 网硕互联帮助中心
网硕互联帮助中心多线程服务器分析——Reactor线程模型和性能分析(三)
4 案例实现
【代码:reactor/distribute_storage】 在这里先叠个甲:以下讲述的分布式存储并非业界真实使用的分布式系统,只是在设计上具有相似之处,都有网关、数据管理,元数据管理等等,因此代码部分主要着眼于讲述的线程模型的实现,很多异常情况是没有考虑到的,以及针对写失败情况的垃圾回收也并没有实现,并且可能包含一些未知的bug,请读者海涵。
4.1 Gateway网关进程的启动
下面将根据前面所有的内容实现一个基于reactor + 线程池的分布式存储中的写请求,也就是上传文件。这个分布式存储系统在第二章多线程服务器分析——Reactor线程模型和性能分析(二)中的3.4节描述了其业务逻辑和接口设计等等,在这里我们简单回顾一下上传文件的逻辑过程: 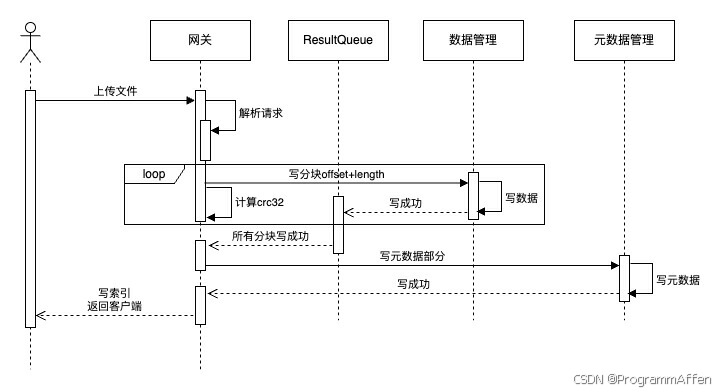 网关(Gateway):负责接收来自客户端的请求并处理。 数据管理(DataManager):负责存储上传的数据。 元数据管理(MetaDataManager):负责存储上传数据的元数据信息,包括文件大小、创建时间等等。 从客户端上传文件,必然不可能是一整个文件一下子写入到socket中,而是分块读取,分块上传。当请求到达网关层时,发现客户端是的请求是上传文件,那么就开始接收,接收一个分块就传递给数据管理层,直到最后一个分块在数据管理层写入成功或者中途某个分块处理失败,数据管理层将该信息返回给网关层,如果失败网关层直接返回用户写入失败,如果成功则向元数据管理层写入元数据,元数据管理层写入成功再返回给网关,直到这时网关层才能返回给用户该文件写入成功的响应。 我们就从网关层的main函数开始,讲述网关进程的启动和运行机制:
网关(Gateway):负责接收来自客户端的请求并处理。 数据管理(DataManager):负责存储上传的数据。 元数据管理(MetaDataManager):负责存储上传数据的元数据信息,包括文件大小、创建时间等等。 从客户端上传文件,必然不可能是一整个文件一下子写入到socket中,而是分块读取,分块上传。当请求到达网关层时,发现客户端是的请求是上传文件,那么就开始接收,接收一个分块就传递给数据管理层,直到最后一个分块在数据管理层写入成功或者中途某个分块处理失败,数据管理层将该信息返回给网关层,如果失败网关层直接返回用户写入失败,如果成功则向元数据管理层写入元数据,元数据管理层写入成功再返回给网关,直到这时网关层才能返回给用户该文件写入成功的响应。 我们就从网关层的main函数开始,讲述网关进程的启动和运行机制:
【代码:reactor/distribute_storage/gateway/gateway_main.cc】
int main() {
GWGlobalContext* context = new GWGlobalContext(THREAD_NUM, GATEWAY_REQUEST_HANDLER);
Server<GatewayRequestCB, GWRequestDispatcher> server =
Gateway<GatewayRequestCB, GWRequestDispatcher>(8890, SUBLOOP_NUM, context);
server.start();
return 0;
}
首先是一个GWGlobalContext类,这是一个基础类,存储所有的类可能都需要的数据结构,例如各个进程的ip和port,用于处理各种任务的线程池,这里线程池有两个,一个是接收请求的request_handler,另一个则是接收处理请求过程中产生的阻塞任务: 【代码:reactor/distribute_storage/common/Context.h】
class GlobalContext {
public:
Address gateway_adr;
Address data_mgr_adr;
Address metadata_mgr_adr;
int data_shard_num;
int metadata_shard_num;
ThreadPool* thread_pool;
ThreadPool* request_handler;
GlobalContext() {}
GlobalContext(int thread_num, int handler_num) :
thread_pool(new ThreadPool(thread_num)),
request_handler(new ThreadPool(handler_num)),
data_shard_num(DATA_SHARDS),
metadata_shard_num(META_DATA_SHARDS),
gateway_adr(Address(std::string(GATEWAY_IP), GATEWAY_PORT)),
data_mgr_adr(Address(std::string(DATA_MGR_IP), DATA_MGR_PORT)),
metadata_mgr_adr(Address(std::string(METADATA_MGR_IP), METADATA_MGR_PORT)) {}
