 网硕互联帮助中心
网硕互联帮助中心《智能的理论》全书转至目录
不同AGI的研究路线对比简化版:《AGI(具身智能)路线对比》,欢迎各位参与讨论、批评或建议。
视觉叙事是指从图像中获取事件信息。这是一个困难而复杂的问题,它需要涉及协调感知和理解过程。这个过程会在多个图像或视频上进行处理,并产生情景模型(Loschky,Hutson,Smith,Smith和Magliano,2018)。
一.一个例子
1.故事
这里,可以通过一个漫画例子说明人们在视觉叙事中需要有那些操作和有困难。图1展示了Meyer(1967)的一个图片叙事故事《一个男孩,一只狗和一只青蛙》,它包含三张图片。在第一张图片中,一个男孩拿着网和桶,和他的狗一起沿着长满树木的小山向下跑,朝着山脚下池塘里的一只青蛙跑去,除此之外,半山腰处还有一个树干。这里有几点值得注意。首先,观众需要识别到这里是一个山坡,并识别出男孩、网、桶、狗、青蛙、莲叶、池塘、小山和树干。其次,观众需要认识到男孩和狗正在下山,并且男孩正在拿着网和桶。最后,为了理解叙事,观众必须推断出男孩的目标,即抓住青蛙(Graesser和Clark,1985;Long,Golding和Graesser,1992;Suh和Trabasso,1993)。当观看这样的图画故事时,观众可以通过场景的一些细节生成推断,例如,男孩的视线方向与青蛙位置之间的关系,以及男孩的网的位置,这些细节暗示了他抓青蛙的目标(Hutson,Magliano和Loschky,2018年)。这些场景背景、故事角色、行动、对象目标等构成了一个较为完整的叙事;第二张图片展示了在树干处男孩和狗倒在地上,根据与前一张图片的联系,需要联想到男孩和狗被树干绊倒的场景。男孩已经松开了他的网和桶,之所以用“松开”一词,是因为前一张图小男孩是拿着的。同时根据青蛙的视线,可以推测它注意到了这些事件。重要的是,男孩和狗在树干上绊倒与从第一张图片中推断出的捕捉青蛙的目标不一致;因此,它反映了这一目标的失败(Trabasso,van den Broek和Suh,1989)。这说明,理解这张图片不但需要有与理解第一张图片相同的感知和理解过程,还需要将两张图的表征连续起来(Graesser和Clark,1985);最后一张图片显示了水里伸出的靴子,观众必须意识到那是男孩的靴子,因为它暗示男孩掉进水里,这是由于他被树干绊倒所致…。
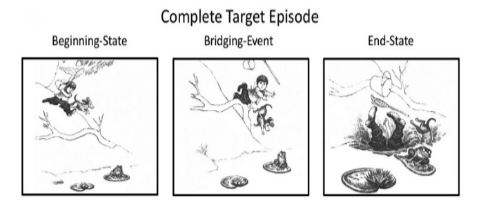
图1(a)

图1(b)
2.总结
总结一下,在视觉叙事这个过程中,首先通过初步的观察建立第一个情景模型(根据“19-12:语篇”,情景模型的五个索引,时间、空间、因果、目的、主角)。另外,情景模型中的信息不是同时建立的,而是“一些成分(或索引)需要建立在另外一些成分之上”,尤其是需要推理的成分:
(a)场景(时间地点):山坡。
(b)对象:男孩、网、桶、狗、青蛙、莲叶、池塘、小山和树枝。
(c)对象之间的动作或关系:根据姿势推断。如跑、拿。
(d)目的和意图:这些可以通过图片中的线索推理,如抓青蛙。“抓青蛙”这一意图的识别需要建立在这一阶段的其他处理结果之上,比如小男孩在往青蛙的方向跑(动作与关系成分),并且“网”(对象成分)这个工具也与“抓青蛙”有关。
(e)因果:
在后续的每个图片或者视频片段中,除了要提取当前的视觉信息,还需要根据情景模型理论,建立当前视觉信息(当前模型)与先前视觉信息(整合模型)的联系:
(a)场景:场景是否有转换。该漫画中在同一个山坡上,根据运动方式和位移距离,可以推理时间应该特别相近。
