 网硕互联帮助中心
网硕互联帮助中心目录
昨日总结
今日计划
JVM
数据库——索引
索引语法
SQL性能分析
慢查询日志
索引的使用原则(满足最左前缀法则)
索引的设计原则
昨日八股答案
今日八股
总结编辑
昨日总结
- JVM底层原理学习,mysql进阶篇——索引
- cv(停滞中)
- 小林coding–Spring面试篇(1/7)
- 代码随想录——从中序与后序遍历序列构造二叉树
今日计划
- JVM底层原理学习,学习mysql进阶篇
- cv(停滞中)
- 小林coding–Spring面试篇(2/7)
- 码随想录——最大二叉树
JVM
- 在创建对象过程中,三者的关系如下
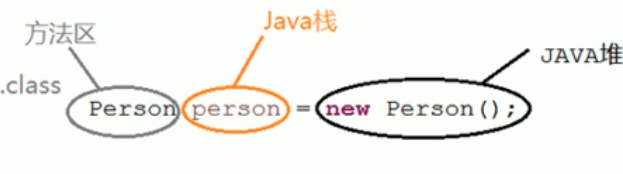
- 方法区的大小可以固定也可以扩展
- jdk8以前,本质上,方法区和永久代并不等价。jdk8以后,废弃了永久代概念,用内存中元空间替代 。永久代和元空间并不只是名字变了,内存结构也调整了
- 元空间不在虚拟机设置的内存中,而是使用本地内存
- 方法区存储JVM加载的类型信息、常量、静态变量、方法信息(名称和参数和方法的字节码,操作数栈等等),以及编译器编译后的代码缓存 等。
- 方法区中为什么要常量池呢。如果将一个程序中的代码全部存储到字节码文件中,他的大小会非常的大。如果代码多,引用到的结构会更多。因此,可以将一些
代码规划到常量池中,如果用到,从常量池中调编号来使用
数据库——索引
- 索引是帮助mysql高效获取数据的数据结构,维护着满足特定查找算法的数据结构,这种结构以某种方式引用数据。
- 索引的优缺点,如下

- InnoDB存储引擎的索引采用的是B+树的结构,与数据结构的B+树不同,他的叶子结点是双向的,提高区间访问的性能。(树中非叶子结点仅起到索引的作用,不存储数据。数据存储在叶子节点上)如下图
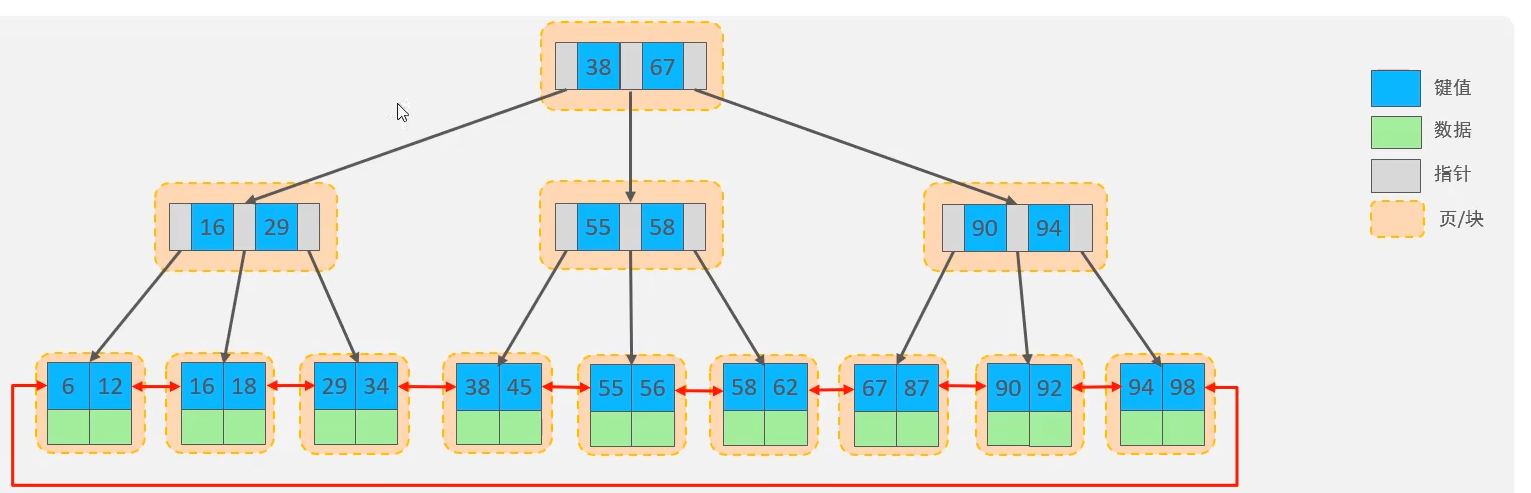
- 哈希索引:基于哈希算法,处理冲突的方式采用链表解决。其查询效率高。但无法利用索引完成排序操作,hash索引不支持范围匹配,只支持等值匹配。InnoDB中具有自适应hash功能
- 索引的分类,如下图

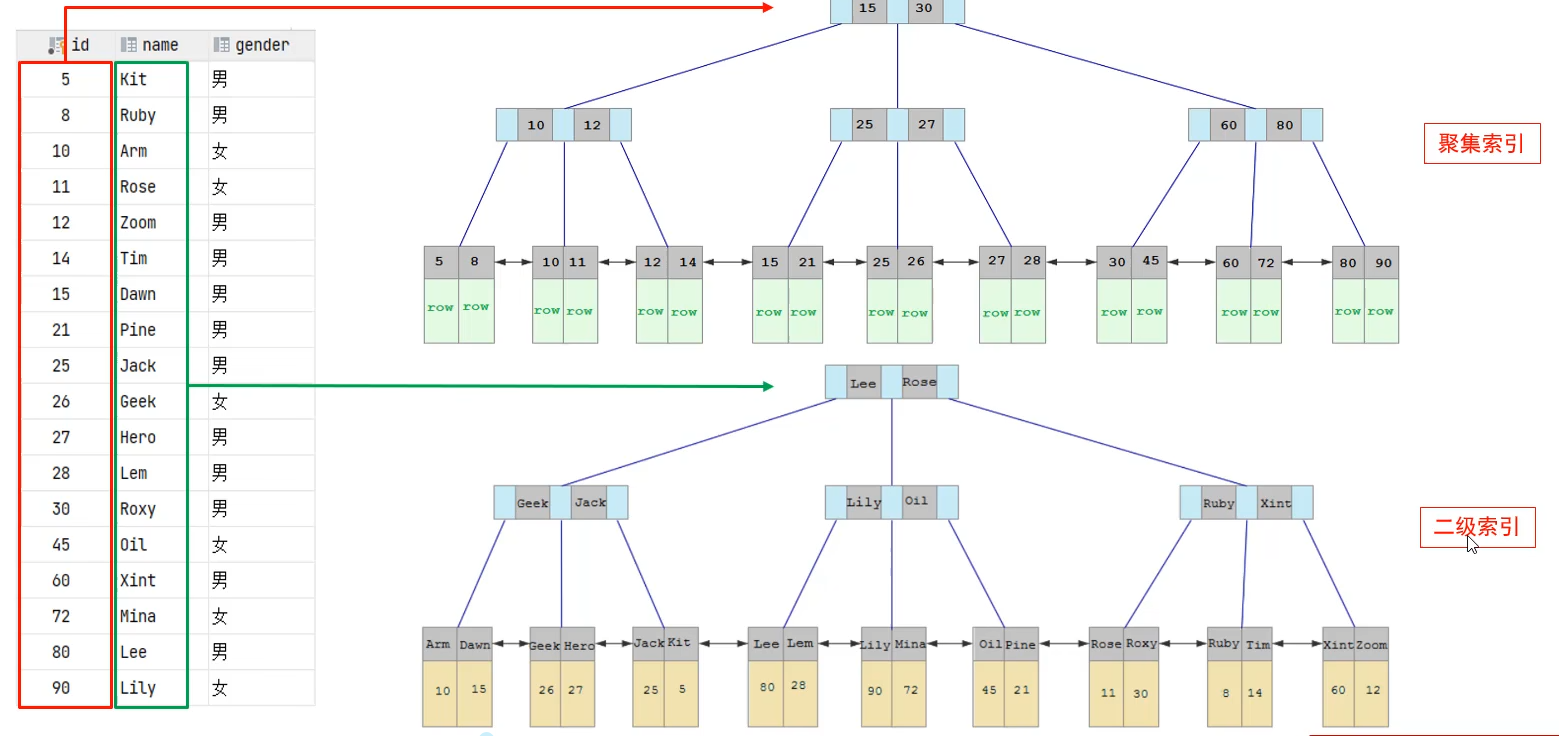
- 根据索引的存储形式,又可以分为聚集索引和二级索引

索引语法
- 创建索引
