 网硕互联帮助中心
网硕互联帮助中心前言
最近给一家集团公司部署本地大模型,便写下本文记录一下企业级生产环境部署大模型的全过程。
整体服务器配置如下:

部署框架选型
考虑到对方企业人数超过2万,所以我们对于并发性、稳定性、安全性都有一定的要求,在综合对比了一些主流的推理框架后,最终确定了vLLM。具体各框架的研究细节这里就不再赘述了,感兴趣的可以搜索相关资料。

再附上几个其他框架的对比图

在正式上机之前,我们做了大量的远程部署演练,所以过程还算一帆风顺。
本文就记录下本次部署的全过程以及遇到的坑。先上两张部署成功的图(DS 8卡跑满,Qwen用了4卡)
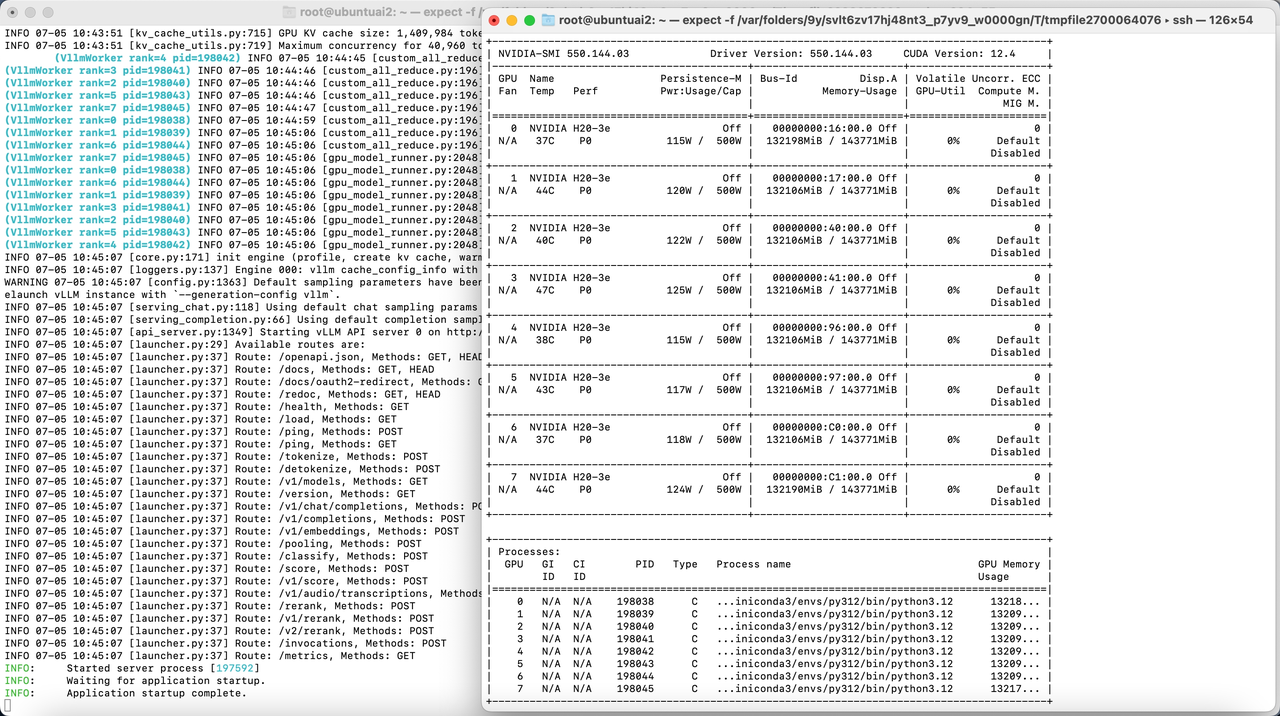
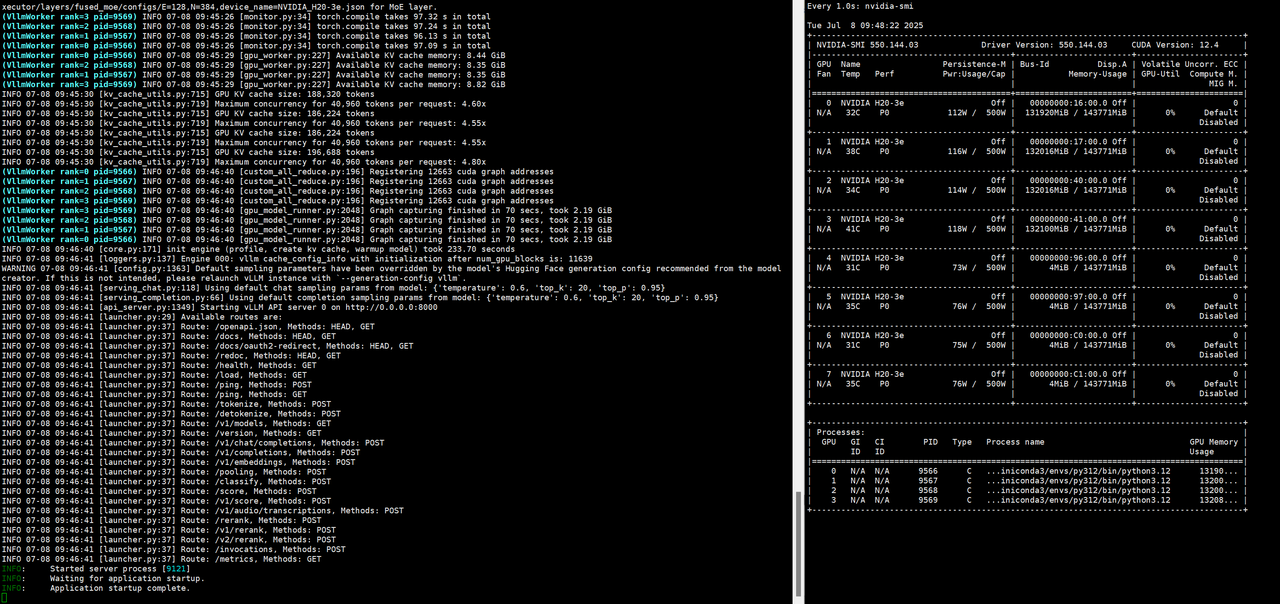
正文
部署的过程分为三步
1. 环境准备 -> 2. 正式安装 -> 3. 推理速度测试
一、环境准备
—————-
ubuntu 22.04
python 3.12
cuda 12.4
pytorch 2.5.1
nividia driver 550
—————-
操作系统选择Ubuntu 22.04 LTS版本,其他库以及驱动版本如上(版本最好全部对应,否则容易出问题)
1. 安装GPU驱动
客户服务器并未预装驱动,所以我们需要将NVIDIA驱动先装好,有两种安装方式,一种是下载好官方驱动后运行安装程序,一种是更新PPA源后apt安装。我这里演示一下apt的方式安装。
安装 NVIDIA 驱动
sudo add-apt-repository ppa:graphics-drivers/ppa # 添加第三方PPA源
sudo apt update
sudo apt install nvidia-driver-550 # 安装550驱动
安装CUDA Toolkit
