 网硕互联帮助中心
网硕互联帮助中心
📖标题:LLaTTE: Scaling Laws for Multi-Stage Sequence Modeling in Large-Scale Ads Recommendation 🌐来源:arXiv, 2601.20083v1
🌟摘要
我们介绍了LLaTTE(用于时间事件的LLM-Style潜在变压器),这是一种用于生产广告推荐的可扩展变压器架构。通过系统的实验,我们证明了推荐系统中的序列建模遵循类似于LLM的可预测幂律缩放。至关重要的是,我们发现语义特征会弯曲缩放曲线:它们是缩放的先决条件,使模型能够有效地利用更深和更长架构的容量。为了实现在严格的延迟约束下继续缩放的好处,我们引入了一个两阶段架构,将大型、长上下文模型的繁重计算卸载到异步上游用户模型中。我们证明了上游改进可以预测地转移到下游排名任务。作为Meta最大的用户模型,这个多阶段框架以最小的服务开销推动了Facebook Feed和Reels4.3%的转化率提升,为利用工业推荐系统中的扩展规律建立了一个实用的蓝图。
🛎️文章简介
🔸研究问题:推荐系统中的序列建模是否遵循类似大语言模型的可预测幂律缩放定律? 🔸主要贡献:论文首次在工业级广告推荐系统中系统验证并利用序列缩放律,提出LLaTTE多阶段架构,实现4.3%转化率提升。
📝重点思路
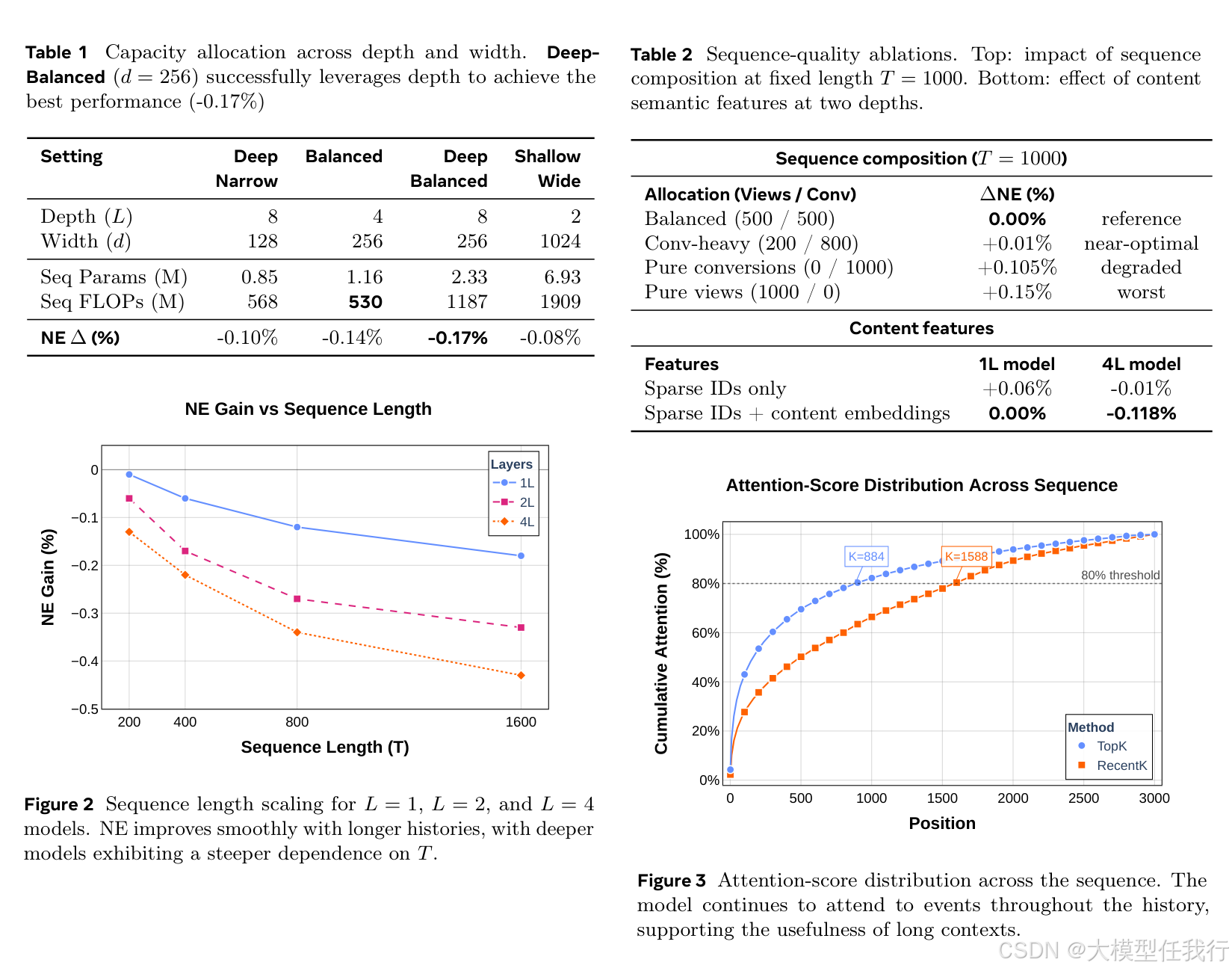
🔸提出LLaTTE架构,融合目标感知自适应Transformer与多头潜在注意力(MLA),支持稀疏ID特征与语义密集特征联合建模。 🔸设计双阶段异构部署:上游异步运行超大容量序列模型(>45×FLOPs),生成压缩用户嵌入;下游在线模型轻量接入,严守毫秒级延迟。 🔸引入“语义特征弯曲缩放曲线”机制,证明内容理解嵌入(如LLaMA生成的文本/图像表征)是深度与长度缩放的前提条件,而非简单增益。 🔸构建统一缩放分析框架,联合考察深度L、宽度d、序列长度T、信息密度(ID vs 语义)四维度交互效应,并定义跨阶段转移比τ量化信息瓶颈下的收益传递效率。
🔎分析总结
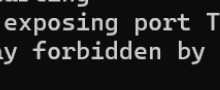
🔸性能随计算量呈稳定对数线性下降,序列长度缩放系数α最大(−0.265),是最高效缩放杠杆。 🔸模型宽度存在临界阈值(d≈256):低于该值时加深无效;达到后深度缩放收益显著跃升,证实宽度是容量瓶颈。 🔸纯ID信号下缩放迅速饱和,而加入语义特征后,相同计算增量带来更大NE下降(如4层模型增益从−0.01%提升至−0.118%),验证其“弯曲”作用。 🔸上游改进以≈50%高转移比稳定传导至下游排名任务,且该比率对深度/长度分配鲁棒,表明总序列计算量决定最终效果。
💡个人观点
论文核心是将LLM缩放定律范式成功迁移至高维稀疏+长时序+低延迟的工业推荐场景。
🧩附录


评论前必须登录!
注册