};
接下来就要启动server了,Server是一个模板类,用于实现不同的RequestCB和RequestDispatcher,这两个类的作用分别是什么呢? RequestDispatcher比较好理解,字面意思理解就是分发请求,因为有不同类型的请求,PUT、GET,POST等等,Dispatcher就是为了给这些请求配一个对应的handler,以下的内容在多线程服务器分析——Reactor线程模型和性能分析(三)的3.7.1节有详细的讲述,这里从启动server开始简单的过一下: 【代码:reactor/distribute_storage/gateway/Gateway.h】
RequestHandler* GWRequestDispatcher::get_handler(ReqMethod method, std::shared_ptr<RawRequest> request) {
if (method == ReqMethod::TEST)
return new TestRequestHandler(this, request);
if (method == ReqMethod::PUT)
return new PutRequestHandler(this, request);
if (method == ReqMethod::POST)
return new PostRequestHandler(this, request);
// TODO implement other request methods
return nullptr;
}
而针对不同类型的请求,细分一下可能有不同的操作,例如GET请求下可以get_data或者get_metadata,分别是获取数据和元数据,因此又需要handler区分一下具体的Op: 【代码:reactor/distribute_storage/gateway/Gateway.cc】
class TestRequestHandler : public GWRequestHandler {
public:
TestRequestHandler(RequestDispatcher* req_disp, std::shared_ptr<RawRequest> req) : GWRequestHandler(req_disp, req) {}
GatewayOP* get_op(std::map<std::string, std::string>* header_data) override {
...
if (op_type == "ping_gw") {
return new TestPingGatewayOp(dispatcher->_ctx, this);
}
...
}
void send_response() override;
};
例如上面的Op就是约定客户端请求中带有『ping_gw』就表示TEST请求类型下的检验网关可用性的Op,上面这些都是针对网关特有的数据结构,其基类都来自于reactor/distribute_storage/common/server.h中的Op、RequestHandler、RequestDispatcher类。
回到RequestCB,这个数据结构解释起来有点复杂,但其实就是之前提到的EventLoop中的EventCallback类的子类,也就是当socket发生可读事件(即接收到来自客户端数据)时执行的回调函数:
class RequestCB : public EventCallback {
protected:
int socket_fd;
RequestDispatcher* _dispatcher;
public:
...
virtual void handle_request() {};
void do_callback() override {
_loop->remove_poll(socket_fd);
handle_request();
_loop->remove_event_from_map(socket_fd);
}
};
也就是说当socket发生可读事件的时候,会调用do_callback()函数,最终实现请求逻辑的则是handle_request()函数,也就是说,不同的server只需要重写handle_request()函数即可,为什么在执行handler_request()函数之前要执行_loop->remove_poll(socket_fd)呢? 那是因为来自客户端的数据可能是源源不断的,那么epoll监听的时候就会一直有可读事件,导致其他的socket上传来的数据得不到处理。
在看网关实现的handler_request()函数之前,我们接着来Server是如何启动的:
template<typename CB, typename DISPATCH>
class Server {
...
void start() {
main_loop = new EventLoop(true, sub_loop_count);
listen_sock = socket(AF_INET, SOCK_STREAM, 0);
...
