 网硕互联帮助中心
网硕互联帮助中心📖 前言:为什么需要正则表达式?
在日常开发中,你是否遇到过这样的烦恼?
查找所有以"139"开头的手机号
验证邮箱格式是否正确
提取文本中的日期信息
匹配特定格式的身份证号
传统的 LIKE 操作符在这些复杂场景下力不从心,而正则表达式就是解决这些问题的瑞士军刀!
🎯 第一章:正则表达式基础入门
1.1 什么是正则表达式?
正则表达式(Regular Expression)是一种用于描述字符串模式的强大工具。想象一下:
LIKE ‘%abc%’ 只能找包含"abc"的字符串
正则表达式可以找:"以a开头,中间是任意数字,以c结尾"的字符串
1.2 MySQL中的正则表达式函数
MySQL提供了两个主要的正则表达式函数:

🔧 第二章:REGEXP基础匹配
2.1 最简单的匹配:查找包含特定文本的记录
sql
— 传统LIKE写法
SELECT * FROM users
WHERE username LIKE '%admin%';
— 使用正则表达式(更直观)
SELECT * FROM users
WHERE username REGEXP 'admin';
— 两者的区别:
— LIKE '%admin%' 可以匹配:superadmin、admin123、myadmin
— REGEXP 'admin' 可以匹配:admin、administrator、badmin(同样匹配!)
2.2 匹配开头和结尾
sql
— 查找以"张"开头的姓名
SELECT * FROM employees
WHERE name REGEXP '^张';
— 查找以"com"结尾的邮箱
SELECT * FROM users
WHERE email REGEXP 'com$';
— 查找以"139"开头的手机号
SELECT * FROM customers
WHERE phone REGEXP '^139';
— 精确匹配"hello"(开头到结尾都是hello)
SELECT * FROM messages
WHERE content REGEXP '^hello$';
📊 对比表:
2.3 匹配多个字符之一
sql
— 查找姓"张"或"王"的员工
SELECT * FROM employees
WHERE name REGEXP '^[张王]';
— 查找包含数字0-5的电话
SELECT * FROM contacts
WHERE phone REGEXP '[0-5]';
— 查找元音字母开头的单词
SELECT * FROM articles
WHERE title REGEXP '^[aeiouAEIOU]';
— 排除性匹配:查找不是数字的字符
SELECT * FROM logs
WHERE message REGEXP '[^0-9]'; — ^在[]内表示"非"
🔍 字符集说明:
[abc]:匹配a、b或c中的任意一个
[a-z]:匹配任意小写字母
[A-Z]:匹配任意大写字母
[0-9]:匹配任意数字
[^abc]:匹配除了a、b、c之外的字符
⚙️ 第三章:高级匹配技巧
3.1 重复匹配:控制字符出现次数
sql
— 精确匹配:包含3个连续数字
SELECT * FROM products
WHERE product_code REGEXP '[0-9]{3}';
— 范围匹配:2到4个数字
SELECT * FROM orders
WHERE order_no REGEXP '[0-9]{2,4}';
— 至少匹配:3个或更多字母
SELECT * FROM books
WHERE isbn REGEXP '[A-Z]{3,}';
— 可选匹配:0个或1个字母
SELECT * FROM files
WHERE filename REGEXP 'backup_[0-9]?\\.sql';
— 一个或多个:匹配连续的数字
