 网硕互联帮助中心
网硕互联帮助中心MySQL索引优化:从入门到实战
一、为什么需要索引优化?
在实际开发中,我们经常遇到这样的场景:一条SQL查询语句在数据量小时执行飞快,但随着数据增长,查询速度越来越慢,甚至成为系统性能瓶颈。这时候,索引优化就成为了提升数据库性能的关键手段。
真实案例对比
假设我们有一张用户表user,包含1000万条记录:
没有索引的查询:
SELECT * FROM user WHERE mobile = '13800138000';
执行时间:8.5秒
添加索引后的查询:
— 创建索引
CREATE INDEX idx_mobile ON user(mobile);
— 再次执行同样的查询
SELECT * FROM user WHERE mobile = '13800138000';
执行时间:0.003秒
性能提升:2800倍!
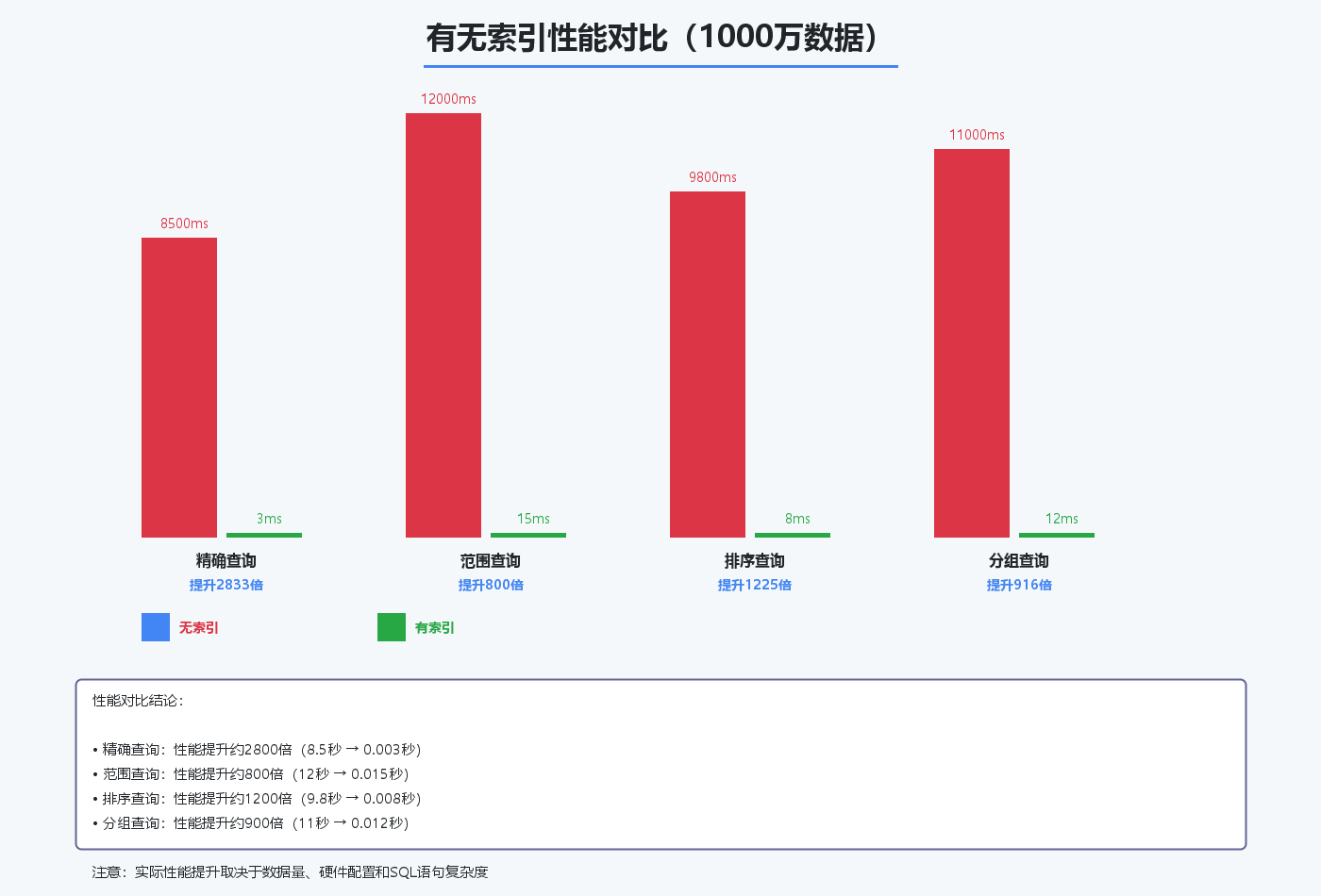
这就是索引的威力。
二、MySQL索引类型全解析
2.1 主键索引(PRIMARY KEY)
主键索引是唯一索引的一种特殊形式,每个表只能有一个主键,主键列的值不能为NULL。
CREATE TABLE users (
id BIGINT AUTO_INCREMENT PRIMARY KEY,
username VARCHAR(50),
email VARCHAR(100)
);
特点:
- 唯一性约束
- 非空约束
- 自动聚簇索引(InnoDB引擎)
2.2 唯一索引(UNIQUE INDEX)
唯一索引要求索引列的值必须唯一,但允许有空值(空值不参与唯一性比较)。
CREATE TABLE users (
id BIGINT PRIMARY KEY,
username VARCHAR(50) UNIQUE,
email VARCHAR(100),
UNIQUE KEY idx_email (email)
);
— 或使用ALTER TABLE添加
ALTER TABLE users ADD UNIQUE INDEX idx_username (username);
使用场景:
- 用户名
- 邮箱地址
- 身份证号
- 手机号
2.3 普通索引(INDEX)
普通索引是最基本的索引类型,没有任何约束,主要用于加速查询。