CREATE 【UNIQUE|FULLTEXT】 INDEX index_name ON table_name (idnex_col_name,…)
- 查看索引
SHOW INDEX FROM table_name;
- 删除索引
DROP INDEX index_name ON table_name;
SQL性能分析
通过以下指令来查询当前数据库的访问频次
SHOW GLOBAL STATUS LIKE '表名' 用_表示匹配字符
慢查询日志
记录了所有执行时间超过指定参数的所有SQL语句的日志。
慢查询日志的文件在/var/lib/mysql中,里面有一个localhost-slow.log文件,里面记录着慢查询的信息
可用以下指令查询每条指令的耗时情况
show profiles;
通过执行时间判断SQL的执行性能,执行时间长,说明执行性能高;执行时间长,说明执行性能低。(粗略的去判定)
也可用采用explain执行计划查询性能(用到的时候再去查就行),其中参数解释如下
- Id:查询的序列号,id相同,执行顺序从上到下;id不同,值越大,越先执行。
- select_type:表示select的类型(不重要)
- type:表示连接的类型,性能由好到差类型为(NULL,system,const,eq_ref,ref,range,index,all),类型优化最好保持在前面
- rows:MYSQL认为要执行的行数,早InnoDB中是个估计值
- filtered:表示返回结果的行数占需读取行数的百分比,值越大越好
- possible_key:可能用到的索引
- key:实际用到的索引
- key_len:索引用到的长度
索引的使用原则(满足最左前缀法则)
使用索引去查询记录会大大加快查询速度
1.在索引中,如果引用了多列索引,最左侧的列要存在,一旦没有出现,就会按全表扫描,不会走索引扫描。
2.如果最左侧索引字段存在,中间部分不存在,后面的索引字段也会失效。
3.如果中间索引字段采用了范围查询,该字段后面的索引字段会失效(如果采用>=或<=的话会生效)。
4.不要在索引列上进行运算操作,索引将失效
5.字符串类型字段使用时,如果不加引号,索引将会失效
6.如果仅仅是尾部模糊匹配,索引不会失效,如果是头部模糊匹配,索引失效(如果在大规模的查询下,要规避头部模糊扫描)
7.如果or连接的两个条件,其中一个条件没有索引,则涉及的索引都不会生效
8.数据分布影响:如果MySQL评估使用索引比全表更慢,则不使用索引
