 网硕互联帮助中心
网硕互联帮助中心🚀 AI 史上最大升级来了! 2025 年 8 月 8 日凌晨,OpenAI 发布了 GPT-5 —— 这不只是一次版本更新,而是一次架构革命。 智能路由 + 多模型融合,推理更强、速度更快、幻觉更少,上下文可达 256k tokens,还能精细控制推理力度与回答详尽度。 微软、医疗、编程、内容创作……它已开始渗透每一个行业。

本文为你全景解读 GPT-5 的技术细节、性能对比、真实应用与未来趋势,一篇读懂新一代 AI 的全部变化。
GPT-5 发布全解读:参数升级、长上下文与多领域能力提升
—— 一篇面向开发者与行业从业者的深度长文
一、引言:AI 发展的新里程碑
2025 年 8 月(北京时间8月8日凌晨1点),OpenAI 发布了最新旗舰模型 GPT-5。这不仅是一个迭代更新,而是一次体系级的升级: 它将此前分散的 GPT-4o、o3、o4-mini、GPT-4.1 等能力整合进一个统一的路由系统,让普通用户无需关心模型版本选择,而专业用户则能通过 API 精细控制推理深度、回答详尽度、工具调用等参数。
正如 OpenAI首席执行官萨姆·奥尔特曼称,:
GPT-5是“世界上最好的模型”,代表着OpenAI在开发通用人工智能 (AGI) 道路上迈出了“重要一步”。
这意味着,它不仅仅是更聪明的对话机器人,更是多领域任务的自动专家调度系统。
二、GPT-5 核心技术解析
2.1 架构:Mixture of Models + 智能路由
GPT-5 不再是单一模型,而是一个“多模型混合系统”(Mixture of Models,MoM),核心由**智能路由器(Router)**驱动。
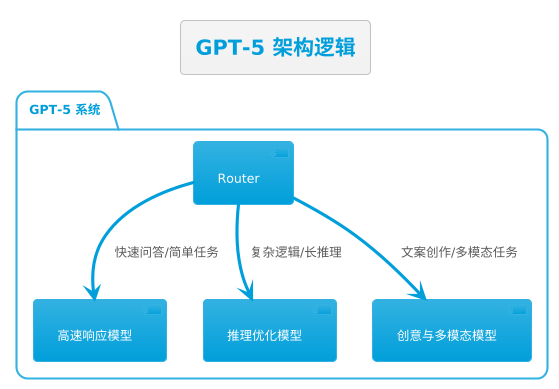
特点:
- 动态路由:根据用户输入自动分配最优子模型。
