 网硕互联帮助中心
网硕互联帮助中心一、论文信息
本文目录
一、论文信息
二、论文摘要概况
三、PATConv模块结构图
四、PATConv模块的作用
五、PATConv模块的原理
六、PATConv模块的优势
七、即插即用模块代码

论文题目:Partial Channel Network: Compute Fewer, Perform Better
中文题目:部分通道网络:计算更少,性能更优
论文链接:https://arxiv.org/pdf/2502.01303
所属单位:西安交通大学·人工智能与机器人研究所
二、论文摘要概况
设计一种能让网络在不牺牲精度和吞吐量的前提下,保持低参数数量和计算量(FLOPs)的模块或机制,仍是一项挑战。为应对这一挑战并充分利用特征图通道间的冗余性,我们提出了一种新的解决方案 —— 部分通道机制(PCM)。具体而言,通过拆分操作将特征图通道划分为不同部分,每个部分对应卷积、注意力、池化和恒等映射等不同操作。基于这一思路,我们引入了一种新颖的部分注意力卷积(PATConv),能够高效地将卷积与视觉注意力相结合。研究表明,PATConv 可完全替代常规卷积和常规视觉注意力,同时减少模型参数和计算量。此外,PATConv 还能衍生出三种新型模块:部分通道注意力模块(PAT_ch)、部分空间注意力模块(PAT_sp)和部分自注意力模块(PAT_sf)。我们还提出了一种动态部分卷积(DPConv),其能自适应学习不同层的通道拆分比例,以实现更优的性能平衡。基于 PATConv 和 DPConv,我们构建了一个新的混合网络家族 PartialNet。该网络在 ImageNet-1K 分类任务中取得了优于现有部分 SOTA 模型的 Top-1 精度和推理速度,并且在 COCO 数据集的目标检测和实例分割任务中也表现出色。
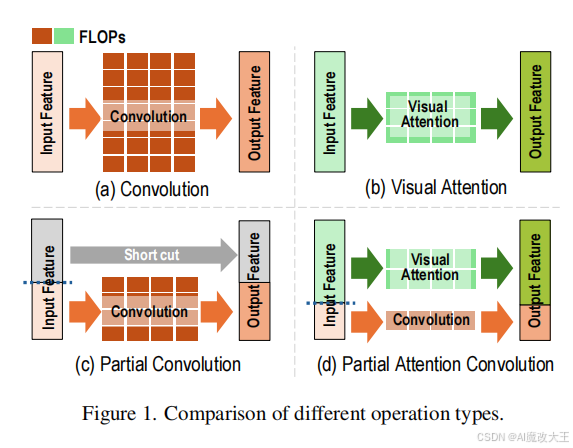
三、PATConv模块结构图
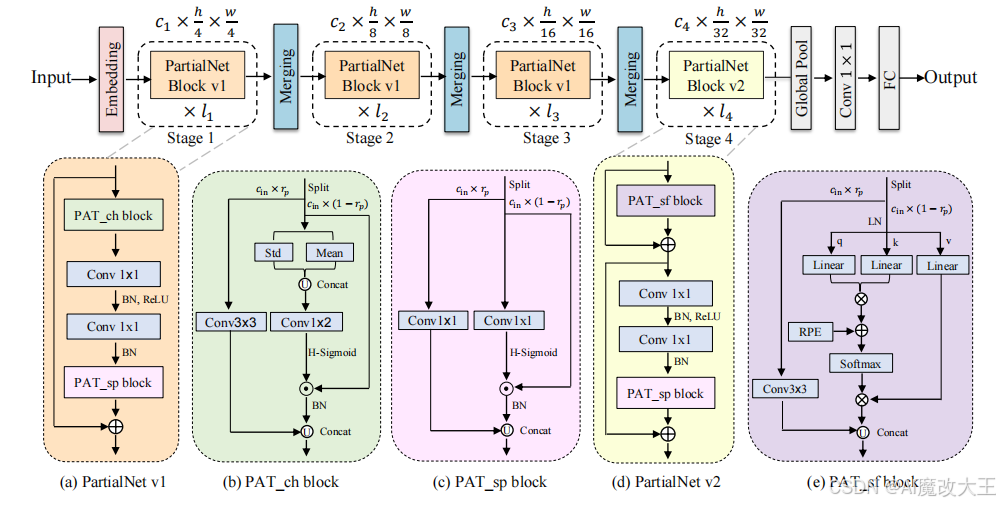
四、PATConv模块的作用
PATConv(Partial Attention Convolution,部分注意力卷积)是一种适用于深度学习视觉任务的即插即用模块,核心作用是在不牺牲模型精度的前提下,实现参数数量、计算量(FLOPs)与推理速度的最优平衡,具体表现为:
五、PATConv模块的原理
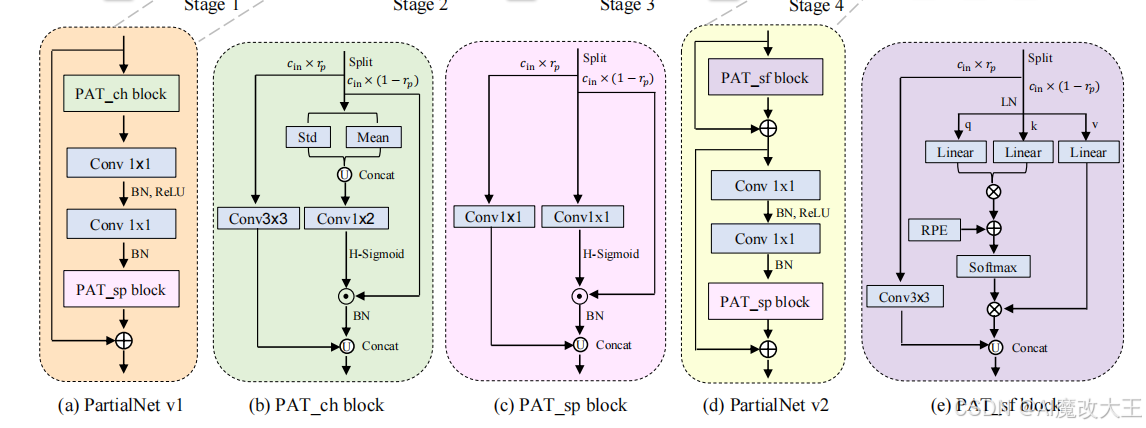
PATConv 基于部分通道机制(PCM) 设计,核心思路是 “通道拆分 – 并行运算 – 融合输出”,具体原理如下:
1. 通道拆分(Split Operation)
将输入特征图的通道(c)按比例 p(可自适应学习的超参数)拆分为两部分:
- 第一部分通道(占比 p):执行轻量级卷积运算(如 Conv3×3、Conv1×1),保留局部归纳偏置;
