 网硕互联帮助中心
网硕互联帮助中心 本文还有配套的精品资源,点击获取 
简介:服务器多ping工具专为系统管理员和网络工程师设计,允许同时对多台主机执行ping命令,快速诊断网络问题,节省手动操作时间。此工具通过自动化批处理ping操作,支持统计报告生成和定时任务,为网络故障排查、性能监控、带宽评估和网络规划提供重要数据支持。用户通过配置主机列表和参数来运行工具,以实现快速的网络状态了解。 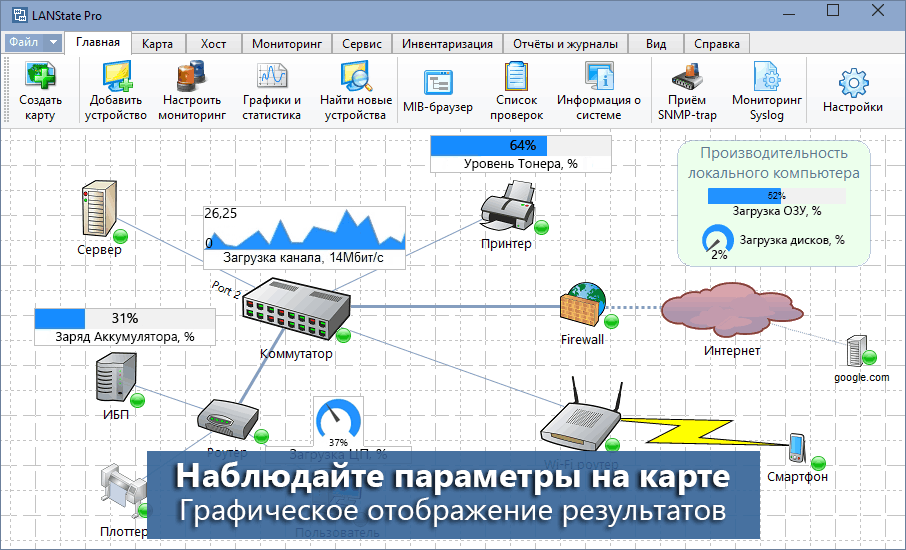
1. 网络管理与监控工具的重要性
随着网络技术的飞速发展,网络管理与监控工具已经变得至关重要。这些工具不仅协助IT专业人员维护网络的稳定性和性能,而且对于企业的运营效率和安全监控有着不可或缺的作用。本章将探讨这些工具的必要性以及它们在网络管理中扮演的角色,同时概述它们如何帮助企业做出更加明智的决策。
网络管理工具的核心价值在于其能够自动化常规任务,比如监控网络状态、生成报告和警报,这样就允许技术人员专注于更为复杂和需要人为干预的网络问题。这不仅提高了工作效率,也降低了人为错误的风险。
此外,网络监控工具提供实时数据分析,使管理者能够快速识别并响应网络异常,如延迟、带宽饱和和安全事件,这些都是维护网络健康的关键因素。通过网络管理与监控工具的深入应用,企业能够优化网络资源的配置,预防潜在的网络故障,从而确保业务连续性和服务质量。本章将为读者提供网络管理与监控工具重要性的深入理解,并在后续章节中详细探讨具体的应用和技术实现。
2. 批量执行ping命令的原理与应用
2.1 理解ping命令的基础知识
2.1.1 ping命令的作用与基本语法
ping命令是网络管理员最常用的工具之一,它能够测试网络连接的质量以及特定设备的可达性。通过发送ICMP回声请求消息到目标主机并监听回声应答消息,管理员可以检测设备间是否能够通信以及通信延迟的程度。其基本语法为:
ping [选项] 目标地址
常用的选项包括 -c 用于指定发送的回声请求数量, -i 设置发送回声请求的间隔时间,以及 -s 定义回声请求数据包的大小。
2.1.2 ping命令返回数据的解读
当执行ping命令时,返回结果中包含了多个重要参数,例如:
- 序列号:每个回声请求和回声应答包的唯一标识。
- 时间戳:请求和响应包在传输过程中的时间消耗。
- TTL(Time To Live)值:表示数据包在网络中可以经过的最大路由器数量。
- 数据包大小:发送和接收的ICMP回声请求和回声应答包的大小。
通过这些信息,管理员可以判断目标设备是否可达、网络的稳定性和延迟情况。
2.2 批量ping命令的实现机制
2.2.1 批量ping的脚本编写方法
为了有效地管理大型网络或进行大规模的网络设备检查,批量ping脚本的编写显得尤为重要。以下是一个基本的bash脚本示例,用于批量ping网络上的多个IP地址:
#!/bin/bash
# 定义一个IP地址列表
ip_list=("192.168.1.1" "192.168.1.2" "192.168.1.3")
# 遍历IP地址列表并执行ping操作
for ip in "${ip_list[@]}"
do
echo "Pinging $ip with 32 bytes of data:"
ping -c 4 $ip | grep "rtt"
echo ""
done
该脚本会遍历 ip_list 数组中的每个IP地址,执行4次ping操作,并只打印往返时间(rtt)。
2.2.2 批量ping的效率优化策略
当需要ping的地址数量很多时,脚本的执行效率变得至关重要。以下几点可以提高批量ping操作的效率:
- 使用多线程或并行处理技术来同时发送多个ICMP请求,可以极大地减少总体的执行时间。
- 限制ICMP请求的发送频率,避免因发送速度过快而被网络设备识别为攻击,导致被阻止。
- 通过计时器跟踪,优化每个ping命令的执行时间,确保即使在网络条件不良的情况下,也不会无谓地等待超时。
2.2 批量ping命令的优化案例分析
在本节中,我们将通过一个案例分析来探讨批量ping命令的优化策略。假设有一家大型企业,需要检测其分布在不同地点的多个服务器的网络连通性。为了提高效率,我们编写了一个优化后的批量ping脚本。
#!/bin/bash