wget https://developer.download.nvidia.com/compute/cuda/repos/ubuntu2204/x86_64/cuda-keyring_1.1-1_all.deb
sudo dpkg -i cuda-keyring_1.1-1_all.deb
sudo apt-get update
sudo apt-get -y install cuda-toolkit-12-4
查看驱动是否安装成功
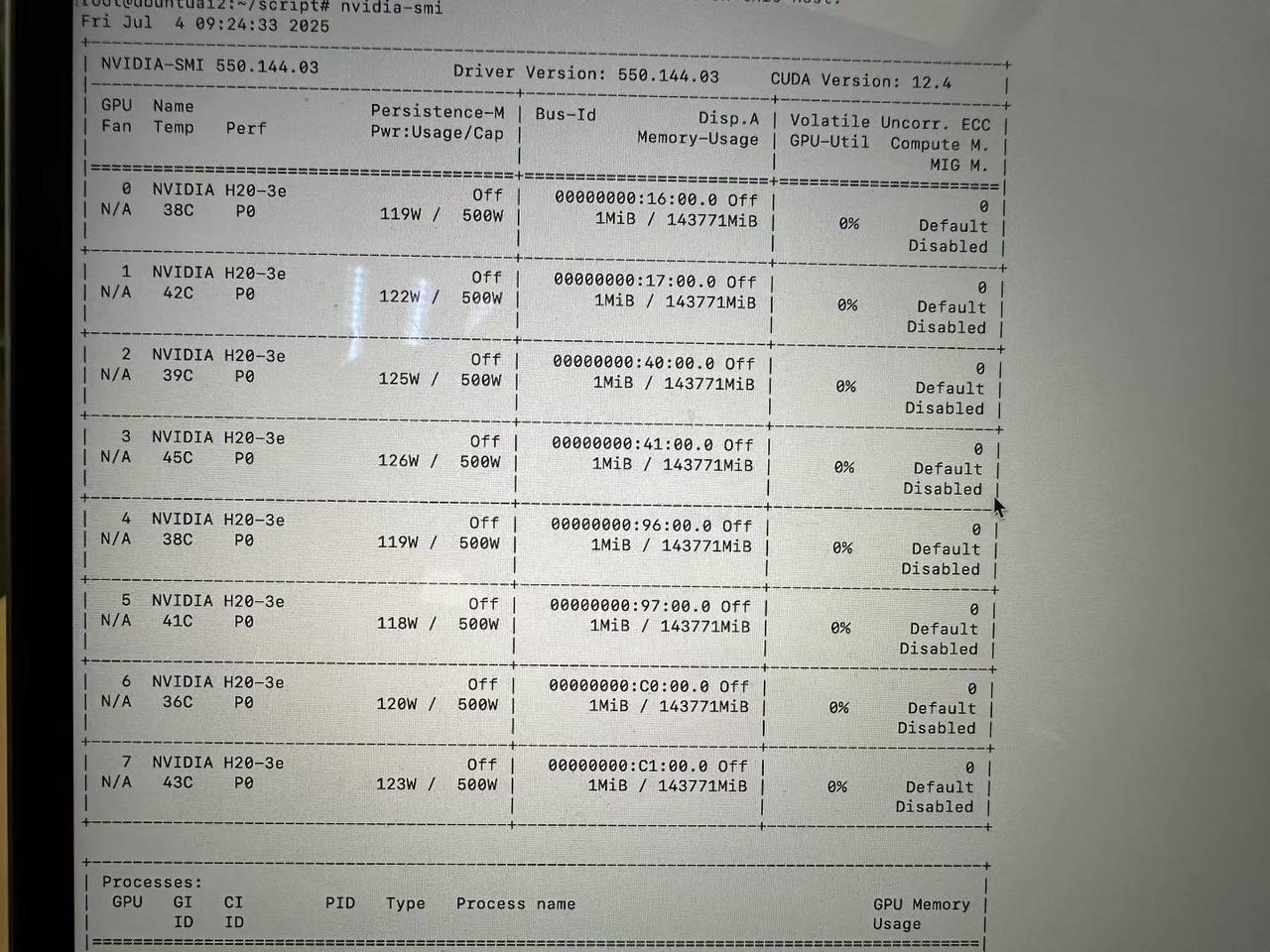
nvidia-smi
此时安装成功,我们看到有8张H20的GPU,单张143G显存,如下图:
此时我们还要再看一下NVLink(高速 GPU 互联)是否已经联通
# 查看GPU拓扑图
nvidia-smi topo -m
# 查看nvlink连接状态
nvidia-smi nvlink –status
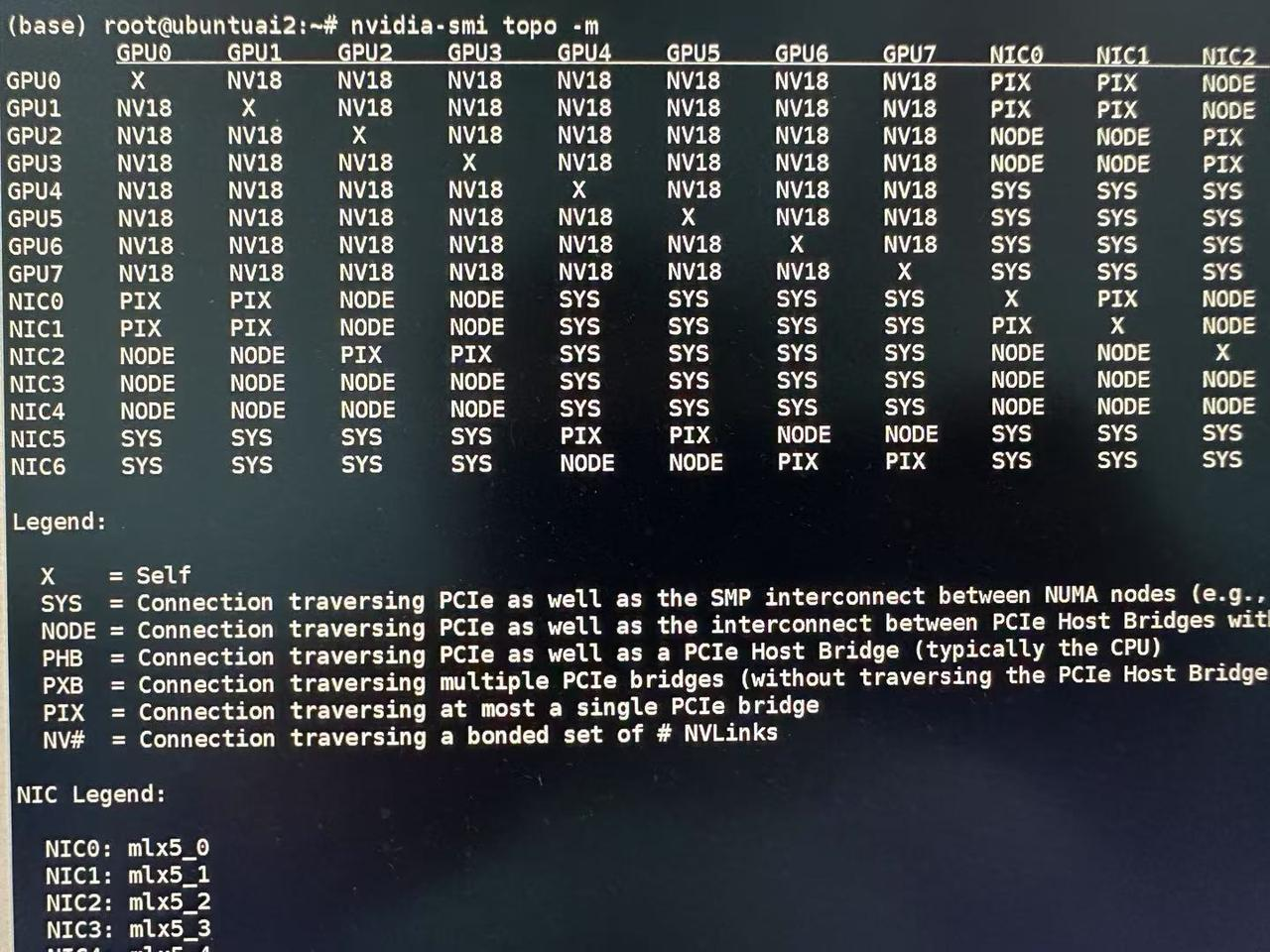
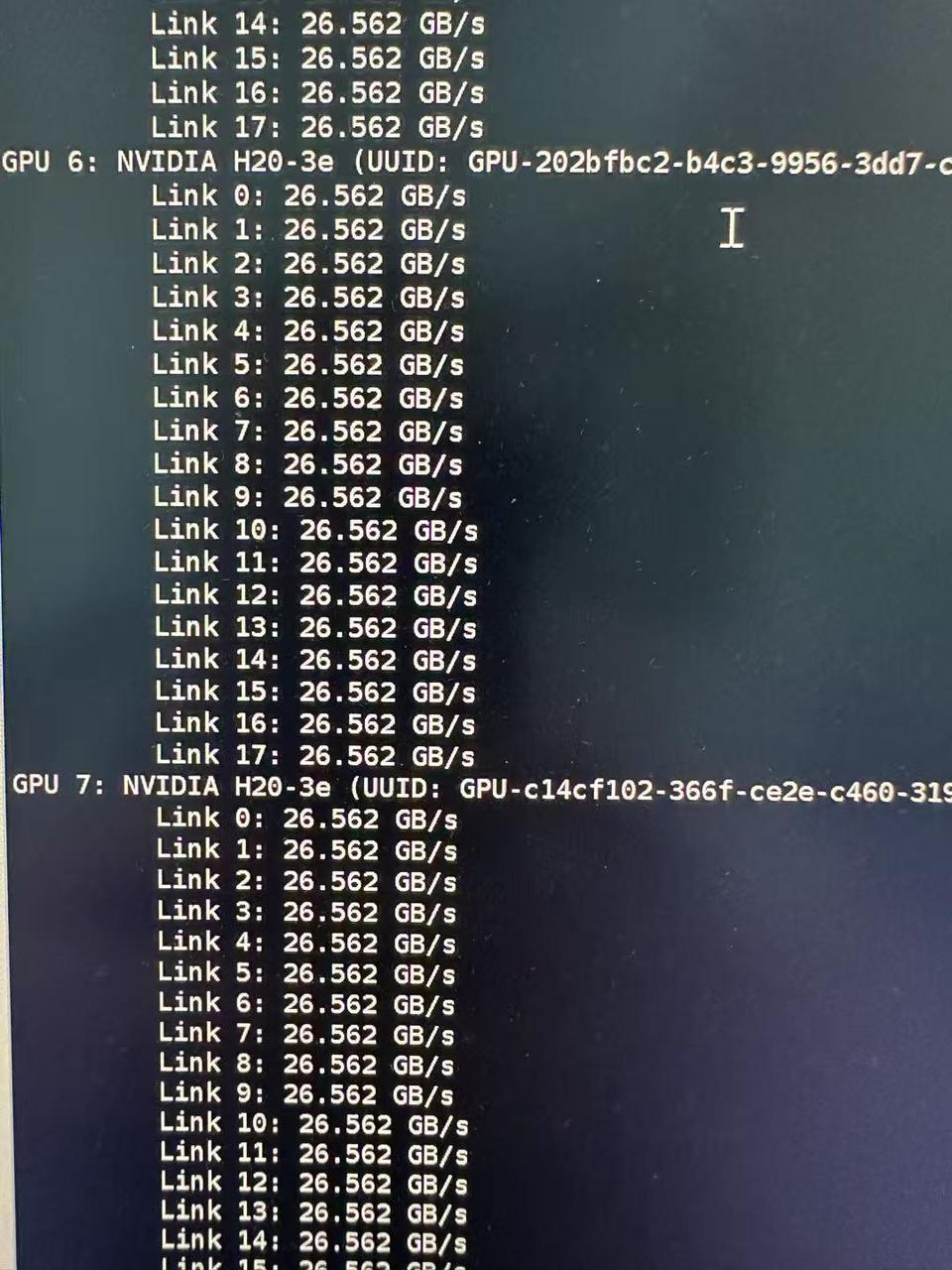
我们看到GPU之间通过18条NVLink互联,整体带宽可达 26.562 GB/s * 18 = 478.116 GB/s
至此驱动和GPU环境准备完成
2. 用conda安装虚拟环境(推荐)
驱动安装好之后,我们用conda创建一个python虚拟环境,避免各种版本的兼容性问题
# 下载 Miniconda 安装包
cd ~ && wget https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.sh
# 安装脚本
bash Miniconda3-latest-Linux-x86_64.sh
# 激活
source ~/.bashrc
conda –version
