 网硕互联帮助中心
网硕互联帮助中心本篇技术博文摘要 🌟
-
本文通过动画可视化深入解析数据结构中的核心查找算法,从基础概念到高阶应用,全面覆盖顺序查找、折半查找、分块查找、B树/B+树及散列查找的核心原理与实现细节。文章以动态演示为核心工具,直观展现算法执行过程与数据结构演化,帮助读者突破抽象理论难点。
-
内容核心:
-
基础算法:
-
顺序查找:从暴力遍历到哨兵优化,结合判定树分析ASL(平均查找长度),探讨有序表场景下的效率提升策略。
-
折半查找:通过二分思想与判定树模型,解析有序数据的高效检索逻辑,并给出代码实现与时间复杂度推导。
-
-
进阶索引结构:
-
分块查找:融合顺序与折半查找优势,分析块划分对效率的影响。
-
B树与B+树:从多叉查找树的平衡规则出发,动态演示插入、删除操作如何维持树结构稳定;对比B+树的特性(如叶子节点链表),阐释其在数据库索引中的核心地位。
-
-
散列查找与冲突解决:
-
详解哈希函数设计原则(如除留余数法),通过动画模拟拉链法、开放定址法、再散列法的冲突处理过程,揭示哈希表动态扩容与数据分布规律。
-
-
引言 📘
- 在这个变幻莫测、快速发展的技术时代,与时俱进是每个IT工程师的必修课。
- 我是盛透侧视攻城狮,一名什么都会一丢丢的网络安全工程师,也是众多技术社区的活跃成员以及多家大厂官方认可人员,希望能够与各位在此共同成长。

上节回顾
目录
本篇技术博文摘要 🌟
引言 📘
上节回顾
7.2数据结构与算法之查找算法题目
7.2.1题:
代码算法实现思路:
核心代码实现:
7.2.2题:
代码算法实现思路:
核心代码实现:
注意:
7.2.3题:
代码算法实现思路:
核心代码实现:
7.3.数据结构与算法之树形查找算法题
7.3.1题:
代码算法实现思路:
核心代码实现:
7.3.2题:
代码算法实现思路:
核心代码实现:
7.3.3题:
代码算法实现思路:
核心代码实现:
7.3.4题:
代码算法实现思路:
核心代码实现:
7.3.5题:
代码算法实现思路:
核心代码实现:
补充:
7.3.6题:
代码算法实现思路:
核心代码实现:
补充:
欢迎各位彦祖与热巴畅游本人专栏与技术博客
你的三连是我最大的动力
点击➡️指向的专栏名即可闪现
7.2数据结构与算法之查找算法题目
7.2.1题:
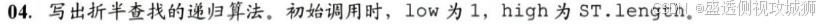
- 出折半查找的递归算法。初始调用时,low为1,high为ST.length。
代码算法实现思路:
- 根据查找的起始位置和终止位置,将查找序列一分为二,判断所查找的关键字在哪一部分,然后用新的序列的起始位置和终止位置递归求解。
核心代码实现:
typedef struct{ //查找表的数据结构
ElemType *elem; //存储空间基址,建表时按实际长度分配,0号留空
int length; //表的长度
} SSTable;
int BinSearchRec(SSTable ST, ElemType key, int low, int high){
if(low>high)
return 0;
mid=(low+high)/2; //取中间位置
if(key>ST.elem[mid]) //向后半部分查找
BinSearchRec(ST,key,mid+1,high);
else if(key<ST.elem[mid]) //向前半部分查找
BinSearchRec(ST,key,low,mid-1);
else //查找成功
return mid;
}

7.2.2题:

- 线性表中各结点的检索概率不等时,可用如下策略提高顺序检索的效率:
- 若找到指定的结点,则将该结点和其前驱结点(若存在)交换,使得经常被检索的结点尽量位于表的前端。
- 试设计在顺序结构和链式结构的线性表上实现上述策略的顺序检索算法。
代码算法实现思路:
- 检索时可先从表头开始向后顺序扫描,若找到指定的结点,则将该结点和其前趋结点(若存在)交换。
核心代码实现:
int SeqSrch(RcdType R[], ElemType k) {
//顺序查找线性表,找到后和其前面的元素交换
int i=0;
while ((R[i].key !=k) && (i<n))
i++; //从前向后顺序查找指定结点
if (i<n&&i>0) { //若找到,则交换
temp=R[i]; R[i]=R[i-1]; R[i-1]=temp;
return –i; //交换成功,返回交换后的位置
}
else return -1; //交换失败
}
注意:
- 链表方式实现的基本思想与上述思想相似,但要注意用链表实现时,在交换两个结点之前需要保存指向前一结点的指针。

7.2.3题:

代码算法实现思路:
- 从矩阵A的右上角(最右列)开始比较,若当前元素小于目标值,则向下寻找下一个更大的元素;
- 若当前元素大于目标值,则从右往左依次比较,若目标值存在,则只可能在该行中。
核心代码实现:
bool findkey(int A[][], int n, int k) {
int i=0, j=n-1;
while (i<n&&j>=0) { //离开边界时查找结束
if (A[i][j]==k) return true; //查找成功
else if (A[i][j]>k) j–; //向左移动,在该行内寻找目标值
else i++; //向下移动,查找下一个更大的元素
}
return false; //查找失败
}
- 比较次数不超过2n次,时间复杂度为O(n);空间复杂度为O(1)。

7.3.数据结构与算法之树形查找算法题
7.3.1题:
![]()
- 试编写一个算法,判断给定的二叉树是否是二叉排序树。
代码算法实现思路:
- 对二叉排序树来说,其中序遍历序列为一个递增有序序列。
- 因此,对给定的二叉树进行中序遍历,若始终能保持前一个值比后一个值小,则说明该二叉树是一棵二叉排序树。
核心代码实现:
KeyType predt=-32767; //predt 为全局变量,保存当前结点中序前驱的值,初值为-∞
int JudgeBST(BiTree bt) {
int b1,b2;
if(bt==NULL) //空树
return 1;
else{
b1=JudgeBST(bt->lchild); //判断左子树是否是二叉排序树
if(b1==0||predt>=bt->data) //若左子树返回值为 0 或前驱大于或等于当前结点
return 0; //则不是二叉排序树
predt=bt->data; //保存当前结点的关键字
b2=JudgeBST(bt->rchild); //判断右子树
return b2; //返回右子树的结果
}
}

7.3.2题:
![]()
- 设计一个算法,求出指定结点在给定二叉排序树中的层次。
代码算法实现思路:
- 设二叉树采用二叉链表存储结构。
- 在二叉排序树中,查找一次就下降一层。
- 因此,查找该结点所用的次数就是该结点在二叉排序树中的层次。
- 采用二叉排序树非递归查找算法,用n保存查找层次,每查找一次,n就加1,直到找到相应的结点。
核心代码实现:
int level(BiTree bt,BSTNode *p){
int n=0; //统计查找次数
BiTree t=bt;
if(bt!=NULL){
n++;
}
while (t->data!=p->data) {
if (p->data<t->data) //在左子树中查找
t=t->lchild;
else
t=t->rchild; //在右子树中查找
n++; //层次加 1
}
return n;
}