- 第二部分通道(占比 1−p):执行高效视觉注意力运算,捕捉全局信息交互,避免全通道注意力的高计算成本。
2. 并行运算与融合
两部分通道分别经过对应运算后,通过拼接(Concatenation)操作融合为完整输出特征图,数学定义为:
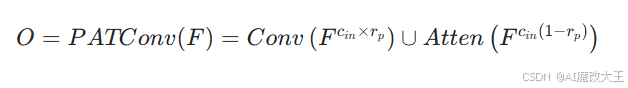
其中,F 为输入特征图(维度 h×w×c),O 为输出特征图(维度 h×w×c),∪ 表示拼接,Atten 表示视觉注意力操作。
3. 衍生三种注意力块
基于上述原理,PATConv 可灵活组合卷积与不同类型注意力,衍生出三种专用块,适配网络不同层需求:
- PAT_ch(通道注意力块):融合 Conv3×3 与增强型高斯通道注意力,通过计算通道均值和方差(而非仅均值),更充分捕捉通道间全局信息;
- PAT_sp(空间注意力块):融合 Conv1×1 与空间注意力,通过点卷积压缩全局通道信息生成注意力图,可与 MLP 层的 Conv1×1 合并推理,进一步降低 latency;
- PAT_sf(自注意力块):引入相对位置编码(RPE)的全局自注意力,仅用于网络最后一层,以最小计算代价扩展模型感受野。
4. 动态通道比例优化(结合 DPConv)
为解决固定拆分比例 rp 适配性不足的问题,PATConv 可搭配动态部分卷积(DPConv):通过可学习的门向量(Gate Vector)和克罗内克积(Kronecker Product)生成二进制关系矩阵,自适应调整不同网络层的通道拆分比例,满足参数、 latency 等约束条件,实现精度与效率的动态平衡。
六、PATConv模块的优势
1. 效率优势:大幅降低计算开销与推理 latency
- 相比常规卷积:通过仅对部分通道执行卷积,减少参数数量和 FLOPs(如 PartialNet-T2 相比 FasterNet-T2,FLOPs 从 1.91G 降至 1.03G);
- 相比全注意力机制:避免对所有通道执行元素级乘法,降低内存访问频率和并行计算压力,推理速度显著提升(如 PartialNet-T2 在 AMD MI250 GPU 上吞吐量提升 13.7%,CPU latency 降低 24.1%);
- 硬件适配性强:并行运算架构适配 GPU 资源调度,在计算密集型(Nvidia V100)和带宽密集型(AMD MI250)硬件上均表现优异。
2. 性能优势:精度不降反升
- 充分利用通道冗余:通过 “局部卷积 + 全局注意力” 的组合,既保留卷积的局部特征提取能力,又通过注意力弥补局部操作的全局信息缺失,特征表达更全面;
- 三种衍生块协同优化:PAT_ch 替换常规卷积、PAT_sp 增强 MLP 层、PAT_sf 扩展感受野,分层适配网络需求,使模型在分类(ImageNet-1K Top-1 精度最高 83.9%)、检测(COCO AP^b 最高 44.7%)、分割(COCO AP^m 最高 41.0%)任务中均超越 SOTA 模型;
