 网硕互联帮助中心
网硕互联帮助中心电脑将内存划分为静态存储区、动态存储区(如堆)、栈等不同区域,本质上是为了更高效地管理程序运行时的数据,满足不同数据的生命周期、访问方式和内存需求。这种划分是操作系统和编译器协作的结果,核心目标是提升内存利用率、保证程序运行效率,并简化开发者的内存管理工作。
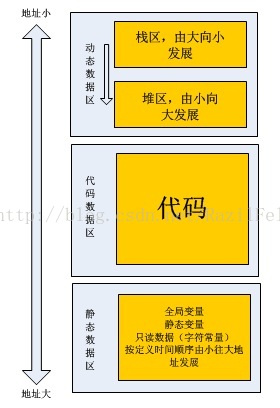
这张图展示了程序运行时内存空间的基本布局结构,主要分为三个核心区域:静态数据区、代码数据区和动态数据区。每个区域的特点、用途和内存分配方式不同,下面结合图中细节详细讲解:
程序运行就像一场“食堂就餐流程”:
-
代码区:食堂的菜单(固定不变的规则,不能随便改)。
-
静态数据区:食堂提前准备好的共享餐具(全局可用,一直存在)。
-
动态数据区:同学们排队打饭的区域——
-
栈区:固定窗口(如收米饭的窗口),排队顺序固定,吃完自动收盘(自动释放)。
-
堆区:自助餐区,想吃什么自己拿盘子装(手动申请),吃不完要自己倒掉(手动释放)。
-
核心目标:让同学理解“内存是程序运行的‘场地’,不同数据需要不同的‘活动规则’”。
一、整体布局逻辑
-
地址方向:图中左侧标注了“地址小”(上方)到“地址大”(下方),即内存地址从上到下逐渐增大(符合大多数系统的地址映射规则)。
-
区域划分:从上到下依次是 动态数据区(栈区+堆区)、代码数据区(存放程序指令)、静态数据区(存放全局数据和常量)。
二、动态数据区
最上层:动态数据区(栈区 + 堆区)——“会呼吸”的内存
动态数据区在程序运行时动态分配和释放内存,包含两个子区域,增长方向相反:
1. 栈区(Stack)—— 由大向小发展(地址递减)
-
特点:
-
自动管理:用于存储局部变量、函数参数、返回地址等,由编译器自动分配和释放(遵循“后进先出”LIFO原则)。
-
空间有限:大小通常为几MB(系统预设,如Windows默认1MB左右),过量使用会导致栈溢出(如无限递归)。
-
-
内存增长:
当函数调用时,新的栈帧(包含局部变量等)从高地址向低地址分配内存(即“由大向小”增长)。
-
示例:
void func() { int a = 10; } // 变量a在栈区分配,函数结束后自动释放
-
栈区(自动食堂窗口):
-
特点:
-
只存“短期刚需”:局部变量(如函数里的 int a)、函数调用记录(谁先吃谁后吃)。
-
自动服务:不用自己申请,用完自动清理(函数结束就收盘子)。
-
容量小但快:像食堂的快速通道,只能装少量东西(几MB),但拿取速度极快。
-
-
增长方向:
想象窗口前排队的队伍:后来的人(新函数调用)从“高地址”往“低地址”排队(因为栈顶指针向下移动),所以叫“由大向小发展”。
-
翻车案例:
如果递归太深(队伍无限长),会挤爆窗口(栈溢出),比如无限循环调用函数。
-
2. 堆区(Heap)—— 由小向大发展(地址递增)
-
特点:
-
手动管理:用于存储动态分配的内存(如通过malloc/new申请的空间),需程序员手动释放(否则导致内存泄漏)。
-
空间较大:理论上受限于系统可用内存,但分配/释放效率低于栈区。
-
-
内存增长:
当申请堆内存时,从低地址向高地址逐块分配(即“由小向大”增长)。
-
示例:
int* p = (int*)malloc(sizeof(int) * 10); // 动态分配的数组在堆区 free(p); // 需手动释放
-
堆区(自助餐区):
-
特点:
-
存“长期/变长需求”:动态分配的内存(如 malloc申请的数组)、大对象(比如图片数据)。
-
手动操作:自己申请(拿盘子)、自己释放(倒垃圾),忘了放就是“内存泄漏”(垃圾留在食堂)。
