 网硕互联帮助中心
网硕互联帮助中心添加新成员
添加成员的过程有两个步骤:
- 通过 HTTP members API 添加新成员到集群, gRPC members API, 或者 etcdctl member add 命令.
- 使用新的层原配置启动新成员,包括更新后的成员列表(以后成员加新成员)
使用 etcdctl 指定 name 和 advertised peer URLs 来添加新的成员到集群:
$ etcdctl member add infra3 http://10.0.1.13:2380 added member 9bf1b35fc7761a23 to cluster
ETCD_NAME="infra3" ETCD_INITIAL_CLUSTER="infra0=http://10.0.1.10:2380,infra1=http://10.0.1.11:2380,infra2=http://10.0.1.12:2380,infra3=http://10.0.1.13:2380" ETCD_INITIAL_CLUSTER_STATE=existing
etcdctl 已经给出关于新成员的集群信息并打印出成功启动它需要的环境变量。现在用关联的标记为新的成员启动新 etcd 进程:
$ export ETCD_NAME="infra3" $ export ETCD_INITIAL_CLUSTER="infra0=http://10.0.1.10:2380,infra1=http://10.0.1.11:2380,infra2=http://10.0.1.12:2380,infra3=http://10.0.1.13:2380" $ export ETCD_INITIAL_CLUSTER_STATE=existing $ etcd –listen-client-urls http://10.0.1.13:2379 –advertise-client-urls http://10.0.1.13:2379 –listen-peer-urls http://10.0.1.13:2380 –initial-advertise-peer-urls http://10.0.1.13:2380 –data-dir %data_dir%
新成员将作为集群的一部分运行并立即开始赶上集群的其他成员。
如果添加多个成员,最佳实践是一次配置单个成员并在添加更多新成员前验证它正确启动。
如果添加新成员到一个节点的集群,在新成员启动前集群无法继续工作,因为它需要两个成员作为galosh才能在一致性上达成一致。这个行为仅仅发生在 etcdctl member add 影响集群和新成员成功建立连接到已有成员的时间内。
1.查看集群状态 获取主节点和故障节点id
ETCDCTL_API=3 ./etcdctl –cacert=/etc/kubernetes/ssl/new-ca.pem –cert=/etc/kubernetes/ssl/etcd.pem –key=/etc/kubernetes/ssl/etcd-key.pem –endpoints="https://192.168.7.132:2379,https://192.168.7.134:2379,https://192.168.7.135:2379" endpoint status cluster-health –write-out=table
ETCDCTL_API=3 ./etcdctl –cacert=/etc/kubernetes/ssl/new-ca.pem –cert=/etc/kubernetes/ssl/etcd.pem –key=/etc/kubernetes/ssl/etcd-key.pem –endpoints="https://192.168.7.132:2379,https://192.168.7.134:2379,https://192.168.7.135:2379" endpoint status cluster-health –write-out=table

查看故障节点
ETCDCTL_API=3 ./etcdctl –cacert=/etc/kubernetes/ssl/new-ca.pem –cert=/etc/kubernetes/ssl/etcd.pem –key=/etc/kubernetes/ssl/etcd-key.pem –endpoints="https://192.168.7.132:2379,https://192.168.7.134:2379,https://192.168.7.135:2379" endpoint
health –write-out=table