- 可视化验证有效:Grad-CAM 结果显示,PATConv 的部分注意力能精准聚焦目标区域,证明其对关键特征的捕捉能力不弱于全注意力机制。
3. 灵活性与通用性优势
- 即插即用:可直接替换现有网络中的常规卷积、深度可分离卷积(DWConv)和注意力模块,无需调整网络结构(如在 ResNet50、MobileNetV2、ConvNext-tiny 中替换后,精度均提升 1-2.5%);
- 适配不同模型规模:支持 tiny、small、medium、large 等多种网络变体,通过调整通道数和块数量,平衡精度与资源需求(如 PartialNet-T0 适用于移动端,PartialNet-L 适用于高精度场景);
- 任务泛化能力强:在图像分类、目标检测、实例分割等任务中均表现优异,证明其对不同 CV 任务的适配性。
4. 创新性优势
- 突破传统 “串行融合” 思路:将卷积与注意力并行应用于不同通道,而非传统的 “卷积后接注意力” 或 “注意力后接卷积”,大幅降低推理 latency;
- 动态比例学习:结合 DPConv 实现拆分比例的自适应优化,解决固定比例难以适配所有网络层的问题,相比 FasterNet 固定 1/4 拆分比例,灵活性和性能更优;
- 理论支撑充分:基于特征通道冗余理论,通过高斯统计(PAT_ch)、相对位置编码(PAT_sf)等优化,使部分注意力的效果接近甚至超越全注意力。

七、即插即用模块代码
import torch
import torch.nn as nn
import timm
from torch import Tensor
import torch.nn.functional as F
from exp.irpe import build_rpe, get_rpe_config
try:
from mmdet.models.builder import BACKBONES as det_BACKBONES
from mmdet.utils import get_root_logger
from mmcv.runner import _load_checkpoint
has_mmdet = True
except ImportError:
print("If for detection, please install mmdetection first")
has_mmdet = False
def hard_sigmoid(x, inplace: bool = False):
if inplace:
return x.add_(3.).clamp_(0., 6.).div_(6.)
else:
return F.relu6(x + 3.) / 6.
def _make_divisible(v, divisor, min_value=None):
"""
This function is taken from the original tf repo.
