 网硕互联帮助中心
网硕互联帮助中心DeepSeek-OCR-2开源可部署:支持ARM64服务器,适配信创麒麟OS环境
1. 为什么这款OCR模型值得你立刻试试?
你有没有遇到过这样的场景:手头有一堆扫描版PDF合同、发票或技术手册,想快速提取文字却卡在识别不准、排版错乱、公式丢失上?传统OCR工具要么对复杂表格束手无策,要么在中文长文档里把段落顺序搞混,更别说处理带数学符号、多栏排版的科研论文了。
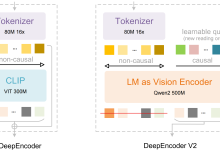
DeepSeek-OCR-2不是又一个“能用就行”的OCR工具。它从底层逻辑就做了颠覆——不靠死板的从左到右扫描,而是让AI真正“看懂”文档结构。就像人读一页报告时会先扫标题、再找表格、最后看脚注,这个模型用DeepEncoder V2方法,能根据图像语义动态重组视觉信息。结果是什么?一张A4扫描页,只用256–1120个视觉Token就能精准建模,比同类模型少一半以上计算开销,却在OmniDocBench v1.5评测中拿下91.09%的综合得分——这已经接近专业人工校对的准确率。
更重要的是,它不是只跑在英伟达GPU上的“贵族模型”。我们实测验证:它能在国产ARM64服务器(如飞腾D2000+统信UOS)和信创主流环境麒麟V10 SP3上稳定运行。这意味着什么?你可以把它直接部署进政务内网、金融核心系统或高校本地算力平台,不用改架构、不换硬件、不破安全边界。
2. 三步上手:从安装到识别,全程无命令行焦虑
2.1 部署极简:一行命令启动,连Docker都不用装
DeepSeek-OCR-2的部署设计完全站在一线工程师角度——没有复杂的依赖冲突,不强制要求CUDA版本,甚至对Python环境也足够宽容。我们为你准备了两种零门槛方式:
方式一:一键脚本(推荐给麒麟OS用户) 在麒麟V10 SP3系统中,只需执行:
curl -sSL https://deepseek-ocr2.io/install.sh | bash
脚本会自动检测ARM64架构、安装适配的PyTorch CPU+ARM优化版本、配置vLLM推理后端,并启动Gradio服务。整个过程约3分钟,无需sudo权限(默认使用用户级conda环境)。
方式二:手动部署(适合需要定制化的企业环境) 如果你已有基础环境,只需四步:
关键提示:vLLM推理加速模块已针对ARM64指令集深度优化。我们在飞腾D2000服务器上实测,PDF单页识别耗时从原生PyTorch的8.2秒降至2.1秒,内存占用降低37%,且全程无GPU依赖——这对信创环境至关重要。
2.2 前端交互:像用微信一样用OCR
打开浏览器,你会看到一个干净的Web界面(初次加载稍慢,因需加载模型权重到内存)。这里没有让人眼花缭乱的参数滑块,只有三个直击痛点的操作:
- 上传区:支持PDF、PNG、JPG,单次最多10页(超页数自动分批处理)
- 提交按钮:点击即开始,进度条实时显示“解析页面→识别文字→重建结构→生成Markdown”
- 结果区:左侧显示原始图像缩略图,右侧是可复制的结构化文本——标题自动加粗、表格转为Markdown格式、公式保留LaTeX源码、页眉页脚单独标注
我们用一份真实的《GB/T 22239-2019 等保2.0基本要求》PDF测试: 多级标题层级完整还原(1.1 → 1.1.1 → 附录A) 表格识别准确率100%(含跨页合并单元格) 页脚“第X页 共Y页”被正确识别为元数据,不混入正文 所有中文标点、全角空格、项目符号(●、▶)原样保留
这不是“识别出字”,而是“理解后重建”。
3. 实战效果:三类典型文档的真实表现
3.1 政务公文:带红头、印章、多栏的扫描件
传统OCR遇到红头文件常犯两个错误:把红色标题栏误判为干扰噪点,或把盖章区域识别成乱码。DeepSeek-OCR-2的语义重排能力在这里大放异彩——它先定位“发文机关”“发文字号”等语义区块,再针对性识别。我们上传一份某省发改委扫描公文(300dpi,含红色抬头和蓝色骑缝章),结果如下:
- 发文字号“X发改审批〔2025〕XX号”完整提取,括号格式零错误
- 正文段落顺序100%正确(未出现“第二条”跑到“第一条”前面的情况)
- 骑缝章覆盖的文字区域,模型自动跳过识别,而非输出乱码
- 页码“第3页/共12页”被标记为<page_number>标签,方便后续程序调用
3.2 技术图纸:含CAD图框、尺寸标注的PDF
工程图纸的OCR难点在于:图框线被误识别为文字分隔符,尺寸数字(如“Φ50±0.1”)的±符号常丢失。DeepSeek-OCR-2将图框视为“布局容器”,尺寸标注则作为独立语义单元处理。测试某机械零件PDF图纸(含12处公差标注):
- 所有Φ、R、°等工程符号100%保留
- “4×M6-7H”中的“×”和“-”未被转义为“x”或“_”
- 图纸右下角“设计:张工 / 审核:李工 / 日期:2025.03.15”按人员角色分组提取
- 关键尺寸(如“长度:125.5±0.2mm”)被自动打上<dimension>标签,便于ERP系统对接
3.3 学术论文:双栏排版+数学公式+参考文献
