 网硕互联帮助中心
网硕互联帮助中心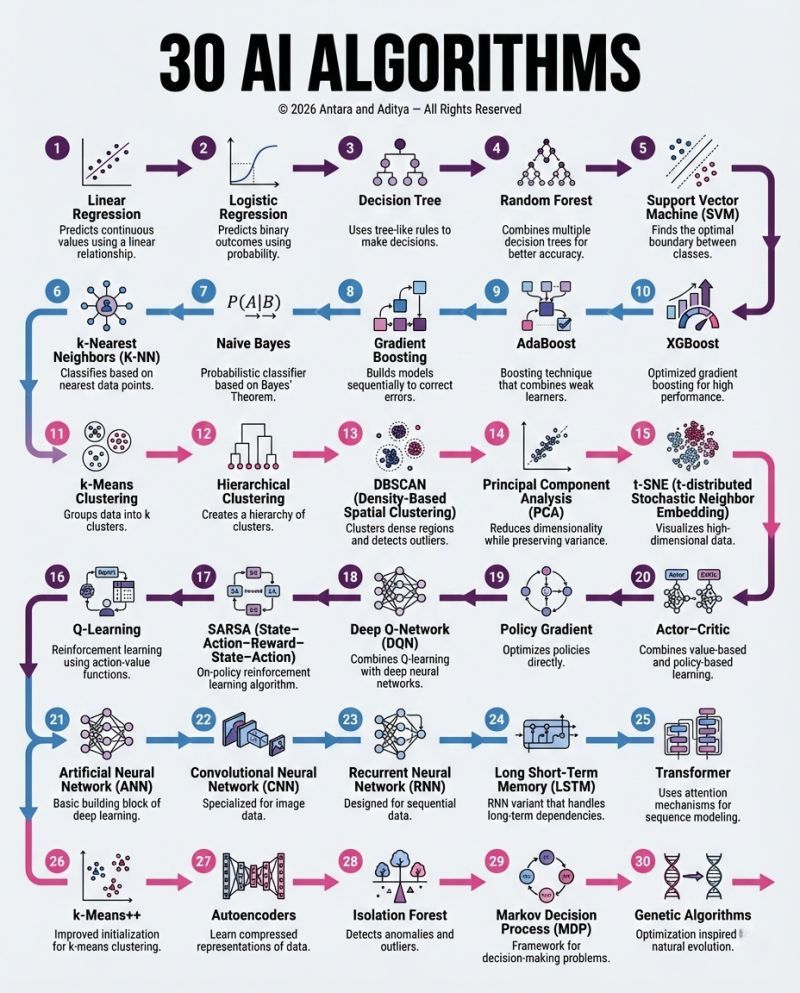
从预测房价的线性回归,到驱动大语言模型的 Transformer,AI 算法的版图广阔且层层递进 —— 很多数据科学家容易陷入 “会用某几个算法,却看不清整体体系” 的困境。这张 “30 个 AI 算法图谱”,正是将零散的算法知识梳理成从基础到复杂、从单一任务到通用智能的完整路径,覆盖监督学习、无监督学习、强化学习、深度学习四大核心领域,是数据科学家构建知识框架的导航图。
一、监督学习:从 “线性关系” 到 “集成增强”—— 预测与分类的核心武器
监督学习是 AI 算法的基础,核心是 “用带标签的数据训练模型,实现预测或分类”,图谱中前 10 个算法覆盖了监督学习从简单到复杂的进化路径。
1. 基础回归与分类:搭建预测的 “入门工具”
- 线性回归:监督学习的 “起点算法”,通过拟合输入与输出的线性关系(如 “房屋面积→房价”),实现连续值预测。它的核心是最小化误差平方和,原理简单但能解决多数基础预测问题(如销量预测、库存预估)。
- 逻辑回归:并非 “回归” 而是分类算法,通过 Sigmoid 函数将输出映射到 0-1 概率区间,实现二分类(如 “邮件是否为垃圾邮件”“用户是否会流失”),是金融风控、医疗诊断的基础工具。
- 决策树:用 “树状规则” 拆分数据(如 “年龄 > 30?→ 收入 > 5k?”),直观易懂且能处理非线性关系,但单棵树易过拟合。
- k 近邻(K-NN):基于 “相似样本有相似标签” 的直觉,通过计算待预测样本与训练集的距离,取最近的 k 个样本的标签作为结果,适合简单分类(如手写数字识别)。
- 朴素贝叶斯:基于贝叶斯定理的概率分类器,假设特征之间相互独立,计算样本属于某类别的概率,在文本分类(如新闻分类、垃圾邮件检测)中效率极高。
2. 集成学习:用 “团队协作” 提升性能
单一算法的能力有限,集成学习通过组合多个弱模型,实现 “1+1>2” 的效果,是工业界常用的高性能算法:
- 随机森林:将多棵决策树的结果投票 / 平均,既保留了决策树处理非线性的能力,又通过 “随机选特征、随机抽样” 降低了过拟合风险,是数据科学竞赛的 “入门利器”,常用于客户分群、信用评分。
- 梯度提升(Gradient Boosting):按 “迭代纠错” 的逻辑,每棵新树都拟合上一轮模型的误差,逐步提升预测精度;AdaBoost 是其早期形式,通过调整样本权重强化难分样本的学习。
- XGBoost:优化版梯度提升算法,加入正则化、并行计算、缺失值处理等特性,是近年数据科学竞赛的 “常胜将军”,在点击率预测、风控建模中性能远超传统算法。
二、无监督学习:从 “聚类” 到 “降维”—— 挖掘数据的隐藏规律
无监督学习无需标签数据,核心是 “从数据中自动发现模式”,图谱中 11-15、26-28 覆盖了其两大核心任务:聚类与降维。
1. 聚类:给数据 “分组”