It ensures that all layers have a channel number that is divisible by 4
It can be seen here:
https://github.com/tensorflow/models/blob/master/research/slim/nets/mobilenet/mobilenet.py
"""
if min_value is None:
min_value = divisor
new_v = max(min_value, int(v + divisor / 2) // divisor * divisor)
# Make sure that round down does not go down by more than 10%.
if new_v < 0.9 * v:
new_v += divisor
return new_v
class SqueezeExcite(nn.Module):
def __init__(self, in_chs, se_ratio=0.25, reduced_base_chs=None, act_layer=nn.ReLU, gate_fn=hard_sigmoid, divisor=4,
**_):
super(SqueezeExcite, self).__init__()
self.gate_fn = gate_fn
reduced_chs = _make_divisible((reduced_base_chs or in_chs) * se_ratio, divisor)
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.conv_reduce = nn.Conv2d(in_chs, reduced_chs, 1, bias=True)
self.act1 = act_layer(inplace=True)
self.conv_expand = nn.Conv2d(reduced_chs, in_chs, 1, bias=True)
def forward(self, x):
x_se = self.avg_pool(x)
x_se = self.conv_reduce(x_se)
x_se = self.act1(x_se)
x_se = self.conv_expand(x_se)
x = x * self.gate_fn(x_se)
return x
class RPEAttention(nn.Module):
'''Attention with image relative position encoding '''
def __init__(self, dim, num_heads=8, qkv_bias=False, qk_scale=None, attn_drop=0.0, proj_drop=0.0, rpe_config=None):
super().__init__()
self.num_heads = num_heads
head_dim = dim // num_heads
# NOTE scale factor was wrong in my original version, can set manually to be compat with prev weights
self.scale = qk_scale or head_dim ** -0.5
self.qkv = nn.Linear(dim, dim * 3, bias=qkv_bias)
self.attn_drop = nn.Dropout(attn_drop)
self.proj = nn.Linear(dim, dim)
self.proj_drop = nn.Dropout(proj_drop)
# image relative position encoding
self.rpe_q, self.rpe_k, self.rpe_v = build_rpe(rpe_config, head_dim=head_dim, num_heads=num_heads)
def forward(self, x):
B, C, h, w = x.shape
x = x.view(B, C, h * w).transpose(1, 2)
B, N, C = x.shape
qkv = self.qkv(x).reshape(B, N, 3, self.num_heads, C // self.num_heads).permute(2, 0, 3, 1, 4)
q, k, v = qkv[0], qkv[1], qkv[2] # make torchscript happy (cannot use tensor as tuple)
q *= self.scale
attn = (q @ k.transpose(-2, -1))
# image relative position on keys
if self.rpe_k is not None:
# attn += self.rpe_k(q)
attn += self.rpe_k(q, h, w)
# image relative position on queries
if self.rpe_q is not None:
attn += self.rpe_q(k * self.scale).transpose(2, 3)
attn = attn.softmax(dim=-1)
attn = self.attn_drop(attn)
out = attn @ v
# image relative position on values
if self.rpe_v is not None:
out += self.rpe_v(attn)
x = out.transpose(1, 2).reshape(B, N, C)
x = self.proj(x)
x = self.proj_drop(x)
x = x.transpose(1, 2).view(B, C, h, w)
return x
class SRM(nn.Module):
def __init__(self, channel):
super().__init__()
self.cfc1 = nn.Conv2d(channel, channel, kernel_size=(1, 2), bias=False)
#self.cfc2 = nn.Conv2d(channel, channel, kernel_size=1, bias=False)
self.bn = nn.BatchNorm2d(channel)
self.sigmoid = nn.Hardsigmoid()
def forward(self, x):