CREATE TABLE orders (
id BIGINT PRIMARY KEY,
user_id BIGINT,
order_no VARCHAR(50),
create_time DATETIME,
INDEX idx_user_id (user_id),
INDEX idx_create_time (create_time)
);
— 或使用ALTER TABLE添加
ALTER TABLE orders ADD INDEX idx_order_no (order_no);
2.4 组合索引(COMPOSITE INDEX)
组合索引是在多个列上创建的索引,遵循"最左前缀原则"。
— 创建组合索引
CREATE INDEX idx_user_status_time ON orders(user_id, status, create_time);
— 这些查询可以使用索引
SELECT * FROM orders WHERE user_id = 1;
SELECT * FROM orders WHERE user_id = 1 AND status = 1;
SELECT * FROM orders WHERE user_id = 1 AND status = 1 AND create_time > '2024-01-01';
— 这个查询无法使用索引(跳过了user_id)
SELECT * FROM orders WHERE status = 1 AND create_time > '2024-01-01';
最左前缀原则详解:
组合索引 (a, b, c) 相当于创建了三个索引:
- (a)
- (a, b)
- (a, b, c)
查询条件必须包含最左侧的列a,索引才能生效。
2.5 全文索引(FULLTEXT INDEX)
全文索引用于对文本内容进行搜索,仅支持CHAR、VARCHAR和TEXT类型。
CREATE TABLE articles (
id BIGINT PRIMARY KEY,
title VARCHAR(200),
content TEXT,
FULLTEXT INDEX idx_title_content (title, content)
) ENGINE=InnoDB;
— 使用全文索引
