 网硕互联帮助中心
网硕互联帮助中心本方案提出了一套基于AI大模型的现代化数据治理体系建设框架,通过大模型的语义理解、模式识别和生成能力,实现数据治理的智能化、自动化和持续优化。该体系不仅解决传统治理的效率和规模瓶颈,更能挖掘数据深层价值,为企业数字化转型提供坚实的数据基础。
4000余份数字化合集:AI大模型及行业应用方案、企业数字化、数据中台、数据要素、数据资产、数据治理、数字化转型、IT信息化方案及报告等



一、项目背景与建设目标
1.1 建设背景
随着数字化转型加速推进,企业数据规模呈指数级增长,传统数据治理模式面临三大挑战:
-
数据量爆炸式增长:非结构化数据占比超80%,传统规则引擎难以有效处理
-
治理效率瓶颈:人工标注、分类、质量检查成本高昂且一致性差
-
智能化需求迫切:业务部门需要智能数据发现、语义理解、自动化治理能力
1.2 核心目标
构建“智能驱动、自动执行、持续优化”的新一代数据治理体系:
|
治理效率 |
数据分类自动化率≥90% |
|
数据质量 |
异常检测准确率≥95% |
|
知识发现 |
语义关联发现覆盖≥85%数据资产 |
|
成本优化 |
人工治理工作量降低70% |
二、总体架构设计

三、核心AI治理能力建设
3.1 智能元数据管理
-
自动化数据发现:基于大模型的语义理解能力,自动识别数据含义、业务属性和技术特征
-
智能血缘分析:结合代码解析与日志分析,构建完整的数据流转图谱
-
语义标签体系:通过自然语言处理建立业务-技术映射关系
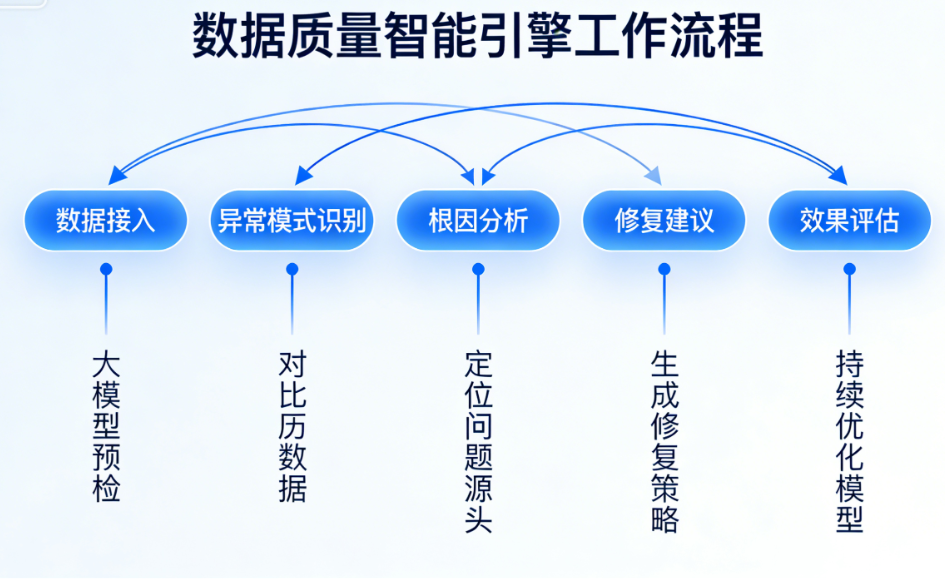
3.2 智能数据质量治理
3.3 智能数据安全与合规
-
敏感数据识别:基于大模型的上下文理解,精准识别个人隐私、商业机密等敏感信息
-
合规策略生成:自动生成符合GDPR、数据安全法等法规的数据处理策略
-
风险预警系统:实时监测数据使用异常,提前预警潜在合规风险
3.4 数据资产智能运营
-
价值评估模型:结合使用频率、业务关联度、质量评分等多维度评估数据价值
-
智能推荐系统:基于用户画像和行为分析,推荐相关数据资产
-
生命周期管理:预测数据衰退周期,制定自动化归档或销毁策略
四、关键技术实现路径
4.1 大模型选型与调优策略
|
通用大模型 |
基础文本理解、分类任务 |
API调用+微调 |
|
领域微调模型 |
行业术语理解、专业分类 |
私有化部署 |
|
轻量化模型 |
实时推理、边缘计算场景 |
端侧部署 |
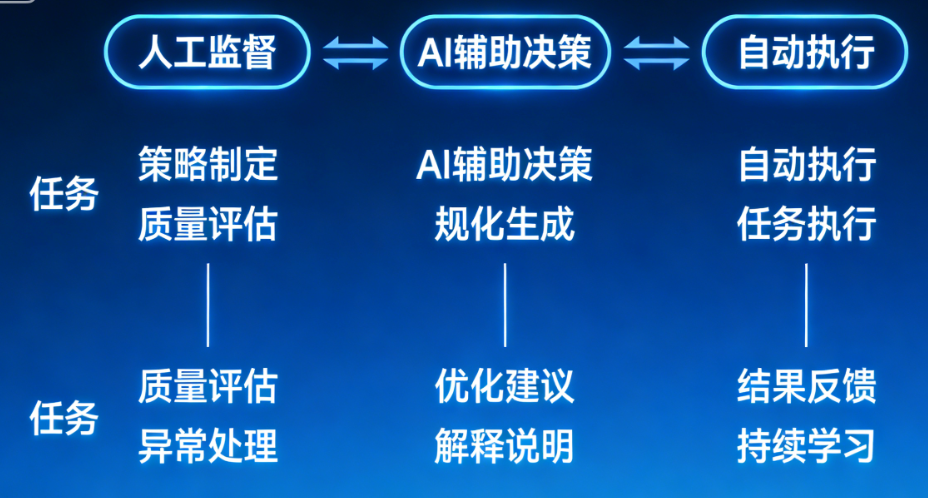
4.2 人机协同治理机制
4.3 持续学习与优化框架
-
反馈闭环:建立治理结果的用户反馈机制
-
A/B测试:新旧治理策略并行对比评估
-
模型迭代:定期更新训练数据,优化模型表现
五、实施路线图
第一阶段:基础能力建设(1-3个月)
构建数据治理基础平台
部署基础大模型服务
实现基础元数据自动采集
第二阶段:AI能力嵌入(4-6个月)
开发智能数据分类模块
建立数据质量AI评估体系
实现敏感数据自动识别
第三阶段:全面智能化(7-12个月)
构建完整的AI治理工作流
实现数据资产智能运营
建立持续优化机制
六、保障机制
6.1 组织保障
-
成立数据智能治理专项小组
-
建立数据治理委员会决策机制
-
制定AI治理伦理规范
6.2 技术保障
-
建立模型版本管理机制
-
实施治理效果监控体系
-
构建容错与回滚机制
6.3 安全与合规
-
数据脱敏处理机制
-
模型可解释性要求
-
审计跟踪全覆盖
七、预期成效与评估指标
|
效率提升 |
数据发现时间 |
缩短80% |
|
质量改进 |
数据质量问题发现率 |
提升90% |
|
成本优化 |
人工治理成本 |
降低65% |
|
业务价值 |
数据资产利用率 |
提升40% |
|
合规风险 |
数据合规事件 |
减少95% |
八、创新亮点
治理范式创新:从“规则驱动”向“智能驱动”转变
技术融合创新:大模型与传统数据治理技术深度融合
运营模式创新:建立“感知-决策-执行-优化”的智能闭环
价值实现创新:将数据治理从成本中心转变为价值中心


评论前必须登录!
注册