_dispatcher = new DISPATCH(ctx);
EventRef main_ev = std::make_shared<Event>(listen_sock, new SocketEventCB<CB>(listen_sock, main_loop, _dispatcher));
main_loop->add_event(listen_sock, main_ev, false, false);
std::vector<EventLoop*>& subloops = main_loop->get_subloop();
for(int i = 0; i < sub_loop_count; ++i) {
subloops[i]->start();
}
main_loop->start();
}
};
我们将多线程服务器分析——Reactor线程模型和性能分析(三)的3.7.1节中的内容用图来表示,加深一下理解: 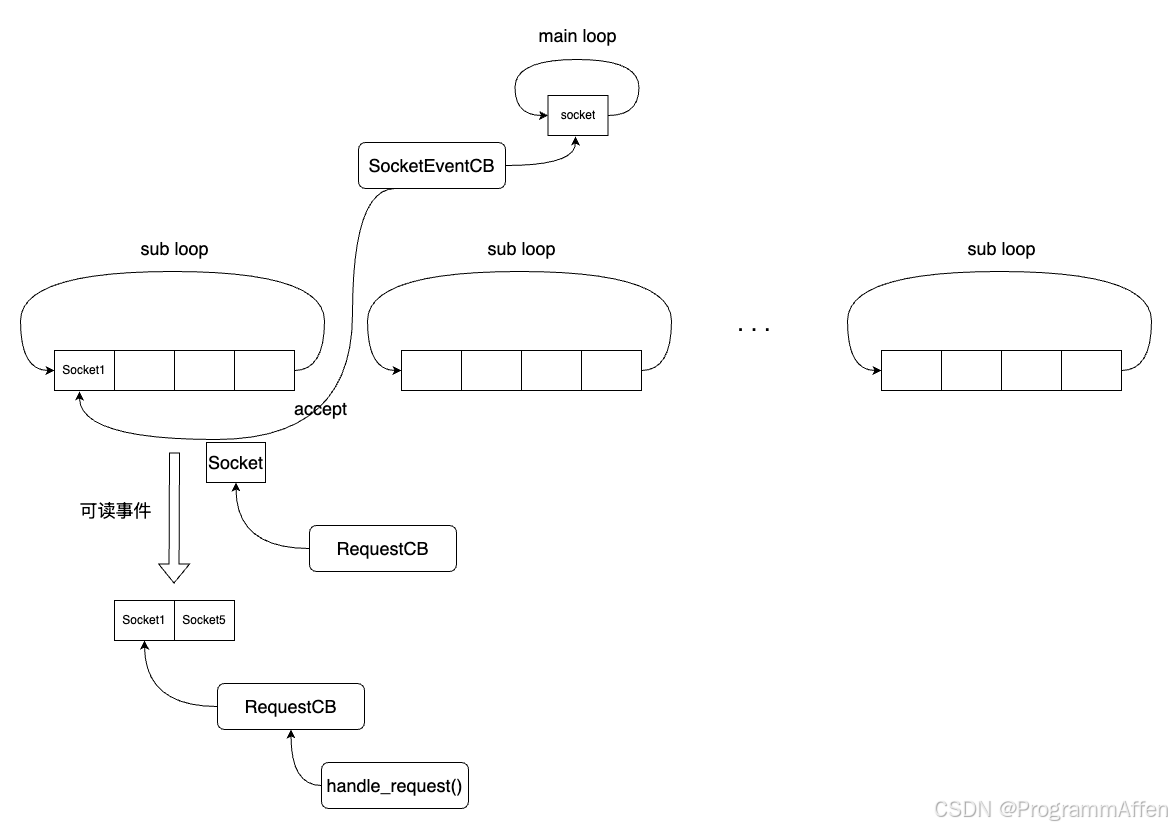 在server启动的时候,先启动一个main loop和多个sub loop,main loop只监听一个socket,就是负责accept客户端请求的那个socket,与这个socket绑定的回调类则是SocketEventCB,它的职责是将accept产生的socket移交给sub loop,由sub loop负责监听客户端来自客户端请求的数据;而跟这个socket绑定的回调类就是RequestCB,当sub loop监听到可读事件的时候,就将可读的socket拿出来按顺序执行它们的回调函数,回调函数最终执行的就是handle_request(),也就是说,所有的业务逻辑都在handle_request()函数中实现。
在server启动的时候,先启动一个main loop和多个sub loop,main loop只监听一个socket,就是负责accept客户端请求的那个socket,与这个socket绑定的回调类则是SocketEventCB,它的职责是将accept产生的socket移交给sub loop,由sub loop负责监听客户端来自客户端请求的数据;而跟这个socket绑定的回调类就是RequestCB,当sub loop监听到可读事件的时候,就将可读的socket拿出来按顺序执行它们的回调函数,回调函数最终执行的就是handle_request(),也就是说,所有的业务逻辑都在handle_request()函数中实现。
4.2 上传文件逻辑的实现
接下来就是针对handle_request()函数的实现:
void GatewayRequestCB::handle_request() {
auto request = std::make_shared<RawRequest>(socket_fd);
int res = request->get_header();
...