SELECT * FROM articles
WHERE MATCH(title, content) AGAINST('MySQL 索引优化' IN NATURAL LANGUAGE MODE);
使用场景:
- 文章搜索
- 商品描述搜索
- 评论内容搜索
2.6 空间索引(SPATIAL INDEX)
空间索引用于地理空间数据的存储和查询。
CREATE TABLE locations (
id BIGINT PRIMARY KEY,
name VARCHAR(100),
coordinates POINT NOT NULL,
SPATIAL INDEX idx_coordinates (coordinates)
) ENGINE=MyISAM;
— 查找附近的位置
SELECT * FROM locations
WHERE ST_Distance_Sphere(coordinates, ST_GeomFromText('POINT(116.404 39.915)')) < 1000;
三、索引存储结构
3.1 B+树索引(InnoDB默认)
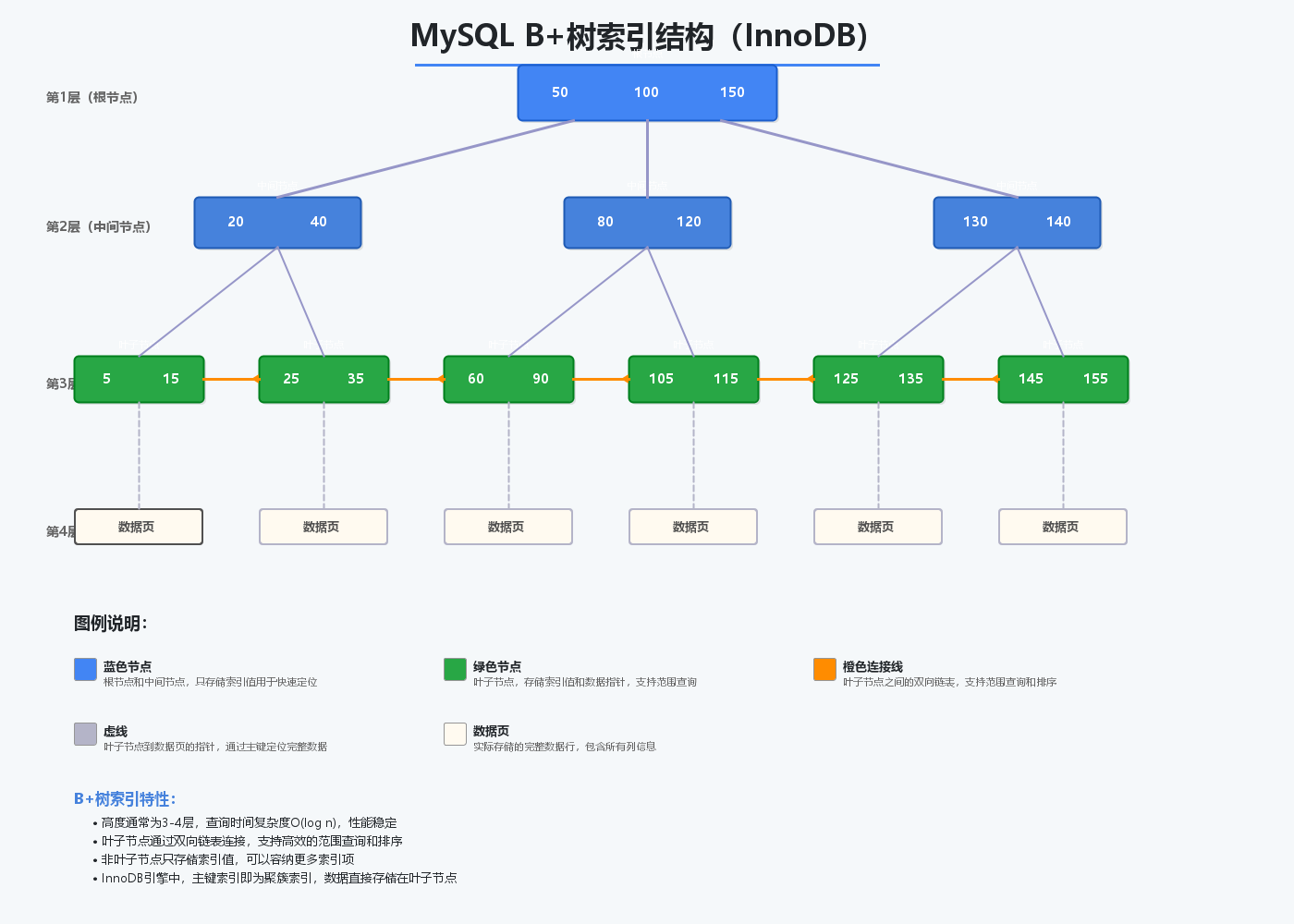
B+树是MySQL InnoDB引擎的默认索引结构,具有以下特点:
优势:
- 查询效率稳定(O(log n))
- 范围查询性能好
- 支持高并发
- 树的高度低(通常3-4层)
B+树查找过程:
3.2 Hash索引(Memory引擎)
Hash索引基于哈希表实现,只支持精确查找。
特点:
- 查询速度极快(O(1))
- 只支持等值比较(=、IN、<=>)
- 不支持范围查询
- 不支持排序
CREATE TABLE users_hash (
id BIGINT PRIMARY KEY,
username VARCHAR(50),
email VARCHAR(100),
HASH INDEX idx_username (username)
) ENGINE=Memory;
3.3 聚簇索引 vs 非聚簇索引
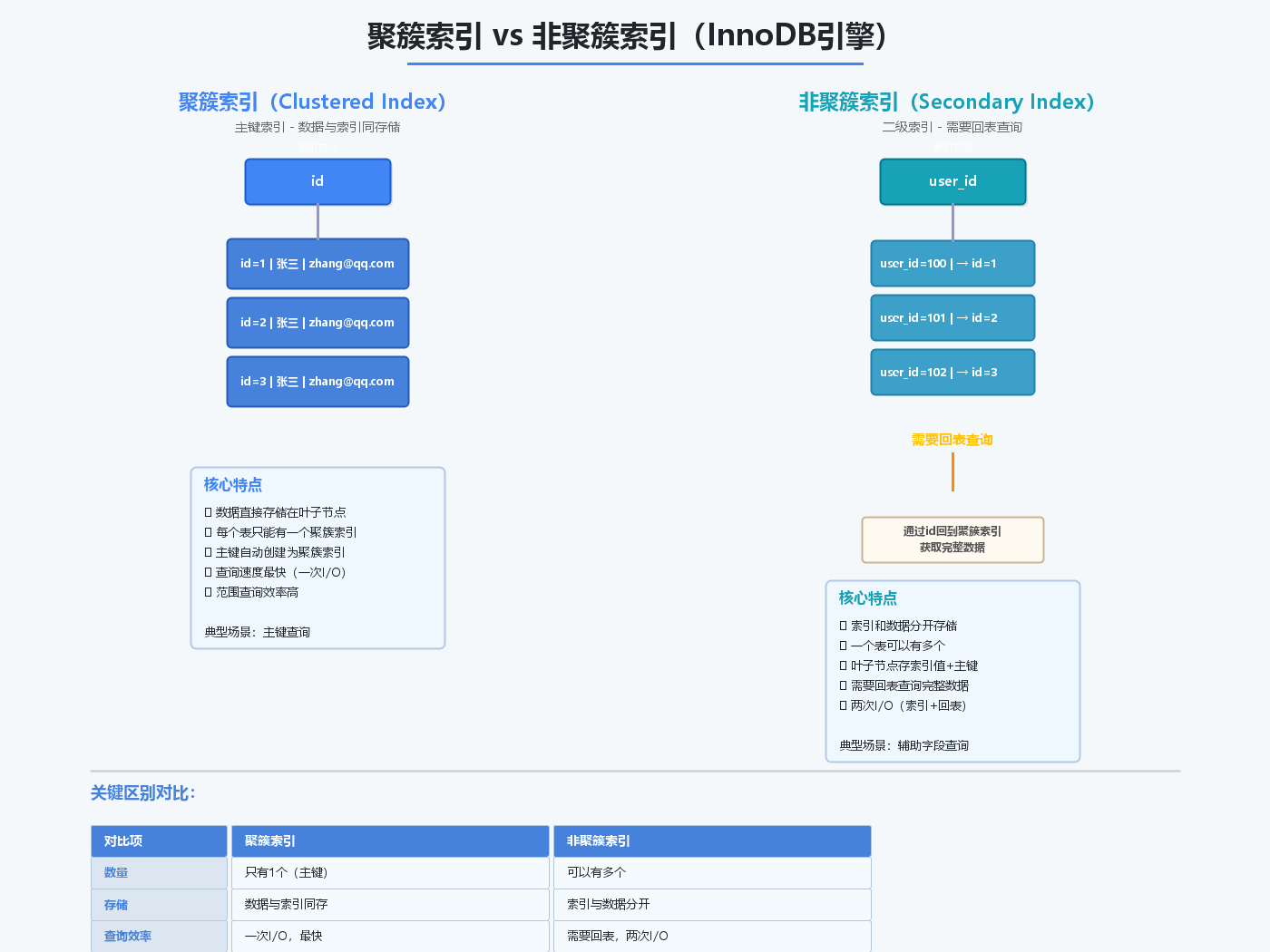
聚簇索引:
- 主键索引自动创建为聚簇索引
- 数据行和索引存储在一起
- 每个表只能有一个聚簇索引
- InnoDB引擎使用聚簇索引
非聚簇索引(二级索引):