SELECT * FROM logs
WHERE log_id REGEXP '[0-9]+';
— 零个或多个:匹配可能的前缀
SELECT * FROM configs
WHERE key_name REGEXP 'debug_.*';
🎯 重复匹配符速查表: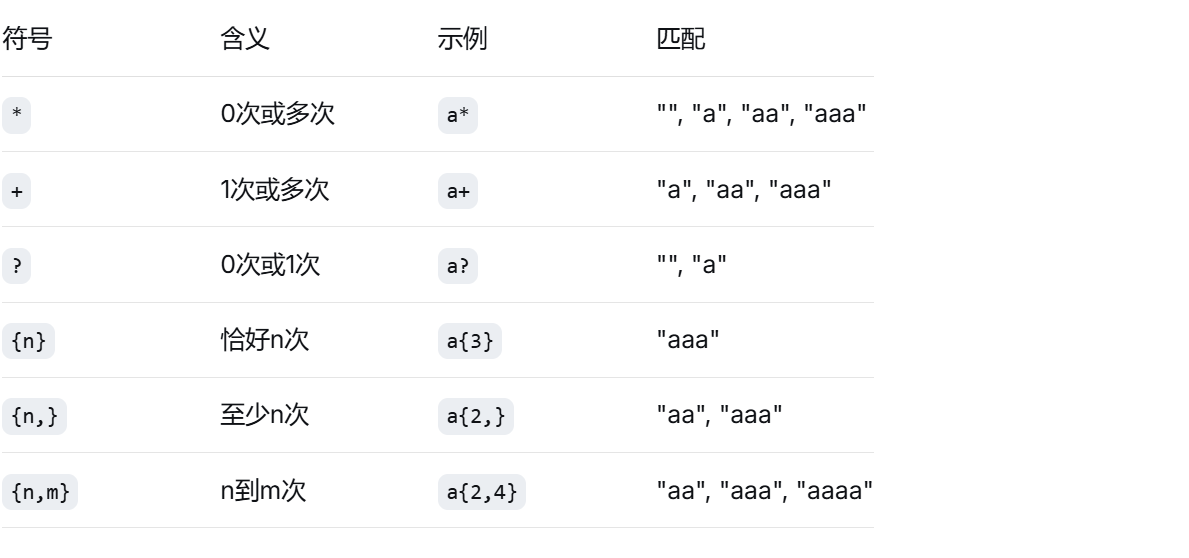
3.2 分组和选择
sql
— 匹配"区号-电话号码"格式
SELECT * FROM contacts
WHERE phone REGEXP '^([0-9]{3,4})-([0-9]{7,8})$';
— 查找多种日期格式
SELECT * FROM documents
WHERE date_string REGEXP '(202[0-9]-[0-9]{2}-[0-9]{2})|([0-9]{2}/[0-9]{2}/202[0-9])';
— 分组提取(MySQL 8.0+)
SELECT
phone,
REGEXP_SUBSTR(phone, '^([0-9]{3,4})-([0-9]{7,8})$', 1, 1, '', 1) as area_code,
REGEXP_SUBSTR(phone, '^([0-9]{3,4})-([0-9]{7,8})$', 1, 1, '', 2) as phone_number
FROM contacts
WHERE phone REGEXP '^[0-9]{3,4}-[0-9]{7,8}$';
3.3 特殊字符和转义
sql
— 匹配点号(需要转义)
SELECT * FROM files
WHERE filename REGEXP '\\.txt$';
— 匹配包含方括号的内容
SELECT * FROM logs
WHERE message REGEXP '\\\\[error\\\\]';
– 常用特殊字符转义
/*
. 匹配点号
* 匹配星号
+ 匹配加号
? 匹配问号
\\ 匹配反斜杠
$ 匹配美元符号
^ 匹配脱字符
[ 匹配左方括号
] 匹配右方括号
( 匹配左括号
) 匹配右括号
*/
💼 第四章:实战应用场景
4.1 数据验证:确保数据质量
sql
— 验证邮箱格式
SELECT email,
CASE
WHEN email REGEXP '^[A-Za-z0-9._%+-]+@[A-Za-z0-9.-]+\\.[A-Za-z]{2,}$'
THEN '有效邮箱'
ELSE '无效邮箱'
END as validation_result
FROM users;
— 验证手机号(中国大陆)
SELECT phone,
CASE
WHEN phone REGEXP '^1[3-9][0-9]{9}$' THEN '有效手机号'
WHEN phone REGEXP '^[0-9]{3,4}-[0-9]{7,8}$' THEN '有效座机'
ELSE '无效号码'
END as phone_type
FROM customers;
— 验证身份证号(简单版)
SELECT id_card,
CASE
WHEN id_card REGEXP '^[1-9][0-9]{5}(18|19|20)[0-9]{2}(0[1-9]|1[0-2])(0[1-9]|[1-2][0-9]|3[0-1])[0-9]{3}[0-9Xx]$'
THEN '格式正确'
ELSE '格式错误'
END as id_validation
FROM person_info;
4.2 数据清洗:处理杂乱数据
sql
— 提取纯数字内容
SELECT
content,
REGEXP_REPLACE(content, '[^0-9]', '') as numbers_only
FROM mixed_data;
— 清理多余空格
SELECT
address,
REGEXP_REPLACE(address, '\\\\s+', ' ') as cleaned_address
