 网硕互联帮助中心
网硕互联帮助中心DiT 相对于 U-Net 的优势
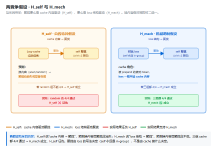
全局自注意力 vs. 局部卷积
- U-Net 依赖卷积和池化/上采样来逐层扩大感受野,捕捉全局信息需要堆叠很多层或借助跳跃连接(skip connections)。
- DiT 在每个分辨率阶段都用 Transformer 模块(多头自注意力 + MLP)替代卷积模块,可直接在任意层级通过自注意力跨越整张图像的所有 Patch,实现真正的全局信息聚合。
- 优势:
- 更快地捕捉远距离像素之间的相关性
- 细粒度地动态调整注意力权重,不再受限于固定卷积核大小
统一的分辨率处理 vs. 编码-解码跳跃
- U-Net 典型的 “编码器–解码器” 结构:编码阶段下采样压缩特征,解码阶段再通过跨层跳跃连接恢复空间细节。
- DiT 采用一系列保持 Token 数量不变的 Transformer Blocks,在同一分辨率上直接对 Patch Token 做深度变换,最后再做少量重构。
- 优势:
- 避免多次下采样/上采样带来的信息丢失与插值伪影
- 跨尺度信息融合更加平滑,不依赖显式的 skip connections
时间/条件嵌入的灵活注入
- U-Net 通常用 AdaGN、FiLM 或时序注意力将噪声步数(timestep)以及类别/文本条件注入到卷积分支中。
- DiT 可将时序(sinusoidal‐PE)和条件(class token 或 cross‐attention 查询)当作额外的 Token,或通过 LayerNorm 与 MLP 融合,形式更统一。
- 优势:
- 融合机制简单一致,易扩展到多种条件(如文本、姿态图、属性向量)
- 条件信息能直接参与自注意力计算,不再受限于卷积核的局部范围
可扩展性与预训练优势
- U-Net 卷积核、通道数需针对扩散任务从头设计与训练。
- DiT 可以借鉴或直接微调已有的视觉 Transformer(如 ViT、Swin)预训练权重,在大规模图像数据上先行学习表征,再做扩散任务微调。
- 优势:
- 少量数据即可获得优异效果,训练收敛更快
- 参数规模与性能可通过堆叠 Transformer Block、增加 Head 数或 Hidden Size 线性扩展
计算效率与实现简洁
- U-Net 的多分辨率跳跃连接和卷积核实现较为复杂,尤其在多尺度下容易引入内存峰值。
- DiT 模型主体仅由标准 Transformer Block 组成,硬件上对自注意力有高度优化(如 FlashAttention),在大尺寸输入时并行更高效。
- 优势:
- 代码结构统一简洁,便于维护和扩展
- 在高分辨率下,自注意力+线性层组合在特定实现下比多次卷积+上采样更省内存
总结
DiT 将 Transformer 的全局自注意力与扩散模型紧密结合,突破了 U-Net 局部卷积的固有限制,使得模型在捕捉远程依赖、条件信息融合、可扩展性和预训练转移上具备显著优势,也为更高分辨率下的高质量图像生成提供了更优的架构选择。
自回归生成模型 vs. 扩散模型 的区别
生成过程:顺序 vs. 并行
- 自回归模型:
- 将图像的联合分布分解为一系列条件分布:
p
(
x
)
=
∏
i
=
1
N
p
(
x
i
∣
x
<
i
)
p(x)=\\prod_{i=1}^Np(x_i\\mid x_{<i})
p(x)=i=1∏Np(xi∣x<i) - 生成时严格按照先后次序,一个像素(或一个 patch/token)接着一个像素地预测,需要在每一步等待前一步完成,完全串行。
- 将图像的联合分布分解为一系列条件分布:
- 扩散模型(U-Net/DiT):
- 将生成看作从纯噪声逐步去噪的过程,可以在每个去噪步骤中并行预测全图像素(或全 Token)。