- 索引和数据分开存储
- 需要回表查询完整数据
- 一个表可以有多个非聚簇索引
四、索引优化实战策略
4.1 选择合适的索引列
适合创建索引的列:
- 经常作为WHERE条件的列
- 经常用于JOIN连接的列
- 经常用于ORDER BY排序的列
- 经常用于GROUP BY分组的列
- 选择性高的列( distinct值多 / 总值)
不适合创建索引的列:
- 频繁更新的列
- 区分度低的列(如性别:只有男/女)
- 数据类型大的列(如TEXT、BLOB)
- 很少被查询的列
4.2 索引选择度计算
索引选择度 = 不重复的值数量 / 总行数
选择度越接近1,索引效果越好。
— 计算索引选择度
SELECT
COUNT(DISTINCT column_name) / COUNT(*) as selectivity
FROM table_name;
— 示例
SELECT
COUNT(DISTINCT user_id) / COUNT(*) as user_selectivity,
COUNT(DISTINCT status) / COUNT(*) as status_selectivity
FROM orders;
判断标准:
- 选择度 > 0.1:适合创建索引
- 选择度 < 0.01:不建议创建索引
- 选择度 < 0.001:完全不适合创建索引
4.3 覆盖索引优化
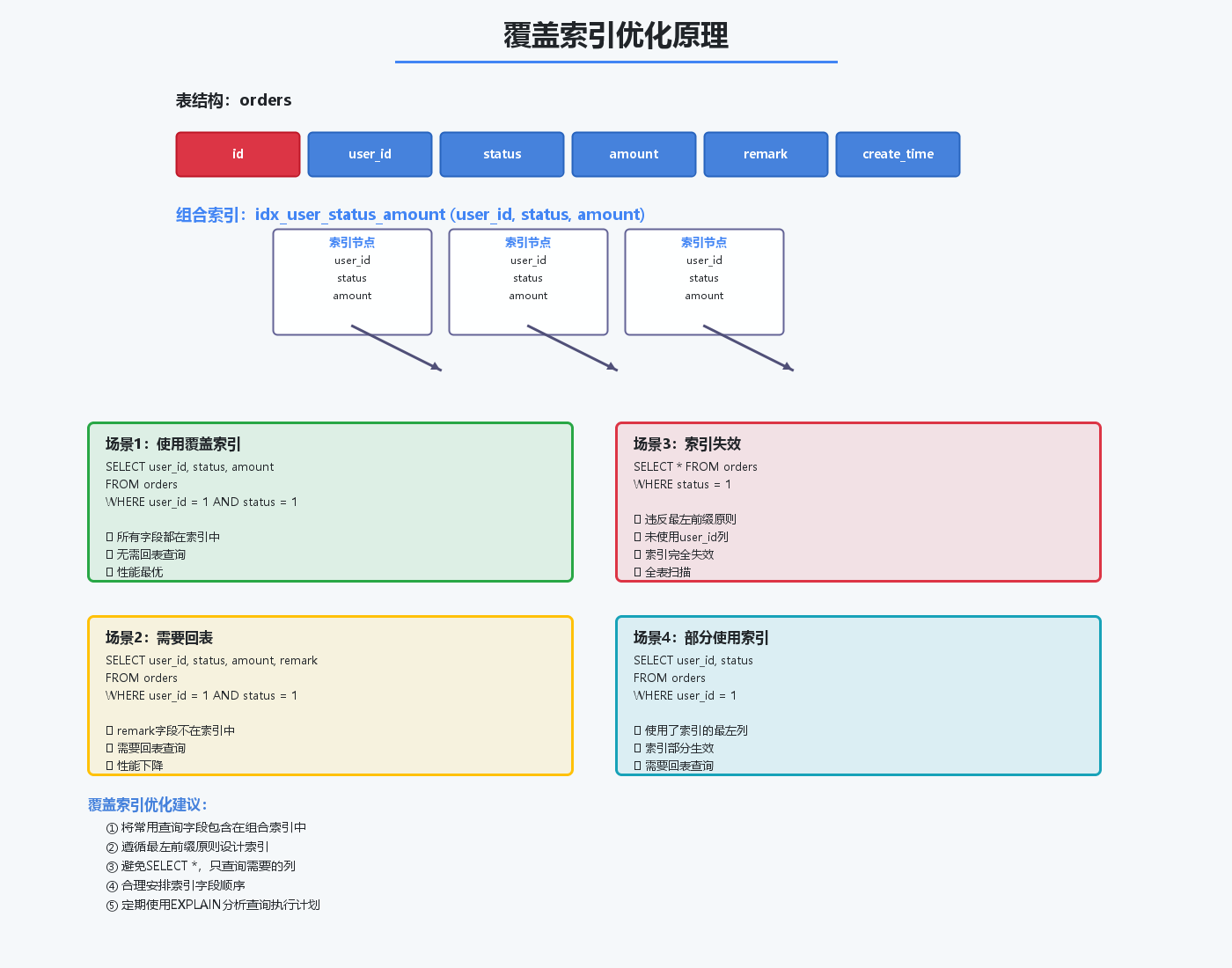
覆盖索引是指查询的所有字段都包含在索引中,无需回表查询。
— 创建组合索引
CREATE INDEX idx_user_status_amount ON orders(user_id, status, amount);
— 这个查询可以使用覆盖索引,不需要回表
SELECT user_id, status, amount
FROM orders
WHERE user_id = 1 AND status = 1;
— 这个查询需要回表(包含了非索引字段remark)
SELECT user_id, status, amount, remark
FROM orders
WHERE user_id = 1 AND status = 1;
4.4 避免索引失效
索引失效的常见情况:
— 索引失效