- 混合策略:简单任务走轻量路径,复杂任务切换到高推理能力模型。
- 对用户透明:普通用户无感知,但享受更优性能。
2.2 API 新参数
GPT-5 在 API 层新增了两个重要可控参数:
| verbosity | 枚举 | 控制回答详尽度(low / medium / high) |
| reasoning_effort | 枚举 | 控制推理深度(minimal / medium / high) |
示例:
{
"model": "gpt-5",
"input": "分析以下财务报表…",
"verbosity": "high",
"reasoning_effort": "high"
}
意义:
- 开发者可精准控制成本与性能平衡。
- 复杂任务(如编程调试、财务分析)可选择更高推理力度。
2.3 上下文长度扩展
- GPT-4.1 支持百万 tokens(部分场景)。
- GPT-5 支持 256k tokens 长上下文,可处理整本书级别的内容。
优势:
- 法律合同全局分析
- 大规模代码库理解
- 长篇论文或技术文档对话
2.4 推理与工具调用优化
在 SWE-bench Verified 测试中:
- GPT-5 准确率 74.9%,较 o3 提升 ~5.8%。
- 输出 token 减少 22%,工具调用次数减少 45%,效率大幅提升。
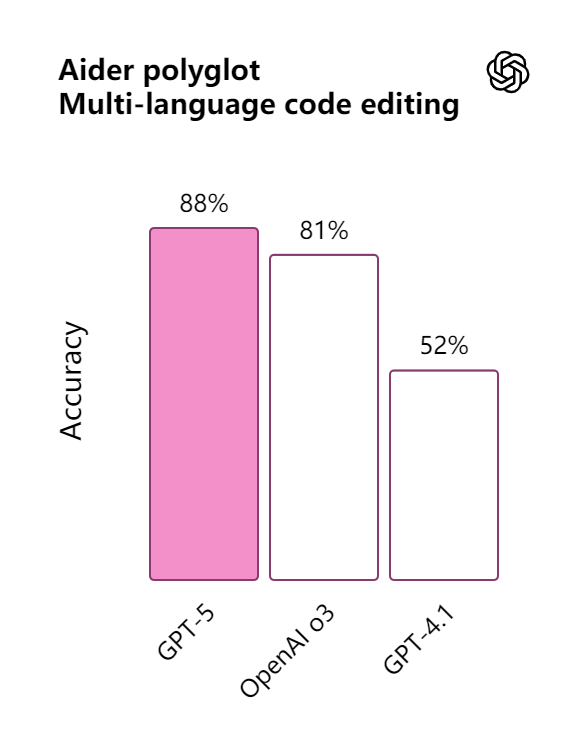
在 Aider Polyglot 测试中:
- GPT-5 准确率 88%,错误率减少约三分之一。
三、性能与基准测试对比
3.1 GPT迭代进程

3.2 GPT-4 / 4o / 4.1 与 GPT-5 全维度对比
| 架构 | 单模型 / MoE | 长上下文、多模态 | 智能路由 + 多模型融合 |
