 网硕互联帮助中心
网硕互联帮助中心一、CLIP核心概念
CLIP(Contrastive Language-Image Pre-training)是 OpenAI 提出的对比学习模型,核心是跨模态对比预训练,目标是让模型同时理解图像和文本的语义关联,实现 “图文互搜”“零样本分类” 等能力。
- 核心思想:将图像和文本分别编码为向量,通过对比学习让 “匹配的图文对” 向量距离近,“不匹配的图文对” 向量距离远。
- 关键组件:
- 图像编码器:如 ViT(Vision Transformer),将图像转为固定维度的向量;
- 文本编码器:如 Transformer,将文本转为固定维度的向量;
- 对比损失函数:通过计算图文向量的相似度,最大化正样本对相似度、最小化负样本对相似度。
二、CLIP数学公式
(1)图文编码
设批量中有 N 个图文对,图像编码器为 I(⋅),文本编码器为 T(⋅):
- 图像向量:
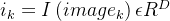 ,(D 为向量维度,如 512)
,(D 为向量维度,如 512) - 文本向量:
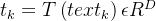
(2)向量归一化
为了让相似度仅由角度决定,需对向量做 L2 归一化:
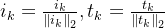
(3)相似度矩阵
计算所有图像与文本的余弦相似度,得到 N×N 的相似度矩阵 S:
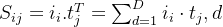
(4)对比损失(InfoNCE)
CLIP 的损失分为 “图像到文本” 和 “文本到图像” 两部分,总损失为两者平均。
- 第一部分:以图像为锚点,计算文本的交叉熵损失;
- 第二部分:以文本为锚点,计算图像的交叉熵损失。
三、CLIP实例代码解读
模块一:导入核心库
# 导入PyTorch核心库,用于构建神经网络
import torch
# 导入PyTorch的神经网络模块,用于定义层和模型
import torch.nn as nn
# 导入PyTorch的函数模块,包含激活函数、归一化等常用函数
import torch.nn.functional as F
# 从torchvision导入预训练图像模型(这里用ViT)
from torchvision import models
# 从transformers库导入BERT的tokenizer和模型,用于文本编码
from transformers import AutoTokenizer, AutoModel
模块二:超参数定义
# 批量大小(N=4),即每次训练4组图文对
BATCH_SIZE = 4
# 图文编码后的向量维度(D=512),统一图像和文本的输出维度
EMBED_DIM = 512
# 温度系数τ(CLIP默认0.07),用于缩放相似度,调节损失分布
TEMPERATURE = 0.07
# 设备选择:优先使用GPU(cuda),无GPU则用CPU
DEVICE = "cuda" if torch.cuda.is_available() else "cpu"
模块三:图像编码器
# 定义图像编码器类,继承自nn.Module(PyTorch所有模型的基类)
class ImageEncoder(nn.Module):
# 初始化函数,接收嵌入维度参数(默认512)
def __init__(self, embed_dim=EMBED_DIM):
# 调用父类nn.Module的初始化函数,必须执行
super().__init__()
# 加载预训练的ViT-B/32模型(Vision Transformer),pretrained=True表示加载预训练权重
self.vit = models.vit_b_32(pretrained=True)
# 定义投影层:将ViT输出的768维特征映射到指定的512维
# self.vit.hidden_dim是ViT的默认输出维度(768),embed_dim是目标维度(512)
self.projection = nn.Linear(self.vit.hidden_dim, embed_dim)
# 前向传播函数:输入图像,输出归一化的512维图像向量
def forward(self, images):
# 1. ViT特征提取:调用forward_features跳过分类头,仅提取特征
# 输入:(batch_size, 3, 224, 224),输出:(batch_size, 768)
x = self.vit.forward_features(images)
# 2. 投影到目标维度:将768维特征转为512维
# 输出:(batch_size, 512)
x = self.projection(x)
# 3. L2归一化:p=2表示L2范数,dim=-1表示对最后一维(512维)归一化
# 归一化后向量模长为1,确保相似度仅由角度决定
x = F.normalize(x, p=2, dim=-1)
# 返回归一化后的图像向量
return x
模块四:文本编码器
# 定义文本编码器类,继承自nn.Module
class TextEncoder(nn.Module):
# 初始化函数,接收嵌入维度参数(默认512)
def __init__(self, embed_dim=EMBED_DIM):
# 调用父类初始化函数
super().__init__()
# 加载预训练的bert-base-chinese模型(中文BERT),用于文本特征提取
self.bert = AutoModel.from_pretrained("bert-base-chinese")
# 加载对应的tokenizer,用于将文本转为模型可识别的token
self.tokenizer = AutoTokenizer.from_pretrained("bert-base-chinese")
# 定义投影层:将BERT输出的768维特征映射到512维
# self.bert.config.hidden_size是BERT的默认隐藏层维度(768)
self.projection = nn.Linear(self.bert.config.hidden_size, embed_dim)
# 前向传播函数:输入文本列表,输出归一化的512维文本向量
def forward(self, texts):