(b)对象:对象之间的联系,如第一张图与第二张图中男孩是对应的,第三张图中露出水面的靴子是男孩的。另外,还要判断是否有新对象出现,是否有对象退出。
(c)动作或关系:从当前视觉刺激,或当前与先前视觉刺激的联系推断。如第二张图,男孩的姿势是趴在地上,根据前一张图片男孩的姿势是跑下山,因此根据这两个姿势的变化可以推断他是摔倒的。对于一个连贯的动作场景,个体可以通过动作线索建立事物之间的语义关系,将动作的发生视为事件,识别基本动作线索为当前事件模型建构奠定了基础(Duke和Harrison,1995;Hafri,Papafragou和Trueswell,2013)。
(d)目的和意图:根据小男孩倒地的状态,推断出目标失败(建立在第二张图片的“动作”成分和第一张图片的“目标”成分之上)。
(e)因果:根据小男孩摔倒处有一根树干,可以推断小男孩是被树干绊倒的。这个因果成分的推断需要建立在“男孩倒地”的动作成分和“某些东西能使人绊倒”的世界知识成分上。
3.视觉叙事的要素
由上述成分可知,视觉叙事需要众多其他模块协调操作,包括物体识别(9-19:图像识别)、动作识别(9-10:运动感知)、场景识别(9-12:场景)、意图识别(9-23:动作意图理解)等等。下面还需要强调一点,即事件角色。
事件大多由人的动作或动作意图确定,事件类型的识别有助于对事件角色(如施动者与受动者)的识别,而事件角色信息中包含了事件类别信息。因此,二者间存在复杂的相互作用(Hafri,Papaftagou和Trueswell,2013;Strickland,2016)。比如,在买卖场景中,事件角色一般为买家和卖家;当然,当得知某人是卖家时,自然也会代入到买卖场景中。
在语言事件描述中,有关动作的对象都有其主题角色,其中施动者一般是主动发起事件者,而受动者则是被事件影响的人。例如,在“一个男孩推一个女孩”的描述中,男孩是施动者,女孩是受动者。典型施动者的特征是(a)在事件中是自愿参与的,(b)引起另一个参与者发生事件或状态的改变,(c)相对于另一个参与者,其位置发生了变化。相反,典型受动者则是(a)不一定是自愿参与事件的,(b)受事件“因果影响”,(c)“静止的”(Dowty,1991)。除了语言,有研究者提出,视觉事件及其角色识别依赖于上述原型施动者和原型受动者的事件角色特征(Hafri,Papafragou和Strickland,2013)。另外。人们在讲述某个动作或某个事件时,总是倾向于优先提到施动者,而后提到受动者。这种叙述先后偏好在不同语言中广泛存在(Griffin和Bock,2000)。“施动者优势”也出现在视觉动作识别的过程中,人类的视觉经验对于施动者的识别效率要显著高于对受动者的识别(Germeys和d'Ydeville,2007)。
二.景感知与事件理解理论(SPECT)
SPECT(Loschky,Hutson,Smith,Smith和Magliano,2018;Loschky,Larson,Smith和Maglianod,2020)是将场景感知过程、事件感知和阅读理解等过程整合在一起的关于视觉叙事的一个综合性理论框架,它被用于解释人类静态刺激(如漫画)或动态刺激(如电影、戏剧、虚拟现实、实现视觉)的视觉叙事机制。如图2所示,SPECT分为前端机制、后端机制和执行处理三部分。前端机制发生在单次眼动期间,它包含信息提取和注意选择两个子过程,前者指在一次眼动的注视过程中对视觉信息的提取,后者指不同阶段中对场景不同区域的注意分布,即控制后续眼动的过程;而后端机制则跨多个眼动的时间段内,发生在工作记忆和长期记忆中,它包括(a)基础构建,即情景模型的初始化,(b)映射,即将新信息整合到整合模型中,(c)切换,即当新信息无法与整合模型整合时,需要创建一个新的情景模型。