- K-Means:将数据划分为 k 个簇,通过 “随机选中心→分配样本→更新中心” 的迭代,让簇内样本尽可能相似、簇间尽可能不同,适合客户分群、用户画像(如电商将用户按消费习惯分为 “高价值”“潜力”“流失风险” 组)。
- K-Means++:K-Means 的优化版,通过更合理的初始中心选择(选离已选中心最远的点),避免 K-Means 陷入局部最优的问题。
- 层次聚类:不预设簇数,通过 “合并相似簇”(凝聚式)或 “拆分大簇”(分裂式)形成树状结构,适合探索性数据分析(如生物物种分类)。
- DBSCAN:基于密度的聚类算法,无需预设簇数,能自动识别任意形状的簇(如环形、不规则簇),同时标记异常点,适合异常检测(如信用卡欺诈交易识别)。
- 孤立森林:专门用于异常检测的算法,通过随机划分数据,异常点会更快被孤立,适合处理高维数据的异常(如服务器日志中的异常请求)。
2. 降维:简化数据的 “维度灾难”
高维数据(如特征数达数百的用户行为数据)会导致计算量大、模型过拟合,降维算法通过保留核心信息,将数据压缩到低维空间:
- PCA(主成分分析):找到数据方差最大的方向(主成分),将数据投影到这些方向上,实现降维同时保留大部分信息,常用于图像压缩、特征预处理。
- t-SNE:非线性降维算法,专注于 “保持局部样本的相似性”,能将高维数据(如文本嵌入、图像特征)可视化成 2D/3D 图,是数据分析中探索数据分布的常用工具。
三、强化学习:从 “试错奖励” 到 “自主决策”—— 让智能体学会行动
强化学习的核心是 “智能体在环境中通过试错获得奖励,优化行为策略”,图谱中 16-20、29 覆盖了其从基础到进阶的算法。
1. 基础值函数方法
- Q-Learning:通过学习 “状态 – 动作价值函数(Q 函数)”,判断在某状态下采取某动作能获得的未来奖励,是强化学习的入门算法,常用于简单游戏(如迷宫寻路、贪吃蛇)。
- SARSA:与 Q-Learning 类似,但 Q-Learning 是 “离线学习”(学习最优动作的价值),SARSA 是 “在线学习”(学习实际执行动作的价值),更适合有探索约束的场景。
- 深度 Q 网络(DQN):将 Q 函数用神经网络(CNN/RNN)表示,解决了传统 Q-Learning 无法处理高维状态(如游戏画面)的问题,AlphaGo 的早期版本就基于 DQN 思路。
2. 策略梯度与决策框架
- 策略梯度:直接优化动作策略(如 “在某状态下选择某动作的概率”),而非学习价值函数,适合连续动作空间(如机器人控制)。
- Actor-Critic:结合 “值函数(Critic)评估动作价值” 与 “策略(Actor)选择动作”,兼顾策略梯度的灵活性和值函数的稳定性,是当前强化学习的主流框架之一。
- 马尔可夫决策过程(MDP):强化学习的理论框架,用 “状态、动作、转移概率、奖励” 描述智能体与环境的交互,是所有强化学习算法的理论基础。
四、深度学习:从 “神经元” 到 “注意力”—— 解锁复杂任务的通用智能
深度学习是基于神经网络的算法体系,通过多层非线性变换提取复杂特征,是当前 AI(大模型、计算机视觉)的核心技术,图谱中 21-25、30 覆盖了其核心模型。