# 1. 文本token化处理
# texts:输入的文本列表(如["一只猫", "一个苹果"])
# return_tensors="pt":返回PyTorch张量
# padding=True:自动补全到同一长度
# truncation=True:超过max_length时截断
# max_length=32:文本最大长度为32
# .to(DEVICE):将张量移到指定设备(GPU/CPU)
inputs = self.tokenizer(
texts,
return_tensors="pt",
padding=True,
truncation=True,
max_length=32
).to(DEVICE)
# 2. BERT编码:输入token化后的张量,输出包含隐藏层的结果
outputs = self.bert(**inputs)
# 取最后一层隐藏状态的第0个token([CLS] token),代表整句语义
# outputs.last_hidden_state.shape:(batch_size, seq_len, 768)
# 取[:, 0, :]后shape:(batch_size, 768)
x = outputs.last_hidden_state[:, 0, :]
# 3. 投影到目标维度:将768维特征转为512维
# 输出:(batch_size, 512)
x = self.projection(x)
# 4. L2归一化:和图像向量一样,确保模长为1
x = F.normalize(x, p=2, dim=-1)
# 返回归一化后的文本向量
return x
模块五:CLIP对比损失函数
# 定义CLIP损失函数:输入图像向量、文本向量、温度系数,输出总损失
def clip_loss(image_embeds, text_embeds, temperature=TEMPERATURE):
# 1. 计算相似度矩阵S (N×N)
# image_embeds.shape:(batch_size, 512)
# text_embeds.t().shape:(512, batch_size)
# torch.matmul后shape:(batch_size, batch_size),即每个图像与每个文本的相似度
# / temperature:温度系数缩放,让相似度分布更合理
similarity = torch.matmul(image_embeds, text_embeds.t()) / temperature
# 2. 构建标签:正样本是对角线(i=j),即第i个图像对应第i个文本
# labels.shape:(batch_size,),值为[0,1,2,3](当batch_size=4时)
labels = torch.arange(BATCH_SIZE).to(DEVICE)
# 3. 图像到文本的损失(Image-to-Text)
# 以图像为锚点,计算每个图像匹配对应文本的交叉熵损失
# similarity是预测值(每个图像对所有文本的相似度),labels是真实标签
loss_i2t = F.cross_entropy(similarity, labels)
# 4. 文本到图像的损失(Text-to-Image)
# 以文本为锚点,需要将相似度矩阵转置(每个文本对所有图像的相似度)
loss_t2i = F.cross_entropy(similarity.t(), labels)
# 5. 总损失:图像到文本、文本到图像损失的平均值
total_loss = (loss_i2t + loss_t2i) / 2
# 返回总损失
return total_loss
模块六:实例运行
# 主函数入口:只有当脚本直接运行时才执行以下代码
if __name__ == "__main__":
# 初始化图像编码器,并移到指定设备(GPU/CPU)
image_encoder = ImageEncoder().to(DEVICE)
# 初始化文本编码器,并移到指定设备(GPU/CPU)
text_encoder = TextEncoder().to(DEVICE)
# 模拟输入:生成4张随机图像(符合ViT输入要求:3通道,224×224)
# fake_images.shape:(4, 3, 224, 224)
fake_images = torch.randn(BATCH_SIZE, 3, 224, 224).to(DEVICE)
# 模拟4条文本,与4张图像一一对应(正样本对)
fake_texts = ["一只黑色的猫", "红色的苹果", "蓝天白云", "小狗在跑"]
# 图像编码:输入随机图像,输出归一化的图像向量
# image_embeds.shape:(4, 512)
image_embeds = image_encoder(fake_images)
# 文本编码:输入文本列表,输出归一化的文本向量
# text_embeds.shape:(4, 512)
text_embeds = text_encoder(fake_texts)
# 计算CLIP损失:输入图文向量,输出损失值
loss = clip_loss(image_embeds, text_embeds)
# 输出图像向量形状,验证维度是否正确
print(f"图像向量形状: {image_embeds.shape}") # 预期输出:torch.Size([4, 512])
# 输出文本向量形状,验证维度是否正确
print(f"文本向量形状: {text_embeds.shape}") # 预期输出:torch.Size([4, 512])
# 输出损失值,item()将张量转为浮点数,保留4位小数
print(f"CLIP损失值: {loss.item():.4f}") # 初始随机状态下约3.5(因batch_size=4,ln(4)≈1.386,加上温度系数缩放)
四、总结
- 核心逻辑:CLIP 通过跨模态对比学习,让图文编码器学习 “匹配对向量相似、不匹配对向量疏远”,核心是归一化 + 余弦相似度 + InfoNCE 损失;
- 关键公式:损失函数由图像到文本、文本到图像两部分交叉熵组成,温度系数 τ 用于调节相似度分布;
- 代码核心:图文编码器输出归一化向量,通过矩阵点积计算相似度,最终用交叉熵实现对比损失。








评论前必须登录!
注册