RequestHandler* handler = _dispatcher->get_handler(request->header.method, request);
...
Op* op = handler->get_op(&(request->header.self_define));
...
op->req = request;
std::shared_ptr<Op> req_op(op);
std::shared_ptr<RequestHandler> req_handler(handler);
_dispatcher->_ctx->request_handler->enqueue_task(new RequestTask(req_op, req_handler));
}
整个函数并不复杂,就是按照根据请求获取RequestHandler和Op的过程,并且在最后将二者封装在线程池的Task中加入线程池,由Worker线程执行逻辑和响应:
class RequestTask : public ThreadPool::Task {
private:
std::shared_ptr<Op> req_op;
std::shared_ptr<RequestHandler> req_handler;
public:
...
void do_task() override {
req_op->execute();
req_handler->send_response();
}
};
有一点值得注意,在多线程服务器分析——Reactor线程模型和性能分析(三)的3.7.1中GatewayRequestCB::handle_request()函数最后的部分是这样的:
void GatewayRequestCB::handle_request() {
...
op->execute(); // 执行逻辑
handler->send_response(); // 返回响应
}
为什么要改成线程池来执行处理请求的逻辑和响应? 首先,EventLoop针对EventCallBack的执行一直是在一个线程中进行的:
void EventLoop::handle_events() {
while (running) {
/* execute events with fd */
int nfds = poller.wait_event();
...
for (int i = 0; i < nfds; ++i) {
int fd = poller.events[i].data.fd;
if (event_map.find(fd) != event_map.end()) {
EventRef ev = event_map[fd];
ev->callback();
}
}
/* execute none fd events */
...
}
return;
}
ev->callback()的执行是通过遍历socket绑定的回调函数,因此执行回调函数的过程中不能出现阻塞,否则会影响后面回调函数的执行。 接下来看文件上传的执行,首先处理PUT请求的是PutRequestHandler,上传文件的Op则是PutFileOp,真正的处理逻辑是PutFileOp::execute(),首先检查一些用户的输入,包括文件名、文件大小等等:
void PutFileOp::execute() {
// get file name and size from header
int ret;
auto& header_data = req->header.self_define;
if (header_data.find("filename") == header_data.end() ||
header_data.find("filesize") == header_data.end()) {
_handler->set_response_code(BAD_REQUEST);
_handler->set_response_data(
std::map<std::string, std::string>{{"result",
"lack of file name or file size"}}
);
return;
}
int file_size;
if (!str_to_int(header_data["filesize"], file_size)) {
_handler->set_response_code(BAD_REQUEST);
return;
}
...
}
接下来则是通过socket读取用户发来的文件的数据部分:
while (total_read < file_size) {
ret = req->get_raw_data(&read_str, timeout);
...
// send the chunk read from socket to data manager
send_data.append(read_str);
if (send_data.size() >= DATA_FLUSH_SIZE || file_size – offset <= DATA_FLUSH_SIZE) {
if (offset == 0) {
ret = client->flush_data_chunk(offset, header_data["filename"], file_size, send_data, req_id, false);
...
} else {
PutFileOp::PutDataChunkTask* task = new PutFileOp::PutDataChunkTask(
context,
client,
offset,
send_data,
header_data["filename"],
req_id,
file_size
);
context->thread_pool->enqueue_task(task);
}
...
}
在客户端上传文件的时候,是将文件读一段,上传一段,整个文件的分段是按照顺序传过来的,tcp层会保证传递的顺序不会乱掉: 【代码:reactor/distribute_storage/client/client_interface.cc】
int GatewayClient::upload_file(std::string file_path, std::string file_name) {
...
while (file) {
...
buffer[CHUNK_SIZE] = '\\0';
std::streamsize bytesRead = file.gcount();
if (bytesRead > 0) {
// send to gateway
std::string to_send = std::string(buffer);
ret = request.send_raw_body(to_send);
if (ret < 0)
break;
}
}
...