SELECT * FROM users WHERE YEAR(create_time) = 2024;
— 索引生效
SELECT * FROM users WHERE create_time >= '2024-01-01' AND create_time < '2025-01-01';
— phone是varchar类型,索引失效
SELECT * FROM users WHERE phone = 13800138000;
— 索引生效
SELECT * FROM users WHERE phone = '13800138000';
— 索引失效
SELECT * FROM users WHERE username LIKE '%admin%';
— 索引生效
SELECT * FROM users WHERE username LIKE 'admin%';
— 索引失效(user_id有索引,status没有索引)
SELECT * FROM orders WHERE user_id = 1 OR status = 1;
— 索引生效(两个字段都有索引)
SELECT * FROM orders WHERE user_id = 1 OR order_no = 'ORDER001';
— 索引可能失效
SELECT * FROM orders WHERE status != 1;
— 索引生效
SELECT * FROM orders WHERE status IN (1, 2, 3);
五、生产环境优化案例
5.1 慢查询优化案例
问题SQL:
SELECT * FROM orders
WHERE user_id = 123
AND status IN (1, 2, 3)
AND create_time > '2024-01-01'
ORDER BY create_time DESC
LIMIT 20;
执行计划分析:
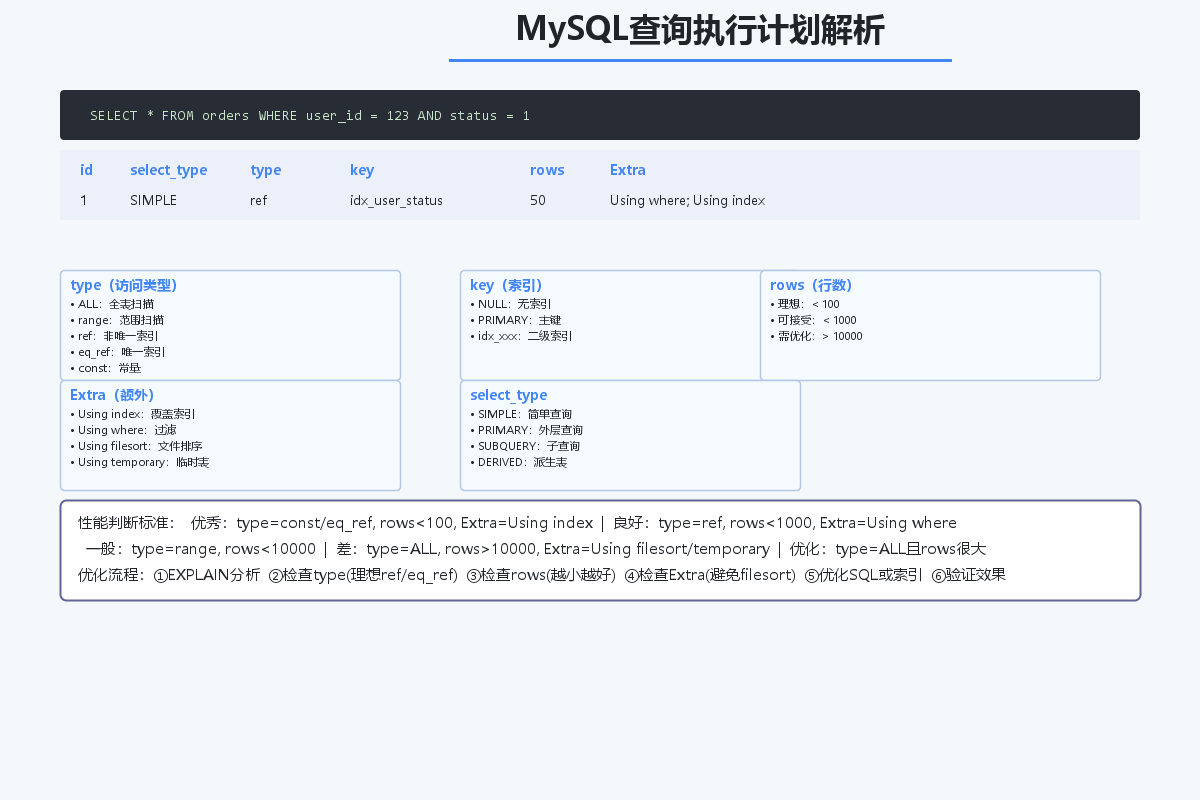
EXPLAIN SELECT ...;
— 结果显示:type: ALL,rows: 5000000,Extra: Using filesort
— 全表扫描500万行,且使用文件排序
优化方案:
CREATE INDEX idx_user_status_time ON orders(user_id, status, create_time);
— type: ref,rows: 50,Extra: Using where; Using index
— 使用索引,只扫描50行,无需排序
性能提升:从15秒优化到0.05秒
5.2 JOIN优化案例
问题场景:
SELECT o.*, u.username, u.email
FROM orders o
LEFT JOIN users u ON o.user_id = u.id
WHERE o.status = 1
AND o.create_time > '2024-01-01'
LIMIT 1000;
优化方案:
— orders表的user_id
CREATE INDEX idx_user_id ON orders(user_id);
— users表的id(主键已有索引)
— id是主键,自动有聚簇索引
CREATE INDEX idx_status_time ON orders(status, create_time);
— 如果users表较小,可以改为
SELECT o.*, u.username, u.email
FROM (SELECT * FROM users WHERE id > 0) u
LEFT JOIN orders o ON o.user_id = u.id
WHERE o.status = 1
AND o.create_time > '2024-01-01'
LIMIT 1000;
5.3 分页查询优化
传统分页问题:
— 深分页性能差
SELECT * FROM orders
WHERE user_id = 123
ORDER BY id DESC
LIMIT 100000, 20;
优化方案1:使用延迟关联
SELECT o.*
FROM orders o
INNER JOIN (
SELECT id FROM orders
WHERE user_id = 123
ORDER BY id DESC
LIMIT 100000, 20
) AS tmp ON o.id = tmp.id;
优化方案2:记录上次查询位置
— 第一次查询
SELECT * FROM orders
WHERE user_id = 123
ORDER BY id DESC