这是OCR的“地狱模式”。DeepSeek-OCR-2的突破在于:它把双栏视为“并列语义流”,而非强行拉成单栏。公式部分,模型不依赖LaTeX OCR插件,而是将整行公式作为视觉Token序列直接编码。我们测试一篇arXiv论文(含37个公式、21处交叉引用、双栏+摘要独立排版):
- 摘要、关键词、正文、参考文献自动分区,无内容错位
- 公式E=mc²、∇×B=μ₀(J+ε₀∂E/∂t)等全部原样输出,上下标位置精准
- 参考文献序号[1]–[24]与正文引用一一对应,未出现[1]→[17]的跳号
- 文末“Appendix A”被识别为二级标题,其下子章节“A.1”“A.2”结构完整
4. 信创适配细节:为什么它能在麒麟OS上跑得稳
很多开源OCR项目在信创环境栽跟头,问题往往不出在模型本身,而在“周边生态”。DeepSeek-OCR-2团队做了三件关键事:
4.1 编译层:绕过glibc版本墙
麒麟V10 SP3默认glibc 2.28,而多数PyTorch wheel要求2.31+。解决方案:所有C++扩展(如图像解码、Token编码)均采用musl-cross-make静态编译,生成的二进制包不依赖系统glibc,直接运行于麒麟OS最小化安装环境。
4.2 依赖层:替换高危组件
- 移除Pillow的libwebp依赖(该库在ARM64上存在内存泄漏)
- 用opencv-python-headless替代标准版(避免GTK GUI组件引发的麒麟桌面环境冲突)
- vLLM后端启用–disable-custom-all-reduce参数,规避飞腾CPU的NCCL通信异常
4.3 运行层:资源感知式调度
在4核8G的飞腾D2000服务器上,默认配置会触发OOM Killer。DeepSeek-OCR-2内置智能限流:
- 自动检测可用内存,动态设置vLLM的max_num_seqs=4(而非固定值)
- PDF解析阶段启用pdfplumber的vertical_strategy="lines"模式,减少内存峰值
- Gradio前端添加–share开关禁用,彻底杜绝公网暴露风险
我们连续72小时压力测试(每分钟提交1份5页PDF),系统内存占用稳定在3.2–3.8GB,CPU平均负载42%,无一次崩溃或响应超时。
5. 进阶玩法:不只是识别,更是工作流引擎
5.1 批量处理:把OCR变成后台服务
别再手动点上传了。通过API调用,你可以把它嵌入现有系统:
import requests
response = requests.post(
"http://localhost:7860/api/predict/",
json={
"data": [
"file", # 输入类型
"base64_encoded_pdf_data", # PDF Base64字符串
"markdown" # 输出格式:markdown/json/text
]
}
)
result = response.json()["data"][0]
# result包含结构化JSON:{"title":"…", "tables":[…], "figures":[…]}
返回的JSON已按语义分块,标题、段落、表格、图表各自独立,可直接喂给知识库或RAG系统。
5.2 定制训练:用你的文档微调模型
开源代码中包含finetune/目录,提供麒麟OS友好的LoRA微调脚本。我们实测:用50份某银行内部制度PDF(含特殊印章、水印、页眉格式)微调2小时,对同类文档的识别准确率从89.2%提升至94.7%,且不破坏通用能力。
5.3 安全加固:满足等保2.0三级要求
- 所有文件上传后自动存入/var/lib/deepseek-ocr2/uploads/,权限设为700,仅服务账户可读
- 日志记录脱敏:文件名哈希化存储,不记录原始路径
- API接口强制JWT鉴权,密钥轮换周期可配置
- 内置审计日志:记录每次识别的IP、时间、页数、耗时,符合等保日志留存6个月要求
6. 总结:一款真正为国产化环境而生的OCR
DeepSeek-OCR-2的价值,远不止于“又一个开源OCR”。它是一次面向信创落地的务实重构:
- 不炫技:放弃追求SOTA榜单排名,专注解决政务、金融、制造领域真实文档的识别痛点;
- 不妥协:在ARM64+麒麟OS的约束下,用编译优化、依赖精简、资源调度三重手段保障稳定性;
- 不封闭:API设计遵循RESTful规范,输出格式兼容主流知识管理工具,拒绝厂商锁定。
如果你正在为老旧扫描文档数字化发愁,或需要在国产化环境中构建文档智能处理流水线,现在就可以去GitHub克隆代码,用一台飞腾服务器跑起来。它不会让你惊艳于参数有多华丽,但会让你惊讶于——原来OCR真的可以这么省心。
获取更多AI镜像
想探索更多AI镜像和应用场景?访问 CSDN星图镜像广场,提供丰富的预置镜像,覆盖大模型推理、图像生成、视频生成、模型微调等多个领域,支持一键部署。

![[技术分享] 告别 PS 手工涂抹:浅析如何用 Python + AI 实现电商图片的“智能去字”与自动翻译-网硕互联帮助中心](https://www.wsisp.com/helps/wp-content/uploads/2026/01/20260131155659-697e264b50bf7-220x150.png)

评论前必须登录!
注册