-
容量大但慢:像食堂的广阔区域,想拿多少拿多少,但找位置、收拾都麻烦。
-
-
增长方向:
盘子从“低地址”往“高地址”搬(因为每次申请都找更靠后的空位),所以叫“由小向大发展”。
-
三、代码数据区(中间)
中间层:代码数据区(只读食堂菜单)
-
特点:
-
存储程序的机器指令(代码)和只读数据,内容在编译后固定,程序运行时不可修改(只读属性)。
-
全局共享:多个程序实例共享同一份代码段,节省内存。
-
-
包含内容:
-
程序的可执行指令(如函数体对应的机器码)。
-
常量字符串(如"Hello World")、const修饰的全局常量等。
-
-
内存特性:
只读且不可修改,尝试写入会导致段错误(Segmentation Fault)。
-
特点:
-
存“不变规则”:程序的机器指令(相当于菜单上的菜名和做法)、只读数据(如 "Hello"这种固定字符串)。
-
只读保护:不能修改(菜单印错了不能直接涂改,否则食堂会报错)。
-
全局共享:所有人(所有程序实例)看同一份菜单,节省纸张(内存)。
-
四、静态数据区
最下层:静态数据区(共享餐具柜)
1. 静态数据区(Static Data Area)
-
包含内容:
-
全局变量:在函数外定义的变量(如int global_var = 10;)。
-
静态变量:用static修饰的变量(包括全局静态变量和函数内静态变量)。
-
只读数据:部分系统将字符串常量单独划分,但广义上也属于静态数据区。
-
-
特点:
-
生命周期:从程序启动到结束,不随函数调用结束而销毁。
-
内存分配:编译时确定大小,程序加载时一次性分配,按定义顺序从低地址向高地址增长(即“由小向大”发展,与图中箭头可能反向,需以逻辑为准)。
-
-
示例:
static int count = 0; // 静态变量在静态数据区 const char* str = "ABC"; // 字符串常量通常也在静态区
-
特点:
-
存“跨天保留的物品”:全局变量(整个食堂通用的餐具)、静态变量(某窗口固定留的备用碗)。
-
生命周期长:从食堂开门(程序启动)到关门(程序结束),一直占用位置。
-
分配顺序:
按“谁先定义谁先占位置”:先定义的变量放在“低地址”(餐具柜左边),后定义的放“高地址”(右边),即“由小向大发展”(注意:这里和栈区相反,是地址从小到大,别被图中的箭头方向迷惑!)。
-
五、关键对比总结
|
栈区 |
自动分配/释放 |
由大向小(递减) |
局部变量、函数参数等 |
函数调用期间有效 |
编译器自动 |
短期临时数据 |
|
堆区 |
手动申请/释放 |
由小向大(递增) |
动态分配的内存块 |
程序运行期间手动管理 |
程序员手动 |
长期使用或变长数据 |
|
代码数据区 |
编译时固定 |
— |
机器指令、只读数据 |
程序运行期间只读 |
系统固定 |
程序逻辑、常量字符串 |
|
静态数据区 |
编译时分配 |
由小向大(递增) |
全局变量、静态变量 |
程序运行期间全局有效 |
系统自动 |
跨函数持久化数据 |
六、为什么栈区向下增长,堆区向上增长?
七、思考
-
历史与效率原因:
栈和堆共享同一块动态内存空间(中间为代码区),栈从高地址向低地址分配,堆从低地址向高地址分配,两者“相向而行”,避免直接冲突,同时利用内存碎片(栈的释放是整块回收,堆需手动管理)。
-
安全性考虑:
栈的自动管理减少了内存泄漏风险,而堆的手动管理赋予了灵活性,但也增加了出错可能。
-
为什么栈区不能存很大的数组?堆区可以吗?
-
“如果把全局变量放在栈区会怎样






评论前必须登录!
注册