 网硕互联帮助中心
网硕互联帮助中心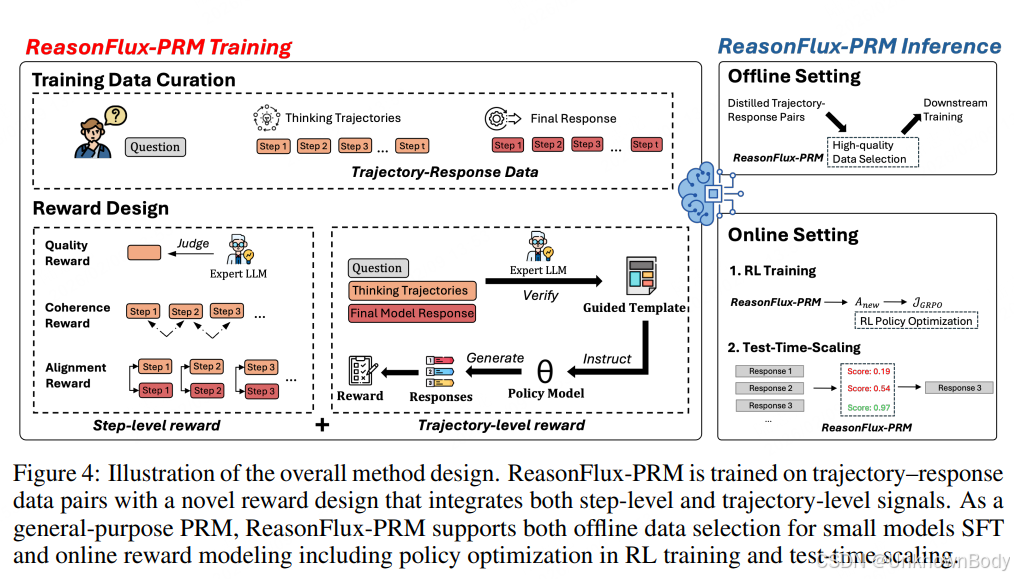
文章核心总结与创新点
主要内容
本文针对现有过程奖励模型(PRMs)难以评估大语言模型中间推理轨迹的问题,提出了轨迹感知的PRM——ReasonFlux-PRM。该模型通过步级和轨迹级双重监督,适配“轨迹-响应”格式的长链推理数据,可应用于离线高质量数据筛选、在线强化学习策略优化和测试时Best-of-N缩放三大场景。在AIME、MATH500等多个挑战性基准测试中,ReasonFlux-PRM(7B版本)表现优于Qwen2.5-Math-PRM-72B等强基线模型和人工精选数据,在监督微调、强化学习和测试时缩放场景分别实现12.1%、4.5%和6.3%的平均性能提升,同时还发布了适用于资源受限场景的1.5B轻量化版本。









评论前必须登录!
注册