 网硕互联帮助中心
网硕互联帮助中心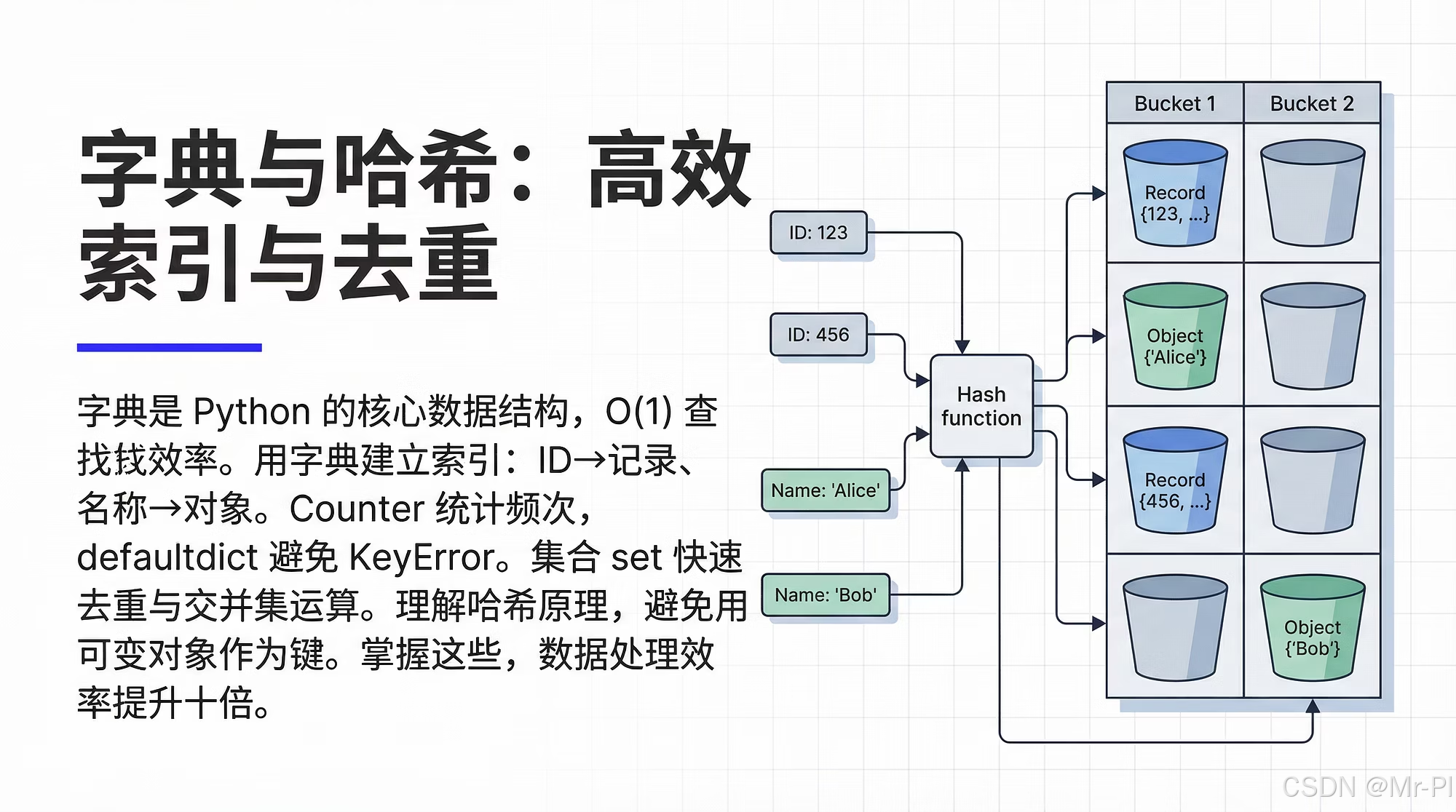
第十五章 字典与哈希:高效索引与去重
-
- 0. 本章目标与适用场景
- 1. 字典为什么快:把“查找”从 O(n) 变成 O(1)
- 2. 哈希表的工作机制:你需要的工程直觉
- 3. 字典与集合:索引与去重的两把刀
-
- 3.1 dict:key→value(索引/映射)
- 3.2 set:key 的集合(判重/过滤)
- 4. 数据工程中的“高频索引模式”(可直接套用)
-
- 4.1 主键索引:id → row
- 4.2 分组聚合:key → list(bucket)
- 4.3 计数:key → count(Counter)
- 4.4 反向索引:token → doc_ids(IR/RAG 基础)
- 5. 去重的三种层级:值去重、行去重、组合 key 去重
-
- 5.1 值去重:单列 unique
- 5.2 行去重:整行判等(结构化数据)
- 5.3 组合 key 去重:最常见、最推荐
- 6. 不可哈希对象怎么办:把 key 变成“稳定且可哈希”
-
- 6.1 list → tuple
- 6.2 dict → 规范化后再哈希(稳定 key)
- 7. 哈希与“相等”的关系:为什么要同时实现 **hash** 与 **eq**
-
- 7.1 dataclass 的安全写法(不可变 + 可哈希)
- 8. 哈希碰撞:要重视,但别恐惧
-
- 8.1 工程建议:避免拿 Python 内置 hash 做持久化 key
- 9. 数据/AI场景中的“哈希指纹”:去重、缓存、实验复现
- 10. 性能意识:什么时候 dict/set 是“必选项”
- 11. 实战清单:你可以立刻回去改的 8 个点
- 12. 小结
- 下一章
你做数据分析或 AI 工程,迟早会遇到这三类“性能坑”:
- 明明只是“查一下某个 id 对应的特征”,结果写成了 O(n) 的循环,数据一大就卡死。
- 去重/判重写得很玄学:字符串去重、样本去重、Embedding 近似去重混在一起,最后谁都不敢动。
- join/merge 用得飞起,但一旦遇到“非结构化 key”(JSON、列表、dict),就不知道怎么稳定索引。
这一章我们把最常用、最容易被低估的基础能力讲透:字典(hash table)与哈希(hashing)。 目标只有一个:让你在工程里把“查询”和“去重”写得又快又稳。
0. 本章目标与适用场景
学完你应该能做到:
1. 字典为什么快:把“查找”从 O(n) 变成 O(1)
列表里查找:
# O(n)
for row in rows:
if row["id"] == target:
return row
字典索引:
# O(1) 平均
idx = {row["id"]: row for row in rows}
return idx.get(target)
当 n=10 万、100 万时,这个差距就是“能不能上线”的差距。
2. 哈希表的工作机制:你需要的工程直觉
哈希表可以理解为:
- hash(key) → 一个整数
- 用这个整数映射到数组位置(bucket)
- bucket 里可能有多个元素(碰撞),再做一次比较确认
平均复杂度(工程上最常用):
- 查找/插入/删除:O(1)
最坏情况:
- 如果大量 key 碰撞,可能退化为 O(n)(但正常业务很少遇到)
你需要的工程直觉是: 只要 key 设计合理、hash 分布均匀,dict/set 就是你最可靠的“索引结构”。
3. 字典与集合:索引与去重的两把刀
3.1 dict:key→value(索引/映射)
