 网硕互联帮助中心
网硕互联帮助中心1实验背景
数字图像相关法DIC是材料力学领域研究的关键技术,其中局部DIC凭借亚像素级精度、全场测量等优势,成为材料局部变形分析的优选方案。传统CPU计算难以应对局部DIC数万个子区并行计算需求,新兴GPU算法一定程度提高了计算效率,如OpenCorr-GPU开源方案。
千眼狼研发工程师们,自主研发局部DIC-GPU算法,针对自研的DIC软硬件生态深度优化。研发人员通过开展几组经典实验,并与开源GPU算法进行横向对比。
2技术原理
自研局部DIC-GPU算法核心是将图像数据、子区网格位置和宽高信息预加载至GPU显存,利用数千核心并行处理所有子区的互相关计算。工程师们优化了线程调度,减少内存访问冗余,并自研子区网格动态分配策略,以最大化调用GPU算力资源。
3实验验证
为验证实际效果,千眼狼工程师设计了六组实验,实验基于同一测试环境GPU 4070开展:
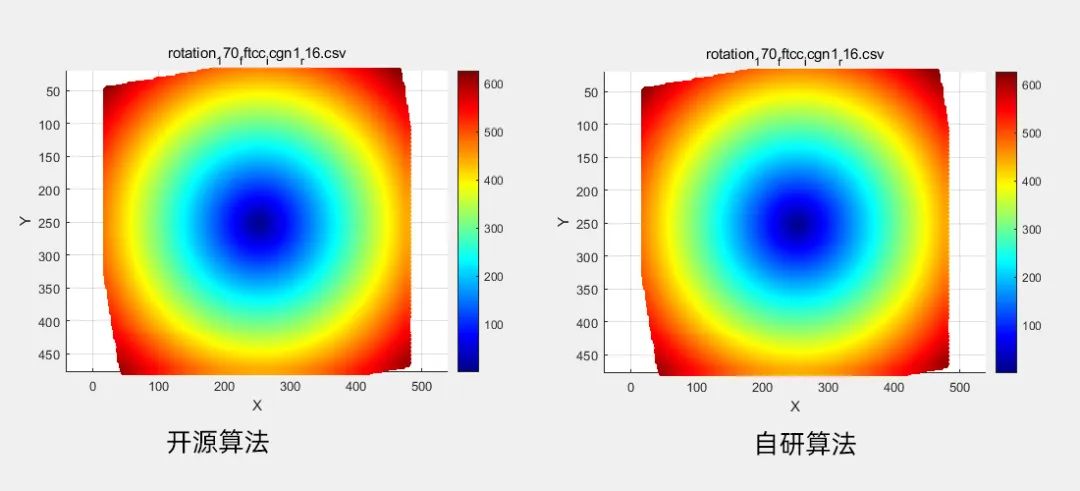
场景1 仿真旋转
数据规模:有效子区个数0.4W
计算结果:左 开源算法耗时160ms,右 自研算法耗时仅54ms
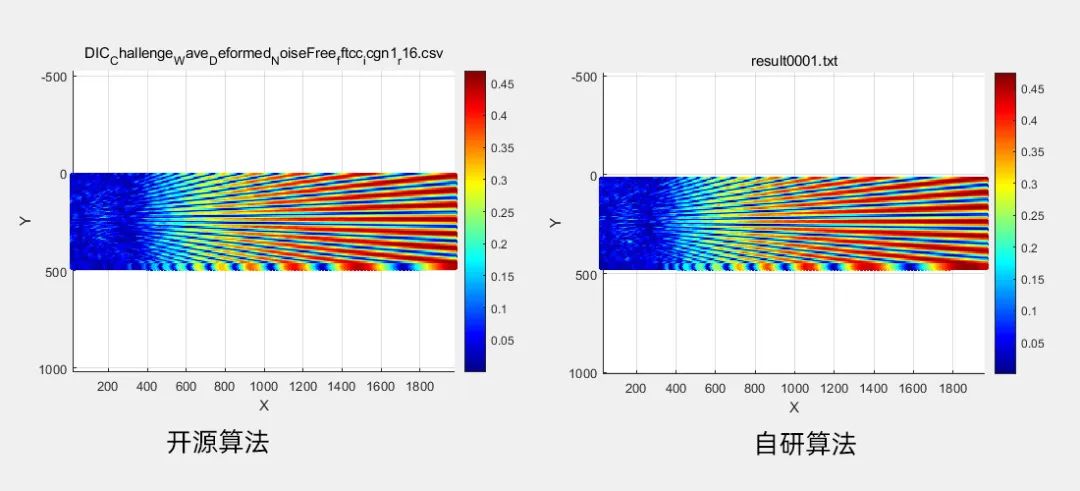
场景2 仿真辐射
数据规模:有效子区个数1.7W
计算结果:左 开源算法耗时696ms,右 自研算法耗时仅85ms
场景3 圆杆拉伸
数据规模:有效子区个数0.3W
计算结果:左 开源算法耗时826ms,右 自研算法耗时仅64ms
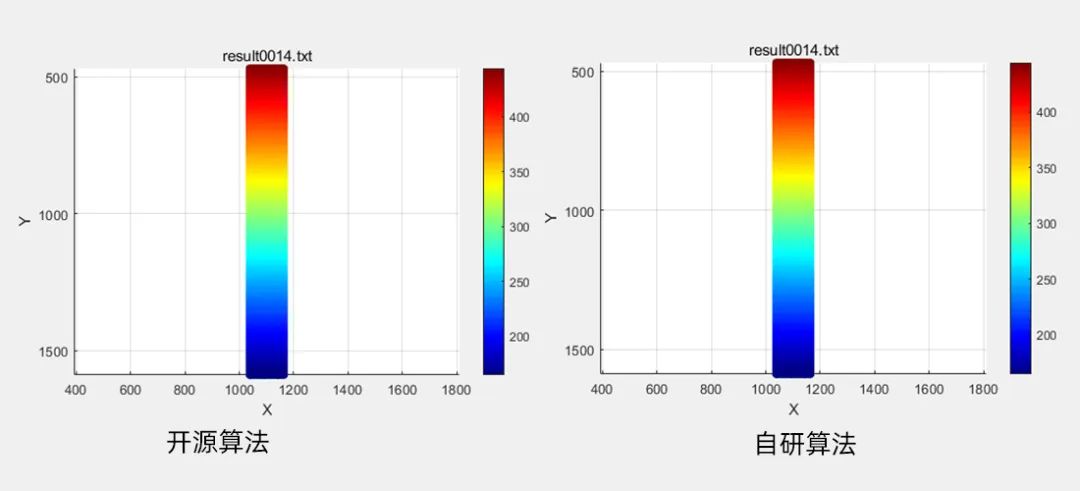
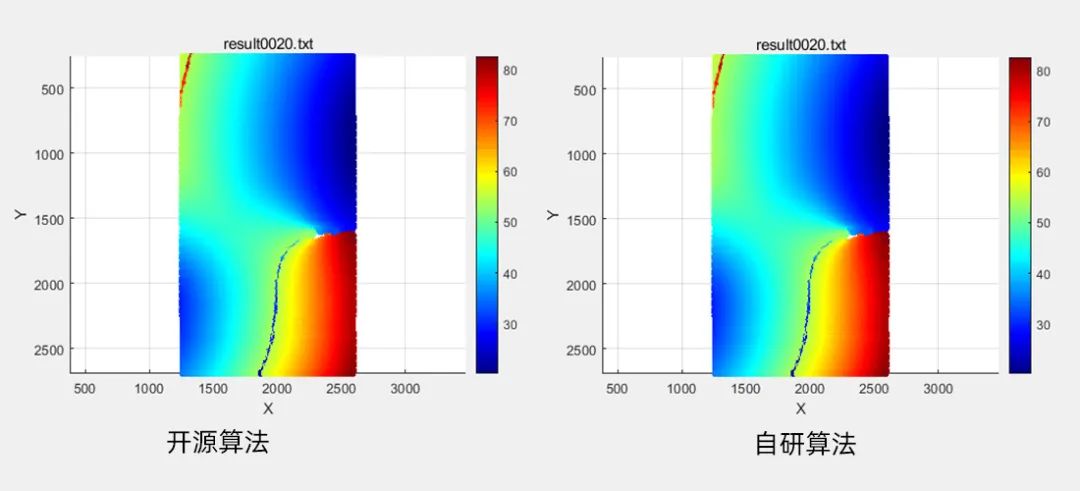
场景4 三点弯
数据规模:有效子区个数0.7W
计算结果:左 开源算法耗时2011ms,右 自研算法耗时仅109ms