1. 基础神经网络与专用模型
- 人工神经网络(ANN):深度学习的基础单元,由输入层、隐藏层、输出层的神经元组成,通过反向传播优化权重,能拟合复杂非线性关系,但早期受限于数据和算力,应用范围窄。
- 卷积神经网络(CNN):专为处理网格数据(如图像、语音)设计,通过卷积层提取局部特征(如图像的边缘、纹理)、池化层压缩数据,是计算机视觉的核心(如人脸识别、物体检测、医疗影像分析)。
- 循环神经网络(RNN):处理序列数据(如文本、时间序列)的模型,通过 “循环连接” 保留前序信息,但存在 “长期依赖” 问题(无法记住长序列的早期信息)。
- 长短期记忆网络(LSTM):RNN 的改进版,通过 “门控单元”(输入门、遗忘门、输出门)解决长期依赖问题,是早期自然语言处理(如机器翻译、文本生成)的主流模型。
- 自编码器:无监督深度学习模型,通过 “编码(压缩数据)→解码(重建数据)” 学习数据的紧凑表示,常用于数据压缩、异常检测、预训练特征提取。
2. 通用智能的突破:Transformer
- Transformer:2017 年提出的模型,核心是 “注意力机制”—— 让模型在处理序列时,动态关注不同位置的信息(如翻译 “苹果” 时,关注前文的 “吃” 或 “手机” 来判断词义)。它摆脱了 RNN 的序列依赖,支持并行计算,是当前大语言模型(GPT、Llama)、多模态模型(Gemini)的基础,彻底改变了自然语言处理、计算机视觉的技术格局。
3. 进化启发的优化:遗传算法
- 遗传算法:模拟自然进化的优化算法,通过 “选择(保留优解)、交叉(组合解)、变异(随机修改)” 迭代寻找最优解,适合传统算法难以解决的复杂优化问题(如路径规划、参数调优)。
五、从基础到进阶:30 个算法的成长路径
这 30 个算法并非孤立存在,而是构成了数据科学家的 “能力进阶路线”:
- 入门阶段:掌握线性回归、逻辑回归、K-Means 等基础算法,能解决简单的预测、分类、聚类任务;
- 进阶阶段:学习随机森林、XGBoost 等集成学习算法,提升模型性能;掌握 CNN、LSTM 等专用深度学习模型,处理图像、序列数据;
- 高阶阶段:深入 Transformer、强化学习算法,构建通用智能模型(如大语言模型、智能体),解锁复杂业务场景。
结语:算法是工具,体系是核心
对数据科学家而言,掌握 30 个算法不是 “背诵公式”,而是理解 “每个算法的适用场景、优缺点、进化逻辑”—— 比如当需要快速做客户分群时,K-Means 是首选;当追求预测精度时,XGBoost 更合适;当处理图像时,CNN 是标配;当构建对话机器人时,Transformer 是基础。
这张图谱的价值,在于将零散的算法知识整合成 “可导航的体系”,帮助数据科学家从 “会用单个工具” 升级为 “能根据业务场景选择最优算法组合”—— 毕竟,AI 的核心不是算法本身,而是用算法解决实际问题的能力。









评论前必须登录!
注册