# 定义一个包含服务器IP的文件路径
ip_file="/path/to/server_ips.txt"
# 使用xargs命令并行执行ping命令
cat $ip_file | xargs -n 1 -P 10 ping -c 4 | grep "rtt" | awk -F '/' '{print $5 " " $6}'
在此脚本中,我们使用 xargs -P 参数来指定并发运行的进程数, grep 用于筛选出往返时间信息, awk 则进一步格式化输出结果。 -P 10 表示同时运行最多10个ping进程。这样的设计不仅提高了脚本的执行速度,还有效利用了系统的资源,减少了总体的执行时间。
通过上述脚本的实施,企业能够有效地、及时地检测其服务器网络状态,从而对网络进行更好的管理和优化。
接下来,我们将继续探讨如何通过其他方法和工具进一步提升网络诊断的效率。
3. 网络诊断效率提升的方法与实践
3.1 网络诊断的常规流程
3.1.1 常见网络问题及其诊断步骤
网络问题的诊断是网络维护中的核心环节,常见问题包括但不限于延迟、丢包、连接失败、带宽饱和等。这些现象往往会导致服务中断或性能下降,影响用户体验。有效的网络诊断流程包括以下几个步骤:
- 问题识别: 首先要明确用户遇到的具体问题,这需要与用户沟通,收集尽可能多的现象描述。
- 初步判断: 根据问题描述初步定位可能发生故障的网络区域。
- 收集数据: 使用网络诊断工具收集相关数据,如ping、traceroute等命令结果。
- 分析数据: 对收集到的数据进行深入分析,尝试找出问题原因。
- 故障模拟: 在不影响实际网络运行的情况下,模拟故障以复现问题。
- 问题修复: 确认问题后,采取相应的措施进行修复。
- 结果验证: 验证问题是否已经彻底解决,并确保未引入新的问题。
3.1.2 网络诊断工具的选择与应用
针对网络诊断,有多种工具可以使用,这些工具各有特点,适合不同的诊断需求:
- Ping: 基本的网络连通性测试工具。
- Traceroute: 跟踪数据包传输路径的工具,可以用来诊断网络路径上的具体问题。
- Wireshark: 功能强大的网络协议分析工具,可以详细查看数据包内容和网络流量。
- Nmap: 主要用于网络发现和安全审核,也可以用于网络问题诊断。
- Netstat: 查看网络连接状态、路由表、接口统计等信息。
为了提高效率,这些工具往往可以搭配使用,通过综合分析多个工具收集的数据,能够快速而准确地定位问题。
3.2 提升ping命令诊断效率的技巧
3.2.1 使用多线程提升ping命令执行速度
在进行大规模网络诊断时,使用单线程逐个ping可能会非常耗时。多线程可以显著提高执行速度,但需要注意的是,过多的线程可能会对网络设备造成压力。一个有效的策略是设置合适的线程数,既能保证诊断效率,又不至于影响网络设备的正常运行。
使用 Bash 脚本结合 ping 命令实现多线程的示例代码如下:
#!/bin/bash
# 定义目标地址列表
targets=("192.168.1.1" "192.168.1.2" "192.168.1.3")
# 启动的线程数
num_threads=5
# 创建线程并运行
for i in $(seq 1 $num_threads); do
for target in "${targets[@]}"; do
# 使用 & 符号后台运行命令,用 disown 命令防止脚本退出时任务被终止
ping -c 4 $target & disown
done
# 等待一个循环内的所有任务完成
wait
done
# 输出结果
echo "所有ping操作完成"
3.2.2 对ping命令结果的快速分析与报告
在执行多线程ping操作后,收集到的输出结果通常量大且难以快速分析。可以编写一个简单的脚本来处理这些结果,快速给出网络连通性状态的总结报告。
以下是一个 Bash 脚本示例,该脚本将收集ping命令的输出结果,并生成一个简单的连通性报告:
#!/bin/bash
# 清空或创建报告文件
echo "网络连通性报告:" > ping_report.txt
# 遍历目标地址列表,执行ping命令并记录结果
for target in "${targets[@]}"; do
if ping -c 4 $target > /dev/null; then
echo "目标 $target 可达" >> ping_report.txt