- id → record
- token → count
- user_id → features
- doc_id → embedding path
3.2 set:key 的集合(判重/过滤)
- seen_ids
- unique_words
- visited_nodes
最常见的去重:
seen = set()
out = []
for x in xs:
if x in seen:
continue
seen.add(x)
out.append(x)
4. 数据工程中的“高频索引模式”(可直接套用)
4.1 主键索引:id → row
def build_pk_index(rows, key="id"):
return {r[key]: r for r in rows}
使用场景:
- 批量补充字段(用 id 对齐)
- 快速查样本
- 替代多次循环扫描
4.2 分组聚合:key → list(bucket)
from collections import defaultdict
groups = defaultdict(list)
for r in rows:
groups[r["category"]].append(r)
使用场景:
- 先分桶再统计
- 构建倒排:token → doc_ids
4.3 计数:key → count(Counter)
from collections import Counter
cnt = Counter(r["tag"] for r in rows)
使用场景:
- 词频、标签频次、错误码分布
- 数据质量统计(缺失原因计数)
4.4 反向索引:token → doc_ids(IR/RAG 基础)
inv = defaultdict(set)
for doc in docs:
doc_id = doc["id"]
for tok in doc["tokens"]:
inv[tok].add(doc_id)
这就是最简倒排索引,RAG/检索系统的底层直觉在这里。
5. 去重的三种层级:值去重、行去重、组合 key 去重
5.1 值去重:单列 unique
unique_users = set(r["user_id"] for r in rows)
5.2 行去重:整行判等(结构化数据)
行是 dict 时,不能直接放 set(不可哈希)。工程做法:
- 选择“决定唯一性”的字段作为 key
- 构造 tuple
key = (r["user_id"], r["item_id"], r["ts"])
5.3 组合 key 去重:最常见、最推荐
seen = set()
out = []
for r in rows:
k = (r["user_id"], r["item_id"])
if k in seen:
continue
seen.add(k)
out.append(r)
6. 不可哈希对象怎么办:把 key 变成“稳定且可哈希”
Python 的规则:
- 可哈希:int/float/str/bytes/tuple/frozenset(前提是内部也可哈希)
- 不可哈希:list/dict/set
6.1 list → tuple
k = tuple(r["tags"])
注意:如果 tags 顺序无关,你要先排序,否则同一集合不同顺序会被当成不同 key:
k = tuple(sorted(r["tags"]))
6.2 dict → 规范化后再哈希(稳定 key)
工程里常用:
import json
def stable_dict_key(d: dict) –> str:
return json.dumps(d, sort_keys=True, ensure_ascii=False, separators=(",", ":"))
然后用这个字符串当 key。
7. 哈希与“相等”的关系:为什么要同时实现 hash 与 eq
当你把自定义对象作为 dict key(或放进 set)时,必须理解这个不变量:
若 a == b,则必须 hash(a) == hash(b)
可以用一个数学式表达:
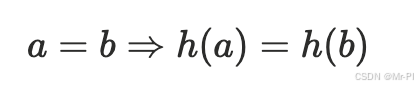
否则你会得到“看似相等却查不到”的灾难级 bug。
7.1 dataclass 的安全写法(不可变 + 可哈希)
from dataclasses import dataclass
@dataclass(frozen=True)
class Key:
user_id: int
item_id: int
frozen=True 让对象不可变,天然适合作为 key。
8. 哈希碰撞:要重视,但别恐惧
碰撞本身不是 bug,哈希表设计就假设会碰撞;真正的问题通常来自两类:
8.1 工程建议:避免拿 Python 内置 hash 做持久化 key
Python 的 hash(str) 在不同进程可能不一致(出于安全原因)。 所以:
- 内存索引用 dict/set:可以直接用内置 hash(你甚至感知不到)
- 落库/跨进程一致的 fingerprint:用稳定哈希(如 sha256/xxhash)
示例(稳定指纹):
import hashlib
def sha256_hex(s: str) –> str:
return hashlib.sha256(s.encode("utf-8")).hexdigest()
9. 数据/AI场景中的“哈希指纹”:去重、缓存、实验复现
你会经常需要一个 “fingerprint”:
- 样本去重:同一条样本(文本/JSON)只处理一次
- 缓存:同一输入不重复算 embedding
- 实验复现:同一配置生成同一 run_id
一个实用范式:
def fingerprint(obj) –> str:
import json, hashlib
s = json.dumps(obj, sort_keys=True, ensure_ascii=False, separators=(",", ":"))
return hashlib.sha256(s.encode("utf-8")).hexdigest()
然后你可以:
- cache[fingerprint(input)] = result
- seen.add(fingerprint(sample))
10. 性能意识:什么时候 dict/set 是“必选项”
你可以用一个简单的判断式:
当你的代码出现 “在循环里做查找”,且查找对象规模 ≥ 1e4 时, 大概率应该改成:
- 预构建 dict 索引
- 或者预构建 set 判重
形式化一点:
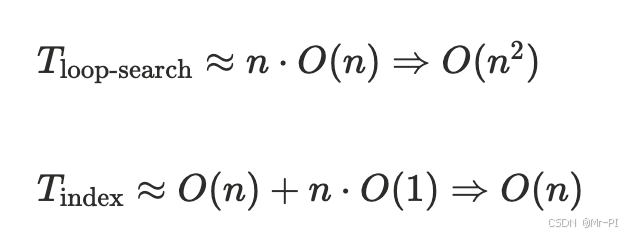
这就是为什么“写一个索引”常常能把程序从分钟级降到秒级。
11. 实战清单:你可以立刻回去改的 8 个点
12. 小结
字典与哈希不是“基础语法”,而是数据/AI工程里最核心的两件事:
- 索引:让查询从 O(n) 变成 O(1)
- 去重:让数据处理从“重复劳动”变成“可控计算”
你写得越工程化,就越离不开这套思维: 先建索引,再处理;先定 key,再去重;先做指纹,再缓存。
你现在最想优化的是哪一种?
下一章
《第十六章 迭代器与生成器:处理大数据的第一步》




评论前必须登录!
注册