LIMIT 20;
— 记录最小ID,下次查询
SELECT * FROM orders
WHERE user_id = 123 AND id < last_max_id
ORDER BY id DESC
LIMIT 20;
六、索引维护与管理
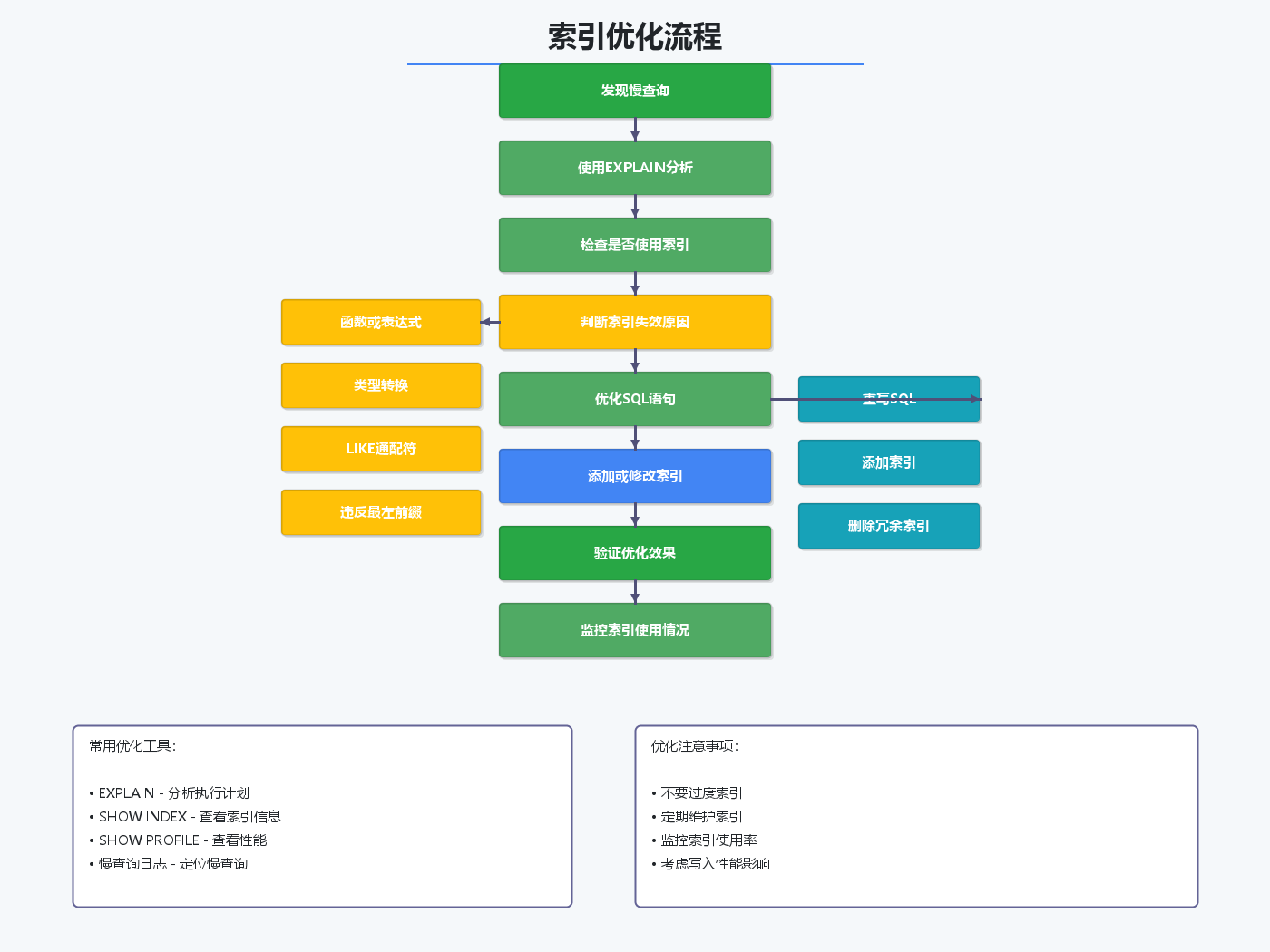
6.1 查看索引使用情况
— 查看表的索引
SHOW INDEX FROM orders;
— 查看索引统计信息
SELECT
TABLE_NAME,
INDEX_NAME,
SEQ_IN_INDEX,
COLUMN_NAME,
CARDINALITY
FROM information_schema.STATISTICS
WHERE TABLE_SCHEMA = 'your_database'
AND TABLE_NAME = 'orders';
— 查看索引使用效率(MySQL 8.0+)
SELECT
TABLE_NAME,
INDEX_NAME,
COUNT_STAR as 执行次数,
SUM_TIMER_WAIT/1000000000 as 总耗时秒,
COUNT_READ as 读取次数,
COUNT_FETCH as 获取次数
FROM performance_schema.table_io_waits_summary_by_index_usage
WHERE TABLE_SCHEMA = 'your_database'
ORDER BY COUNT_STAR DESC;
6.2 删除冗余索引
— 查找重复索引
SELECT
a.TABLE_SCHEMA,
a.TABLE_NAME,
a.INDEX_NAME as index1,
b.INDEX_NAME as index2,
a.COLUMN_NAME
FROM information_schema.STATISTICS a
JOIN information_schema.STATISTICS b
ON a.TABLE_SCHEMA = b.TABLE_SCHEMA
AND a.TABLE_NAME = b.TABLE_NAME
AND a.COLUMN_NAME = b.COLUMN_NAME
AND a.INDEX_NAME != b.INDEX_NAME