b, c, h, w = x.shape
# style pooling
mean = x.reshape(b, c, -1).mean(-1).view(b, c, 1, 1)
std = x.reshape(b, c, -1).std(-1).view(b, c, 1, 1)
# max_value = torch.max(x.reshape(b, c, -1), -1)[0].view(b,c,1,1)
u = torch.cat([mean, std], dim=-1)
# style integration
z = self.cfc1(u)
# z = self.act(z)
# z = self.cfc2(z)
# z = self.bn(z)
g = self.sigmoid(z)
g = g.reshape(b, c, 1, 1)
return x * g.expand_as(x)
class PATConv(nn.Module):
def __init__(self, dim, n_div=4, forward_type='split_cat', use_attn=True, channel_type='se', patnet_t0=True): #'se' if i_stage <= 2 else 'self',
super().__init__()
self.dim_conv3 = dim // n_div
self.dim = dim
self.n_div = n_div
self.dim_untouched = dim – self.dim_conv3
self.partial_conv3 = nn.Conv2d(self.dim_conv3, self.dim_conv3, 3, 1, 1, bias=False)
self.use_attn = use_attn
self.channel_type = channel_type
if use_attn:
if channel_type == 'self':
self.partial_conv3 = nn.Conv2d(self.dim_conv3, self.dim_conv3, 3, 1, 1, bias=False)
rpe_config = get_rpe_config(
ratio=20,
method="euc",
mode='bias',
shared_head=False,
skip=0,
rpe_on='k',
)
if patnet_t0:
num_heads = 4
else:
num_heads = 6
self.attn = RPEAttention(self.dim_untouched, num_heads=num_heads, attn_drop=0.1, proj_drop=0.1,
rpe_config=rpe_config)
self.norm = timm.layers.LayerNorm2d(self.dim_untouched)
# self.norm = timm.layers.LayerNorm2d(self.dim)
self.forward = self.forward_atten
elif channel_type == 'se':
self.partial_conv3 = nn.Conv2d(self.dim_conv3, self.dim_conv3, 3, 1, 1, bias=False)
self.attn = SRM(self.dim_untouched)
self.norm = nn.BatchNorm2d(self.dim_untouched)
self.forward = self.forward_atten
else:
if forward_type == 'slicing':
self.forward = self.forward_slicing
elif forward_type == 'split_cat':
self.forward = self.forward_split_cat
else:
raise NotImplementedError
def forward_atten(self, x: Tensor) -> Tensor:
if self.channel_type:
#print(self.channel_type)
if self.channel_type == 'se':
x1, x2 = torch.split(x, [self.dim_conv3, self.dim_untouched], dim=1)
x1 = self.partial_conv3(x1)
# x = self.partial_conv3(x)
x2 = self.attn(x2)
x2 = self.norm(x2)
x = torch.cat((x1, x2), 1)
# x = self.attn(x)
else:
x1, x2 = torch.split(x, [self.dim_conv3, self.dim_untouched], dim=1)
x1 = self.partial_conv3(x1)
x2 = self.norm(x2)
x2 = self.attn(x2)
x = torch.cat((x1, x2), 1)
return x
def forward_slicing(self, x: Tensor) -> Tensor:
x1 = x.clone() # !!! Keep the original input intact for the residual connection later
x1[:, :self.dim_conv3, :, :] = self.partial_conv3(x1[:, :self.dim_conv3, :, :])
return x1
def forward_split_cat(self, x: Tensor) -> Tensor:
x1, x2 = torch.split(x, [self.dim_conv3, self.dim_untouched], dim=1)
x1 = self.partial_conv3(x1)
x = torch.cat((x1, x2), 1)
return x
if __name__ == '__main__':
input = torch.rand(1, 64, 32, 32)
PATConv= PATConv(64,channel_type='se')
output = PATConv(input)
print('PATConv input_size:', input.size())
print('PATConv output_size:', output.size())






评论前必须登录!
注册