创建新环境(python=3.12)
conda create -n py312 python=3.12
# 需要conda init,如果没有则输入:source /root/miniconda3/etc/profile.d/conda.sh
conda activate py312
二、安装vllm
上面的环境都准备好后,进入虚拟环境,安装vllm
pip install vllm
经过一段时间后vllm完成安装(大约有2-3个G)
三、下载模型
因为部署的是满血的DeepSeek,所以两个模型文件就有1T多,所以我们提前准备了4T的移动硬盘,将模型下载好,交给对方的运维进行拷贝。
我们先使用将模型文件下载到硬盘里,这里使用国内的魔搭进行下载(Model Scope)
先看一下磁盘空间,可以看到有6T的数据空间,够用了

开始下载
pip install modelscope
# 使用 –local_dir参数下载到指定目录
modelscope download –model deepseek-ai/DeepSeek-R1-0528 –local_dir /data/models/DeepSeek-R1-0528
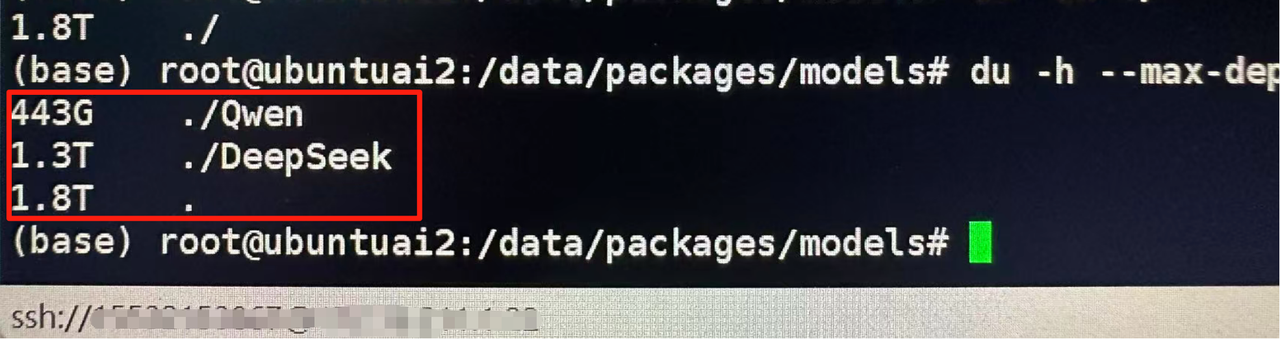
全部下载好后,大概有1T的占用,我这里还下载了别的模型,所以显示1.8T,如图:
四、vllm启动大模型
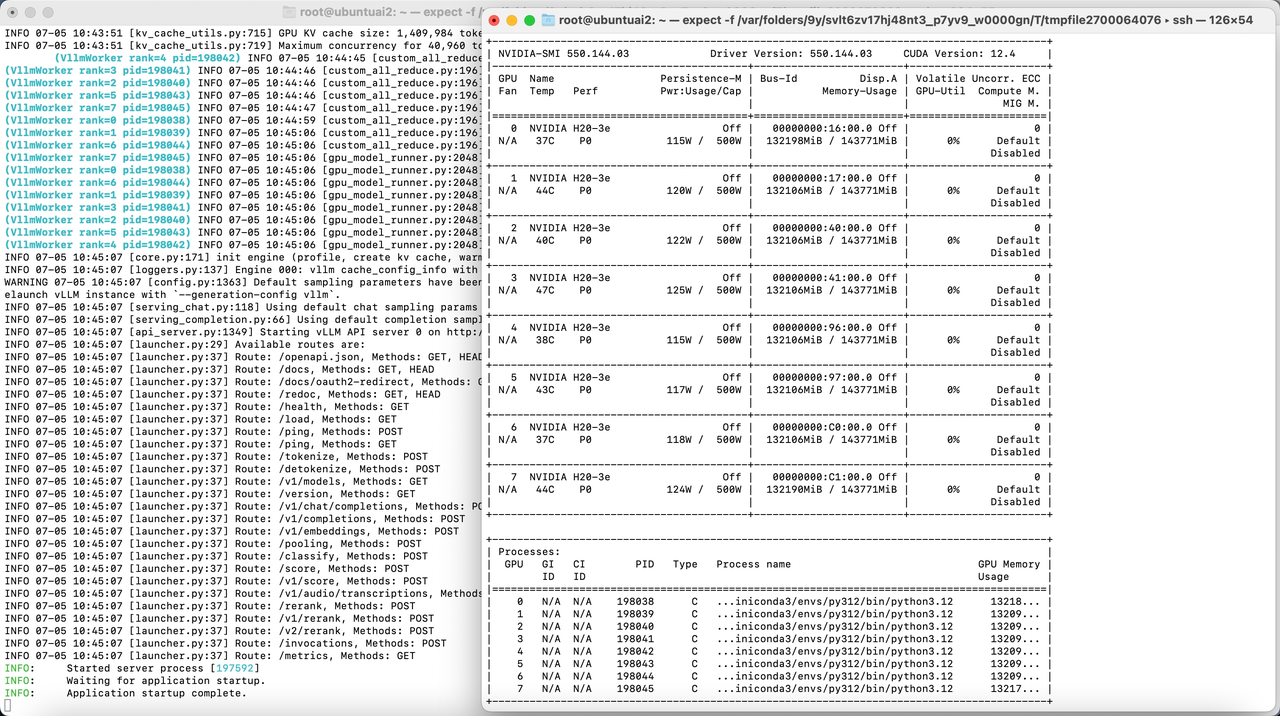
现在我们的驱动安装好了,模型下载好了,且已经在py312的虚拟环境中,万事具备只欠东风,此时运行一个最小化执行命令,看看vllm是否能成功启动
# 运行
vllm serve /data/packages/models/DeepSeek/DeepSeek-V3-0324/ \\