AND a.SEQ_IN_INDEX = b.SEQ_IN_INDEX
WHERE a.TABLE_SCHEMA = 'your_database';
6.3 索引重建
— 重建主键
ALTER TABLE orders DROP PRIMARY KEY, ADD PRIMARY KEY(id);
— 重建普通索引
ALTER TABLE orders DROP INDEX idx_user_id, ADD INDEX idx_user_id(user_id);
— 优化表(重建表和索引)
OPTIMIZE TABLE orders;
6.4 分析表
— 分析表,更新索引统计信息
ANALYZE TABLE orders;
— 检查表的键值分布
SELECT
COLUMN_NAME,
COLUMN_TYPE,
IS_NULLABLE,
COLUMN_KEY,
EXTRA
FROM information_schema.COLUMNS
WHERE TABLE_SCHEMA = 'your_database'
AND TABLE_NAME = 'orders';
七、最佳实践总结
7.1 索引设计原则
7.2 查询优化技巧
7.3 监控与诊断
— 开启慢查询日志
SET GLOBAL slow_query_log = 'ON';
SET GLOBAL long_query_time = 2; — 超过2秒的查询记录
— 查看慢查询日志
SHOW VARIABLES LIKE 'slow_query%';
— 使用EXPLAIN分析查询
EXPLAIN SELECT * FROM orders WHERE user_id = 123;
EXPLAIN EXTENDED SELECT * FROM orders WHERE user_id = 123;
— 查看表结构
SHOW CREATE TABLE orders;
八、常见问题与解决方案
Q1:为什么加了索引还是慢?
可能原因:
Q2:多列索引如何设计?
原则:
Q3:什么时候需要分区?
适用场景:
- 单表数据量超过1000万
- 历史数据很少访问
- 查询总是包含分区键
九、总结
MySQL索引优化是提升数据库性能的核心手段,掌握正确的索引优化方法可以让你的应用性能提升数倍甚至数百倍。



评论前必须登录!
注册