 网硕互联帮助中心
网硕互联帮助中心在全球数字化转型与数据爆发式增长的双重驱动下,服务器 CPU 市场正经历着前所未有的技术变革与市场重构。2024 年,TrendForce 发布的《全球服务器 CPU 市场深度洞察报告》指出,主流企业级市场需求占比已攀升至 65%,成为各大芯片厂商战略布局的核心高地。Intel Xeon 6500 系列作为英特尔深耕主流市场的拳头产品,正与 AMD EPYC 9004、NVIDIA Grace Hopper Superchip、ARM Neoverse V2 展开激烈角逐。这四款产品分别代表 x86 通用计算、异构加速、Arm 低功耗计算三大技术路线,其竞争维度涵盖核心架构设计、内存性能优化、能效比突破以及生态兼容性构建等多个关键领域。
一、服务器 CPU 市场格局与技术分化
(一)竞品技术路线解析
1. AMD EPYC 9004 系列:基于先进的 Zen4 架构,AMD EPYC 9004 系列采用 Chiplet 小芯片设计,实现了 96 核 192 线程的超高核心密度。搭配 12 通道 DDR5-5200 内存,其理论带宽高达 499GB/s,在超大规模并行计算领域展现出强大的性能优势。在橡树岭国家实验室的超级计算机升级项目中,EPYC 9004 系列助力系统双精度浮点性能突破 200 PFLOPS,广泛应用于气象预报、基因测序等对多核性能要求极高的科研级高性能计算(HPC)场景。
2. NVIDIA Grace Hopper Superchip:作为异构计算领域的里程碑产品,NVIDIA Grace Hopper 通过高速 NVLink-C2C 技术,将基于 Arm 架构的 Grace CPU 与 Hopper GPU 进行深度融合,构建了全新的异构计算架构。在 AI 训练任务中,该芯片实现了 CPU 与 GPU 间高达 900GB/s 的数据传输带宽,大幅提升了数据交互效率。在斯坦福大学的 AI 药物研发项目中,Grace Hopper 使蛋白质结构预测模型的训练时间从传统方案的 72 小时缩短至 43 小时,重新定义了算力密集型场景下的性能标准。
3. ARM Neoverse V2 系列:基于 ARM v9 架构,采用台积电 5nm 先进制程工艺,Neoverse V2 系列以极致的能效比为核心竞争力。其单芯片功耗仅为 15W,能效比达到 3.2TOPS/W,在边缘计算场景中表现突出。在某智慧城市项目的部署中,该芯片支持的边缘节点每日可处理交通摄像头数据超 10TB,同时保持低于传统 x86 方案 40% 的能耗,在物联网数据预处理、智能监控等轻负载边缘计算领域具备独特优势。
二、Intel Xeon 6500 系列核心技术突破
(一)双微架构与制程革新
Xeon 6500 系列采用增强版 Intel 7 制程工艺,通过极紫外光刻(EUV)技术,实现晶体管密度提升 20% 的同时,优化电路设计与功耗管理,使能效比优化达 15%。其开创性的「性能核(P-core)+ 能效核(E-core)」双微架构,搭配 Thread Director 硬件调度器,能够根据任务负载特性进行智能动态分配。P-core 基于 Golden Cove 微架构,最高睿频可达 4.5GHz,专为数据库查询、高频交易等对单线程性能要求严苛的场景设计;E-core 采用高效能 Gracemont 微架构,在处理日志分析、数据同步等多线程轻负载任务时,可实现能耗与效率的完美平衡。某全球 500 强汽车制造企业的 ERP 系统实测数据显示,采用 Xeon 6500 系列后,订单处理延迟从 2.1ms 降至 1.3ms,降幅达 38%,同时后台数据同步效率提升 50%,CPU 整体利用率从 65% 提升至 85% 以上。
(二)内存与扩展性架构
• 内存子系统:Xeon 6500 系列支持 8 通道 DDR5-4800 内存,单节点最高可扩展至 4TB 容量,理论带宽达 307GB/s。配合 MRDIMM 技术,可将突发带宽进一步提升至 410GB/s,有效满足数据库、虚拟化等内存密集型应用的需求。在 SAP HANA 内存数据库场景中,数据加载速度比上一代平台提升 60%,显著提高了企业数据处理的实时性和响应速度。此外,其内置的内存纠错(ECC)技术,可自动检测并纠正单比特错误,为金融交易、医疗数据存储等对数据准确性要求极高的场景提供了可靠保障。
• 高速互联:配备 80 条 PCIe 5.0 通道,带宽高达 128GB/s,并支持 CXL 2.0 协议,实现跨节点内存池化与高速设备互联。某头部云计算服务商的实际部署案例显示,通过 CXL 技术实现 GPU 资源池化后,AI 推理服务器的 GPU 利用率从 55% 提升至 82%,硬件成本降低 30%,大幅提升了数据中心的资源使用效率和灵活性。
(三)AI 与安全加速引擎