–tensor-parallel-size=8 \\ # 张量并行,GPU数
–served-model-name DeepSeek-V3-0324 \\ # 模型名称
等待3-5分钟后,启动成功!我们看到启动满血版DeepSeek-V3-0324,单卡占用了132g的显存。
同时vLLM会提供一个兼容OpenAI API格式的接口,默认端口为8000
至此,我们的大模型服务就通过vLLM成功启动起来了,当然为了在生产环境持久化部署,还需要做一些参数优化
五、持久化部署
一、用nohup运行
nohup vllm serve /data/packages/models/DeepSeek/DeepSeek-V3-0324/ \\
–tensor-parallel-size=8 \\ # 张量并行,GPU数
–served-model-name DeepSeek-V3-0324 \\ # 模型名称
–max-model-len 8192 \\ # 限制token长度(可选)
> /logs/vllm.log 2>&1 & # 输出日志
二、用docker运行
1. 安装docker
# 运行docker安装脚本
sh install_docker.sh
2.2 安装NVIDIA Container Toolkit
# 添加源并安装NVIDIA Container Toolkit GPU穿透过去
distribution=$(. /etc/os-release;echo $ID$VERSION_ID)
curl -s -L https://nvidia.github.io/nvidia-docker/gpgkey | sudo apt-key add –
curl -s -L https://nvidia.github.io/nvidia-docker/$distribution/nvidia-docker.list | sudo tee /etc/apt/sources.list.d/nvidia-docker.list