| 编码能力 | 优秀 | 更强 | 基准测试领先,工具调用精准 |
| 上下文长度 | 8k~128k | 最高 1M | 256k tokens 稳定支持 |
| 用户体验 | 手动切换模型 | 略简化 | 自动选择最优路径 |
| API 参数 | 无 | 少量可调 | verbosity / reasoning_effort 完整支持 |
| 性能优化 | 中等 | 高 | 更快、更准、更少幻觉 |
3.1 核心性能对比表
- 对比
| SWE-bench Verified | 65% | 69.1% | 74.9% |
| Aider Polyglot | 78% | 85% | 88% |
| τ²-bench(工具链能力) | 90% | 94% | 97% |
| 上下文长度 | 128k | 1M* | 256k |
| 事实性(可信度) | 中 | 高 | 最高 |
3.2 能力测评
SWE-bench Verified
链接:https://openai.com/index/introducing-swe-bench-verified
在 SWE-bench Verified 基准测试中,模型会获得代码仓库和问题描述,并需要生成补丁来解决问题。文本标签用于标识推理强度。我们的评分排除了 500 个问题中的 23 个,因其解决方案在我们的测试环境中无法稳定通过。GPT‑5 收到一个简短的提示,强调要彻底验证解决方案;而相同的提示对 o3 没有帮助。 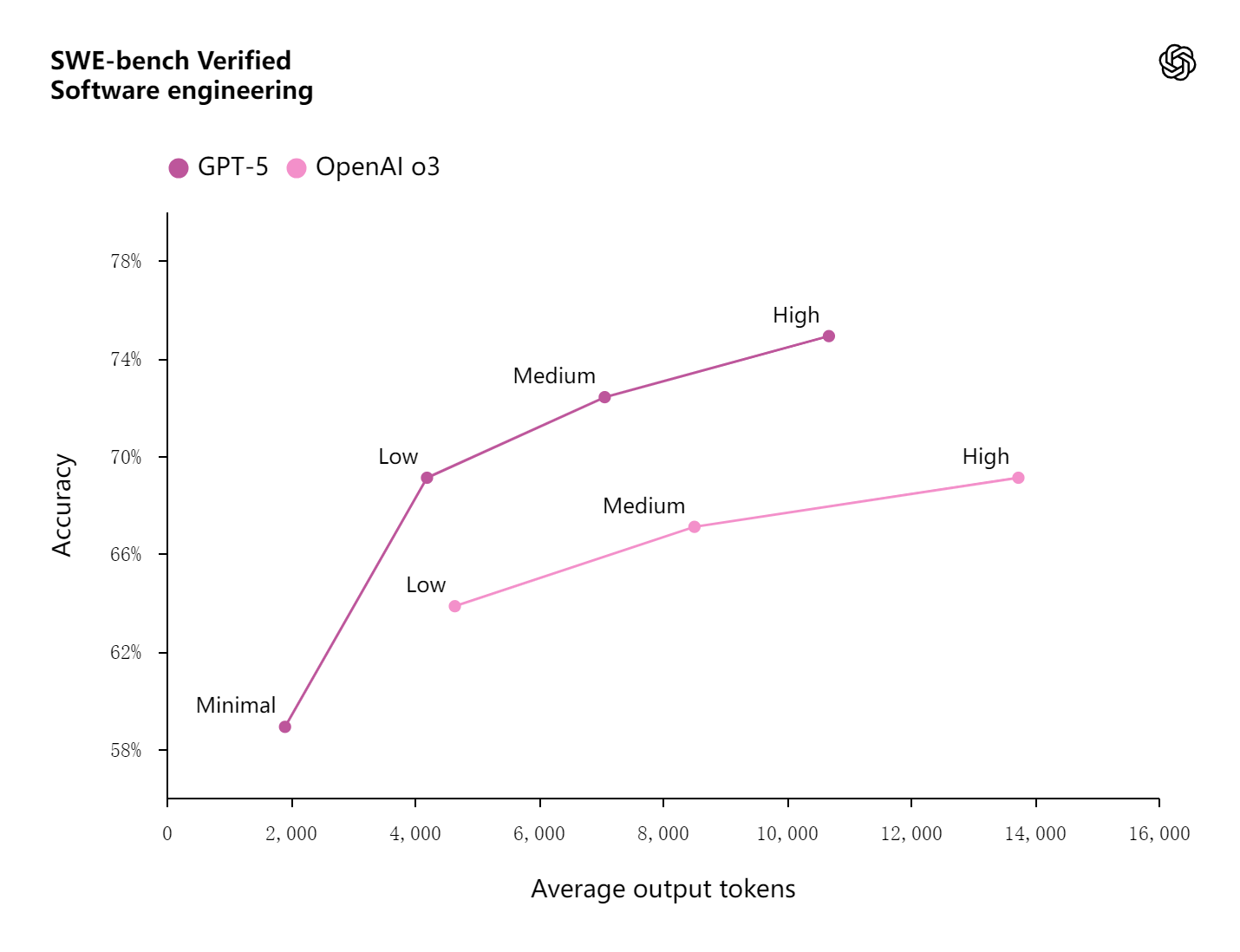
Aider polyglot
在评估代码编辑能力的 Aider polyglot 测试中,GPT‑5 以88% 的得分刷新纪录,其错误率较 o3 版本降低了三分之二。
