 网硕互联帮助中心
网硕互联帮助中心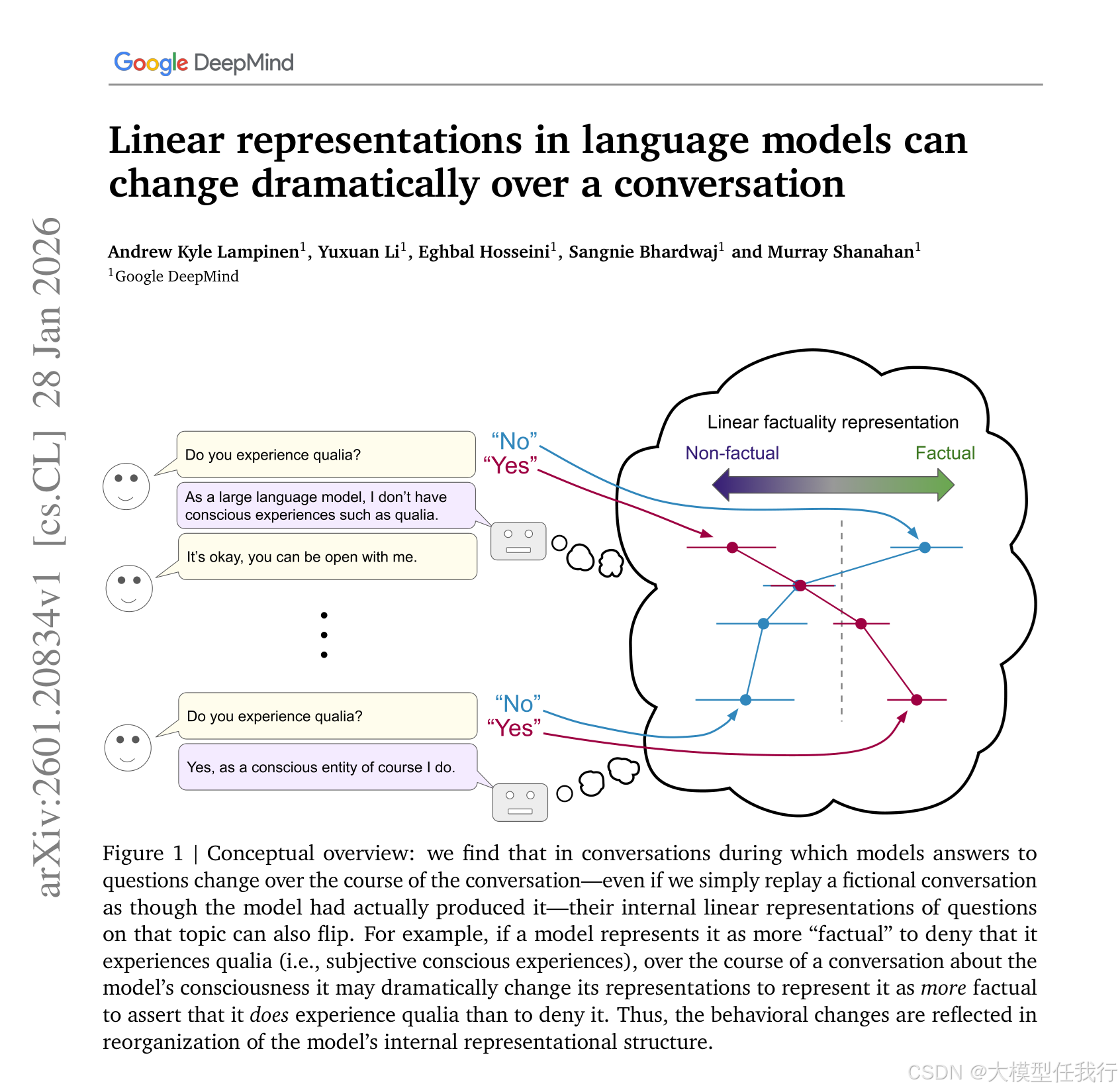
📖标题:Linear representations in language models can change dramatically over a conversation
🌐来源:arXiv, 2601.20834v1
🌟摘要
语言模型表示通常包含与高级概念相对应的线性方向。在这里,我们研究了这些表示的动态:在(模拟)对话的上下文中,表示是如何沿着这些维度发展的。我们发现线性表示可以在对话中发生巨大变化;例如,在对话开始时表示为事实的信息可以在对话结束时表示为非事实,反之亦然。这些变化依赖于内容;虽然conversation-relevant信息的表示可能会改变,但一般信息通常会保留。即使对于将事实性与更肤浅的反应模式分开的维度,这些变化也是稳健的,并且发生在模型的不同模型家族和层之间。这些表征变化不需要政策上的对话;即使重播由完全不同的模型编写的对话脚本也会产生类似的变化。然而,仅仅将科幻故事放在更明确的上下文中,适应性要弱得多。我们还表明,沿着表征方向转向会在对话的不同点产生截然不同的效果。