}
而网关层下发给数据管理层的之后,采用多线程的模式写入同一个文件,因此必须采用offset + length的形式记录每一个分段,因为网关层并不是针对同一个socket写入所有分段,也就不能保证分段按照顺序抵达数据管理层。而将读到的数据下刷的函数就是ManagerClient::flush_data_chunk():
int ManagerClient::flush_data_chunk(off_t offset, std::string filename, int filesize,
std::string& data, std::string req_id, bool asio) {
...
if (asio)
header["io_type"] = "aio";
else
header["io_type"] = "bio";
request.set_request_header(header);
int ret = request.send_header("PUT", data.size());
...
}
这个函数本身没什么好说的,只有一个asio参数值得思考一下,这个参数的作用是决定下刷这一段数据是同步的还是异步的,为什么要设置这样一个参数? 首先来想,从网关层下刷的数据分段,需不需要等待数据管理层写入完成再写下一段?显然是不需要的,那这样多线程的写入就失去了意义,也就是说每一段的写入对于网关层来说都是同步的,写入的总时间为:
T
i
m
e
t
o
t
a
l
=
分块数
×
(
下刷到数据管理层
+
数据管理层写入
+
数据管理层返回响应
)
Time_{total} = 分块数 \\times (下刷到数据管理层 + 数据管理层写入 + 数据管理层返回响应)
Timetotal=分块数×(下刷到数据管理层+数据管理层写入+数据管理层返回响应) 这与接收分块依次下发没有任何区别,因此需要将下刷的请求改为异步,即数据管理层接收到下刷数据的时候只是返回给网关层:『我接收到了你下发的数据』,而不是返回写入成功或者失败的响应,而当最后一个分块写入成功的时候或者中途某个分块写入失败,再给网关层发一个请求告知这个文件的写入结果: 【代码reactor/data_manager/Datamanager.cc】
void PutDataChunkOP::execute() {
if (header_data.find("io_type") != header_data.end() && header_data["io_type"] == "aio") {
// send the write_data_by_offset to threadpool
DataMgrOP::AsyncWriteChunk* task = new DataMgrOP::AsyncWriteChunk(context, header_data["req-id"], chunk);
context->thread_pool->enqueue_task(task);
_handler->set_response_code(REQ_RECEIVED);
} else if (header_data.find("io_type") != header_data.end() && header_data["io_type"] == "bio") {
context->register_req(header_data["req-id"], header_data["target"] + header_data["filename"], filesize);
bool last_chunk;
ret = write_data_by_offset(header_data["req-id"], chunk, offset, last_chunk);
if (ret < 0) {
_handler->set_response_code(–ret);
_handler->set_response_data(std::map<std::string, std::string>{{"result", "write head data failed"}});
return;
}
if (last_chunk)
_handler->set_response_code(FULL_REQ_SUCCESS);
else
_handler->set_response_code(GWOP_SUCCESS);
} else {
_handler->set_response_code(EINVALIDDATA);
_handler->set_response_data(std::map<std::string, std::string>{{"result", "invalid io type"}});
}
}
其中write_data_by_offset()函数就是写入一个分块,当看到请求是bio,也就是同步请求时,直接调用,并返回给网关层写入的结果;如果是aio则将其放入线程池中,返回REQ_RECEIVED表示收到了分块数据。 回到网关层下发分块:
if (offset == 0) {
ret = client->flush_data_chunk(offset, header_data["filename"], file_size, send_data, req_id, false);
...
}
当第一个分块下发的时候,采用同步请求,在数据管理层创建好文件再继续多线程写入。
那么网关层是如何得知数据管理层写入的结果呢?
这就需要使用异步回调的概念了:
void PutFileOp::execute() {
...
while (total_read < file_size) {
...
if (send_data.size() >= DATA_FLUSH_SIZE || file_size – offset <= DATA_FLUSH_SIZE) {
if (offset == 0) {
ret = client->flush_data_chunk(offset, header_data["filename"], file_size, send_data, req_id, false);
...
} else {
PutFileOp::PutDataChunkTask* task = new PutFileOp::PutDataChunkTask(
...
}
context->thread_pool->enqueue_task(task);
}
if (file_size – offset <= DATA_FLUSH_SIZE && offset != 0) {
waiter = std::make_shared<AioCompleteWaiter>();
std::shared_ptr<PutChunkcompletion> completion = std::make_shared<PutChunkcompletion>(waiter);
GWGlobalContext* context = dynamic_cast<GWGlobalContext*>(ctx);
context->complete_mgr->register_completion(req_id, completion);
}
...