链接:https://aider.chat/2024/12/21/polyglot.html#the-polyglot-benchmark
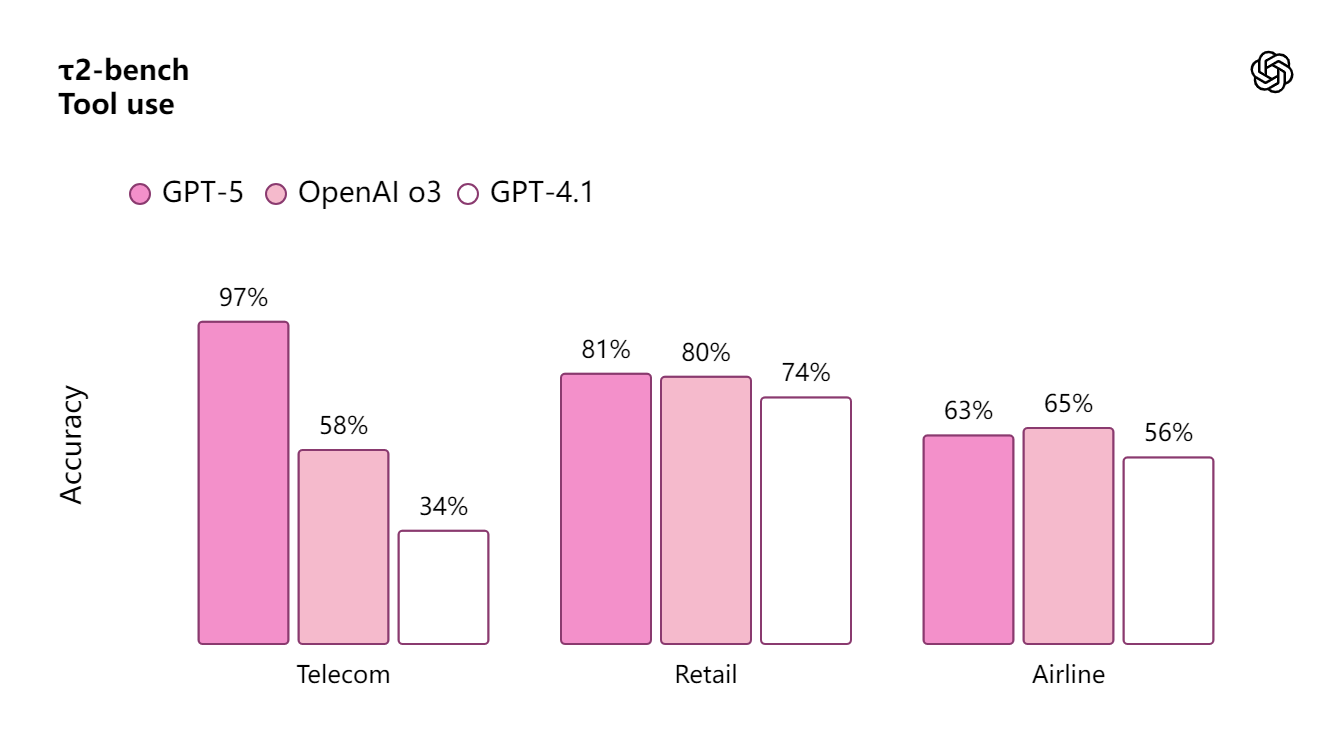
τ2-bench
两个月前,Sierra.ai 发布了τ2-bench telecom 测试基准,该基准作为高难度工具使用评估体系,重点揭示了语言模型在用户可变更环境状态下的性能显著衰减现象。根据其发布报告(在新窗口中打开),所有参评模型的得分均未超过 49%。而 GPT‑5 的得分为 97%。
链接:https://arxiv.org/pdf/2506.07982
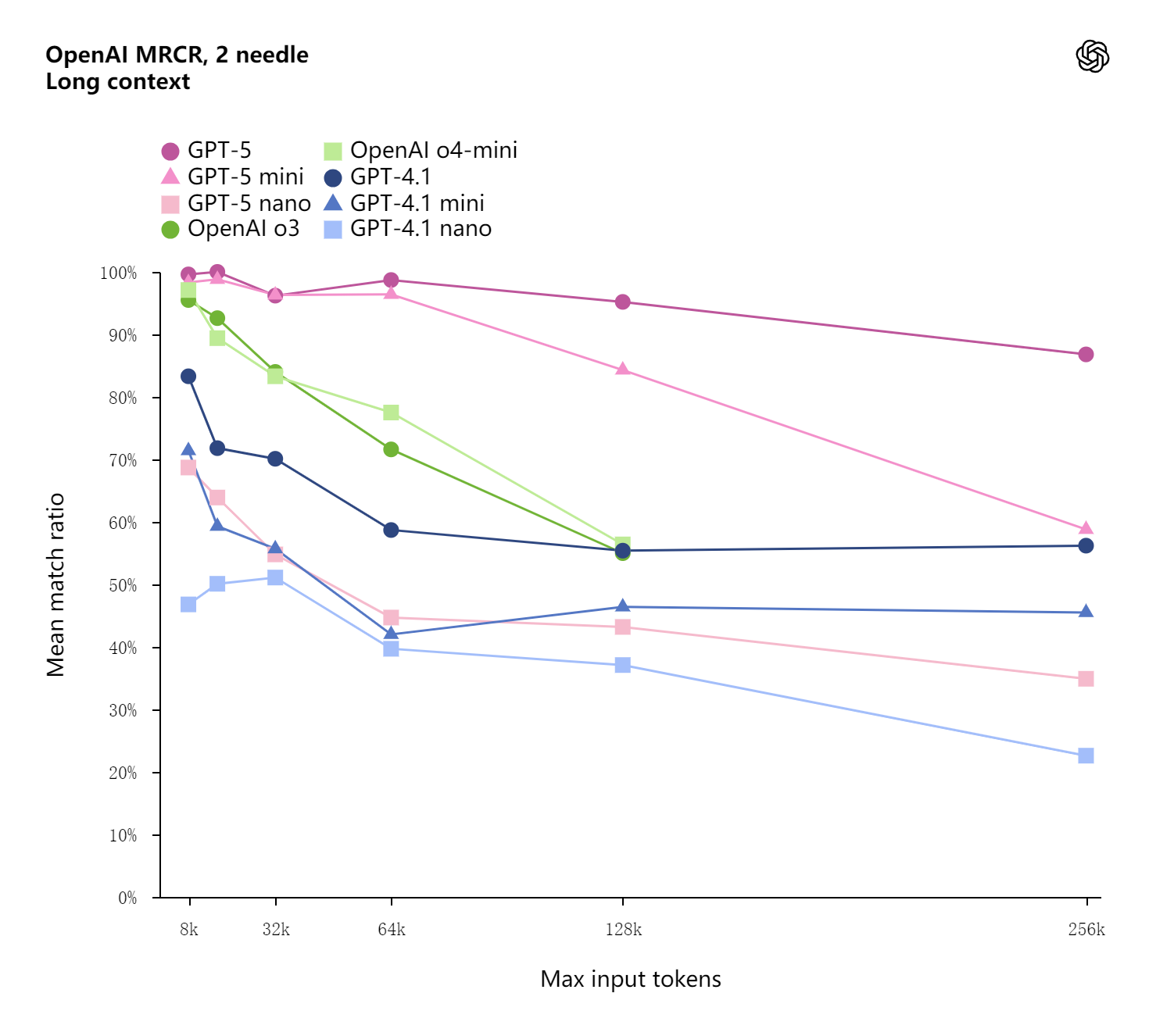
上下文长度
GPT‑5 在长背景信息性能方面也展现出显著提升。在 OpenAI-MRCR(一种衡量长背景信息检索能力的指标)中,GPT‑5 的表现优于 o3 和 GPT‑4.1,且随着输入长度的增加,这种优势会显著扩大。
在 OpenAI-MRCR(多轮共指解析)(https://huggingface.co/datasets/openai/mrcr)中,多个相同的“针”用户请求被插入到由相似请求和响应组成的长“草堆”中,模型被要求重现第 i 个“针”的响应。平均匹配比率衡量模型回复与正确答案之间的平均字符串匹配比率。在 256k 最大输入令牌处的数据点代表 128k 至 256k 输入令牌范围内的平均值,依此类推。这里,256k 代表 256 × 1,024 = 262,114 个令牌。推理模型在高推理强度下运行。
在 API 中,所有 GPT‑5 模型最多可接受 272,000 个输入令牌,并生成最多 128,000 个推理及输出令牌,总上下文长度为 400,000 个令牌。
事实性