FROM customer_address;
— 标准化日期格式
SELECT
original_date,
CASE
WHEN original_date REGEXP '^[0-9]{4}-[0-9]{2}-[0-9]{2}$' THEN original_date
WHEN original_date REGEXP '^[0-9]{2}/[0-9]{2}/[0-9]{4}$'
THEN CONCAT(
SUBSTRING_INDEX(SUBSTRING_INDEX(original_date, '/', -1), '/', 1),
'-',
LPAD(SUBSTRING_INDEX(original_date, '/', 1), 2, '0'),
'-',
LPAD(SUBSTRING_INDEX(SUBSTRING_INDEX(original_date, '/', 2), '/', -1), 2, '0')
)
ELSE NULL
END as standard_date
FROM dates_table;
4.3 日志分析:提取关键信息
sql
— 从日志中提取IP地址
SELECT
log_entry,
REGEXP_SUBSTR(log_entry, '[0-9]{1,3}\\\\.[0-9]{1,3}\\\\.[0-9]{1,3}\\\\.[0-9]{1,3}') as ip_address
FROM server_logs
WHERE log_entry REGEXP '[0-9]{1,3}\\\\.[0-9]{1,3}\\\\.[0-9]{1,3}\\\\.[0-9]{1,3}';
— 提取错误级别
SELECT
log_entry,
CASE
WHEN log_entry REGEXP '\\\\[(ERROR|FATAL)\\\\]' THEN '严重错误'
WHEN log_entry REGEXP '\\\\[WARNING\\\\]' THEN '警告'
WHEN log_entry REGEXP '\\\\[INFO\\\\]' THEN '信息'
ELSE '未知级别'
END as log_level
FROM application_logs;
— 提取时间戳和消息
SELECT
log_entry,
REGEXP_SUBSTR(log_entry, '\\\\[[0-9]{4}-[0-9]{2}-[0-9]{2} [0-9]{2}:[0-9]{2}:[0-9]{2}\\\\]') as timestamp,
REGEXP_REPLACE(log_entry, '^.*\\\\] ', '') as message
FROM system_logs;
🚀 第五章:性能优化与最佳实践
5.1 创建正则表达式索引(虚拟列)
sql
— 创建虚拟列存储提取的信息
ALTER TABLE users
ADD COLUMN email_domain VARCHAR(100)
GENERATED ALWAYS AS (
REGEXP_SUBSTR(email, '@([A-Za-z0-9.-]+)$', 1, 1, '', 1)
) STORED;
— 在虚拟列上创建索引
CREATE INDEX idx_email_domain ON users(email_domain);
— 现在可以快速查询特定域名的用户
SELECT * FROM users WHERE email_domain = 'gmail.com';
5.2 避免性能陷阱
sql
— ❌ 避免过度复杂的正则表达式
SELECT * FROM large_table
WHERE content REGEXP '^([a-z]+)\\\\1{10,}'; — 可能很慢!
— ✅ 尽量使用更简单的模式