ETCDCTL_API=3 ./etcdctl –cacert=/etc/kubernetes/ssl/new-ca.pem –cert=/etc/kubernetes/ssl/etcd.pem –key=/etc/kubernetes/ssl/etcd-key.pem –endpoints="https://192.168.7.132:2379,https://192.168.7.134:2379,https://192.168.7.135:2379" endpoint
health –write-out=table
2.剔除故障节点
ETCDCTL_API=3 etcdctl –endpoints="https://172.16.169.82:2379" –cacert=/etc/etcd/ssl/ca.pem –cert=/etc/etcd/ssl/etcd.pem –key=/etc/etcd/ssl/etcd-key.pem member remove 971a0fee3d275c5
ETCDCTL_API=3 etcdctl –endpoints="https://172.16.169.82:2379" –cacert=/etc/etcd/ssl/ca.pem –cert=/etc/etcd/ssl/etcd.pem –key=/etc/etcd/ssl/etcd-key.pem member remove 971a0fee3d275c5
验证是否剔除成功
ETCDCTL_API=3 ./etcdctl –cacert=/etc/kubernetes/ssl/new-ca.pem –cert=/etc/kubernetes/ssl/etcd.pem –key=/etc/kubernetes/ssl/etcd-key.pem –endpoints="https://192.168.7.132:2379,https://192.168.7.134:2379,https://192.168.7.135:2379" member list –write-out=table
ETCDCTL_API=3 ./etcdctl –cacert=/etc/kubernetes/ssl/new-ca.pem –cert=/etc/kubernetes/ssl/etcd.pem –key=/etc/kubernetes/ssl/etcd-key.pem –endpoints="https://192.168.7.132:2379,https://192.168.7.134:2379,https://192.168.7.135:2379" member list –write-out=table
3.重新添加故障节点
3.1 检查旧etcd数据并清空
rm -rf etcd3.etcd/
3.2 修改要加入集群etcd3的启动参数
vi /etc/etcd/etcd.conf并保存
将etcd的–initial-cluster-state启动参数,改为–initial-cluster-state=existing
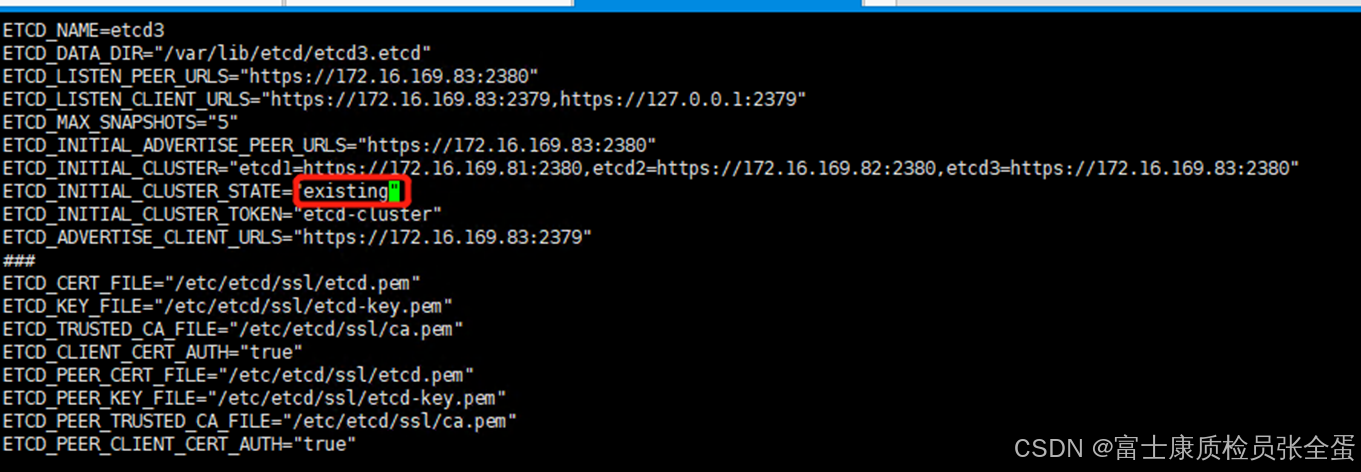
3.3 从etcd-master拷贝证书
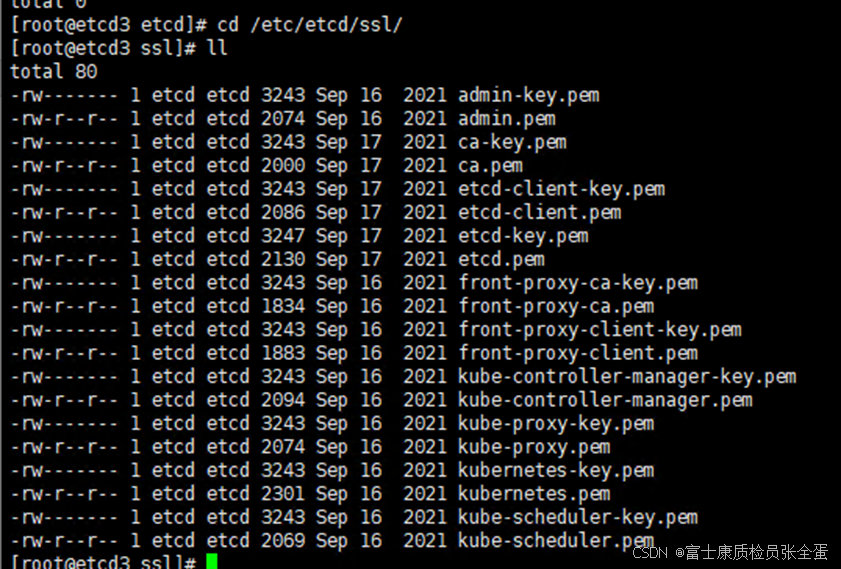
scp -rp etcd1:/etc/etcd/ssl/ /etc/etcd/
拷贝后检查etcd证书所属用户
3.4 重新添加故障节点etcd3 注意:etcd3为etcd.conf中ETCD_NAME
ETCDCTL_API=3 etcdctl –endpoints="https://172.16.169.82:2379" –cacert=/etc/etcd/ssl/ca.pem –cert=/etc/etcd/ssl/etcd.pem –key=/etc/etcd/ssl/etcd-key.pem member add etcd3 –peer-urls=https://172.16.169.83:2380
3.5 重启服务验证成功
systemctl daemon-reload systemctl restart etcd
二. 备份恢复方式重做集群
备注:此方式有可能导致数据丢失,亲身经历,尽量使用第一种方式。
备份ETCD集群时,只需要备份一个ETCD数据,然后同步到其他节点上 恢复ETCD数据时,每个节点都要执行恢复命令 恢复顺序:停止kube-apiserver –> 停止ETCD –> 恢复数据 –> 启动ETCD –> 启动kube-apiserve
etcd资源文件在/var/lib/etcd下,有两个文件夹
- snap:存放快照数,etcd防止WAL文件过多而设置的快照,存储etcd数据状态