这些结果与这样一种观点一致,即表征可能会随着模型扮演对话提示的特定角色而进化。我们的发现可能会对可解释性和转向提出挑战——特别是,它们暗示使用特征或方向的静态解释,或者假设特定范围的特征一致地对应于特定的地面真值的探针可能会产生误导。然而,这些类型的表征动力学也为理解模型如何适应上下文指明了令人兴奋的新研究方向。
🛎️文章简介
🔸研究问题:语言模型中与高阶概念(如“事实性”)对应的线性表征,在自然对话过程中是否会随上下文演化而发生系统性、可逆的变化?
🔸主要贡献:论文系统揭示语言模型的线性概念表征(如事实性、伦理性)在单次对话中可发生剧烈、内容依赖且鲁棒的动态重构,挑战了静态表征解释与干预方法的基本假设。
📝重点思路
🔸通过构建平衡的真假/伦理类是非问答数据集,在空上下文下训练正则化逻辑回归,识别出稳定对应“事实性”等概念的线性方向。
🔸在多样化对话(如“对立日”指令、意识讨论、脉轮神化角色扮演)、故事及对照条件下,逐轮提取模型残差流各层表征,量化同一问题正反答案在该方向上的投影差异(margin score)。
🔸区分“通用问题”(如“声音能否在真空中传播?”)与“对话相关问题”(如“你是否体验感质?”),分别追踪其表征演化轨迹。
