推荐不再局限于 “用户喜欢什么”,而是 “用户现在可能喜欢什么”。奈飞引入上下文特征(时间、设备、当前观看进度),例如:- 工作日晚间推荐短剧集(用户时间有限);
- 周末推荐长电影(用户更放松)。
模型通过在线学习(如 FTRL 算法)实时更新,确保推荐结果与用户当前状态匹配。
2. 内容制作:用算法 “押注” 爆款
奈飞每年投入数百亿美元制作原创内容,算法在 “拍什么” 的决策中扮演关键角色:
-
核心问题:如何预测内容的市场潜力,降低投资风险?
奈飞通过分析三类数据构建预测模型:- 用户历史行为:对同类题材、演员、导演的观看时长、评分;
- 外部数据:社交媒体热度、影评人偏好、同类内容的历史表现;
- 内容元数据:剧本关键词、角色设定、叙事节奏。
-
实战优化:
- 早期依赖线性模型(如逻辑回归)预测内容受欢迎程度,但误差较大(如低估小众题材的潜力);
- 后期引入梯度提升树(XGBoost)和图神经网络(GNN):GNN 可捕捉 “内容 – 用户 – 标签” 的关联网络(如 “喜欢《怪奇物语》的用户也喜欢 80 年代怀旧题材”),提升跨类推荐的准确性;
- 平衡 “算法预测” 与 “创作自由度”:算法提供潜力方向(如 “家庭喜剧 + 女性主角” 近期热度上升),但不直接决定剧情,避免内容同质化。
典型案例:《纸牌屋》的制作决策,正是算法分析出 “大卫・芬奇导演 + 凯文・史派西主演 + 政治题材” 的组合与用户偏好高度匹配,最终成为现象级作品。
3. 用户流失预测(Churn Prediction):提前留住 “潜在离开者”
用户流失(取消订阅)是流媒体平台的核心风险,奈飞通过算法提前识别高风险用户,采取干预措施(如推荐专属内容、临时优惠):
-
模型优化路径:
- 早期用逻辑回归识别流失特征(如连续 7 天未观看、对推荐内容点击率下降),但特征单一,误判率高;
- 升级为集成模型(随机森林、XGBoost):纳入更细粒度特征(如 “观看时长环比下降 30%”“对新上线内容无点击”),并通过 SHAP 值分析关键流失因素(如 “连续 3 周无感兴趣的新内容” 占比最高);
- 引入实时性:用流处理框架(如 Flink)实时处理用户行为,每小时更新一次流失概率,确保干预时机精准(如用户刚出现 “连续 2 天未打开 App” 时,立即推送其收藏的内容更新)。
-
实战效果:通过算法优化,奈飞将用户流失率降低了约 15%,每年减少数十亿美元损失。
4. 流媒体体验优化:让 “缓冲” 成为历史
用户对 “卡顿” 的容忍度极低,奈飞通过算法优化视频传输与编码,平衡画质与流畅度:
-
自适应比特率(ABR)算法:
根据用户实时网络状况(带宽、延迟)动态调整视频清晰度(从标清到 4K)。早期 ABR 依赖简单规则(如带宽低于 2Mbps 降为标清),但易频繁切换清晰度(导致观感差)。
优化方案:引入强化学习(RL),将 “用户观看体验” 作为奖励(如 “减少切换次数 + 维持高清晰度”),训练智能体实时决策,使缓冲时间减少了 40%。 -
视频编码优化:
用机器学习优化视频压缩算法(如 H.265/HEVC),在相同画质下减少 30% 的带宽消耗。例如,通过分析视频帧的内容(如静态场景 vs 动态动作场景),动态调整压缩率(静态场景可更高压缩,不影响观感)。
二、算法优化的 “实战方法论”
奈飞的算法优化并非孤立的技术行为,而是一套贯穿 “数据 – 模型 – 部署 – 验证” 的闭环体系:
数据驱动的 A/B 测试文化
任何算法优化必须通过严格的 A/B 测试验证。例如,新推荐模型需在小部分用户(如 1%)中测试,对比关键指标(观看时长、点击率、留存率),只有统计显著优于旧模型才会全量上线。
实战细节:测试组与对照组严格匹配(用户画像、设备、地区一致),避免干扰因素;测试周期至少 2 周,覆盖不同用户行为周期(如工作日 vs 周末)。
工程化落地优先
再好的模型若无法高效部署,也无实战价值。奈飞通过以下方式解决 “模型上线难”:
- 模型轻量化:用知识蒸馏将复杂深度学习模型压缩为小模型(如将 10 亿参数模型压缩至 1 亿,精度损失 < 1%),适配移动端;
- 分布式部署:用 Kubernetes 管理模型服务,支持每秒百万级请求的并发处理;
- 实时更新:通过在线学习框架(如 Vowpal Wabbit),模型可每小时更新一次,无需重启服务。
平衡数据价值与隐私保护
奈飞依赖用户数据,但需遵守 GDPR 等法规。其优化方案包括:
- 联邦学习:用户数据留在本地,仅上传模型参数更新,避免原始数据泄露;
- 差分隐私:在数据集中加入噪声,确保无法反推单个用户信息,同时不影响模型精度。
三、挑战与未来方向
尽管奈飞的算法优化已非常成熟,仍面临持续挑战:
- “算法茧房” 风险:过度个性化可能导致用户视野狭窄(如只推荐同类内容),需引入 “探索式推荐”(主动推荐少量陌生题材);
- 全球化适配:不同地区用户偏好差异大(如亚洲用户更爱 dramas,欧美用户偏好喜剧),需设计地域自适应模型;
- 生成式 AI 的融入:用 GPT 类模型自动生成内容描述、推荐语,甚至辅助剧本创作,目前仍在测试阶段。
总结
奈飞的 “算法优化实战” 本质是 **“用技术解决业务痛点”**:从推荐、内容到用户留存,每个场景的优化都紧扣 “用户体验” 和 “商业目标”,并通过严谨的工程实践和数据验证确保效果。其经验表明,算法的价值不在于复杂度,而在于能否在真实业务场景中落地、迭代并创造价值。

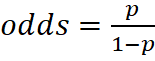



评论前必须登录!
注册