SPECT模型还描述了感知过程(前端过程)和事件模型(后端过程)在构建过程是如何协调的,即两个过程之间是相互影响和相互作用的。前端机制和后端机制通常都是自动化处理过程,然而SPECT也考虑到有意识控制的过程,即执行处理。最后,完成处理的情景模型会被存放在长时情景记忆中,并且在这些存储的情景模型中,可以通过平均多个相似情景模型实例来衍生出语义记忆(Hintzman,1988)。
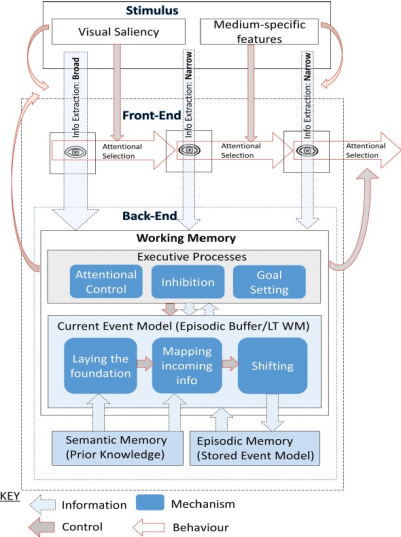
图2
1.前端机制
前端机制主要发生在单次眼动间。它包括两个子机制,信息提取,即从图像中提取信息语义表征,并将语义表征发送到工作记忆中;和注意选择,即为下一次眼动选择注意力焦点。
(a)信息提取 在该阶段,能广泛地提取全部或大部分的场景信息,产生场景类别(场景主旨),也能狭窄地提取特定信息,包括特定的人、物、基本动作、基本关系等。通常,更广泛(更粗略)信息的提取速度比更狭窄(更精细)信息的提取速度快(Fei-Fei,lyer,Koch和Perona,2007)。在第一次注视时,观察者以粗略到精细的方式感知场景的整体语义信息:从较上位的场景类别(例如,室内场景)到基本级别的类别(例如,厨房)。这些信息激活了对场景中重要信息所在位置的预期,这会影响下一次注视时的注意力选择(Eckstein,Drescher和Shimozaki,2006),如菜刀一般处于图片的中间(上中下)。场景中的人和物(男孩、网、桶、狗、树干等)可能能在单次注视期间被识别(Fei-Fei,lyer,Koch和Perona,2007),一些较小的刺激物(如“青蛙”)可能由于太小而无法被外周视觉检测到,需要进一步的注视(通过眼动使用中央凹观察)(Nelson和Loftus,1980),而基本级动作(如“奔跑下山”)可能需要两次眼动才能提取(Larson,2012),刺激物之间的关系的提取(如“男孩拿着捕虫网和水桶”)也可能需要两到三次的眼动。因此,在前端过程中,随着每次眼动,越来越详细的信息被逐一提取,并在后端的工作记忆中进行积累(Hollingworth和Henderson,2002;Pertzov,Avidan和Zohary,2009)。
(b)注意选择
另一个关键的前端过程是注意选择。在每次注视中,在下一次眼动之前,注意力会悄悄地转移到下一个即将被注视的物体上,换句话说信息提取和注意选择是同时发生的(Deubel和Schneider,1996)。
注意选择受到内外部因素的影响,外部因素是自下而上的刺激吸引力,内部因素是自上而下的认知过程。具体来说,刺激吸引力是由视觉特征的对比决定的,即在某一视觉特征的维度上,当某个位置与其他位置存在明显不同时,这个位置将比其他位置更能吸引注意,这些视觉特征包括运动、亮度、颜色、方向和大小等。而自上而下的认知过程包括任务驱动、寻找特定信息、世界知识等(“17-1:注意”和“9-15:视觉注意”)。
外部因素需要特别提到一种显著性算法(Garcia-Diaz,Fdez-Vidal,Pardo和Dosil,2009),这种显著性是基于在多个大小尺度上分析图像元素的方向,并找到与图像其余部分最不同的区域。例如,通过计算这种显著性,图3(a)显示了最高显著性的区域(即最有可能吸引观众注意力的区域)是男孩的头部和树的腿。为了验证该算法的正确性,研究人员统计了39名被试在观看此图像时的实际注视点平均图,即图3(b),实验证实了两张图具有高度的一致性。