sudo apt-get update && sudo apt-get install -y nvidia-container-toolkit
sudo systemctl restart docker
2.3 配置 Docker 运行时
# 生成 NVIDIA 运行时配置
sudo nvidia-ctk runtime configure –runtime=docker
# 重启 Docker 服务
sudo systemctl restart docker
3. 拉取镜像
需要指定号相应版本,避免CUDA版本和驱动对应不上,我这里用v0.8.5.post1
# 指定v0.8.5.post1
docker pull vllm/vllm-openai:v0.8.5.post1
4. 运行docker
docker run –runtime nvidia –gpus all \\
-v /root/models:/models \\
-p 8000:8000 -d \\
–ipc=host \\
vllm/vllm-openai:v0.8.5.post1 \\
–model /models/Qwen/Qwen3-4B-FP8
以下是润色后的版本,优化了语言表达和技术细节的呈现,同时保持了专业性和可读性:
六、推理速度测试
为测试大模型的推理性能,我们使用EvalScope测试工具,它是由魔搭社区推出的评测框架,支持推理速度压测(如TTFT、TPS、吞吐量),内置多数据集(MMLU、CMMLU等),可本地或API测试,生成可视化报告。
下面是具体的测试流程:
1. 环境配置
# 创建专用conda环境
conda create -n evalscope python=3.10 -y