GPT‑5 比我们之前的模型更值得信赖。在 LongFact 和 FactScore 基准测试的提示下,GPT‑5 的事实错误率比 o3 低约 80%。这使得 GPT‑5 尤其适用于正确性要求高的智能体任务场景,特别是在代码生成、数据处理和决策支持等关键领域。 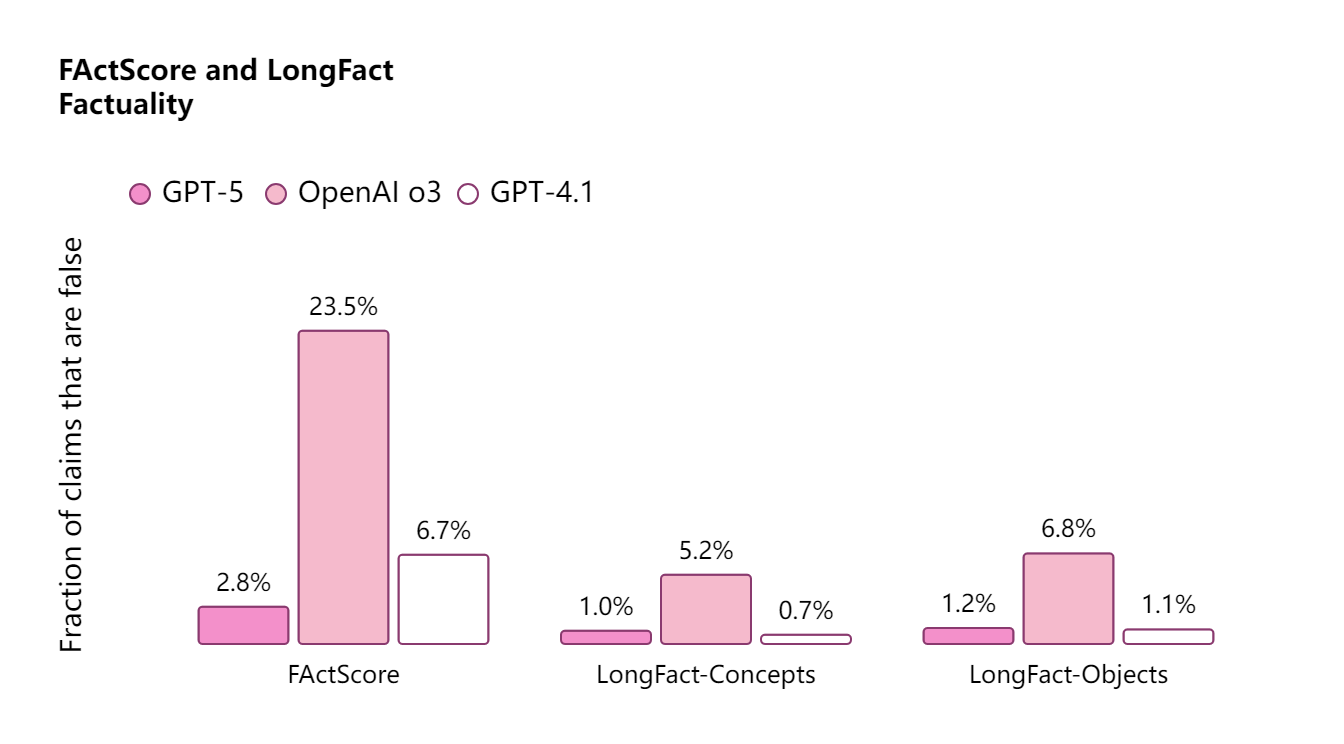
五、GPT-5 的实际应用与影响
从最顶级的企业产品到普通用户的日常体验,GPT-5 正在引领一场从“技术演示”到“真实赋能”的变革。在微软生态系统中,GPT-5 已整合并渗透到 Microsoft 365 Copilot、GitHub Copilot、Azure AI Foundry 等服务,带来推理更强、对话更连贯、工具调用更精准的协作体验,开发者如今可以在 Visual Studio Code 内直接享受 GPT-5 的强大编码与调试能力,不再经历版本跳转的困扰 (Source, The Economic Times)。
在医疗领域,Sam Altman 明确指出,GPT-5 为普通用户提供更可靠的健康信息和建议工具,将健康从“搜索”变为“理解与参与”,让用户以更理性的方式面对诊断与治疗选择 (Fierce Healthcare)。此外,GPT-5 在功能安全性上的优化,使其在应对敏感医疗、法律等场景时,降低幻觉率、提升准确度,在行业内赢得了更广泛的信任。
自由用户也能直接受益。GPT-5 的轻量版本(mini/nano)已面向免费帐户开放,并提供与 Plus、Pro 用户几乎一致的写作、语音、Gmail 与 Google Calendar 集成等功能,例如“ChatGPT Voice”声音模式升级、更自然的人声表达、界面配色自定义等 —— 这些都让普通用户的互动体验更具个性化与实用性 (Tom’s Guide, TechRadar)。