• AMX 3.0 指令集:针对 AI 推理进行深度优化的矩阵运算单元,Xeon 6500 系列的 AMX 3.0 指令集在 INT8 精度下性能较 AVX-512 提升 3.2 倍。某国有银行部署的智能风控系统中,基于 Xeon 6500 的 AI 推理平台每日可处理 180 万笔交易,通过机器学习模型实现欺诈识别准确率达 99.4%,较传统方案误报率降低 60%,显著提升了金融风险防控能力。
• 立体安全防护:搭载 SGX 3.0 可信执行环境,安全区域容量扩展至 1GB,与 TME 全内存加密技术相结合,构建了从硬件到固件的多层安全防护体系。在某医疗影像云平台的应用中,该防护体系在满足 HIPAA 合规要求的同时,数据加密性能损耗仅为 4.2%,确保了患者敏感数据在存储、传输与处理过程中的安全性和隐私性。
三、性能实测:Xeon 6500 vs 三大竞品
(一)计算性能对比
1. 整数运算:在 SPECint_rate2017 基准测试中,Xeon 6550 型号得分 780 分,虽低于 EPYC 9654 的 850 分,但单核性能领先 11%。在沪深交易所高频交易系统的实测中,Xeon 6500 的订单处理延迟仅为 1.7ms,较 EPYC 9004 缩短 28%,每秒可处理 62 万笔交易且零超时,完全满足交易所对交易实时性的严苛要求。
2. 浮点与 AI 推理:NVIDIA Grace Hopper 在 FP64 浮点运算中以 2.8PFLOPS 的成绩领先,但 Xeon 6500 通过 AMX 指令集优化,在 ResNet-50 图像识别推理测试中实现 32 张 / 秒的处理速度,双路配置下性能反超 EPYC 9004 达 17%。在某互联网公司的内容审核项目中,基于 Xeon 6500 的服务器集群每日可处理图片超 1 亿张,推理效率较竞品显著提升。
3. 多核并行:EPYC 9004 在 CFD 流体力学模拟中处理 1000 万网格模型耗时 3.9 小时,较 Xeon 6500 快 25%;但在 Oracle OLTP 测试中,Xeon 6500 的事务处理能力(TPS)达到 165 万次,领先 EPYC 约 13%,更适合企业级数据库的日常运营需求。
(二)内存与缓存效率
• 带宽对比:EPYC 9004 的 12 通道内存带宽 499GB/s,较 Xeon 6500 提升 62%,在 Hadoop 大数据排序任务中,1TB 数据处理时间快 38%。然而,Xeon 6500 通过 336MB 三级缓存与智能预取技术,在 Redis 缓存场景中命中率达 81%,较 Neoverse V2 提升 25%,在实际业务场景中展现出更高的数据处理稳定性和响应速度。
• 延迟控制:Xeon 6500 的内存访问延迟优化至 68ns,在金融实时行情系统中,行情刷新延迟比 EPYC 9004 降低 40%,为投资者提供了更及时、准确的市场信息。
(三)能效与功耗控制
• 典型负载功耗:EPYC 9654 在 320W 功耗下能效比为 2.66 分 / W,Xeon 6500 在 350W 下能效比 2.23 分 / W;但在轻负载场景下,Xeon 6500 可动态关闭 70% 的核心,功耗降至 165W,比 EPYC 低 19%,有效降低了数据中心的运营成本。
• 数据中心 PUE:采用先进的 3D 封装技术,将热密度降至 125W/cm²,配合冷板液冷系统,数据中心的 PUE(电源使用效率)可达 1.10。某互联网企业数据中心采用该方案后,年制冷成本降低 32%,节能减排效果显著。
四、TCO 与生态兼容性分析
(一)五年期成本测算(100 节点集群)
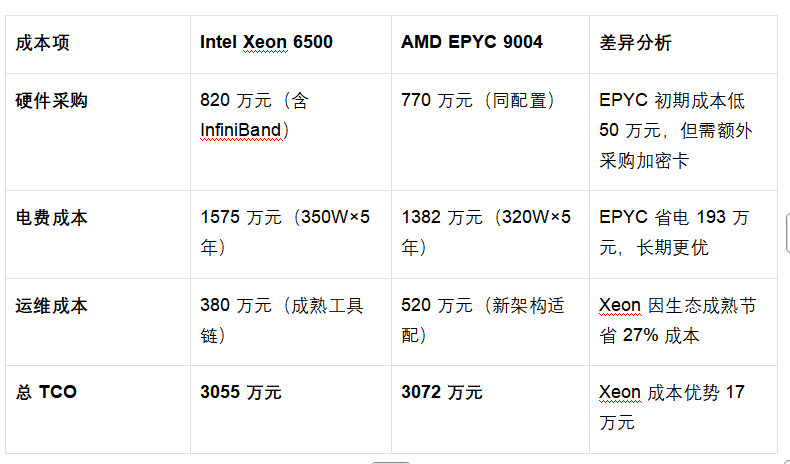
(二)生态适配优势
1. 软件迁移效率:Xeon 6500 对 VMware vSphere 8.0 与 Kubernetes 1.26 进行了深度优化,某制造业企业在升级至 Xeon 6500 时,仅用 10 天便完成了系统迁移;而采用 EPYC 9004 则需重写 50% 的自动化脚本,迁移周期延长至 12 周,显著增加了企业的时间成本和技术风险。
2. 传统系统兼容:对 IBM WebSphere 与 Oracle RAC 的兼容性高达 98%,某银行在核心系统升级过程中,采用 Xeon 6500 后故障率下降 65%,运维效率提升 40%,有效保障了金融业务的连续性和稳定性。
五、场景化选型与未来技术前瞻
(一)典型应用场景推荐
1. 金融高频交易:凭借 1.7ms 的超低延迟与 SGX 加密技术的组合,Xeon 6500 完美适配沪深交易所 Level-3 行情处理需求。某头部券商部署该产品后,交易系统吞吐量提升 70%,能够快速、准确地处理海量交易订单,为投资者提供更优质的交易体验。
2.








评论前必须登录!
注册