conda activate evalscope
# 安装评测工具(含性能测试组件)
pip install 'evalscope[all]' evalscope[perf] -U
4.2 测试参数设计
采用EvalScope性能测试模块,通过以下配置模拟真实业务场景:
-
API端点:本地部署的OpenAI兼容接口(http://127.0.0.1:8000/v1/chat/completions)
-
并发量:32线程并行请求
-
测试轮次:每线程20次迭代
-
测试数据集:openqa(开放域问答基准)
-
流式输出:启用stream模式
evalscope perf \\
–url "http://127.0.0.1:8000/v1/chat/completions" \\
–parallel 32 \\
–model /data/packages/models/DeepSeek/DeepSeek-V3-0324 \\
–number 20 \\
–api openai \\
–dataset openqa \\
–stream
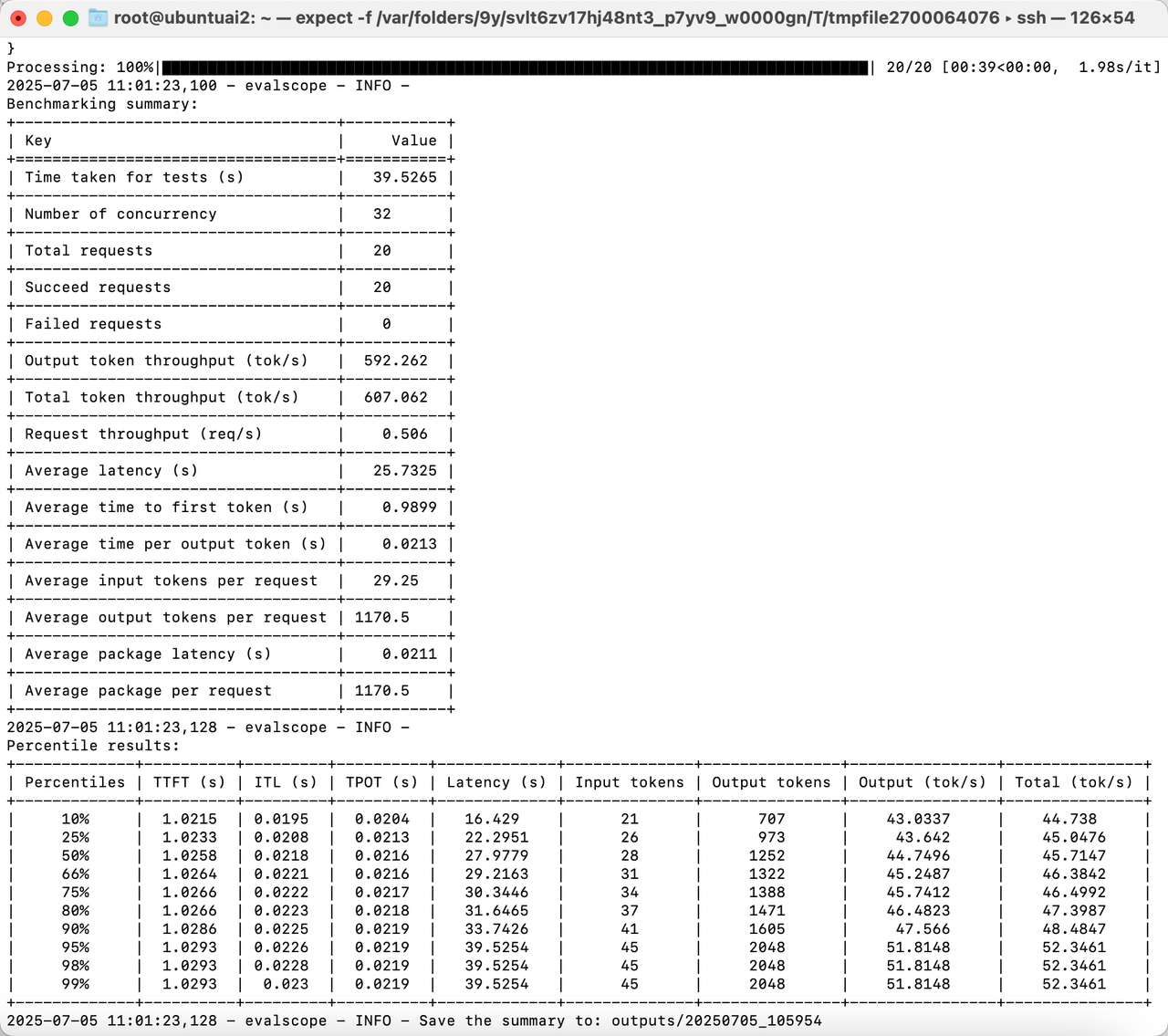
4.3 测试结果分析
基准测试总结(32并发/20请求):
-
总测试时间:39.53秒
-
请求成功率:100%(20/20)
-
输出Token吞吐量:592.26 tok/s
-
总Token吞吐量:607.06 tok/s
-
平均首Token延迟(TTFT):0.99秒
-
平均输出Token间隔(ITL):0.0213秒
-
平均输入Token数/请求:29.25
-
平均输出Token数/请求:1170.5
-
吞吐能力:系统在32并发下保持607.06 tok/s的总吞吐量,很不错
-
延迟表现:
-
首Token延迟稳定在1.02秒(P95)
-
