 网硕互联帮助中心
网硕互联帮助中心因为有时候Kaggle的数据集很大,很显然下到本地再上传到云服务器不现实,所以官方提供了API的下载接口。可以通过Kaggle、Kagglehub、cURL、mlcroissant进行下载。
需要使用算力服务器下载kaggle上的数据集,使用kaggle自带的kagglehub快速下载。
/要使用Kaggle 的公共 API+,必须首先使用 API 令牌进行身份验证。转到用户个人资料的“帐户”选项卡,然后选择“创建新令牌”。这将触发下载 kaggle.json 文件,该文件包含 API 凭据。
将kaggle.json 文件上传到服务器,创建目录 。
mkdir -p ~/.kaggle
将 kaggle.json 文件上传到该目录。
在服务器上安装kagglehub
pip install kagglehub
使用 kagglehub 的核心是找到资源的唯一标识符,称为 "Handle"。这个 Handle 的格式通常是: [所有者]/[模型名称]/[框架]/[变体]
您可以在 Kaggle 的模型页面上轻松找到它。通常在 "Usage" 或代码示例部分会直接提供。
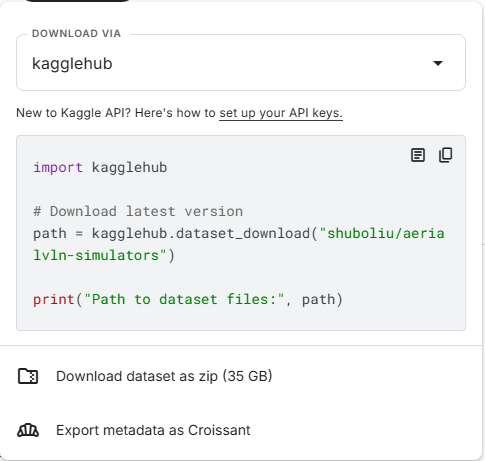
import kagglehub
# Download latest version
path = kagglehub.dataset_download("shuboliu/aerialvln-simulators")
print("Path to dataset files:", path)
Kagglehub提供得下载示例当中只给了下载到默认路径的方法。如果数据集很大,(一般算力服务器给的系统盘30g)系统的缓存文件夹不够用,需要更改下载数据集的目录。
直接在脚本中加入环境变量设置
export KAGGLEHUB_CACHE=/root/autodl-tmp/
记得source哦
source ~/.bashrc



评论前必须登录!
注册