}
// wait for finish or fail
if (waiter.use_count()) {
waiter->wait_for_notify();
}
}
当网关层下刷最后一个分块的时候(file_size – offset <= DATA_FLUSH_SIZE),会设置一个AioCompleteWaiter和AioCompletion: 【代码:reactor/distribute_storage/gateway/manager_client/mgr_client_interface.h】
class AioCompleteWaiter {
public:
std::mutex mtx;
std::condition_variable cv;
bool finish{false};
int ret;
std::map<std::string, std::string> results;
void wait_for_notify() {
std::unique_lock<std::mutex> lock(mtx);
while (!finish) {
//tm
std::cout << "finish: " << finish << std::endl;
cv.wait(lock);
}
}
void notify() {
std::unique_lock<std::mutex> lock(mtx);
finish = true;
cv.notify_one();
}
};
class AioCompletion {
protected:
int retcode;
std::map<std::string, std::string> result_data;
public:
virtual void do_completion() {}
AioCompletion() {}
void set_retcode(int ret) { retcode = ret; }
void set_results(std::map<std::string, std::string> res) { result_data = res; }
};
AioCompletion的作用是当请求返回时,执行对应的回调函数,回调函数则是通过一个随机出来的16位字符串作为request id记录在CompletionManager中:
class CompletionManager {
private:
std::mutex mtx;
std::map<std::string, std::shared_ptr<AioCompletion>> completions;
public:
bool register_completion(std::string req_id, std::shared_ptr<AioCompletion> completion) {
std::lock_guard<std::mutex> lock(mtx);
if (completions.find(req_id) != completions.end())
return false;
completions[req_id] = completion;
return true;
}
...
};
当网关层下发分块数据时,请求中会带有这个16位的request id,同时数据管理层执行完毕也会携带这个request id请求向网关层发送请求,网关层判断到来自数据管理层的请求时会根据request id找到对应的AioCompletion并执行回调函数:
void ChunkOp::execute() {
...
req_id = body_data["req-id"];
if (body_data.find("status_code") == body_data.end()) {
...
completion->set_retcode(retcode);
completion->do_completion();
context->complete_mgr->unregister_completion(req_id);
}
由于全部写入分块数据成功之后才能写入元数据,因此网关层必须等待写入的结果:
void PutFileOP::execute() {
...
if (file_size – offset <= DATA_FLUSH_SIZE && offset != 0) {
waiter = std::make_shared<AioCompleteWaiter>();
std::shared_ptr<PutChunkcompletion> completion = std::make_shared<PutChunkcompletion>(waiter);
GWGlobalContext* context = dynamic_cast<GWGlobalContext*>(ctx);
context->complete_mgr->register_completion(req_id, completion);
}
...
}
// wait for finish or fail
if (waiter.use_count()) {
waiter->wait_for_notify();
}
...
}
在AioCompletion的回调函数中notify:
void PutChunkcompletion::do_completion() {
set_waiter_retcode(retcode);
set_waiter_results(result_data);
waiter->notify();
}
PutFileOP::execute()就可以继续执行元数据的写入了,最终再通过_handler->set_response_code()设置返回的响应码,最终返回给用户整个文件上传的结果:
void PutFileOP::execute() {
...
if (waiter.use_count()) {
waiter->wait_for_notify();
}
// write metadata for file
ret = client->write_meta_data(header_data["filename"], file_size, crc32);
if (ret < 0) {
...
}
_handler->set_response_code(STATUS_OK);
}
以上就是写入一个文件的全部过程,由于数据管理层和元数据管理层都是复用的同一套Server代码,因此在这里不在赘述,读者可以通过阅读代码查看详细的写入数据和元数据的过程。另外元数据和数据的写入位置都在/home/storage/metadata和/home/storage/data中,通过文件名哈希并取写到这两个文件夹下的某个数字表示的文件夹下面,实际的分布式存储系统中这些数字文件夹可能代表着一块磁盘。
4.3 小结
本章根据一个实际的分布式存储系统的写入文件的案例,结合之前讲述的线程模型,实现了一个完整的多线程任务的执行逻辑。在PutFileOP::execute()中,其实有更高效的执行方法,那就是在AioCompletion的异步回调函数中加上写入元数据的逻辑,这样就不必在当前线程中等待数据管理层写入的结果,提高了线程的利用率,这也是Proactor线程模型的思想。







评论前必须登录!
注册