Token间延迟(ITL)控制在22ms左右,满足实时交互需求
-
-
稳定性:不同百分位指标波动小于5%,表现稳定
-
资源利用率:长文本生成场景(平均1170输出Token/请求)下仍保持高吞吐
测试截图如下:
七、问题与解决方案
因为涉及很多软硬件的因素,部署过程中难免会遇到一些问题,这里我们列举一些问题和解决办法
有的时候NVLink的服务可能未启动,或者nvlink的版本和驱动版本不一致
# 查看nvlink状态
systemctl status nvidia-fabricmanager.service
会出现类似fabric manager NVIDIA GPU driver interface version 535.216.01 dont match with driver version 550.183.01这种提示,这时我们需要将两者的版本号统一,重新安装nvidia-fabricmanager或者驱动版本
- 显存不足(OOM)问题
推理过程中如果出现CUDA out of memory错误,可以尝试如下解决方法:
-
降低批次大小(Batch Size)
-
使用半精度(FP16)或混合精度推理
-
尝试量化模型(如8-bit或4-bit量化)
-
考虑使用更小的模型变体
-
及时清除不再需要的变量和缓存
-
使用torch.cuda.empty_cache()释放未使用的显存
-
Docker部署时,GPU未映射
-
确保安装了NVIDIA Container Toolkit
-
确保配置了docker运行时nvidia-ctk runtime configure –runtime=docker
- 多GPU负载不均衡
问题现象:
-
nvidia-smi显示各GPU利用率差异大
-
部分GPU显存占用明显高于其他卡
解决方案:
–tensor-parallel-size 4 # 需与GPU数量匹配