SELECT * FROM large_table
WHERE content REGEXP 'aaaaaaaaaaa'; — 更高效
— ❌ 避免在开头使用通配符
SELECT * FROM users
WHERE username REGEXP '.*admin'; — 扫描全表
— ✅ 尽量锚定开头
SELECT * FROM users
WHERE username REGEXP '^admin.*'; — 可以使用索引
5.3 实用技巧和小贴士
sql
— 1. 测试正则表达式(先SELECT后WHERE)
SELECT 'test@example.com' REGEXP '^[A–Za–z0–9._%+–]+@[A–Za–z0–9.–]+\\.[A–Za–z]{2,}$' as is_valid;
— 2. 使用变量存储复杂正则表达式
SET @phone_regex = '^1[3-9][0-9]{9}$';
SELECT * FROM customers WHERE phone REGEXP @phone_regex;
— 3. 组合使用LIKE和REGEXP
SELECT * FROM products
WHERE
— 先用LIKE过滤大部分数据(快)
description LIKE '%折扣%'
AND
— 再用REGEXP精确匹配(准)
description REGEXP '限时折扣[0-9]{1,2}%';
— 4. 正则表达式调试函数
SELECT
REGEXP_INSTR('hello123world', '[0-9]+') as match_position, — 返回6
REGEXP_SUBSTR('hello123world', '[0-9]+') as match_string, — 返回"123"
REGEXP_REPLACE('hello123world', '[0-9]+', '###') as replaced_string; — "hello###world"
📊 第六章:REGEXP vs LIKE 全面对比
6.1 功能对比表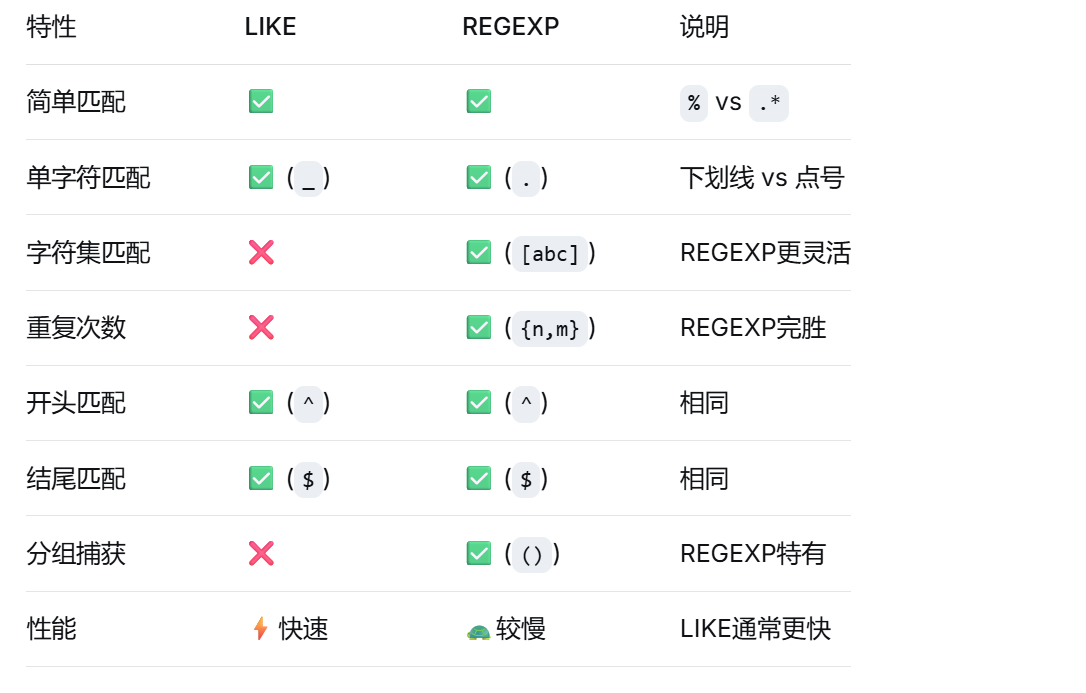
6.2 使用场景建议
sql
— 场景1:简单前缀匹配(推荐LIKE)
— LIKE版本(更快)
SELECT * FROM products WHERE name LIKE 'Apple%';
— REGEXP版本
SELECT * FROM products WHERE name REGEXP '^Apple';
— 场景2:复杂模式匹配(必须用REGEXP)
— 查找包含3个连续数字的产品编码
SELECT * FROM products WHERE code REGEXP '[0-9]{3}';
— LIKE无法实现!
— 场景3:混合使用(最佳实践)
— 先用LIKE快速过滤,再用REGEXP精确匹配
SELECT * FROM logs
WHERE
message LIKE '%error%' — 快速过滤
AND message REGEXP 'error:[0-9]{4}'; — 精确匹配
🎉 总结与进阶建议
核心要点回顾
✅ REGEXP比LIKE更强大,适合复杂模式匹配
✅ 先测试后使用,复杂正则先在工具中测试
✅ 注意性能影响,大数据表慎用正则
✅ 合理使用索引,虚拟列是性能优化的利器
✅ 保持正则简洁,越复杂的正则性能越差
最后的小提示 💡
从简单开始:不要一开始就写复杂的正则表达式
善用工具:在线测试工具能大大提高效率
写好注释:复杂的正则一定要写注释说明
性能监控:在生产环境监控正则查询的性能
记住:正则表达式是一门语言,需要不断练习才能掌握。开始可能会觉得符号很多很难记,但只要多练习,你会发现它是处理文本数据的强大武器!
祝你在正则表达式的世界里探索愉快,成为数据处理的专家! 🚀





评论前必须登录!
注册