else
echo "目标 $target 不可达" >> ping_report.txt
fi
done
# 输出报告文件内容
echo "连通性报告如下:"
cat ping_report.txt
以上脚本将输出的报告保存在 ping_report.txt 文件中,报告内容将简明地展示哪些目标是可达的,哪些目标存在网络连接问题。通过自动化脚本快速处理大量数据,网络诊断的效率得到了明显提升。
4. 网络故障的快速定位与解决方案
4.1 网络故障的分类与特征
4.1.1 网络故障的基本分类
网络故障可以分为物理层故障、数据链路层故障、网络层故障、传输层故障以及应用层故障等。在排查故障时,理解故障的分类有助于定位问题所在的层次,从而采取适当的诊断和修复策略。
- 物理层故障 通常与网络硬件设备的物理连接有关,如网线损坏、接口故障等。此类故障通常会导致设备间的物理连接中断。
- 数据链路层故障 与局域网通信协议(如以太网)相关,问题可能出现在MAC地址解析、交换机配置错误等方面。
- 网络层故障 可能涉及IP地址配置错误、路由问题或IP分组的传输错误等。
- 传输层故障 通常表现为端口错误或数据包传输错误,与TCP/UDP协议相关。
- 应用层故障 则更多地与网络应用有关,例如,服务未运行、访问权限设置错误等。
4.1.2 常见网络故障的诊断要点
对于每种类型的网络故障,都有一套特定的诊断步骤和要点:
- 物理层故障的诊断 重点在于检查连接线缆、网络接口卡(NIC)状态,确保硬件无损坏且正确连接。
- 数据链路层故障的诊断 需要检查交换机端口的状态、VLAN配置以及MAC地址表等。
-
网络层故障的诊断 需要验证IP配置的正确性,检查路由表以及IP分组的路由是否正确。
-
传输层故障的诊断 应关注端口号、连接状态、丢包率等参数,使用命令如 netstat 来查看网络连接状态。
-
应用层故障的诊断 则需要验证服务状态,例如使用 telnet 或 curl 测试服务是否可访问。
4.2 实现网络故障的快速定位
4.2.1 利用脚本记录网络状态变化
为了快速定位网络故障,可以通过编写脚本来记录网络状态的变化。以下是一个简单的bash脚本示例,用于记录网络接口的UP/DOWN状态变化:
#!/bin/bash
# 定义日志文件路径
LOG_FILE="/var/log/network_status.log"
# 获取当前网络接口状态
CURRENT_STATE=$(ip link show | grep "state UP")
# 检查日志文件是否存在,不存在则创建
if [ ! -f "$LOG_FILE" ]; then
touch $LOG_FILE
fi
# 如果当前状态与上一次记录的状态不同,更新日志文件
if [ -z "$(grep "$CURRENT_STATE" $LOG_FILE)" ]; then
echo "$(date) – Network state changed to $CURRENT_STATE" >> $LOG_FILE
fi
这段脚本首先定义了日志文件的路径,并获取了当前网络接口的UP状态。如果这个状态与上次记录的状态不同,脚本会将当前时间以及新的状态信息追加到日志文件中。
4.2.2 自动化故障通知与响应机制
自动化故障通知机制是指在检测到网络状态变化时,系统能自动发送通知给管理员或相关责任人。响应机制则是指根据网络故障的类型和严重程度,自动执行预设的响应措施。
下面是一个使用Python编写的示例,它利用 sendmail 功能发送电子邮件通知:
#!/usr/bin/env python
import smtplib
from email.mime.text import MIMEText
from email.header import Header
# 配置邮件发送者和接收者信息
sender = 'admin@example.com'
receivers = ['admin@example.com']
# 创建邮件对象,并设置邮件头信息
message = MIMEText('网络故障发生,接口状态发生变化。', 'plain', 'utf-8')
message['From'] = Header("网络监控系统", 'utf-8')
message['To'] = Header("管理员", 'utf-8')