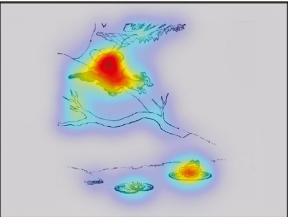
图3(a)
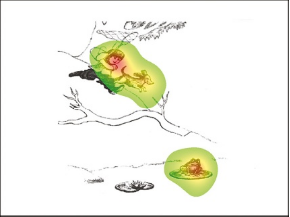
图3(b)
在内部注意方面,存在有意识控制的自上而下效应与基于无意识知识的自上而下效应之间的差异。这两个效应可以在视觉搜索等任务中相互作用,其中,有意识的自上而下的目标(例如,寻找烟囱)可以通过无意识的自上而下的知识(例如,烟囱在房子的顶部)来促进(Eckstein,Drescher和Shimozaki,2006; Torralba,Oliva,Castelhano和Henderson等人,2006)。在SPECT中,有意识的自上而下的注意力控制发生在工作记忆,在执行过程中触发(Moss,Schunn,Schneider和McNamara等人,2011)。无意识的自上而下过程可以来自情景模型或相关的世界知识。
在单次注视期间,注意力选择可以是高度集中的,例如把注视力聚焦在某一很小的范围;也可以是广泛地分布在视觉场的大部分区域。视觉注意的分配会根据观察者的需求动态变化。一般来说,在观看图像的前2秒属于环境模式,这时观众开始探索图像以确定主要场景元素的位置。此时的眼跳距离较长,表明其注意力广泛分布;凝视持续时间较短,表明仅进行浅层处理。然后,在观看的4至6秒内属于焦点模式,观众开始探索图像以确定主要场景元素的位置,此时的眼跳距离较短,表明其注意力集中,凝视持续时间较长,表明其进行更深入的处理(Pannasch,Helmert,Roth和Herbold等人,2008;Smith和Mital,2013)。另外,研究发现,在被识别为事件边界的图像上,眼跳距离较长,凝视持续时间较短。具体来说,对于边界图像,平均扫视视觉角度大约在5度,但对于非边界图像,则大约下降了20%(从5度降至4度)。对于边界图像,平均注视时间保持较长,仅比非边界图像慢22%。这些结果与SPECT提出的假设一致,即在新事件的开始时,观看者以环境模式探索图像,为新事件的情景模型奠定基础。在后续阶段,观看者则以焦点模式关注场景中某些特定信息。就SPECT的两个前端机制而言,较长的扫视是注意力选择变化的证据,较短的注视将被归因于信息提取的变化,两者都与当前事件模型的变化有关,即奠定基础和切换。
最后,这里可以产生两种推论,第一种是,由于这种从周围环境到焦点的注意转换发生在多个注视期间,因此后端过程可能影响前端过程的注意选择。当然,视觉叙事的刺激分为两种,一种是静态的(漫画、图片故事),另外一种是动态的(电视节目、视频和电影)。后端过程对注意力选择的影响也要分开讨论。具体来说,对于动态的视觉叙事,自下而上过程似乎对注意力选择施加了更多的影响,这可能是因为在动态视觉叙事中,“运动”特征是预测眼球运动和引导注意选择的唯一最强刺激特征(Carmi和Itti,2006;Mital,Smith,Hill和Henderson, 2010)。相反,由于静态叙事缺乏运动特征,而观看是自定节奏的(如被试可以在图片的不同位置上随意切换),它们似乎可以通过后端情景模型对注意选择提供更多的自上而下过程影响。第二种是,信息提取和注意选择通常是协同工作的,注意力选择即选择将你的眼睛发送到哪个物体上,信息提取即在注视期间对该物体的视觉处理。
2.后端机制