- 每一步可以并行预测全图像素/Token,内部无序列化依赖。
架构:因果掩码 vs. 全局交互
- 自回归模型:
- 核心是因果(causal)自注意力或卷积(如 PixelCNN),只允许看到已生成部分。
- 通常使用 Transformer Decoder(带因果 Mask)或 PixelRNN/PixelCNN。
- 扩散模型:
- U-Net 用多层编码–解码卷积,DiT 用堆叠的 Transformer Blocks(无因果 Mask)做全局自注意力。
- 它们不需要在同一张图内部做序列化生成,因此注意力和卷积都可跨全图自由运作。
训练目标:最大似然 vs. 去噪匹配
- 自回归模型:
- 直接对像素/Token 做交叉熵或负对数似然最大化。 模型学会准确预测下一个像素的离散分布。
- 扩散模型:
- 对加噪—去噪过程建模,常用 score matching (估计噪声分布的梯度)或均方误差去噪目标。
- 无需离散化像素分布,训练时需设计噪声调度(noise schedule)和时间步(timestep)嵌入。
采样速度与效率
- 自回归模型:
- 序列长度越长,生成时间线性增长,每一步都需一次前向推理,推理速度受限于最小单位(像素/patch)的顺序依赖。
- 扩散模型:
- 虽然要迭代多步(通常数十到数百步),但每步能一次性预测整张图,且可以借助并行硬件与优化(如 FlashAttention、批量去噪)加速。
生成质量与灵活性
- 自回归模型:
- 在小分辨率下可达高像素级一致性,但高分辨率下难以捕捉全局结构。
- 扩散模型:
- 多步去噪的随机性和全局信息交互,能生成更丰富、多样化的全局结构,高分辨率表现优异。
- DiT 优势:
- 利用 Transformer 预训练表征,进一步提升细节一致性和可控性。
总结:
自回归生成模型强调“一步一步来”,靠因果掩码和离散最大似然保证每个像素都被精确建模;而扩散模型(无论是传统 U-Net 还是基于 Transformer 的 DiT)则通过“同时去噪全图、多次迭代”的方式,结合连续噪声建模与并行全局交互,实现了更高效、更灵活的高分辨率图像生成。
| 架构 | 编码-解码卷积(多尺度 + skip) | 多层 Transformer Block(Patch Token) | Transformer Decoder / PixelCNN |
| 生成过程 | 从噪声并行去噪,多步迭代 | 从噪声并行去噪,多步迭代 | 串行逐像素/逐 Token 生成 |
| 注意力范围 | 局部卷积,靠层级扩展感受野 | 全局自注意力,任意 Patch 交互 | 因果 Mask,仅能看到已生成内容 |
| 条件注入 | AdaGN/FiLM/时序注意力 | 条件 Token + Sinusoidal PE 统一注入 | Prefix Prompt 或在输入端拼接 |
| 训练目标 | MSE 去噪 / Score Matching | MSE 去噪 / Score Matching | 交叉熵(NLL)最大似然 |
| 推理效率 | 每步并行,需几十至上百步 | 每步并行,需几十至上百步 | 串行生成,步数 ∝ 序列长度 |
| 预训练优势 | 通常从头训练 | 可微调 ViT/Swin 等大规模预训练模型 | 可微调 GPT 等语言大模型 |
| 适用场景 | 中分辨率图像生成 | 高分辨率、需要全局一致性 | 低分辨率、追求像素级一致性 |
简而言之,U-Net 扩散利用多尺度卷积去噪,DiT 则在各尺度用全局自注意力替代卷积,从而更有效地捕捉长程依赖;自回归模型则通过因果 Mask 串行生成,保证像素级最大似然。扩散模型每步可并行预测全图,速度优势明显;自回归虽然精度高,但推理必须等上一步完成,效率较低。DiT 还能直接复用 ViT/Swin 等预训练模型加速收敛,适合高分辨率图像生成。



评论前必须登录!
注册