7.3.3题:
![]()
- 用二叉树遍历的思想编写一个判断二叉树是否是平衡二叉树的算法。
代码算法实现思路:
- 设置二叉树的平衡标记balance,以标记返回二叉树bt是否为平衡二叉树,若为平衡二叉树,则返回1,否则返回0;h为二叉树 bt 的高度。采用后序遍历的递归算法:
- 1)若 bt为空,则高度为0,balance=1。
- 2)若 bt仅有根结点,则高度为1,balance=1。
- 3)否则,对bt的左、右子树执行递归运算,返回左、右子树的高度和平衡标记,bt 的高度为最高子树的高度加1。若左、右子树的高度差大于1,则balance=0;若左、右子树的高度差小于或等于1,且左、右子树都平衡时,balance=1,否则 balance=0。
核心代码实现:
void Judge_AVL(BiTree bt, int &balance, int &h) {
int bl=0, br=0, hl=0, hr=0; //左、右子树的平衡标记和高度
if (bt==NULL) { //空树,高度为 0
h=0;
balance=1;
}
else if (bt->lchild==NULL&&bt->rchild==NULL) { //仅有根结点,则高度为 1
h=1;
balance=1;
}
else {
Judge_AVL(bt->lchild, bl, hl); //递归判断左子树
Judge_AVL(bt->rchild, br, hr); //递归判断右子树
h=(hl>hr?hl:hr)+1;
if (abs(hl-hr)<2) //若子树高度差的绝对值<2,则看左、右子树是否都平衡
balance=bl&&br; //&&为逻辑与,即左、右子树都平衡时,二叉树平衡
else
balance=0;
}
}

7.3.4题:
![]()
- 设计一个算法,求出给定二叉排序树中最小和最大的关键字。
代码算法实现思路:
- 一棵二叉排序树中,最左下结点即为关键字最小的结点,最右下结点即为关键字最大的结点,本算法只要找出这两个结点即可,而不需要比较关键字。
核心代码实现:
KeyType MinKey(BSTNode *bt) {
while (bt->lchild!=NULL)
bt=bt->lchild;
return bt->data;
}
KeyType MaxKey(BSTNode *bt) {
//求出二叉排序树中最大关键字结点
while (bt->rchild!=NULL)
bt=bt->rchild;
return bt->data;
}

7.3.5题:
![]()
- 设计一个算法,从大到小输出二叉排序树中所有值不小于k的关键字。
代码算法实现思路:
- 由二叉排序树的性质可知,右子树中所有的结点值均大于根结点值,左子树中所有的结点值均小于根结点值。
- 为了从大到小输出,先遍历右子树,再访问根结点,后遍历左子树。
核心代码实现:
void Output(BSTNode *bt, KeyType k) {
//本算法从大到小输出二叉排序树中所有值不小于k的关键字
if (bt==NULL)
return;
if (bt->rchild!=NULL)
Output(bt->rchild, k); //递归输出右子树结点
if (bt->data>=k)
printf("%d", bt->data); //只输出大于或等于k的结点值
if (bt->lchild!=NULL)
Output(bt->lchild, k); //递归输出左子树的结点
}
补充:
- 本题也可采用中序遍历加辅助栈的方法实现。
7.3.6题:

代码算法实现思路:

- 所以我们可以对左右子树的搜索采用相同的规则,
核心代码实现:
BSTNode *Search_Small(BSTNode*t, int k) {
//在以t为根的子树上寻找第k小的元素,返回其所在结点的指针。k从1开始计算
//在树结点中增加一个count数据成员,存储以该结点为根的子树的结点个数
if(k<1||k>t->count) return NULL;
if(t->lchild==NULL) {
if(k==1) return t;
else return Search_Small(t->rchild,k-1);
}
else{
if(t->lchild->count==k-1) return t;
if(t->lchild->count>k-1) return Search_Small(t->lchild,k);
if(t->lchild->count<k-1)
return Search_Small(t->rchild, k-(t->lchild->count+1));
}
}
补充:
- 最大查找长度取决于树的高度。
- 由于二叉排序树是随机生成的,其高度应是O(log2n),算法的时间复杂度为O(log2n)。


欢迎各位彦祖与热巴畅游本人专栏与技术博客
你的三连是我最大的动力
点击➡️指向的专栏名即可闪现
➡️渗透终极之红队攻击行动
➡️动画可视化数据结构与算法
➡️ 永恒之心蓝队联纵合横防御
➡️华为高级网络工程师
➡️华为高级防火墙防御集成部署
➡️ 未授权访问漏洞横向渗透利用
➡️逆向软件破解工程
➡️MYSQL REDIS 进阶实操
➡️红帽高级工程师
➡️红帽系统管理员
➡️HVV 全国各地面试题汇总






评论前必须登录!
注册