export CUDA_VISIBLE_DEVICES=0,1,2,3,4,5,6,7
nccl-tests/build/all_reduce_perf -b 8 -e 256M -f 2
建议在部署前使用vllm.entrypoints.benchmark进行基准测试,提前发现性能瓶颈。典型测试命令:
python -m vllm.entrypoints.benchmark \\
–model deepseek-ai/deepseek-v3 \\
–dataset huggingface:openai/summarize_from_feedback \\
–quantization awq \\
–tensor-parallel-size 2
总结
本次生产环境部署总共历时5天,前期大模型模型文件、脚本、镜像等文件的下载和传输用了2天,实际部署用了3天,这里给一些实际建议:
前期准备:提前准备移动硬盘(至少2T)将大模型、docker镜像以及一些自动化脚本拷贝好,另外必须做好测试服务器的安装演练,否则到了生产环境你会手忙脚乱
网络环境:本次非纯离线安装,所以需要保证机房的网络环境稳定
硬件上:8 * H20(141G)可以保证稳定运行满血DeepSeek,4 * H20可以稳定运行满血Qwen3
部署:使用vLLM部署,一定要创建虚拟环境,整体部署过程都比较丝滑
并发:32并发还有很大空间,100以内压力不大,首token延迟1秒左右,单请求600token/s
最后
感谢大家看完全文,本文是基于我在生产环境部署DS的一些实操记录,当然因为部署时在甲方公司,所以很多截图和BUG记录有所遗漏,整体上还是具有参考意义的,希望对大家有所帮助和启发。
另外,大家有大模型、AI智能体相关的商业合作和咨询可以和我聊聊哦:lwbg66







评论前必须登录!
注册