9.SQL提示:在多个索引(存在单列索引和联合索引)情况下,自己可以规定根据哪个索引来查询。简单来说就是在SQL语句中加入一些人为的提示来达到优化操作的目的
10.注意要避免使用select * 查询所有字段操作,因为容易触发回表查询情况,影响性能,解决方案是可以采用联合索引,覆盖查询是不需要回表的
索引的设计原则
昨日八股答案
- 谈谈对Spring的理解
Spring作为一个轻量级的java开发框架,通过Ioc(控制反转)和AOP(面相切面编程)两大特性,解决了开发中组件耦合度高,配置复杂等问题。同时,还包含了Web应用开发Spring MVC、微服务架构Spring Cloud、一致的事务管理接口以及集成了多种消息队列框架等技术。
在Spring框架中,IOC和AOP的结合使用,可以更好的实现代码的模块化和分层管理
- Spring IOC 和AOP的理解
IOC:传统的程序设计中,对象的创建和依赖关系的管理是由程序代码直接控制的,在IOC模式下,这些控制交给了Spring容器。通过依赖注入(DI)实现控制反转。将对象的依赖关系通过外部注入的方式提供给对象,被Spring容易管理的对象称为Bean。这样可以降低组件之间的耦合度,提高代码的可维护性和可测试性。
AOP:是对面向对象编程(OOP)的补充,允许在不修改原有业务逻辑的基础上,进行增强。通过定义切面(Aspect)、切点(Pointcut)和通知(Advice)来实现。切面是一个包含了多个通知和切点的模块,切点定义了哪些方法会被增强,通知则定义了在何时(如方法执行前、后)执行增强逻辑。
- IOC和AOP是通过什么机制来实现的
IOC:
反射:利用反射机制来动态的加载类、创建对象实例以及调用对象方法
DI:IOC的狠心概念是依赖注入,负责管理组件之间的依赖关系
IOC容器:是实现IOC的核心
AOP:
AOP的实现依赖于动态代理技术。动态代理是在运行时动态生成代理对象。主要有两种:基于JDK的动态代理,基于CGLIB的动态代理
- 依赖注入的了解
传统创建对象中,需要在类内部new来创建依赖对象,使得类与类之间的耦合度较高
而依赖注入则是将对象的创建和依赖关系的管理交给Srping容器来完成,类只需要声明自己所依赖的对象,从而降低了耦合度。
今日八股
-
动态代理是什么
-
动态代理和静态代理的区别
-
AOP实现有哪些注解
-
什么是反射





评论前必须登录!
注册