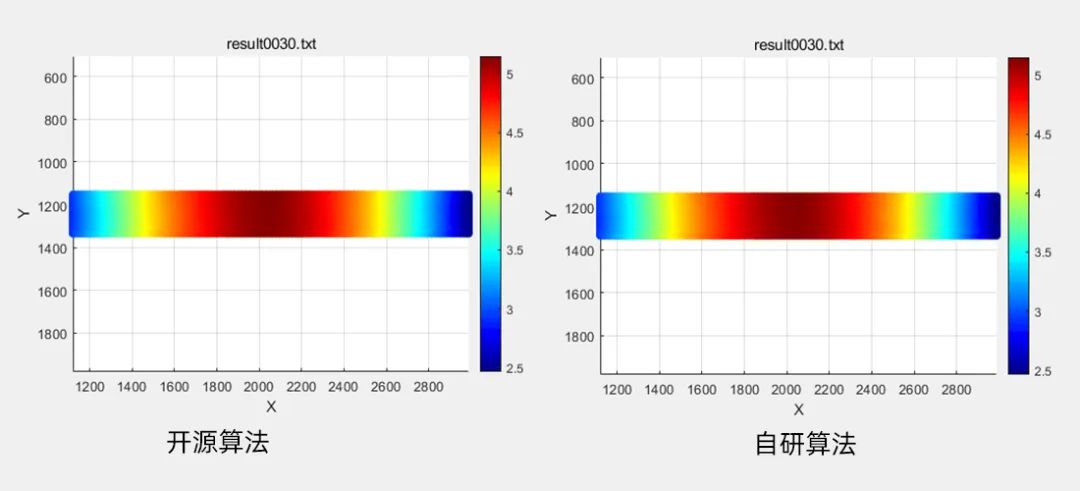
场景5 孔洞拉伸
数据规模:有效子区个数3.2W
计算结果:左 开源算法耗时2755ms,右 自研算法耗时仅148ms
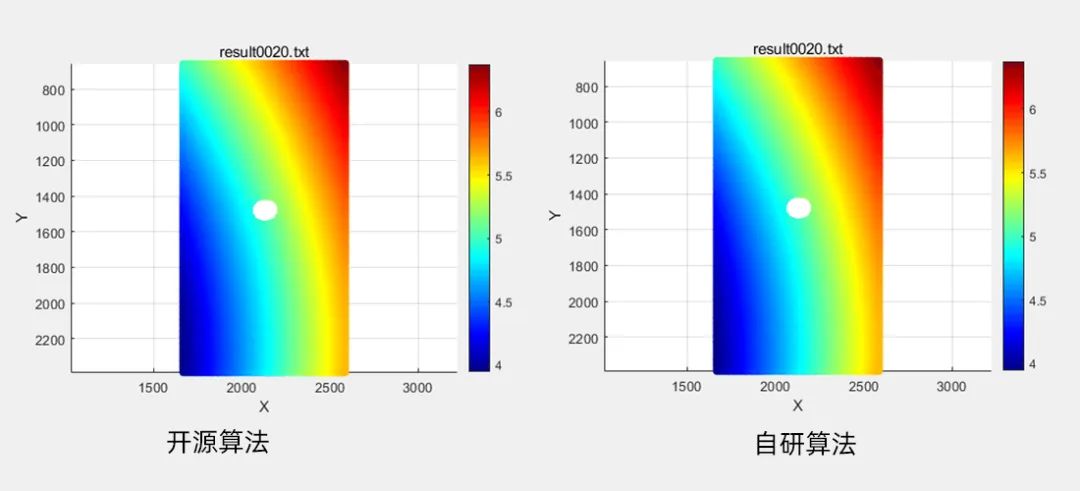
场景6 拉伸裂纹
数据规模:有效子区个数6.6W
计算结果:左 开源算法耗时3855ms,右 自研算法耗时仅217ms
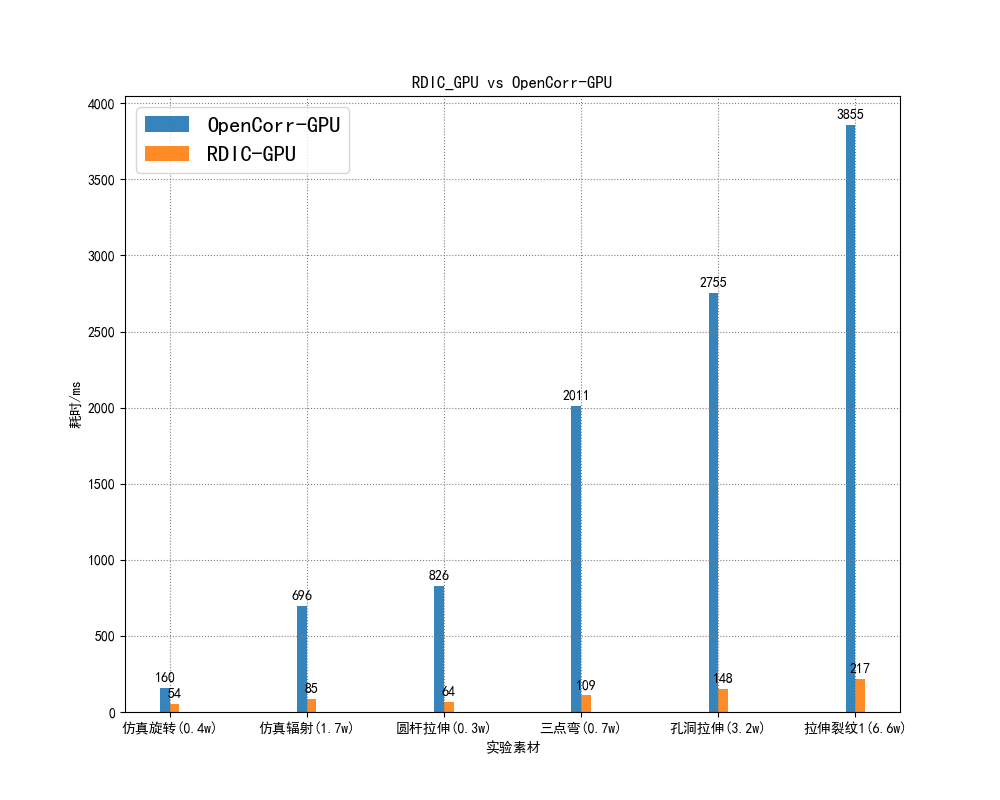
六大实验场景耗时对比
千眼狼自研GPU加速算法较开源GPU 提速3–18倍,且子区规模越大优势越显著。如圆杆拉伸0.3W子区提速3倍,6.6W子区拉伸裂纹场景提速18倍。
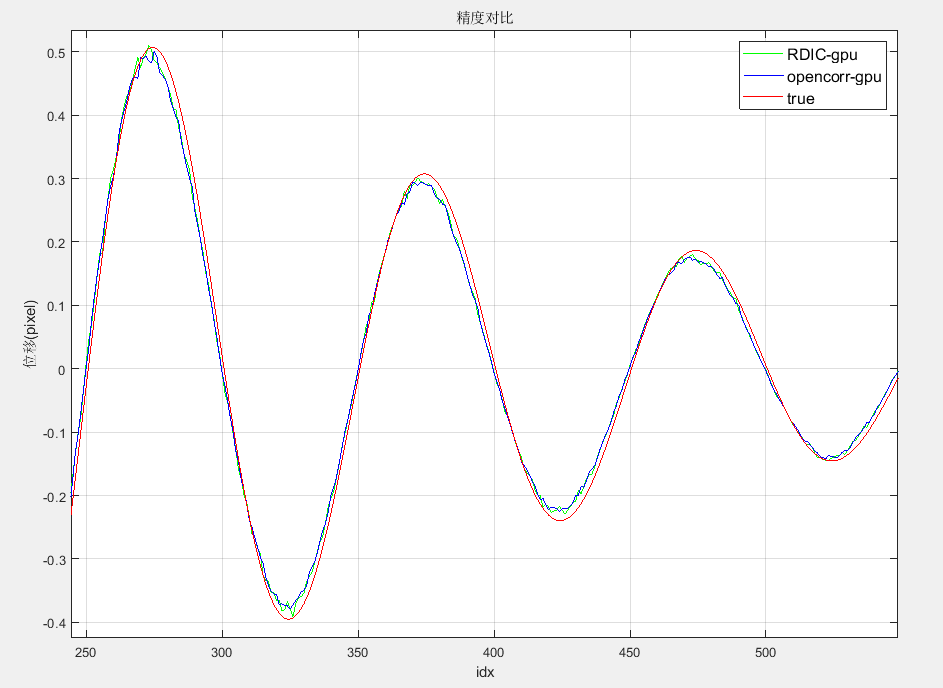
六大实验场景精度对比
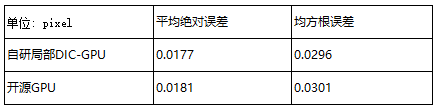
千眼狼工程师们使用带有位移真值的仿真素材做精度对比,素材位移真值为振幅衰减的正弦函数,绘制自研GPU计算结果、开源GPU计算结果和位移真值曲线如下:
将两组计算结果与真值的平均绝对误差和均方根误差如下:
4实验结论
通过上述实验对比,千眼狼自主研发的局部DIC-GPU算法与开源GPU算法在精度一致的前提下,在效率、适用性、稳定性上有较大提升。
1)效率:实现了较开源算法同计算场景下的3~18倍的提升。
2)适用性:涵盖从仿真到实拍不同场景,可高效处理万级以上子区。
3)稳定性:计算结果与开源方案误差≤0.03pixel,满足科研级精度需求。
5实验展望
千眼狼自主研发的局部DIC-GPU加速算法已融入DIC软硬件生态系统,帮助科研人员提高在焊接残余应力、裂纹尖端变形等局部应变分析场景中的科研效率, 以更先进的性能赋能科学研究与工业智造。









评论前必须登录!
注册