# 创建SMTP对象,指定服务器地址
smtpObj = smtplib.SMTP('smtp.example.com', 25)
# 登录验证
smtpObj.login(sender, 'password')
# 发送邮件
smtpObj.sendmail(sender, receivers, message.as_string())
# 断开连接
smtpObj.quit()
在这个Python脚本中,我们配置了发送者和接收者信息,创建了一个邮件对象,并通过SMTP服务器发送邮件。管理员会收到包含故障简报的电子邮件,从而快速响应网络故障。
5. 网络监控与性能报告的自动化
5.1 定时任务自动监控网络状态
在IT运维管理中,持续地监控网络状态是确保网络正常运行的关键。通过定时任务可以实现网络监控的自动化,减少人为干预,提高运维效率。
5.1.1 设定定时任务的必要性
定时任务对于网络管理来说至关重要,因为它允许我们周期性地执行脚本或命令来监控网络状态。例如,使用ping命令来检查关键服务器的连通性或使用SNMP工具来获取网络设备的状态信息。此外,定时任务可以用于收集日志文件、清理临时文件、执行备份等运维常规操作。
5.1.2 使用cron进行定时任务设置
在Linux系统中,cron是用于设定定时任务的强大工具。cron使用crontab文件来存储定时任务的配置信息。下面是一个简单的示例,展示如何设置crontab以每5分钟执行一次网络状态检查的脚本:
* * * * * /usr/local/bin/network-check.sh
该crontab条目表示,脚本 network-check.sh 应该每分钟执行一次。脚本的路径是 /usr/local/bin/ ,这里假设脚本已经存在并可执行。
5.2 网络性能统计报告的生成与分析
网络性能的统计报告能够提供网络运行状态的详细视图,帮助IT专业人员分析网络性能趋势和可能出现的问题。
5.2.1 统计报告的重要性与内容
网络性能统计报告通常包括网络延迟、吞吐量、丢包率等关键性能指标。这些数据有助于监控网络健康状态,预测潜在问题,并为网络升级或调整提供数据支持。
5.2.2 自动化报告生成工具的选择与使用
有多种工具可以用于生成网络性能统计报告,如Nagios、Cacti和MRTG等。这些工具大都支持通过插件或脚本来收集数据,并根据收集到的数据自动生成报告。以Nagios为例,可以利用其插件系统来收集各种网络性能数据,并通过其Web界面呈现出来。
以下是一个简单的Nagios插件的示例,用于收集网络延迟数据:
#!/bin/bash
# Nagios plugin for network latency check
HOST=$1
PING_COUNT=5
ping -c $PING_COUNT $HOST | tail -1 | awk '{print $4}' | cut -d '/' -f 2
这个脚本接受一个主机名作为参数,并使用ping命令发送5个ICMP请求。它解析ping命令的输出并返回平均延迟时间。
5.3 网络带宽评估与网络规划支持
了解网络带宽使用情况对于有效管理网络资源至关重要。评估当前的带宽使用可以帮助网络规划者预测未来需求并进行合理规划。
5.3.1 带宽评估的常用方法
评估带宽使用的方法多种多样,可以使用简单的工具如iftop、nethogs来实时监控带宽使用情况,也可以使用更复杂的网络流量分析工具如Wireshark或SolarWinds来分析长期趋势。
5.3.2 网络规划与未来发展的支持
网络规划是一个持续的过程,涉及到对现有网络性能数据的分析以及对未来需求的预测。通过使用自动化工具收集数据并生成报告,网络规划者可以更好地理解当前的网络状态和未来的扩展需求。这有助于做出决策,比如增加带宽、升级硬件或调整网络架构。
本文还有配套的精品资源,点击获取
简介:服务器多ping工具专为系统管理员和网络工程师设计,允许同时对多台主机执行ping命令,快速诊断网络问题,节省手动操作时间。此工具通过自动化批处理ping操作,支持统计报告生成和定时任务,为网络故障排查、性能监控、带宽评估和网络规划提供重要数据支持。用户通过配置主机列表和参数来运行工具,以实现快速的网络状态了解。
本文还有配套的精品资源,点击获取







评论前必须登录!
注册