后端过程支持在工作记忆中构建一个连贯的情景模型。一个连贯的情景模型包含有关事件发生的时间和地点(时空框架)、事件中的实体(人、动物、物体)、这些实体的属性(例如颜色、大小、情绪、目标)、参与者的行为以及关系信息(空间、时间、因果、所有权、亲属关系和社会关系等)等等(Magliano,Miller和Zwaan,2001;Zwaan,Magliano和Graesser,1995;Zwaan和Radvansky,1998))。如图2所示,SPECT描述了构建情景模型过程中所涉及的三个关键后端过程:基础构建、映射以及切换。这个后端过程是自动发生的。
(1)基础构建
基础构建是视觉情景模型第一个节点的构建过程,其中节点代表基本的表征单元(例如,命题或知觉模拟)。这些节点随后成为后续信息连接或不连接的记忆结构(Gernsbacher, 1990)。如构建例中第一张图的情景模型,这个情景模型会成为后续第二和第三张图的整合模型,整合过程在工作记忆中进行。根据SPECT的观点,相比后续其他图片,观看第一张图片时需要进行基础构建,因此观看时间更长,在Foulsham等人的研究中证实了这点(Foulsham,Wybrow和Cohn,2016)。
每一部分的视觉叙事都对后续的注意选择产生影响,尤其是开头的部分。Hutson等人(Hutson,Smith,Magliano和Loschky,2017)研究了剪辑对电影注意力选择的影响。实验中的电影片段展示了两对夫妇在墨西哥/美国边境城镇的街道上相遇的情景。影片中的一个人设置了一个定时炸弹,并把它放在了一辆车的后备箱。不久后,拥有这辆车的夫妇钻进了这辆车并开走。然后,车上的这对夫妇在街上遇到了另一对走路的夫妇。该电影片段分为两种条件,一种是剪辑条件,把放置炸弹的片段剪去;另外一种是无剪辑条件(完整视频)。影片观看结束后被试需要预测接下来发生的事情。研究者认为,由于炸弹在情景模型中具有巨大的因果力,因此相比不知道炸弹的观众,知道炸弹的观众更可能关注汽车。实验结果显示,剪辑条件下的被试更倾向预测“汽车会爆炸”,而无剪辑条件的被试更倾向预测“两对夫妇会一起吃饭”。这个实验的另外一个发现是,在两种条件下,被试对汽车的注视比例是相等。这进一步表明,在动态视觉中,(汽车的)运动特征(自下而上过程)是被试注意力选择的主要控制因素。
(2)映射
类似文本的阅读理解,新注视点、新图像或新视频片段所产生的当前模型都会根据时间、空间、实体、因果关系和目标等5个索引与整合模型产生联系,从而使整合模型得到更新。如图1,第二张图与第一张图的实体之间的连接,或者第二张图中先后两个注视点(如假设旧信息“男孩摔倒”(前一次注视)与新信息“树干”产生因果联系(后一次注视))。完成整合后的整合模型存放在长时工作记忆中。通过这种方式,随着每次注视提取到了更多的信息,情景模型逐渐得到完善。
推理是映射的一种方式,包括因果推理、目的推理和连接性推理。如图1所示,图(a)的漫画描述了一个较为完整的故事,它们由开始状态、连接事件和结束状态组成(每张图片均没有文字描述);而图(b)缺少了这个漫画的连接事件,只有开始状态和结束状态,当读者观看图(b)时,为了维持故事的连贯性,需要对连接事件进行推理构建。比如在例中,被试需要思考是什么原因使男孩和小狗掉入水中。生活中连接性推理是常见的,比如在你参与的一件事件中,你中途离开了一段时间,在你返回后会根据当前状态和其他信息推测中间离开阶段发生了什么。在最近的一项研究(Magliano,Larson,Higgs和Loschky,2016)中,研究者设置了两种条件,一种是显示三种状态的阅读条件,另外一种是缺少了连接事件的推理条件。实验要求观众在电脑屏幕上观看这些图片故事,一次展示一张图像,并在看完结束状态图像后说出你对故事的思考。这项研究的一个发现是,在推理条件,由于连接事件被推理得出,被试更倾向于提到连接事件动作。这说明,当连接事件是通过生成推理的方式得出来时,会导致它在情景模型中被高度激活。相反,如果只是简单地看到它,则不会有这种现象;另外一个发现是,相比阅读条件,推理条件下观看结束图片所花的时间更长(“平均约2450毫秒”对比“平均约2800毫秒”)。研究者认为,比起简单的阅读,生成连接推论的时间会更长。这两个发现一致认为,被试在推理条件下确实会产生连接性推理。