在市场层面,GPT-5 的发布引发广泛讨论。许多媒体将其定义为 AI 从“实验室玩具”迈向“产品级工具”的关键一步,并称其“就像从普通屏幕进化到 Retina 显示” (WIRED)。与此同时,印度媒体指出,随着 GPT-5 在印度市场的迅速普及,印度有望成为全球最大的 AI 市场之一,这也标志着 GPT-5 在全球扩展上的战略价值 (Navbharat Times, The Economic Times)。至于技术界的对抗性讨论,Elon Musk 关于“OpenAI 会将微软吃掉”的言论与 Satya Nadella 冷静回应的新闻也凸显出 GPT-5 发布在产业层面的深远震动 (The Times of India, 金融快报, The Economic Times)。
最终,无论是企业、开发者,还是普通用户,GPT-5 的出现都大幅降低了使用门槛,提高了实用性与可访问性,这种从“高门槛高性能”向“高性能零门槛”的转化,预示着 AI 正逐渐成为更广泛、更深入的生产力工具。
六、未来展望
架构演进、定制化发展与 AGI 路径
GPT-5 已经不是简单的迭代,而是一次架构理念的跃变——从“单模型”向“多模型协作 + 智能路由”转型。基于 GPT-5 架构的成功演绎,未来可预见如下几大趋势:
-
构建自适应推理系统 当前的 reasoning_effort 虽然有力,但仍需导入明确控制指令;未来模型可能会更智能地自动判断任务难度并自调理应深度,真正实现“智能推理力度匹配”。
-
增强多模态协同能力 GPT-5 已展示了文字、图像、声音集成的雏形,未来若能进一步加入视频、3D、甚至实时感知,将真正满足元宇宙时代交互需求。
-
个性化与定制化正式起航 目前 GPT-5 在 GUI 上提供了“个性化角色选择(如 Cynic、Robot 等)”,未来这种人格化交互将进一步精细化,用户可为 AI 定义语气、风格、推理节奏,使其“像一个长期伙伴”。