- wal:存放预写式日志,最大的作用是记录了整个数据变化的全部历程。在etcd中,所有数据的修改在提交前,都要先写入到WAL中
1、查看健康节点
ETCDCTL_API=3 /opt/etcd/bin/etcdctl –cacert=/opt/etcd/ssl/etcd-ca.pem –cert=/opt/etcd/ssl/server.pem –key=/opt/etcd/ssl/server-key.pem –endpoints="https://192.168.15.215:2379,https://192.168.15.216:2379,https://192.168.15.217:2379" endpoint health –write-out=table
2、在健康节点上备份etcd数据
ETCDCTL_API=3 etcdctl snapshot save backup.db \\
–cacert=/opt/etcd/ssl/etcd-ca.pem \\
–cert=/opt/etcd/ssl/server.pem \\
–key=/opt/etcd/ssl/server-key.pem \\
–endpoints="https://192.168.15.215:2379"
3、将备份后的文件复制到其他etcd节点下
for i in {etcd2,etcd3};do scp backup.db root@i:/root ;done
4、恢复etcd数据 恢复之前需要先关闭apiserver和etcd,删除etcd数据文件
systemctl stop kube-apiserver #停止apiserver
systemctl stop etcd #停止etcd
rm -rf opt/etcd/data/* #删除数据目录文件,根据实际情况
在节点1执行恢复命令,如下:
ETCDCTL_API=3 etcdctl snapshot restore backup.db \\
–name etcd-1 \\
–initial-cluster="etcd-1=https://192.168.15.215:2380,etcd-2=https://192.168.15.216:2380,etcd-3=https://192.168.15.217:2380" \\
–initial-cluster-token=etcd-cluster \\
–initial-advertise-peer-urls=https://192.168.15.215:2380 \\
–data-dir=/opt/etcd/data
在节点2执行恢复命令,如下:
ETCDCTL_API=3 etcdctl snapshot restore backup.db \\
–name etcd-2 \\
–initial-cluster="etcd-1=https://192.168.15.215:2380,etcd-2=https://192.168.15.216:2380,etcd-3=https://192.168.15.217:2380" \\
–initial-cluster-token=etcd-cluster \\
–initial-advertise-peer-urls=https://192.168.15.216:2380 \\
–data-dir=/opt/etcd/data
在节点3执行恢复命令,如下:
ETCDCTL_API=3 etcdctl snapshot restore backup.db \\
–name etcd-3 \\
–initial-cluster="etcd-1=https://192.168.15.215:2380,etcd-2=https://192.168.15.216:2380,etcd-3=https://192.168.15.217:2380" \\
–initial-cluster-token=etcd-cluster \\
–initial-advertise-peer-urls=https://192.168.15.217:2380 \\
–data-dir=/opt/etcd/data
恢复完成后,重启kube-apiserver和etcd,如下:
systemctl start kube-apiserver
systemctl start etcd
5、查看集群状
ETCDCTL_API=3 /opt/etcd/bin/etcdctl –cacert=/opt/etcd/ssl/etcd-ca.pem –cert=/opt/etcd/ssl/server.pem –key=/opt/etcd/ssl/server-key.pem –endpoi




评论前必须登录!
注册