Magliano等人(Magliano,Larson,Higgs和Loschky,2016)研究了在推理条件下导致被试观看时间延长的眼动过程是什么?这里有三种可能,第一种是增加了注视的持续时间(进行更深的加工),第二种是更多的眼动过程(进行更多的搜索),第三种是两者皆有。实验发现,阅读条件和推理条件两种条件下,注视持续时间几乎没有差异。然而,相比阅读条件,在推理条件下,产生的眼动数量有20%的增加(分别为9次和11次)。该结果与第二种可能一致,这种现象被称为视觉搜索假说。这表明,连接事件的生成推理是不需要进一步的内部处理(更多凝视时间),而可能是需要收集额外的信息(更多眼动)。后续的一个研究还发现,在推理条件下,为了维持画面连贯性,被试更倾向于聚焦对生成推断更有帮助的区域。由于这个过程需要使用前端过程的注意选择,这说后端过程的映射机制对前端机制(即注意力选择机制)具有重要影响。
(3)切换
当新信息与整合模型无法发生映射时,观察者就会创建一个新的情景模型。另外,当模型预测失败(时间、空间、实体、因果关系、目标、动作或关系的不连续),就会产生事件切割,即将连续的感知解析为离散事件(19-12:语篇)。当事件已经结束时,其对应的情景模型就会存储在长时工作记忆或长时记忆中,并开始新的基础构建和新的情景模型。
一项研究对视觉叙事的事件切割进行了研究。首先参与者需要阅读一个故事,随后被试会看一组关于某个故事的图片集。被试的任务是当他们认为故事情境发生变化时,则点击该图片。故事中包含许多变化,尽管并非每张图片都与一个变化相对应。点击图片后,被试会看到该图片周围有一个虚线边框,表示该图片是故事的一个边界事件。如图4所示,这个故事包含8张图片,其中3张带有虚线边框。这三个边界图片似乎处于不同的分割粒度。第三个边界图片似乎是一个粗略的事件边界标记,这意味着一个新的更大的事件的开始,这是因为地点、时间、动作和目标都发生了很大的变化(即从室内到森林,需要更长时间到达那里,角色们从拆礼物到正在旅行,目的是未知)。前两个边界图片是两个较细的分割粒度,因为它们似乎是一个较大事件(即收到礼物以及角色之间的互动)的两个子事件,其中这两个子事件分别是打开礼物和发现一只新的青蛙。(Magliano,Loschky,Clinton和Larson,2013)

图4
3.执行处理
上述讨论的后端过程通常是自动发生的,而无需观看者的意识参与。然而,当观看者觉得有必要时,他们可以对自己的思维过程施加意识控制。例如设定目标(例如,总结视觉叙事)、注意力控制(例如,有意识地在叙事中搜索特定信息)和抑制(例如,有意识地忽略被认为无关紧要的信息)。在一项研究中,被试在观看完一段影片后,需要根据记忆绘制出一副包含所有地标及其相对位置的地图。显然,要完成这项任务需要设定记忆地标及其相对位置的目标,有意识地控制注意力以实现这一目标(例如,控制注意力以聚焦背景建筑、路标等),并抑制对其他事物(如主角)的注意。(Loschky,Hutson,Smith,Smith和Magliano,2018;Loschky,Larson,Smith和Maglianod,2020)



评论前必须登录!
注册