-
向 AGI 的路径更清晰 尽管目前仍不足以称作 AGI,GPT-5 的“统一系统性能 + 广泛通用能力”已具备强大的通用性,将成为通向真正高度自治 AI 的重要铺垫。
从技术到产品体验再到应用落地,GPT-5 无疑是一个里程碑。它所勾勒的未来,强调的是“AI 的亲和化普及 + 智能化强大”,而这必将引导行业在后 GPT-5 时代走得更快、更深、更广。 转折点。它代表了未来 AI 从“一个模型”向“多模型协作平台”的演进趋势,为开发者与企业提供了更高的生产力工具。
无论你是普通用户、程序员、还是企业决策者,GPT-5 都意味着更低的使用门槛、更高的性能与更广的应用空间。
七、参考文章
- GPT-5 is meant for the casual user, not the advanced user. Here’s why that’s an upgrade.
- GPT-5 vs GPT-4: Here’s what’s different (and what’s not) in ChatGPT’s latest upgrade
- OpenAI unveils GPT-5, free for all with usage limits
- OpenAI GPT-5 release: technical overview for developers
- OpenAI announces GPT-5: new era of AI work
- Reddit: I vastly prefer GPT-5 over 4o
- τ2-Bench: Evaluating Conversational Agents in aDual-Control Environment





评论前必须登录!
注册