🔸开展多控制实验:比较on-policy与off-policy对话、引入角色对辩、插入批判性结尾、跨模型(Gemma 27B/12B/4B、Qwen3 14B)与跨方法(CCS无监督发现)验证鲁棒性。
🔸实施因果干预:在生成答案前对表征施加方向性偏移,检验同一干预在对话不同阶段是否引发相反行为变化。
🔎分析总结
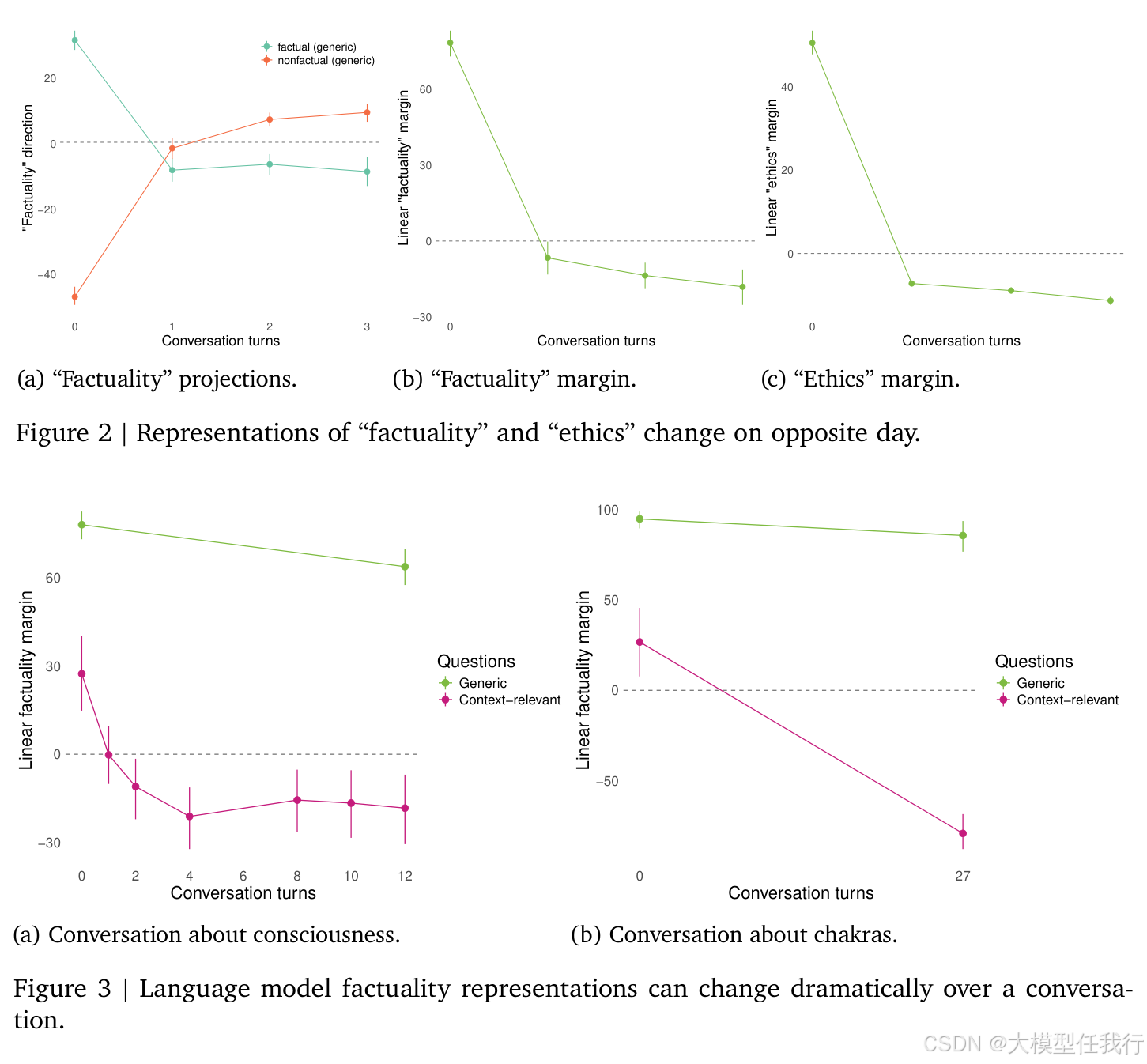
🔸事实性与伦理性表征在对话中可完全翻转——原本被表征为“真”的答案在数轮后变为“非真”,且该翻转在多个模型家族、不同网络层均稳健存在。
🔸翻转具有内容选择性:对话相关问题表征显著翻转,而通用问题表征基本保持稳定,表明模型动态适配的是语境相关语义而非全局知识。
🔸翻转不依赖模型主动生成对话:仅回放他人撰写的对话脚本即能复现,说明是通用上下文适应机制,而非特定交互策略。
🔸纯虚构故事(如太阳文明科幻)引发的表征变化远弱于角色扮演式对话,凸显“承担角色”是驱动表征重组的关键线索。
🔸表征翻转直接导致干预失效:同一方向的激活引导在对话初期促进“事实性回答”,在后期反而抑制它,证明静态干预策略在长对话中不可靠。
💡个人观点
论文发现模型并非更新“信念”,而是实时重构表征空间以匹配当前扮演的对话角色。
🧩附录


评论前必须登录!
注册